视野 | Hadoop技术在商业智能BI中的应用探究
Posted 心网微杂志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视野 | Hadoop技术在商业智能BI中的应用探究相关的知识,希望对你有一定的参考价值。
在这个“大数据”概念满天飞的时代,每个行业都以此为噱头。到底大数据技术能做什么?能给银行业带来哪些新应用?在看过很多讲座、分析文章和教程之后,怀着好奇的心态,决定先撸起袖子试试。Hadoop技术的应用范围很广泛,从数据分析到机器学习等等,由于笔者日常工作涉及到商业智能BI等方面,便从这方面探究一下。
首先谈一下Hadoop到底是什么。Hadoop并非一个软件,而是Apache的一个开源项目名称,核心部分包括HDFS及MapReduce,现在这个单词更多代表的是一个不断成长的生态系统。其中,HDFS是分布式文件系统,MapReduce是分布式计算引擎。时至今日,Hadoop在技术上已经得到验证、认可甚至到了成熟期,同时也衍生出了一个庞大的生态圈,比较知名的包括HBase、Hive、Spark等。HBase是基于HDFS的分布式列式数据库,HIVE是一个基于HBase数据仓库系统。Impala为存储在HDFS和HBase中的数据提供了实时SQL查询功能,基于HIVE服务,并可共享HIVE的元数据。Spark是一个类似MapReduce的并行计算框架,也提供了类似的HIVE的Spark SQL查询接口。Hadoop生态圈的工具组件多如牛毛,版本混乱,相互间又存在很多功能重叠,以上仅是本文用到的部分组件。
Hadoop是完全开源的项目,但同时也有Cloudera、Hortonworks以及国内华为等厂商的商业发行版本,有点类似Linux系统各商业发行版本的形式。为了相互对比,笔者对原生Hadoop以及部分发行版进行了试用。
