使用Sentinel-1/-2Landsat-8及DEM组合数据进行机器学习分类表碛覆盖冰川 Posted 2021-04-20 山坡水文土壤前沿瞭望
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Sentinel-1/-2Landsat-8及DEM组合数据进行机器学习分类表碛覆盖冰川相关的知识,希望对你有一定的参考价值。
题目:
Machine-learning classification of debris-covered glaciers using a combination of Sentinel-1/-2 (SAR/optical), Landsat 8(thermal) and digital elevation data
作者:
Haireti Alifu (Shibaura Institute of Technology, Japan)
Jean-Francois Vuillaume (Japanese Agency for Marine- Earth Science and Technology, Japan)
Brian Alan Johnson (Institute for Global Environmental Strategies, Japan)
刊物/日期:
Geomorphology/26 July 2020
表碛的覆盖阻碍了如波段比值法等传统方法检测冰川的准确性. 本研究提出了一种新的基于机器学习分类器的冰川表碛分层映射的自动分类方法, 包括k-最近邻域法(KNN)、支持向量机(SVM)、梯度提升法(GB)、决策树(DT)、随机森林(RF)和多层感知器(MLP). 本文使用了包括合成孔径雷达数据(Sentinel-1)、多光谱数据(Sentinel-2)、热成像数据(Landsat-8)和数字高程模型数据(AW3D30)的多种数据组合来对比吉尔吉特(巴基斯坦)和克勒青河谷(中国)地区表碛覆盖冰川的提取精度. 结果显示使用所有数据组合(Sentinel、Landsat、ALOS)的RF算法提取的整体精度最高(97%), GB和SVM(径向基核函数)次之. 更重要的是, RF算法能快捷高效的提取表碛冰川且对于参数有更高的鲁棒性. GB算法与RF算法的表现类似, 但是整体精度要次于RF算法. 尽管SVM算法的速度较慢, 其精度仍位列第三. 本文使用的数据公开且全球覆盖的, 这意味着本文应用的方法可以推广至其他流域.
(1) 研究区及源数据
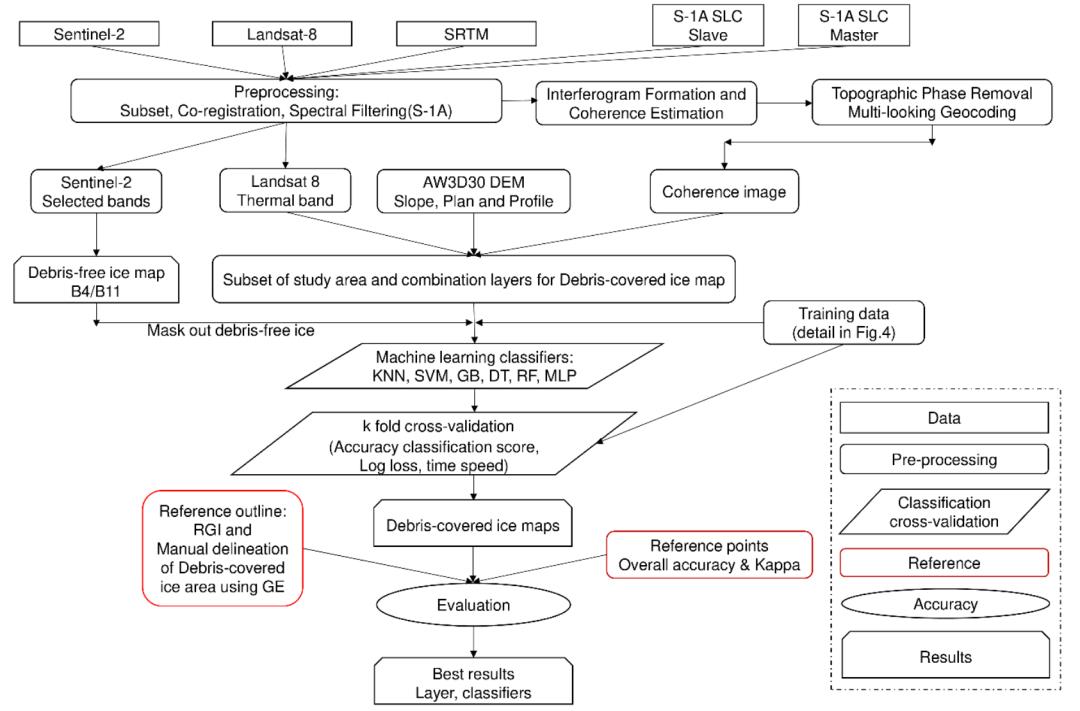
本文选取吉尔吉特(巴基斯坦)和克勒青河谷(中国)两处冰川作为研究区, 海拔高度分别在2300-7700m和3200m-8611m之间. 两处研究区的冰川覆盖面积分别为2000km²和1200km², 此两处分布有不同大小及坡度的冰川, 同时根据前任的研究, 此两处的冰川处于相对稳定或扩张状态, 因此需要一种自动的监测手段以快速提取表碛冰川的范围. 具体见图1.
