商业智能与大数据驱动商业增长背后的技术原理
Posted 同程艺龙技术中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了商业智能与大数据驱动商业增长背后的技术原理相关的知识,希望对你有一定的参考价值。
随着移动互联时代到来,在线购票已成为景点门票销售的主要途径。截止2016年12月,在OTA可售电子票的景区中,在线支付和景区支付比例分别为94.8%和5.2%。景点门票也是同程旅游的一项重要业务,如下图所示:
一般的用户消费过程是从入口进入页面,浏览感兴趣的产品,直至支付完成。而推荐可以给用户提供感兴趣的内容,帮助用户快速方便的找到所求。因此,打造一个高精准性、高丰富度且让用户感到惊喜的推荐系统是我们的迫切需求。
与传统的商品推荐不同,旅游场景中的用户兴趣点很难确定,而且会随着季节、天气、用户属性、景点属性等变化而变化。通过数据分析和业务知识可知,景点的推荐主要有以下几点挑战:
1, 数据稀疏。旅游景点的购买频次不高,订单数据过于稀疏,使用user-based协同过滤的推荐效果不好。
2, 季节性明显。旅游景点季节性明显冬季温泉、滑雪,夏季水上乐园,使用iterm-based协同过滤会有很大的Bias。
3, 本异地差异大。本地和异地出游人对景点的兴趣不一样。比如北京,异地用户推荐故宫、长城更符合需求,但北京本地人推荐欢乐谷、野生动物园更合适。
4, 城市差异。用户的兴趣会随着浏览城市变化,比如选择苏州则可能对园林感兴趣,选择海南则可能对海岛,沙滩感兴趣。所以城市切换可能意味着兴趣点的变化。另外,如果能命中用户感兴趣的城市是一个很好的用户体验。
推荐框架
先从整体看我们的推荐框架,可以分为离线层和在线层。
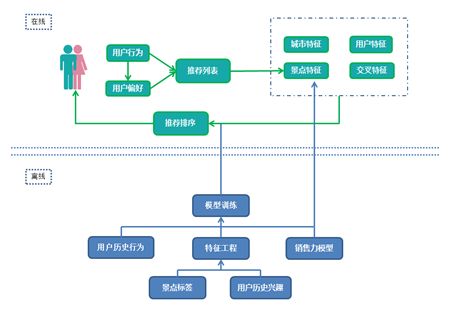
离线层:包括数据清洗,景点标签清洗,特征提取处理,模型训练等等,主要是给线上预测提供数据和算法。
在线层:主要是收集用户的实时行为轨迹,推测用户的景点类型偏好,然后结合用户历史偏好得到推荐候选集,结合景点销售得分候选集,融合后用算法对候选集打分重排。
为了提高线上运行速度,我们优化了特征获取机制。大数据量的特征,如用户特征,数据存储在ElasticSearch中,线上实时查询ElasticSearch。小数据量的特征,如城市特征,我们直接将数据广播到节点,这样 Task 就可以在本地查表了,减少了数据库交互和网络传输时间。经过这样的优化我们的计算整体耗时控制在100ms以内。
从推荐框架上可以看到,推荐系统能根据用户的实时行为改变推荐列表,从而保证推荐的列表是用户最感兴趣的。
模型构建
协同过滤
如前文所述,景点的购买频率比较低。使用半年内的创建订单,发现70%以上的用户只有一个订单。下面的是我们用订单数据做iterm-based协同过滤和隐语义模型(LFM)的结果,在TOP10推荐下的准确率、召回率。
模型 |
准确率(Precise) |
召回率(Recall) |
iterm-based |
0.45% |
17.07% |
LFM |
0.0263% |
4.68% |
由于购买频次太低,矩阵过于稀疏,使用LFM效果也不好。即便使用用户的行为数据填充了矩阵,TOP10的推荐结果甚至比iterm-based协同过滤还差。所以单纯使用协同过滤算法是不太合适的。
CTR预估
CTR预估(Click-Through Rate Prediction)是互联网计算广告中的关键环节,它使用用户特征和广告特征做计算,筛选出最可能被用户点击的广告。
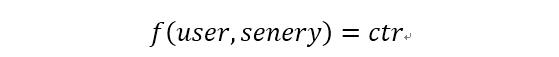
这个思路也可以用于推荐,使用用户特征和候选景点的特征及其他。计算用户对待推荐景点的点击概率,然后展示给用户点击概率靠前的景点。
