论文推荐 | 肖湘文:基于Sentinel-1A数据的多种机器学习算法识别冰山的比较
Posted 测绘学报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文推荐 | 肖湘文:基于Sentinel-1A数据的多种机器学习算法识别冰山的比较相关的知识,希望对你有一定的参考价值。
《测绘学报》
《测绘学报》抖音自开通以来,聚焦于测绘地理信息学术前沿进展,受到了广大专家学者的大力支持,播放量数万,粉丝1.7万。
【测绘学报的个人主页】长按复制此条消息,长按复制打开抖音查看TA的更多作品##7NsBSynuc88##[抖音口令]
基于Sentinel-1A数据的多种机器学习算法识别冰山的比较
肖湘文1,2 , 沈校熠1,柯长青1
, 沈校熠1,柯长青1 ,周兴华2
,周兴华2
1. 南京大学地理与海洋科学学院, 江苏 南京 210000;
2. 自然资源部第一海洋研究所, 山东 青岛 266000
收稿日期:2019-05-07;修回日期:2019-10-17
基金项目:国家重点研发计划(2018YFC1407200;2018YFC1407203);国家自然科学基金(41830105)
第一作者简介:肖湘文(1996-), 男, 硕士, 研究方向为极地遥感影像识别。E-mail:m18709205750@163.com
摘要:冰山识别对于海洋环境监测和船只安全运行等具有重要的意义,是北极航道开通和北极开发过程中的重要内容。采用合成孔径雷达(SAR)影像进行冰山识别具有独特的优势,多种机器学习算法均可用于SAR影像的冰山识别中。为了最大限度地发挥机器学习算法的性能,有必要对不同机器学习算法及其搭配使用的特征与特征标准化方法进行评估,从而进行最优冰山识别方法的选择。因此,本文基于Sentinel-1A SAR影像,采用多种机器学习方法、多种特征组合及多种特征标准化方法进行冰山识别,并比较各流程方法的识别性能差异。采用的机器学习算法包括贝叶斯分类器(Bayes)、反向神经网络(BPNN)、线性判别分析(LDA)、随机森林(RF)以及支持向量机(SVM);特征标准化方法包括Min-max标准化、Z-score标准化及log函数标准化;数据集是含有12个SAR影像特征的969个冰山与非冰山样本,样本主要位于格陵兰岛东海岸。分类效果采用接收者操作特性(ROC)曲线下的面积(AUC)进行衡量。结果显示,最佳搭配下的RF的AUC值最高,达到了0.945,比最差的Bayes高出0.09。从识别率上来看,RF在冰山查全率为80%的情况下非冰山查全率达到92.6%,效果最好,比第2位的BPNN高出1.4%,比最差的Bayes高出2.6%;BPNN在冰山查全率为90%的情况下非冰山查全率达到87.4%,比第2位的RF高出0.8%,比最差的Bayes高出2.7%。上述结果表明,对冰山识别而言,选择最优的机器学习算法和最佳的特征与特征标准化方法都是十分重要的。
关键词:冰山 机器学习 Sentinel-1A SAR
Comparison of machine learning algorithms based on Sentinel-1A data to detect icebergs
XIAO Xiangwen1,2, SHEN Xiaoyi1, KE Changqing1, ZHOU Xinghua2 1. School of Geographic & Oceanographic Science, Nanjing University, Nanjing 210000, China;
2. The First Institute of Oceanography, MNR, Qingdao 266000, China
Foundation support: National Key Research and Development Program of China (Nos. 2018YFC1407200;2018YFC1407203); National Natural Science Foundation of China (No. 41830105)
First author: XIAO Xiangwen(1996—), male, master, majors in polar remote sensing image recognition.E-mail:m18709205750@163.com.
Corresponding author: KE Changqing, E-mail: kecq@nju.edu.cn.
Abstract: Iceberg detection is of great significance for marine environmental monitoring and safe sailing of vessels. It is an important part of the construction of the Arctic channel and the exploitation of the Arctic. Iceberg detection using synthetic aperture radar (SAR) images has unique advantages. Many machine learning algorithms can be used in the recognition of icebergs in SAR images. In order to maximize the performance of machine learning algorithms, it is necessary to evaluate different machine learning algorithms and their matching feature and feature standardization methods, so as to select the optimal iceberg detection process method. Therefore, based on Sentinel-1A SAR image, this paper uses a variety of machine learning methods, a variety of feature combinations and a variety of feature standardization methods for iceberg detection, and compares the performance differences of each process method. Machine learning algorithms include Bayes classifier (Bayes), back propagation neural network (BPNN), linear discriminant analysis (LDA), random forest (RF) and support vector machine (SVM); feature standardization methods include Min-max standardization, Z-score standardization and log function standardization; data sets are comprised of 969 iceberg and non-iceberg samples with 12 SAR image features, located mainly on the east coast of Greenland. The classification result is measured by the area under the receiver operating characteristic (ROC) curve (AUC). The results show that the AUC value of RF with the best configuration is the highest, reaching 0.945, which is 0.09 higher than worst Bayes. In terms of detection rate, under the case of 80% iceberg recall rate, the non-iceberg recall rate of RF is 92.6%, which is the best, 1.4% higher than the second BPNN, 2.6% higher than the worst Bayes; under the case of 90% iceberg recall rate, the non-iceberg recall rate of BPNN is 87.4%, 0.8% higher than the second RF and 2.7% higher than the worst Bayes. The above results show that it is very important to select the best machine learning algorithm, the best features and feature standardization method for iceberg detection.