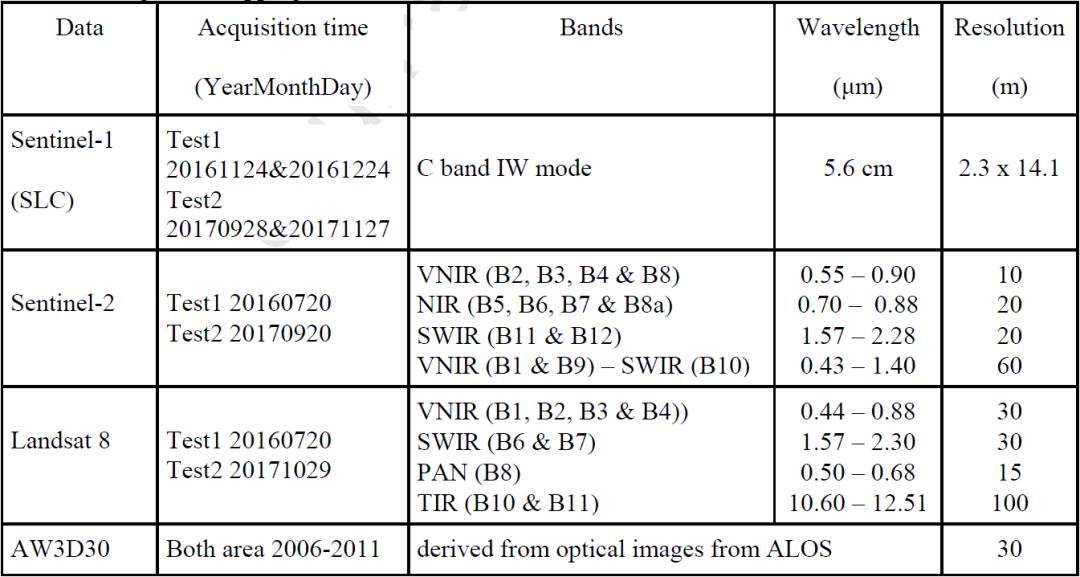
本文选取了光学影像(来自校正后的Sentinel-2A)、相干影像(来自Sentinel-1A单视IW模式SLC数据)、热红外影像(来自Landsat-8)和数字高程影像(来自AW3D 30m)作为源数据. 其中光学影像能够帮助监测表碛冰川及其周边的光谱差异, 热红外影像可以监测辐射温度差异, SAR相干影像可以监测冰川动态, 基于DEM衍生的地形特征可以确定冰川边界. 具体见表1.