Hadoop依赖于JAVA及Linux环境,受资源所限,笔者只能用家里台式电脑安装VMware虚拟机来完成部署,操作系统采用了CentOS。原生版本的Hadoop安装比较简单,从Apache官网下载压缩包,解压缩后参照官方文档修改几个XML配置文件,调用Shell脚本即可完成启动,HBase、HIVE等组件的安装方法也大同小易。但在集群部署时,涉及众多组件及服务器,需配置多个XML文件,且由于各组件版本分支众多,版本间存在冲突,导致配置及维护难度较大。商业发行版如Cloudera公司的CDH,对Hadoop的部分常用组件进行了集成,提供了集群监控管理等功能,极大简化了安装流程,在大规模集群部署时非常方便。Hortonworks公司的HDP也是类似于CDH的一个产品,区别只是HDP是免费,而CDH同时提供免费及付费版本,所采用的部分组件与CDH不同,例如,用Ambari替代了CDH采用的Hue,Spark SQL替代了Impala等等。安装细节由于篇幅限制不多叙述,下面是CDH截图:
总体来说,CDH提供的功能比HDP更强大一些,包括集群机器监控、管理等功能,但消耗的资源也最大,HDP次之。对于开发测试,使用原生Hadoop比较轻便。如果是生产系统,采用一个成熟的商业发行版能减少大量的维护工作,文章下述操作均基于CDH。
商业智能BI(BusinessIntelligence),是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策。以上是百度的官方解释,对于银行来说,实际的应用有各类报表系统、经营决策系统、分析系统等等。商业智能系统的架构主要包括数据层、业务层、应用层三部分。数据层基本上是ETL(抽取extract、转换transform及加载load)过程,业务层主要是OLAP(联机分析)和数据挖掘的过程。在应用层里主要包括数据的展示,结果分析和性能分析等过程。
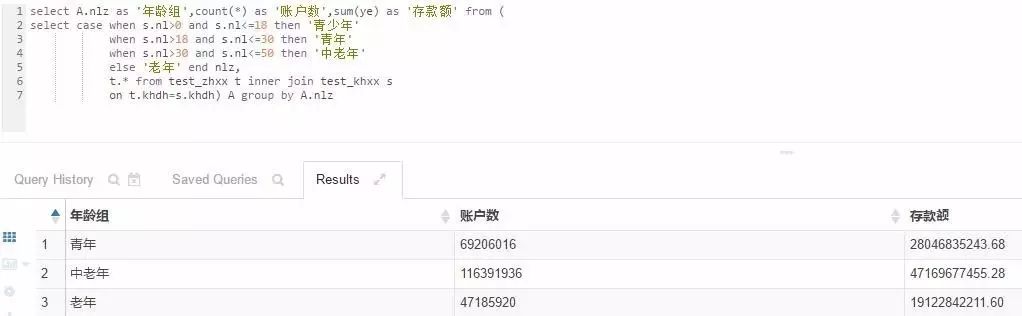
对于数据层及业务层,传统上我们使用关系型数据库(Oracle, mysql等)+ETL工具(Datastage)的方式。在Hadoop技术下,可以用HIVE、Impala、Spark等开源组件来完成上述功能。对于数据的采集、导入等操作,Hadoop提供了非常多的工具:例如,Flume可以采集日志文件中数据并导入到HDFS中,Sqoop可以在HIVE与关系型数据库间进行数据传递,Shell命令行可将文本文件导入HDFS中。对于数据的查询、分析,以上组件均提供了各自的SQL查询语言,JDBC接口等,使用方法类似传统关系型数据库。为做测试,在HIVE中用下图的语句新建了一个账户及客户表:


账户表test_zhxx中包含了账号、客户代号、余额等字段,客户表test_khxx中包含客户代号、客户名称、年龄等信息。为验证性能,采用HIVE的JDBC驱动,使用Java编写程序向表中批量插入超过两亿条数据。在HIVE及Impala中进行单条查询、汇总、关联等操作,均能在数秒至数分钟内返回结果。相比较,Impala查询速度比HIVE快很多。因为HIVE是将SQL分解为MapReduce任务执行,而Impala及Spark则是在内存中计算。根据Apache官网介绍,Impala的查询速度远超Spark SQL及HIVE。Hive适合于长时间的批处理查询分析,内存占用小,可替代传统ETL工具;而Impala适合于实时交互式SQL查询,内存占用大。实际应用可以先使用Hive进行数据转换处理(ETL),之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。以下截图是使用Impala在两亿条测试数据中进行客户账户数及存款额的统计,耗时约3分钟:
这是一台普通PC机中虚拟机所取得的性能,实属不易。当前银行各类系统的历史数据查询、交易流水整合、大表查询等操作完全有可能从关系型数据库中迁移到Hadoop平台下,既能提升效率和可靠性,又能降低成本及数据库负载。需要注意的是,虽然HIVE、Impala可以使用SQL来查询数据,但是与关系型数据库有本质不同,所查询的数据实际是以文件方式存储于HDFS上,没有事物管理,没有update、delete操作,因此Hadoop技术更适合于OLAP应用而非OLTP应用。
对于应用层,一些开源报表工具如Pentaho、SpagoBI等已经支持接入HIVE、Imapla。
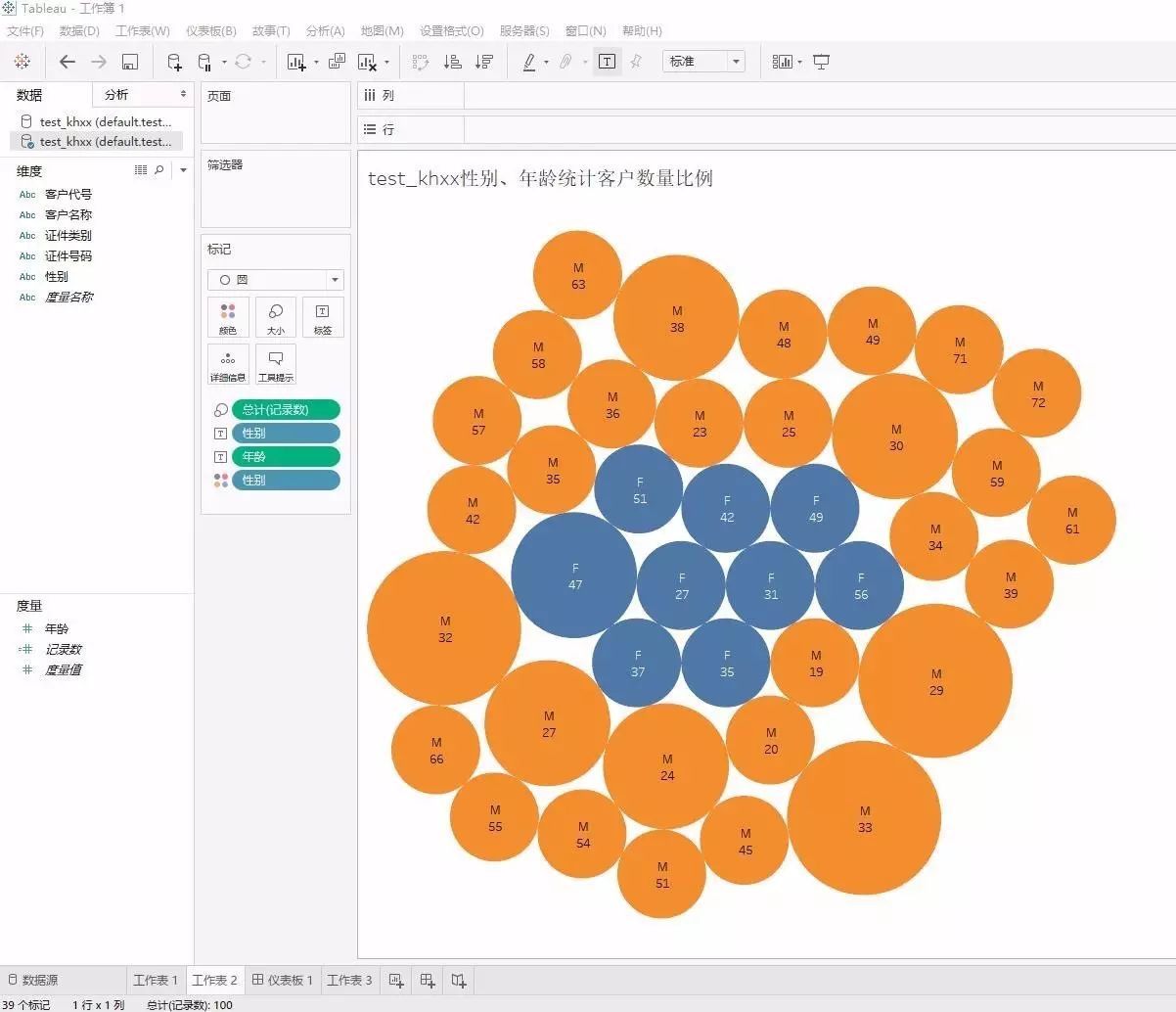
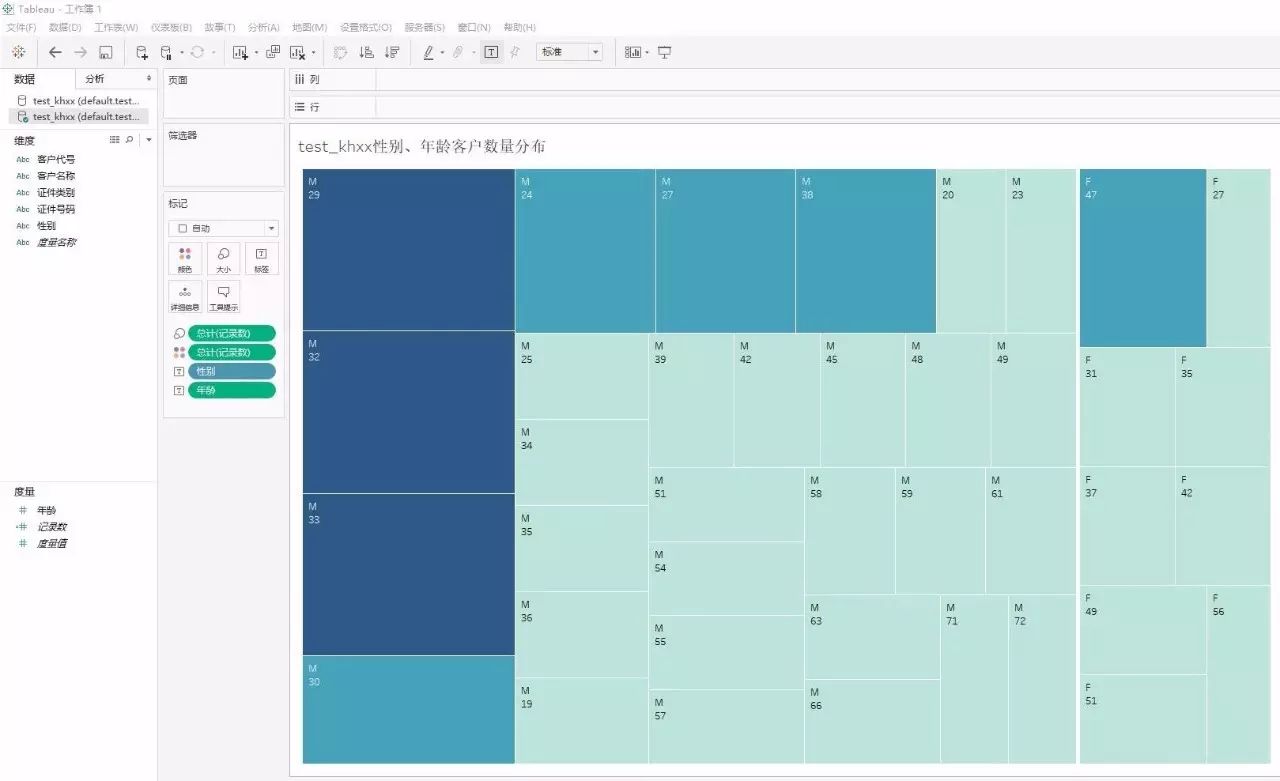