Key words: iceberg machine learning Sentinel-1A SAR
“冰上丝绸之路”是“一带一路”倡议的重要组成部分,而北极航道的开发与运行对此具有重要的意义。冰山是北极航道开发中的主要威胁之一,准确地识别冰山是进行海洋环境监测和海上危险预警的主要内容,也是北极航道开发过程中必须解决的问题。研究表明,每年由格陵兰冰盖崩解而产生的冰山总体量在200 Gt~500 Gt之间[1-3],大约占到格陵兰冰盖年损失总量的一半[1-2],对北极航道和北大西洋上运行的船只及其他海上建筑物产生很大的威胁。此外,冰山的流动将淡水及营养物质带入远离大陆冰架的海域[4-5],对海洋环境的改变有重要影响。因此,冰山的有效监测对于海上运输和海洋环境十分重要。
合成孔径雷达(SAR)因其全天候、全天时以及相对较高空间分辨率等成像特点被广泛地应用于冰山识别中[6-7]。冰山后向散射强度较高的,在SAR影像上呈现为亮白色的斑点,较易与后向散射强度较低的海水区分。但由于环境、气温等问题[7]以及多年冰的存在,使得海面浮冰与冰山存在相似的SAR影像特征,两者的区分较为困难。因此,有效地区分冰山与海面浮冰是冰山识别的关键。
十几年来,针对SAR影像的冰山识别已经进行了多方面的研究。文献[8-9]利用冰山实测数据对Radasat-1 3种模式下的SAR影像与Envisat的ASAR影像的冰山识别概率曲线进行了绘制,证明了基于SAR影像冰山识别的可行性;文献[10]利用Bayes分类器对HH/HV极化方式的ASAR影像数据上的冰山与船只进行分类,分类精度达93.5%;文献[11]针对不同季节、不同海冰条件下Envisat HH极化的ASAR影像与ERS-2 VV极化的SAR影像进行海冰识别,探究了各种影响冰山识别精度的因素;文献[12]率先提出将基于对象的方法应用于冰山识别领域,针对所有海情进行试验,冰山检测率高达96.2%,但此方法工作复杂,计算量较大;文献[13]通过图像分块的迭代CFAR算法对Radarsat-2影像进行冰山识别,识别正确率在85%以上。由以上方法可以发现,由于计算量较大及精度不够等问题,基于简单的SAR影像特征(强度值等)实现冰山与浮冰的区分较难,需要引入几何、纹理等高层次的图像特征进行冰山的识别,因此,需要引入能够考虑多种高层次特征的机器学习算法。
相较于传统的分类方法,机器学习算法可以更好地挖掘分类特征的潜在信息,已经被广泛的应用于基于遥感影像的目标识别领域[14-18]。因此,本文将5种机器学习算法用于SAR影像冰山识别中,比较其识别结果差异,以获取最优的冰山识别机器学习算法。由于不同的机器学习算法倾向于不同的数据预处理方式以及识别特征,为了公平地比较各算法的优劣,本文同时还采用了多种数据预处理方法和识别特征组合进行冰山识别,并采用ROC曲线[19]评价识别精度。同时对识别特征的重要性进行了评估,得到了用于SAR影像冰山识别的主要识别特征。
1 数据和方法1.1 冰山数据集
格陵兰岛位于北冰洋与大西洋之间,有着北半球最大的冰盖和冰架。每年夏天大量冰山会脱落于格陵兰冰架,大小从直径几十m到十多km不等[20],而格陵兰海是北极航道的重要组成部分,也是受到冰山影响最为强烈的海域之一。因此本文将研究区定于格陵兰岛东岸附近,丹麦港口偏南的海域(图 1),以研究该区域内冰山的相关特征和识别方法,并采用一景欧洲航天局哥白尼计划(GMES)的地球观测卫星哨兵一号(Sentinel-1)SAR影像进行冰山识别。该影像是经过几何矫正等处理后的EW GRD(超宽幅模式)一级影像,极化方式为HH,空间分辨率为50 m×50 m。影像覆盖格陵兰海的主要海域,其中心位置地理坐标为75°N,17°W。影像采集时间是2017年9月30日,时值北半球的夏季。
 |
| 图 1 研究区地理位置。位于格陵兰东岸(右下角矩形框内),图中蓝色区域为SAR影像覆盖区域,覆盖格陵兰海主要区域 Fig. 1 Geographical location of the study area. Located on the east coast of Greenland (in the rectangular box at the lower right corner), the blue area in the picture is the coverage area of SAR image, covering the main area of the Greenland Sea |
图选项 |
选取的SAR影像上有海水、浮冰、冰山等多种地物[21](图 2),为了有效提取出冰山与非冰山(浮冰)样本,考虑冰山和浮冰的图像特征,同时为了减少椒盐噪声,采用面向对象的方法[22-23]生成样本集(图 2)。主要步骤如下。
 |
| 图 2 样本生成示例 Fig. 2 The example diagram of sample generation |
图选项 |