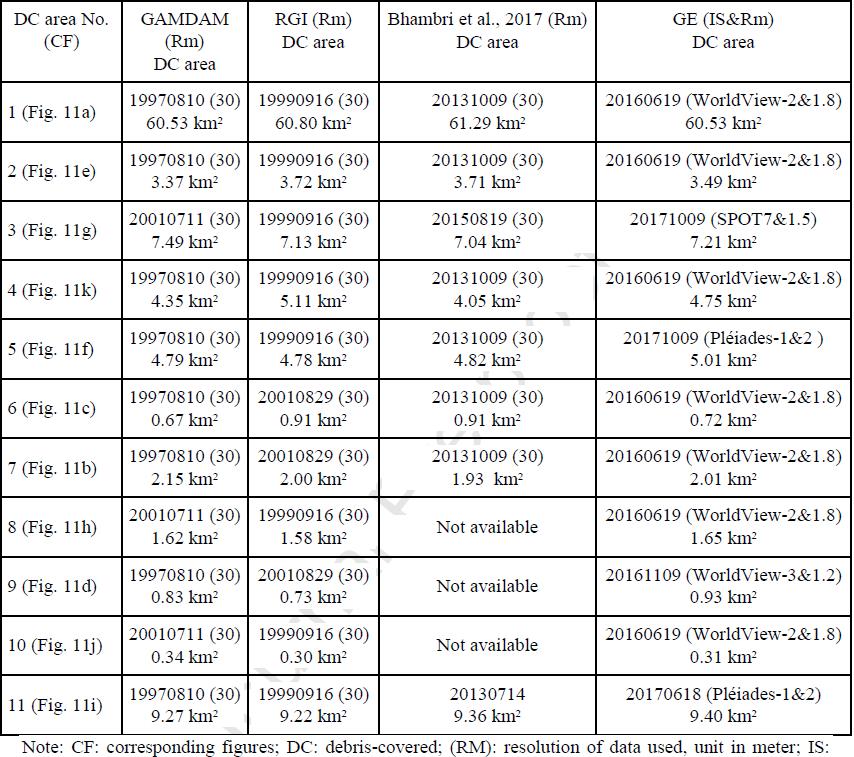
本文选取了伦道夫冰川编目(RGI 6.0)、亚洲山脉冰川流量绘图(GAM-DAM)及前人研究数据作为参照, 同时在Google Earth(GE)上目视解译了表碛冰川的范围. 具体见表2.
表2 参考数据表
本文应用多种机器学习分类器并对比其效果, 所选取的机器学习分类器为K-最邻近算法(KNN)、支持向量器(SVM)、决策树(DT)、梯度提升算法(GB)、随机森林(RF)和多层感知器(MLP).
a 重采样: 对Sentinel-2影像进行重采样至30m分辨率, 保证与Landsat-8和DEM数据一致;
b 配准: 进行不同传感器数据的配准, 保证配准误差在0.4个像素点以下;
c 相干处理: 使用一对Sentinel-1 VV极化SLC影像生成SAR相干影像;