CTR预估中用的最多的模型是LR(LogisticRegression),LR模型中的特征组合很关键,需要大量特征工程预先分析出有效的特征、特征组合,从而去间接增强LR的非线性学习能力。GBDT(Gradient Boost Decision Tree)是一种常用的非线性模型,它基于集成学习中的boosting思想,每次迭代都在减少残差的梯度方向新建立一颗决策树,迭代多少次就会生成多少颗决策树。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合。决策树的路径可以直接作为LR输入特征使用,省去了人工寻找特征、特征组合的步骤。
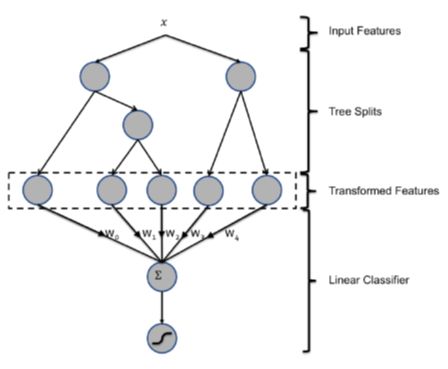
使用GBDT+LR模型结构如图,x为一条输入样本,遍历GBDT树后,x样本分别落到GBDT树的叶子节点上,每个叶子节点对应LR一维特征,通过遍历树,就得到了该样本对应的所有LR特征,然后LR输出预测概率值得到结果。
候选集
线上应用时为了减少计算量,需要对景点做筛选,选择可能是用户感兴趣的景点。同时也可以提高召回率。
一般来说在一个城市中TOP10的热门的景点销量能占到90%以上。因此,销量是景点推荐很重要的因素。但单纯使用热销会降低推荐覆盖度,好的推荐系统应该有很好的长尾发掘能力。为此,我们没有直接使用销量,而是把销量结合景点的特征,给每个景点一个销量得分。销量得分还需要乘以景点的本地异地购买率。这样,那些不热销的景点如果比较优质也会得到一个较高的销量得分,而且能避免热销的产品得到过高的销量得分。取销量得分靠前的TOP n个景点作为候选集1。
用户的行为是用户兴趣的直接体现,我们根据用户的实时行为轨迹,使用指数冷却算法得到用户对景点的兴趣得分。指数冷却算法的一般形式为:
本期得分 =上一期得分 x exp(-(冷却系数) x 间隔时间)
通过对景点打标签和归类,可以从用户对景点的行为历史中提炼出用户对某个类别景点的爱好。比如,有的用户偏爱古镇,有的偏爱山岳等等。
根据用户有行为的景点和偏爱的景点类别,得到新的候选集2。候选集1反应的是景点的热门程度,候选集2反应的是用户的行为和偏好。由于候选集2和景点销量关系不大,这样保证了这样的候选集有较好的长尾发掘能力,每天推荐的景点有70%以上的覆盖度。
特征选择
1, 景点特征:景点特征反应的是景点的一些固有属性,一般变动不大,也不需要太多的数据处理
2, 用户特征:用户特征包括用户的行为、偏好,还有消费习惯,以及用户的基本信息等
3, 城市特征:加入这个特征是因为上面提到,不同的城市可能反应了用户的兴趣爱好,城市本身有一些固有的景点属性。
4, 交叉特征:针对景点的本异地差异,我们针对每一个景点计算了本异地购买率。判断用户常驻地与推荐城市是否一致,将本异地购买率与景点特征做交叉
选择特征后需要对特征做一些处理,包括归一化:
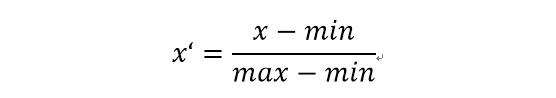
max是特征中的最大值,min是最小值。
特征离散、合并:一些连续特征做分段离散,比如城市,存储的是整数值,但城市本不应该是连续值,因此按照一线,二线,三线城市的等级划分将城市做离散化。
特征筛选:原始特征可能存在分布不均的情况,特别是分类特征,可能大部分特征是1或者0。还有一些入选的特征可能并不重要,对结果影响很小。针对这样的情况,做GBDT训练的时候我们会输出各个特征的重要性。在R的gbm包relative.influence函数能输出每个特征的重要性,它的原理是计算每棵树每次分割带来的信息增益/降低错误率。剔除掉一些不重要的特征后重新训练模型,观察模型表现。
特征噪声剔除:如果两条同样的特征数据,却有着不同label,一条标记的是1,另一个标记的是0。这样的数据会被剔除。