(1) 影像分割:采用多尺度分割的方法,将影像分割为独立的对象。为了保证样本的边界足够准确,将分割参数设置得较小,使得分割出的对象边缘足够细致(图 2(a))。分割尺度设置为50,形状与紧致性因子均设置为0.5。
(2) 自适应阈值分类:使用基于对象的类间最大方差法[24]进行自适应的阈值分割[25](图 2(b))。
(3) 对象融合:使用区域聚合的方法将原本分割较为零碎但实为同一块海冰的对象合并,如图 2(c)所示黄色方框中的放大图展示了小块海冰的分割细节。
(4) 正负样本选取:冰山与非冰山样本的人工识别。由于海面环境变化快,并且光学影像存在大面积被云遮挡等问题,所以光学影像只作为辅助数据,对于冰山与非冰山的判别主要由3位专家独立在分割后的影像中进行,最后采用判别偏差不超过3%的情况下得到的结果。冰山和非冰山的示例如图 2(d)所示,蓝色方框中的为非冰山样本细节,绿色方框中的为冰山样本细节。图 3(e)为冰山与非冰山样本整体分布情况。
 |
| 图 3 方法流程 Fig. 3 Flow chart of the method |
图选项 |
最终生成的样本集中包括475个冰山样本,494个非冰山样本。采用12个图像特征用于SAR影像的冰山识别(表 1),这些特征包含了几何形状属性(No. 1、6、7、9)、物理属性(No. 8、10、11)与背景关系属性(No. 2、3、4、5、12)方面,样本特征的统计信息见表 2。
表 1 12个样本特征的描述与计算式Tab. 1 Description and calculation formulas of 12 sample features
| 序号 | 特征 | 描述 |
| 1 | P | 周长,以样本周边像元数量计算 |
| 2 | Opm/Bpm | Opm=OSd/OMe,Bpm=BSd/BMe,其中OMe代表样本像元均值 |
| 3 | ConSm | (N0/G0)/(Nb/Gb),其中N0是样本像元数量,G0样本像元梯度之和,Nb背景区域像元数量,Gb背景区域像元梯度值 |
| 4 | ConRaSd | OSd/BSd |
| 5 | ConMax | 样本背景像元均值与样本像元最小值之比 |
| 6 | C | 复杂度,P2/N |
| 7 | N | 样本像元数量 |
| 8 | BMe | 样本背景像元均值 |
| 9 | S | 样本长宽比 |
| 10 | OSd | 样本像元值标准差 |
| 11 | GSd | 样本背景区域梯度(Zevenbergen-Thorne方法计算)标准差 |
| 12 | BSd | 样本背景像元标准差 |
表选项
表 2 冰山与非冰山样本特征的统计数据(最小值、中值、最大值与四分差)Tab. 2 Statistical data on characteristics of iceberg and non-iceberg samples (i.e. minimum, median, maximum and quartile difference)
| 序号 | 特征 | 冰山样本 | 非冰山样本 | 数据分 布状态 |
|||||||
| 最小值 | 中值 | 最大值 | 四分差 | 最小值 | 中值 | 最大值 | 四分差 | ||||
| 1 | P | 14.00 | 26.00 | 682.00 | 14.00 | 6.00 | 46.00 | 406.00 | 38.50 | 正偏态 | |
| 2 | Opm/Bpm | 0.66 | 2.10 | 70.34 | 1.38 | 0.26 | 1.03 | 23.99 | 0.63 | 正偏态 | |
| 3 | ConSm | 0.68 | 0.84 | 1.13 | 0.06 | 0.63 | 0.93 | 1.24 | 0.12 | 正偏态 | |
| 4 | ConRaSd | 1.80 | 13.42 | 759.84 | 14.88 | 0.40 | 2.23 | 81.46 | 2.08 | 正偏态 | |
| 5 | ConMax | 0.14 | 0.58 | 0.87 | 0.15 | 0.23 | 0.76 | 1.11 | 0.11 | 负偏态 | |
| 6 | C | 16.20 | 22.22 | 134.58 | 6.87 | 16.00 | 42.10 | 282.25 | 30.34 | 正偏态 | |
| 7 | N | 11.00 | 28.00 | 3 456.00 | 23.25 | 2.00 | 53.00 | 857.00 | 58.00 | 正偏态 | |
| 8 | BMe | 5 572.98 | 20 263.60 | 26 874.58 | 4 510.97 | 8 405.58 | 24 750.42 | 28 635.00 | 2 857.17 | 负偏态 | |
| 9 | S | 1.00 | 1.29 | 4.00 | 0.43 | 1.00 | 1.50 | 3.67 | 0.62 | 正偏态 | |