d 地形指标提取: 基于AW3D DEM数据生成地形指标(GMPs);
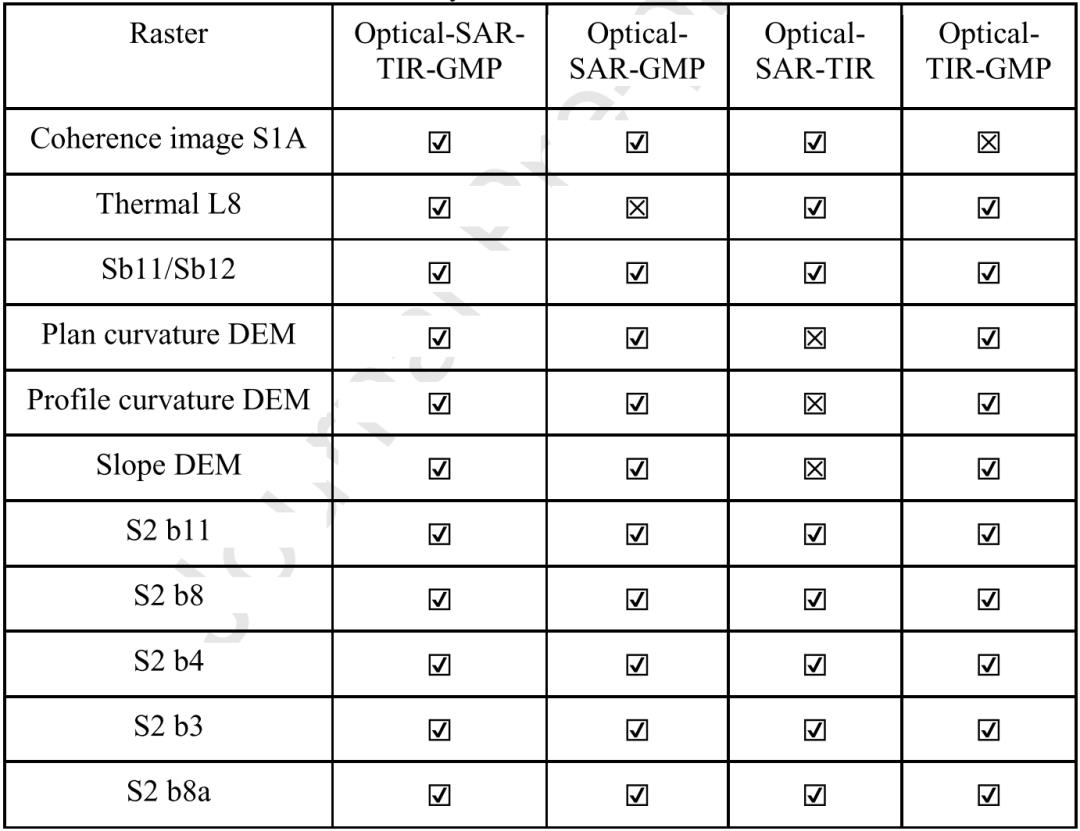
f 数据层生成: 生成不同数据组合的栅格数据层以检验不同数据对于表碛冰川提取的敏感性和准确性的影响.
表3 数据组合表
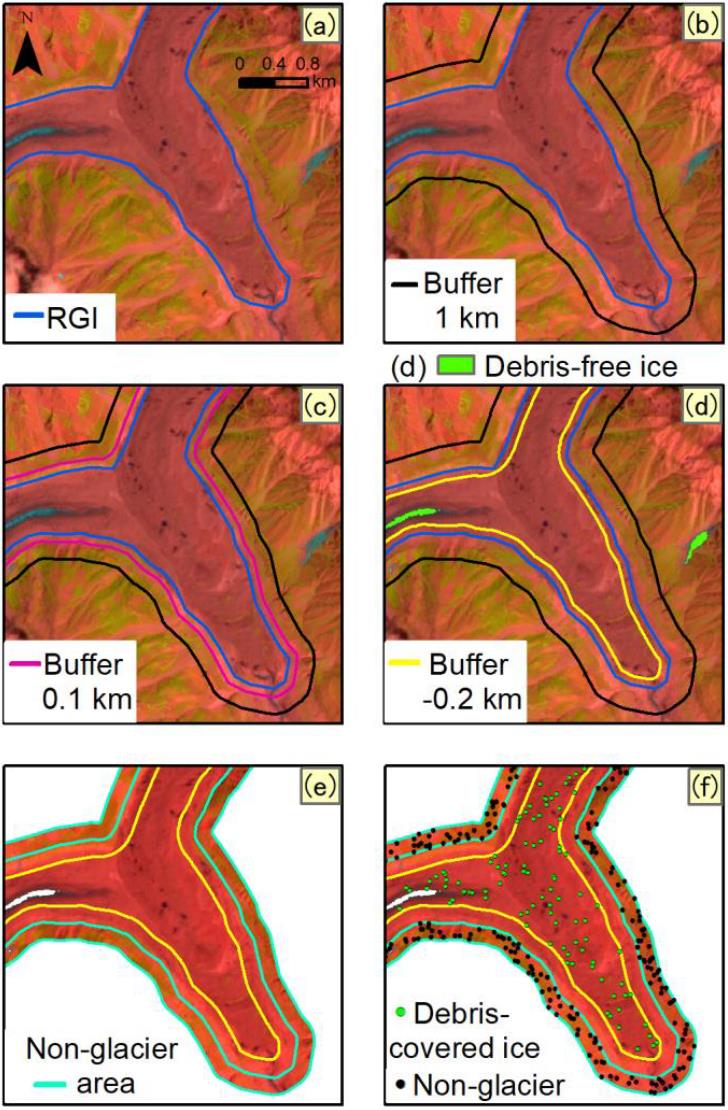
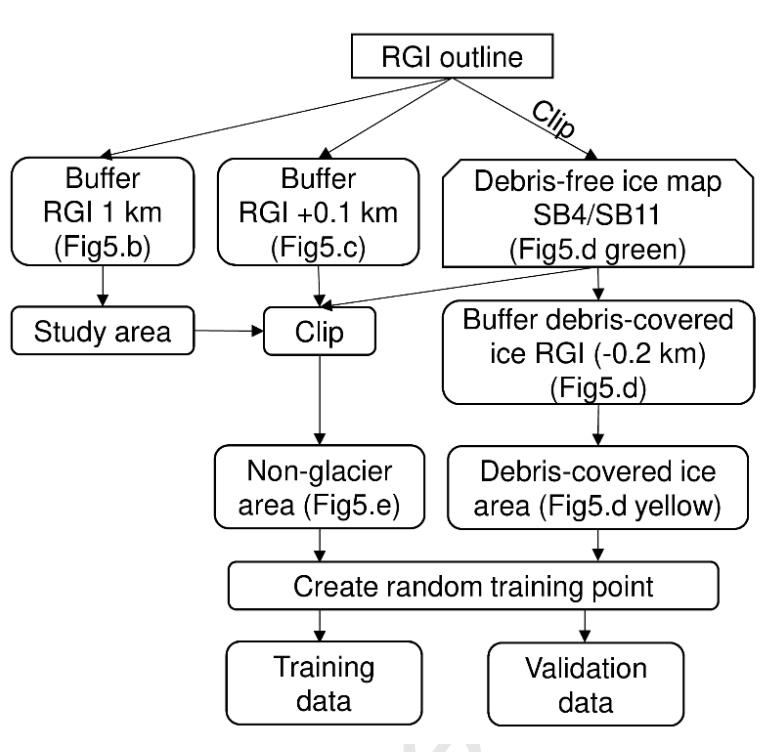
本文提出了一种自动生成训练数据的方法. 首先根据RGI轮廓线通过缓冲区生成表碛冰川和非表碛冰川的覆盖范围; 之后针对表碛冰川使用内部缓冲区(距离为200m), 针对非冰川区本文使用两种不同的外部缓冲区(距离为100和1000m)生成覆盖范围(见图3); 最后在研究区随机生成训练数据, 研究区1先生成2000个训练数据以验证不同数据组合的精度, 之后两研究区各生成20000个训练数据用以比较不同机器学习分类器的分类效果. 训练数据的生成流程具体见图4.
首先将训练数据进行标准化, 有助于提升解决最优化问题的精度; 之后为避免陷入局部最优问题, 将训练数据分为训练集(总样本的80%)和校正集(总样本的20%), 同时进行10折交叉验证获取精度最高的机器学习参数, 搜索范围见表4; 最终分类器使用训练精度最高的参数进行表碛冰川范围的提取.
表 4 机器学习分类器参数搜索表
本文为每个类别随机选择500个验证点(通过GE获取其实际类别)测算分类结果的整体精度. 同时选择11个分布有表碛冰川的参照区域进行对比, 分析不同机器学习分类器(训练数据为光学-SAR-热红外影像-GMP的组合)的提取精度.