由于原始的特征要输入GBDT中,GBDT会做特征间的交叉,所以特征一般不用做过多人工交叉或者其他处理。
使用上述特征,把用户点击数据作为正样本,展示但未点击的数据作为负样本,对数据欠采样尽量平衡正负样本,用GBDT+LR模型训练。训练效果入下:
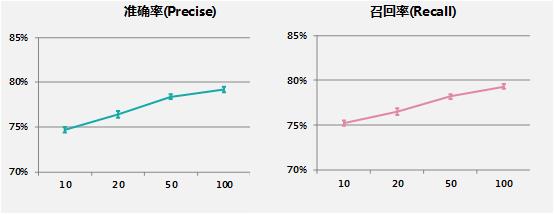
选用较低的树深度且增加树的数量可以防止过拟合,提高模型的泛化能力。固定每棵树深度为3,图中横坐标是树的数量,纵坐标为准确率、召回率。可以看到使用更多的GBDT树会得到更好的分类效果,但是考虑到线上应用的可行性。100棵树、树深度3准确率为79.2%,召回率为79.3%,是比较理想的参数。
推荐效果
先从一开始提出的4个挑战点来看。针对1,2两点采用了CTR预估的方法避免了问题的出现。针对3,4两点加入了相关的特征——景点本地异地购买率、城市特征。让我们从实际推荐的结果来看,同样是苏州的景点:
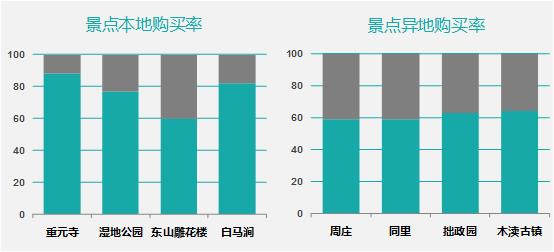
左边的图是对本地用户的推荐结果,这些景点的本地用户购买率比较高。重元寺本地购买率88%,湿地公园77%,雕花楼60%,后面还有白马涧82%等等。
右图是异地用户的推荐结果,异地用户购买率较高。周庄异地购买率59%,同里59%,拙政园63%,还有木渎古镇64%等等。
再看切换城市后,同一个用户从苏州切换到杭州,推荐靠前的的不再是古镇人文相关的景点。而是自然风光类的景点。
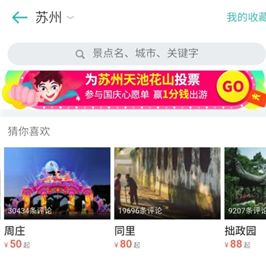
从实际推荐的效果上来看,加入特征后确实解决了本地异地和城市切换的推荐问题。
对于公司来说评价一个推荐系统的好坏,指标可能并不是准确率召回率,而是转化率(订单/UV)。换言之,这个推荐系统能新带来多少订单,增加多少营收。下图是转化率的对比:
横坐标是星期,可以看到不论在工作日还是周末,推荐的转化率相比整体来说都有提升。转化率平均提升了1.6%。相当于1000个uv,推荐能增加16个订单。
总结
我们的推荐系统核心是一个推荐列表的重排序。排序是一个非常经典的机器学习问题,实现模型的记忆和泛化功能也是推荐系统中的一个挑战。面对景点推荐数据和场景的特殊性,我们选用了CTR预估的方法并加入了场景相关的特征。解决了一开始提出的4个问题,但仍有待改进的地方。
更多的数据采集和加工。1,用户搜索的数据,搜索数据没有加入到这一版推荐,主要原因是数据收集达不到使用要求。2,标签数据进一步完善,包括景点和用户标签,除了完善事实标签还需要增加场景标签,比如周末出游,亲子出游等。
数据利用还不够。比如,这一版的推荐没有考虑用户的经纬度位置,推荐出景点的地理位置比较离散。苏州的景点可能会同时推荐市内的苏州乐园和张家港的暨阳湖欢乐世界,后面可以使用用户的经纬度位置做优化。
场景考虑还不充分。比如,用户不在常驻地是商旅还是度假出行。还有,用户出行场景可能是亲子,结伴或者独自出游等等。
算法还有待优化。GBDT虽然能有效做特征交叉,但是过多的分类特征可能会引起Bias。因此,可以尝试Deep & wide的推荐算法。结合深度网络来发掘特征间的非线性交叉。Deep & wide的深度神经网络模型一般参数和特征都非常多,特征抽取的效率和线上计算的实时性都有很大的挑战性,考虑做模型压缩改善这种情况。
以数据为基础,用算法去雕琢,只有将二者有机结合,才会带来效果的提升。推荐是大数据应用的一个重要方向,但数据应用不仅仅只有推荐。各种机器学习算法以及深度网络,自然语言处理、图像处理等技术结合业务的场景能做出更多有用的智能化应用。
以上是关于商业智能与大数据驱动商业增长背后的技术原理的主要内容,如果未能解决你的问题,请参考以下文章