| 10 | OSd | 15 807.25 | 78 511.17 | 769 391.75 | 81 594.94 | 1 853.50 | 17 604.87 | 283 896.76 | 14 625.26 | 正偏态 | |
| 11 | GSd | 0.00 | 10.84 | 29.35 | 14.68 | 0.00 | 15.55 | 26.49 | 4.53 | 负偏态 | |
| 12 | BSd | 0.00 | 6 833.97 | 16 359.08 | 2 404.37 | 0.00 | 7 750.43 | 26 768.34 | 2 766.68 | 正态 | |
表选项
1.2 方法
算法的选择、不同特征及其组合的选择以及特征标准化方式的选择都会影响机器学习算法识别精度。本文比较了5种分类器基于12个分类特征的冰山识别结果差异。同时,为了消除特征值量级不同对识别结果的影响,采用了3种特征标准化方式进行特征数据的处理,具体流程如图 3所示。首先,基于SAR影像上提取出的969个样本,选用3种常见的特征标准化方式,加上用作对照的未进行特征标准化处理的数据,共得到4组特征数据。然后,按照留出法[18]将样本数据分为600个训练样本与369个测试样本,对于每个样本有4095种特征的组合方式(12个特征自由组合),基于4组特征数据,每组4095个特征组合,采用5种机器学习方法进行冰山识别,并通过ROC曲线下的面积(AUC)来衡量各个方法组合的优劣,可得到81 900个识别结果。最后,由于样本数据量不大,留出法得到的识别模型泛化性较差,故而在上述识别结果精度的前5%的识别模型中,再采用5折交叉验证[18]的方法,对这些较优组合进行二次对比,从而得到冰山识别的最优组合。
1.2.1 特征预处理
本文所采用的样本特征均以数值的方式呈现,并且一些不同的特征之间的数值范围相差较大(表 2),所以考虑到特征值量级的差异对样本分布的影响,需对特征数据进行标准化处理。采用以下3种方式对特征数据进行标准化。
(1) Min-max标准化。Min-max标准化也称离差标准化,是对原始数据的线性变换,使特征值都一一映射到[0, 1]之间,其转换函数为
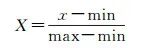 (1)
(1)
式中,x为原始数值;max为数据集最大值;min为数据集最小值;X为转换后的值。
(2) Z-score标准化。这种方法通过原始数据集的均值与标准差来进行数据的标准化,处理后的数据将符合正态分布,且均值为0,标准差为1,其转换函数为
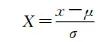 (2)
(2)
式中,x为原始数值;μ为数据集均值;σ为数据集标准差;X为转换后的值。
Z-score标准化为目前使用最为广泛的标准化方法,适用于数据集最大值最小值未知的情况。
(3) log函数标准化。该方法通过以10为底的log函数进行特征标准化,其转换函数为
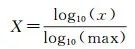 (3)
(3)
式中,x为原始数值;max为数据集最大值;X为转换后的值。
此外,本文将未做标准化处理的特征数据同样作为机器学习算法的特征集之一,与标准化的特征集进行识别结果的对照。
1.2.2 机器学习算法
本文采用5种机器学习算法来进行冰山识别,包括贝叶斯分类器(Bayesian,Bayes)、反向神经网络(back propagation neural network,BPNN)、线性判别分析(linear discriminant analysis,LDA)、随机森林(random forest,RF)和支持向量机(support vector machine,SVM),每种算法的介绍与参数设置如下:
(1) Bayes分类器。贝叶斯分类器的分类原理是利用贝叶斯公式,通过某对象的先验概率,计算出其后验概率,即该对象属于某一类的概率,是一种在概率框架下实施决策的基本方法。贝叶斯分类器收敛速度快,适用于小数据量的分类。本文采用高斯核密度函数对每个类别特征的概率密度进行估计。
(2) BPNN分类器。BPNN是一种基础的神经网络模型,其原理是将特征数据以向量形式传入输入节点后,通过隐含层节点层层计算向前传播,最后由输出层输出,并将输出值与预期值进行对比并求出误差,误差再经过层层节点向后传播,每层的节点根据误差的大小与自身的权值来对自身的权值进行调整,最后得到一个拥有最优权重值的神经网络模型。在参数设置得当的情况下,BPNN具有较高的稳健性与并行性。但实际情况下,BPNN隐含层与节点数量的选择并没有明确的理论指导,容易因参数选择不当产生欠拟合或过拟合的情况。本文设置5个隐含层,每个隐含层包含20个神经元,隐含层间使用tan-sigmoid型函数进行传递,输出层则使用线性传递函数purelin输出,训练函数则使用Levenberg-Marquardt算法。