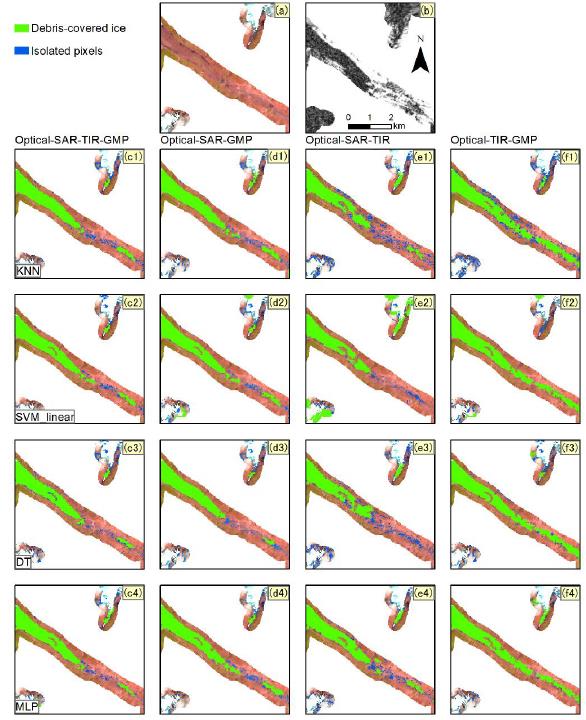
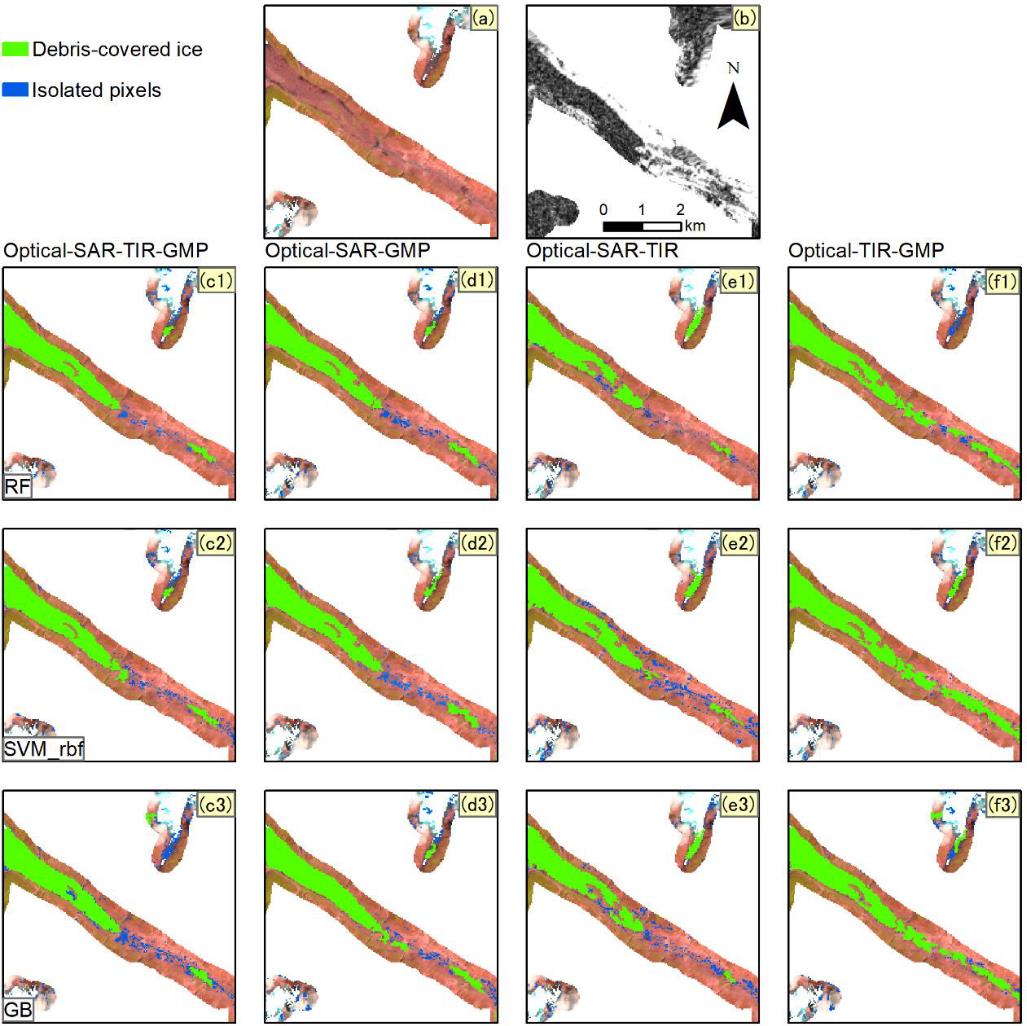
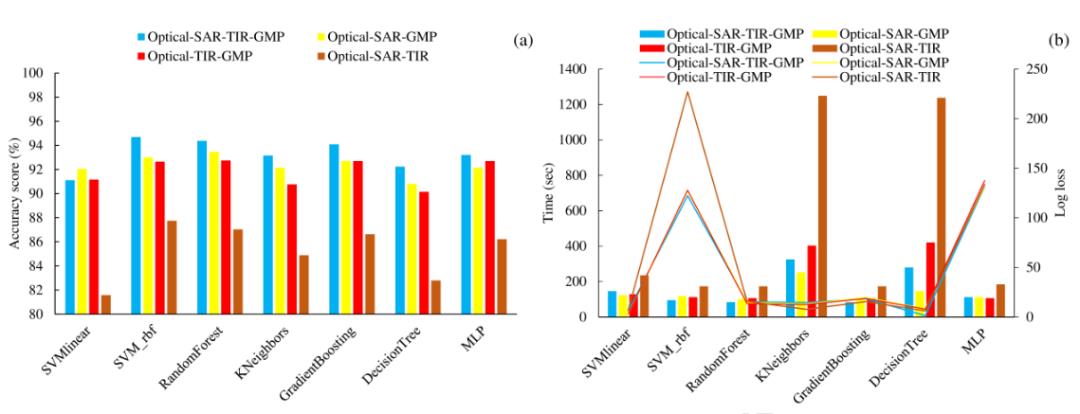
结果显示训练数据为光学-SAR-热红外影像-GMP数据的组合时, 分类器的精度最高. 对于分类器来说, 第二高的是光学-SAR-GMP数据组合, 然后是光学SAR-热红外影像的数据组合. 全数据组合的分类器在冰舌位置最准确地区分了表碛冰川和非冰川区域. 具体见图5和图6. 因此选择全数据组合作为训练数据以对比不同分类器的分类精度.
图 5 不同数据组合机器学习分类器提取结果对比图. 组图上部(a) Sentinel-2假彩色图; (b) Sentinel-1相干图.