对于我行现有基于Cognos等报表工具的应用,则需要对Cognos软件进行升级。根据IBM官网的介绍,最新版的Cognos已经支持与Hadoop平台连接。对于现有大部分使用JDBC方式连接Oracle等关系数据库的Web应用,若要接入Hadoop平台,需要修改代码,使用HIVE、Impala的专用JDBC驱动,并对查询SQL做部分语法微调即可。考虑到虚拟机资源不足以部署Cognos等软件,采用了当前较流行的一款数据分析及可视化软件Tableau来做测试。Tableau是一款轻量化的软件,支持接入Hive及Impala作为数据源,可安装于Windows系统下,通过简单拖拽等方式即可生成各类图表,从而实现对数据的多维分析。下图为使用Tableau软件对上一节建立的客户表test_khxx进行可视化分析,按照客户的性别、年龄两个维度分析客户数量的分布,从图中可直观看出年龄为32、33岁的男性客户占比最大:
在Hadoop技术下,我们未来可以实现对数据的深层次挖掘、业务部门自主用数等需求。Hadoop技术的强大之处不仅存在于处理结构化数据,还在于非结构化的处理能力,同时具备流数据、实时数据处理能力、机器学习等传统数据库无法完成的功能。Hadoop的另一个独特之处是:所有功能都是分布式的,包括以上使用到的HIVE、Impala等,而非传统数据库的集中式系统。这种架构在保证了高可用性的前提下,也提供了高拓展性。当存储、性能等方面遇到瓶颈,可以通过简单地拓展更多节点以满足。
以上仅是笔者在学习过程中的一点感悟,写出来与大家分享,也期望得到大家的批评指正。Hadoop技术包括的范围实在很大,商业智能BI只是Hadoop技术应用的冰山一角,更多更广阔的应用前景需要我们一起去探索!Hadoop技术对于开发人员来说是一种解放,工作重心不再是优化优化再优化,以满足不断增长的资源压力,而可以更多地关注新技术、新算法,从满足业务需求升级到引领业务发展。
以上是关于视野 | Hadoop技术在商业智能BI中的应用探究的主要内容,如果未能解决你的问题,请参考以下文章
4月27日专业知识分享会:商业智能技术应用(BI)- 2 CPD Hours
当“资讯机器人”遇上“商业智能”,当“AI”遇上“BI”会有怎样的火花?