(3) LDA(线性判别式分析)分类器。LDA是将高维的样本特征数据投影到低维度上,并且找到最佳识别的矢量空间,以达到抽取分类信息和压缩特征空间维数的效果。投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。本文中特征相关矩阵的规范参数设置为0。
(4) RF分类器。RF利用随机选择特征和样本集的决策树作为弱学习器,采用所有决策树投票的方式,得到最后的分类结果。RF容易实现且计算效率高。本文决策树的数量定为300棵,每棵树有12个特征可供选择。
(5) SVM分类器。SVM的基本原理是在高维的特征空间中找出最佳的分割超平面,使得训练集上的正负样本间距最大,即求解最大边距超平面。SVM分类器通常拥有高准确率,同时也在理论上避免了过拟合问题,但对核函数等相关参数比较敏感。本文采用高斯函数作为SVM的核函数。
1.2.3 交叉验证
由于样本集较小,所以为了在保证充分利用样本数据,同时避免训练与测试样本特殊性对试验的影响,本文在得到81 900个初步结果后将采用交叉验证的方法进行再比较。交叉验证是指将训练样本随机分为数量相等的K份,每次训练都将其中1份作为测试样本,剩下的K-1份作为训练样本,通常又将这整个过程循环k次,得到K×K个结果,以保证试验结果的稳定与可靠[19]。本文对81 900个组合识别精度的前5%,也就是4095个组合方式进行5折交叉验证,(即K=5),每个组合会得到25个精度结果,之后取其均值后进行精度对比。
1.2.4 精度验证
本文采用接收者操作特性(ROC)曲线及其曲线下面积AUC来对各个分类器性能进行评判。ROC曲线是指根据一系列不同的二分类方式(分界值或者阈值),以真阳性率(sensitivity)为纵坐标,假阳性率(specificity)为横坐标绘制的曲线[26-27]。在本文中,真阳性率表现为冰山查全率,假阳性率则表现为非冰山查全率。
对于一个毫无分类效果的分类器,其ROC曲线将呈现为一条45°斜指右上角的直线,而分类效果越好的分类器,其ROC曲线将越靠近图像的左上角,即其图像下方的面积AUC也就越大。具体精度评价方法如下:
(1) 特征标准化。最高精度与稳健性将是考察特征标准化方法的两个主要方面,由留出法得到的81 900种初步结果的统计数据将用于评价3种特征标准化方法的效果。
(2) 特征重要性。序列性变量精度的重要性(permutation variable accuracy importance,PVAI)[28-29]将被用于特征的重要性,其原理是基于每个特征随机增加或减少后对AUC变化的大小来评判特征的重要性,结果由得到的81 900种结果计算而得。
(3) 机器学习算法。机器学习算法的好坏主要由ROC曲线与80%与90%冰山查全率下的非冰山查全率来评定,结果由交叉验证得到的5种最优结果计算而得。
2 结果与讨论2.1 特征标准化方式比较
总体而言,Z_score标准化方法表现稳定,无论是采用Bayes、BPNN、RF还是SVM,其得到的AUC均值与最大值均高于其他3种特征标准化方式,只在采用LDA分类器时的均值低于log函数标准化方法(图 4)。对于常用的Min-max特征标准化方式,识别效果较差,在采用Bayes、BPNN、LDA与RF分类器时,AUC均值与无标准化处理时相等甚至更低(Bayes)。而由于SVM的分类超平面由少数的几个支持向量决定,因此对特征值量级非常敏感,使得本文中SVM对于未进行标准化处理的特征产生了严重的不适,得到的结果产生了较大的错误,所以特征数据的标准化对SVM至关重要。
 |
| 图 4 不同特征标准化处理方法下(Min-max标准化、Z-score标准化、log函数标准化以及不标准化的对照组)各分类器的识别结果(包含不同的特征组合)。图中每根竖直的线段代表数据的范围,线段中部的矩形代表数据的集中分布位置,矩形中的横线代表数据中位数所在位置,叉号代表数据均值所在位置 Fig. 4 Recognition results of classifiers (including different feature combinations) under different feature standardization processing methods (Min-max standardization, Z-score standardization, log function standardization and non-standardized control group). Each vertical line in the graph represents the range of the result, the rectangle in the middle of the line represents the centralized location of the result, the horizontal line in the rectangle represents the location of the median of results, and the fork represents the location of the mean of results |