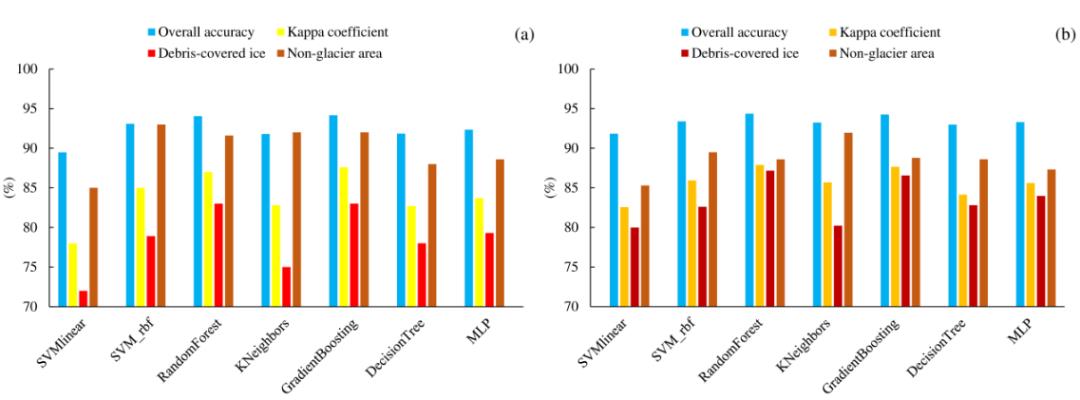
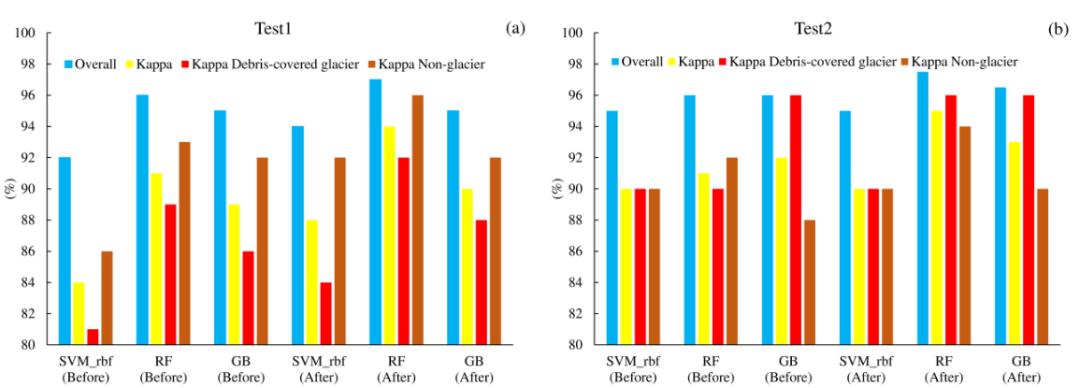
如图7和图8所示, RF、GB和SVM(径向基核函数)分类的精度最高, MLP、KNN、DT和SVM(线性基函数)随后. 训练点数目从2000提升至20000对RF分类精度提升最大, 为1-2%. 如图9所示, 对比发现RF、GB和SVM(径向基核函数)的分类结果与GE目视解译结果相近, 而与RGI数据有显著不同, 这是由于两者数据获取时间不同导致的.
图 7 2000全组合训练数据下不同分类器的分类精度. (a) (b)分别为去除孤立点前后的对比图
图 8 20000全组合训练数据下不同分类器在研究区1, 2的分类精度
通过交叉验证获取了各个分类器的最优参数, 如表5所示.
表 5 不同分类器最佳参数表
(1) 所有分类器都在全数据组合下获得了最高的分类精度表明多传感器数据融合对于表碛冰川识别是重要的. 同时也要注意训练数据的组合, 如不包含GMP数据的组合数据的分类精度低于其他组合数据的分类精度, 说明GMP在表碛冰川提取中占有重要位置, 不能用其他数据替代.
(2) 研究结果表明RF、GB和SVM(径向基核函数)的分类精度最优, 表明这三类分类器对于高维度训练数据的分析能力更强. 同时所有的分类器都存在不同程度的错误分类情况, 这可能是由于冰舌附近存在活跃的滞冰或缓慢移动的表碛层.
(3) 超参数直接影响分类器的性能, 因而通过交叉验证获取最优化的分类器参数.
Rastner, P., Bolch, T., Notarnicola, C., Paul, F., 2013. A comparison of pixel-and object-based glacier classification with optical satellite images. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens., 7(3), 853-862.
Watanachaturaporn, P., Arora, M.K., Varshney, P.K., 2008. Multisource Classification Using Support Vector Machines. Photogramm Eng. Rem. S., 74(2), 239-246.
Zhang, J., Jia, L., Menenti, M., Hu, G., 2019. Glacier Facies Mapping Using a Machine-Learning Algorithm: The Parlung Zangbo Basin Case Study. Remote Sens., 11(4), 452.
以上是关于使用Sentinel-1/-2Landsat-8及DEM组合数据进行机器学习分类表碛覆盖冰川的主要内容,如果未能解决你的问题,请参考以下文章