图选项 |
Z_score标准化表现良好可能的原因有两点。首先,较好稳健性可能是因为其对特征数据量级消除的同时也保留了原有数据的分布;其次,Z_score标准化以每组数据的标准差为单位,使得不同量级的数据也能进行比较,这可能是Z_score标准化比其他方法具有更好效果的原因。而Min-max标准化方式则简单地将所有数据压缩在0与1之间,在将特征数据范围差别消除的同时又使得大部分数据聚集在一个很小的区间中,因此影响了识别结果的精度。值得一提的是,相比于其他分类器,log函数标准化在LDA中有着突出的表现,可能是由于log函数标准化使得特征数据的分布更为均匀,增大了类间距离,让LDA的分类精度有额外的提升。对SVM来说,则必须进行特征值量级的消除。
当然,精度并不是评价标准化方法好坏的唯一标准,虽然Min-max标准化组相比未标准化组精度基本没有提升,但可能会有模型收敛速度、收敛方向甚至是否收敛等方面的改善,这值得更多的研究去探讨。
2.2 分类器比较
由于不同的分类器倾向于不同的特征标准化方式和特征组合,因此本文选择各分类器的最高精度进行分类器识别效果的比较(表 3)。不同的分类器在识别精度最高时所采用的特征不同,并且都没有使用全部的特征,这表明特征数量并非越多越好,多余的特征可能会对分类的效果产生反作用。
表 3 各分类器取得最大识别精度时的特征标准化方式和特征组合,其中特征数据序号对应表 1中的序号Tab. 3 Feature standardization and feature combination when each classifier achieves maximum recognition accuracy, the sequence number of feature data corresponds to the sequence number in Tab. 1
| 分类器 | 特征标准化方式 | 特征 | AUC |
| RF | Min-max标准化 | [2、3、4、6、7、11] | 0.945 |
| LDA | log函数标准化 | [2、4、8] | 0.944 |
| BPNN | log函数标准化 | [1、3、4、6、7、12] | 0.943 |
| SVM | Z_score标准化 | [2、4、12] | 0.939 |
| Bayes | log函数标准化 | [10] | 0.936 |
表选项
使用全特征与使用最佳特征得到的AUC差值称为落差值,落差值能更好的表现出各分类器对最佳特征选择的依赖性。Bayes作为一种假设各特征相互独立的分类器,特征之间的关系对识别结果影响较大,使得其在使用全特征之后AUC值下降最多,为0.021 7,表明其较为依赖最佳特征;RF中的决策树对特征进行随机选取,所以额外特征的使用并没有产生太多的负面影响,落差最小,为0.001 7,依赖性最低;另外BPNN作为一种给各特征施加权重来进行分类的算法,本不应该受到额外特征的影响,但落差依然达到0.010 9,可能是因为额外特征的加入使得模型陷入了一个局部最小值;SVM与LDA都是利用几何原理进行分类的算法,模型会被额外的特征影响。但由于SVM模型通常只由几个支持向量决定,故而所受影响较小,落差值为0.002 1,且接近RF,LDA则受额外特征影响较大,落差值为0.005 6。
从5种分类器的ROC曲线中可以得到更多的信息(图 6(a))。总体而言,没有分类器能够在所有的阈值上都占据最优,但RF与BPNN更为靠近坐标轴左上角,整体上表现出的较优性能。具体而言,RF在冰山查全率介于52.5%~87.5%之间时最靠近坐标轴左上角,但冰山查全率在87.5%~92.5%之间时BPNN要更为靠近坐标轴左上角。对于其他分类器来说,在冰山查全率大于94%时,如图 6(b)中的显微放大图所示,LDA与SVM占据优势,并且趋势一致,但由于此取值情况较为极端,所以即使LDA的AUC值略大于BPNN,总体上来看,依然认为LDA与SVM的效果要差于RF与BPNN。而Bayes效果最差。
 |
| 图 5 各分类器在使用全特征时与使用最佳特征时得到的AUC值的比较,图中黄色折线与次坐标轴(右侧坐标轴)对应,表现了各分类器在使用全特征之后AUC落差的大小 Fig. 5 Comparison of the AUC values of each classifier when using full features with those obtained when using the best features, the yellow line in the graph corresponds to the sub-coordinate axis (right coordinate axis), which directly shows the AUC drop of each classifier after using full features |
图选项 |
 |
| 图 6 (a) 为各分类器的均值ROC曲线,取自25次交叉验证的均值。图中只显示冰山查全率为50%~100%与非冰山查全率为50%~100%的部分,图中黑线强调80%与90%冰山查全率下各分类器的非冰山查全率。(b)为(a)中红框部分放大图,以便更清晰地看出各曲线在冰山查全率为90%~100%时的趋势 Fig. 6 (a)shows ROC curves of each classifier. The mean values were obtained from 5-fold cross validations. The figure only shows the parts with a recall of 50%~100% for icebergs and a recall of 50%~100% for non-icebergs. The black line in the figure emphasizes the non-iceberg recall rate of each classifier under 80% and 90% iceberg recall rate. (b) is a magnified view of the red box in (a), to more clearly see the trend of each curve when the iceberg recall rate is 90%~100% |
图选项 |
由于在实际情况中,正确判断出是冰山的意义显然要远远大于正确判断出不是冰山的意义,因此通过不同分类器在80%与90%的高冰山查全率时(图 6(a)中黑色横线)非冰山查全率的大小可以更为直观地体现各个分类器的差距。RF在80%冰山查全率的情况下非冰山查全率达到了92.5%以上(图 6(a)),比Bayes高出了2.6%,比位于第2名的BPNN也要高出1.4%,表明RF在冰山识别上具有较优越的性能。而在冰山查全率为90%时BPNN的非冰山查全率值为最高(为87.4%),比最低的Bayes高出2.7%,比RF高出0.8%。
总体而言,RF对泛化误差进行无偏估计,模型泛化能力较强,因此在本文中除了获得最高的识别精度以外,在面对不同特征标准化方法时都有很好的稳健性,可以作为SAR影像冰山识别的首选分类器。其次是BPNN,但由于BPNN模型假设了大量的参数,而确定BPNN中各种参数的最优值几乎难以实现[17],因此BPNN对于冰山识别仍然具有较大潜力。与其他分类器不同,LDA与Bayes都既是线性分类器又同属生成模型,LDA在本文中的总体表现较好,表明样本分布的线性关系较强,但精度比RF与BPNN又略差,说明RF与BPNN作为非线性分类器所提供的额外灵活性对分类结果有所提升;而Bayes分类器作为唯一一个假设样本特征之间相互独立的分类器,表现出了最差的性能,说明所选用的12个特征之间相关性很强,Bayes最佳搭配中只用了一个特征也能证明这一点。
图 7所示为得到的最佳冰山识别流程方法对冰山的识别结果局部图,即RF搭配经Min-max标准化处理后的2、3、4、6、7、11号6种特征后得到的模型对冰山的识别结果局部图。
 |
| 图 7 RF在2、3、4、6、7、11六个特征经Min-max标准化处理后得到的模型对冰山的识别结果图,图中绿色斑块为识别出的冰山;红色斑块为非冰山;黑色区域为海水 Fig. 7 The recognition results of the model obtained by RF after Min-max standardization on 6 features of 2, 3, 4, 6, 7 and 11. The green patches are identified as icebergs; the red patches are non-icebergs; and the black areas are sea water |
图选项 |
2.3 特征重要性比较
总体而言,1、6、7、9号4个较为简单的几何特征对于各个分类器来说效果并不好,特别是1号特征P(样本周长)与7号特征N(样本像元数目)在5个分类器中起到的作用都比较小,这可能是因为冰山与浮冰在大小与形状上都比较相似的原因,使得分类器很难从这些特征将样本区分。而描述样本标准差及与背景关系之类的特征(如3、4、8、10号等特征)表现出了较高的重要性。其中10号特征OSd(样本后向散射标准差)在5个分类器中都表现出了很高的重要性,表现出这一特征在冰山识别上的优越性;而9号特征S(样本长宽比)在BPNN、LDA、RF与SVM中的重要性都非常低,在Bayes中的重要性也只有0.24,故而该特征的加入效果最差。
尽管OSd这一个特征在5个分类器上都表现出很高的重要性,但依然可以从其他特征在各分类器中的表现看出不同分类器对于不同特征的偏好。例如,ConRaSd在RF中最为重要,在LDA中的重要性却只有0.42。表明对于特征的选择需要充分考虑到所使用分类器对于特征的适应性问题。因此,在进行特征重要性评估时,“重要”的特征应该通过多数分类器的投票选出。OSd与ConRaSd是冰山识别的最主要特征,其次是ConSm、Opm/Bpm、ConMax和BMe。
表 4 特征重要性的排序。采用序列性变量的重要性(PVAI)评价,并按照比例归一化到[0, 1]之间,各行各列中的最大值用粗体表示Tab. 4 Ranking of feature importance evaluated by permutation variable accuracy importance (PVAI) and the value was normalized to [0, 1] in proportion. The maximum values in each column were expressed in bold
| No. | rank | features | Bayes | BPNN | LDA | RF | SVM |
| 10 | 1 | OSd | 1 | 1 | 1 | 0.98 | 1 |
| 4 | 2 | ConRaSd | 0.73 | 0.84 | 0.42 | 1 | 0.7 |
| 3 | 3 | ConSm | 0.79 | 0.39 | 0.89 | 0.51 | 0.35 |
| 2 | 4 | Opm/Bpm | 0.36 | 0.55 | 0.18 | 0.52 | 0.38 |
| 5 | 5 | ConMax | 0.43 | 0.36 | 0.42 | 0.29 | 0.33 |
| 8 | 6 | BMe | 0.49 | 0.23 | 0.53 | 0.05 | 0.39 |
| 6 | 7 | C | 0.27 | 0.23 | 0.51 | 0.19 | 0.21 |
| 11 | 8 | GSd | 0.23 | 0.36 | 0 | 0.28 | 0 |
| 1 | 9 | P | 0.06 | 0.27 | 0.22 | 0.13 | 0.08 |
| 12 | 10 | BSd | 0.24 | 0.26 | 0.04 | 0.14 | 0.03 |
| 7 | 11 | N | 0 | 0.23 | 0.14 | 0.22 | 0.08 |
| 9 | 12 | S | 0.24 | 0 | 0.01 | 0.01 | 0.01 |
表选项
3 结论
本文使用了5种机器学习方法对格陵兰岛东岸冰山进行识别。基于Sentinel-1A SAR影像数据,采用3种特征标准化方法以及4095种特征组合,系统性地比较了所有的分类器-特征标准化方法-特征组合的方法流程,找到了用于冰山识别的最优方法流程,主要结论如下:
(1) 特征标准化方法:最稳定且表现最优的特征标准化方式为Z_score标准化,Max-min标准化方法在总体表现上甚至会比不进行标准化的特征数据更差一些,而对于SVM来说,不进行特征标准化产生的错误是严重的。同时,由于不同分类器偏好不同特征标准化方法,在冰山识别中应当根据分类器的类型来考虑特征标准化方法的选择。
(2) 特征重要性:在Z_score这一特征标准化方式下,10号特征OSd(样本像元值标准差)表现出了最高的重要性,同时4号特征ConRaSd(样本标准差与背景标准差的比值)以及3号特征ConSm(背景均值与样本梯度均值的比值)紧随其后,拥有较高的重要性,这两个特征为冰山识别的主要特征;而简单的几何特征N(样本像元数量)与S(样本长宽比)重要性较低,在以后冰山识别研究中应当谨慎选择。
(3) 最优算法:根据试验结果,随机森林(RF)在使用经Max-min标准化的2、3、4、6、7、11号特征数据,并且冰山查全率为52.5%~87.5%的情况下效果最好,此时非冰山查全率对应在96.8%~88.3%之间,且在各种组合下都具有较高的稳定性,可以作为SAR影像冰山识别的首选;而反向神经网络(BPNN)在使用经log函数标准化的1、3、4、6、7、12号特征数据,并且冰山查全率为87.5%~92.5%的情况下效果最好,此时非冰山查全率对应在88.3%~84.8%之间,但由于BPNN参数设置问题复杂,BPNN依然还有很大潜力,值得以后的研究者进行探索。
【引文格式】肖湘文, 沈校熠, 柯长青, 等. 基于Sentinel-1A数据的多种机器学习算法识别冰山的比较. 测绘学报,2020,49(4):509-521. DOI: 10.11947/j.AGCS.2020.20190174
精
彩
回
顾
彩
回
顾
资讯 | “80后”院士王家耀的9条青春启示
权威 | 专业 | 学术 | 前沿
微信、抖音小视频投稿邮箱 | song_qi_fan@163.com
进群请备注:姓名+单位+稿件编号
权威 | 专业 | 学术 | 前沿
微信、抖音小视频投稿邮箱 | song_qi_fan@163.com
进群请备注:姓名+单位+稿件编号
以上是关于论文推荐 | 肖湘文:基于Sentinel-1A数据的多种机器学习算法识别冰山的比较的主要内容,如果未能解决你的问题,请参考以下文章