深度学习Caffe | 多标签训练的三种策略
Posted yuanCruise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Caffe | 多标签训练的三种策略相关的知识,希望对你有一定的参考价值。


01
多标签问题
在很多深度学习任务中会用到多标签学习,比如做目标检测任务,如下图所示,图片1中物体类别为1,剩余的四个为其位置坐标。图片2中物体类别为2,剩余的四个为其位置坐标。所以即使一张图片中只有一个目标但其仍然是多标签学习问题。

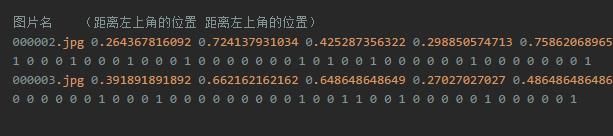
还有一种多标签问题是利用人脸的某些特性来辅助人脸特征点定位(双眼,鼻子,两个嘴角一共五个特征点)。如下图中的标签解释:第一个字段为图片名,第2,3个字段为第一个特征点的位置,以此类推后边8个字段分别为剩余4个特征点的位置(距离左上角的百分比)。后续的字段为是否戴帽子等等特性,每一列代表了一种特性,是为1不是为0。这也是一种多标签学习问题。
02
利用HDF5文件实现多标签制作训练
1
利用python生成hdf5文件
在Caffe中,如果使用LMDB数据格式的话,默认是只支持“图像+整数单标签”这种形式的数据的。如果训练网络需要一些如第一部分中介绍的其他形式的数据或标签(如浮点数据,多标签等等),可以将其制作成HDF5格式。当然万物都有其内在的规律,此消彼长,所以HDF5数据格式虽然比较灵活,但缺点是占用空间较大。
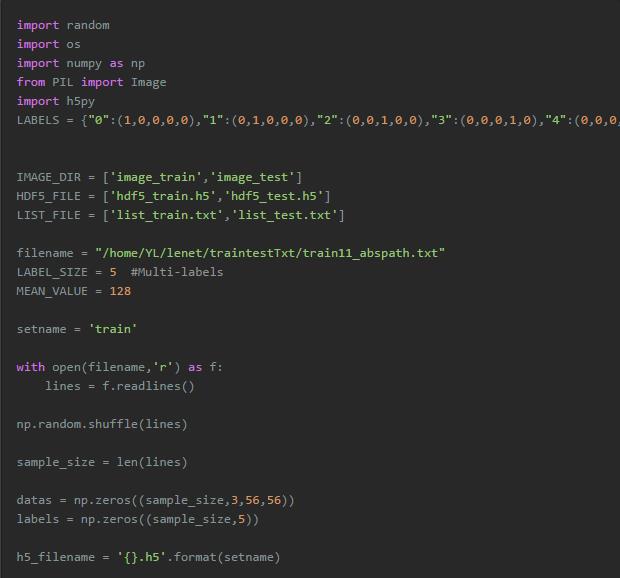
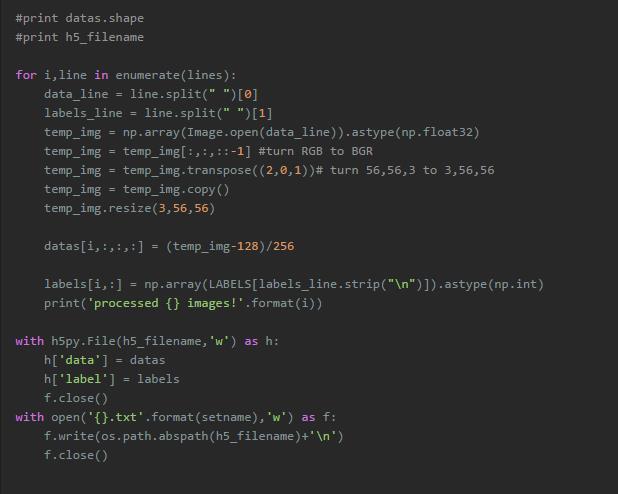
下面的代码是利用python实现hdf5文件的制作。需要注意的是下边的代码仅仅是一种展示如何用python制作h5py文件,并没有严格按照第一部分中介绍的多标签形式来操作。
2
利用hdf5进行训练
正如上面提到过的,DHF5文件往往容量比较大,而且caffe导入单个HDF5文件大小有限制,因此当我们的训练数据较多的时候,往往需要将数据分别写入多个HDF5文件中,并把这多个HDF5文件的路径存放到同一个train.txt中。具体执行如下:
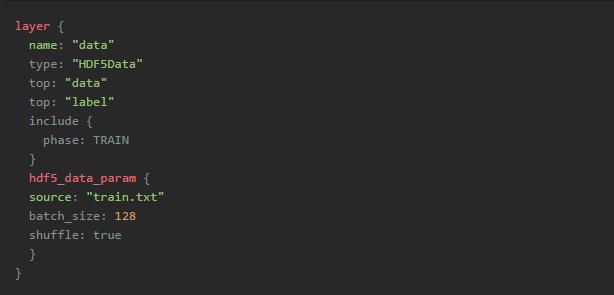
还需要注意,shuffle是对H5文件进行乱序,而每个H5文件内部的顺序不动。由于可能存在多个HDF5文件,所以HDF5Data的输入是从一个TXT文件读取的列表,train.txt内容示例如下:

03
利用LMDB结合HDF5实现多标签制作训练
正如上述提到的HDF5文件的缺点是占用空间较大。而caffe对于单个HDF5文件的大小是有限制的,虽然可以通过上述方法的txt文件解决,但是利用HDF5做多标签时很占用空间。 因此还有一种策略为:将图像文件存为LMDB格式,快速且节省空间;将标签文件存为HDF5格式。并且最终在网络定义Prototxt文件中,同时使用Data层和HDF5层。
1
图像文件LMDB
将图像文件存为LMDB就不多做解释了,详细观看下述两篇文章。
深度学习Caffe | 你的第一个分类网络之数据准备
深度学习Caffe | 你的第一个分类网络之Caffe训练
2
标签文件HDF5
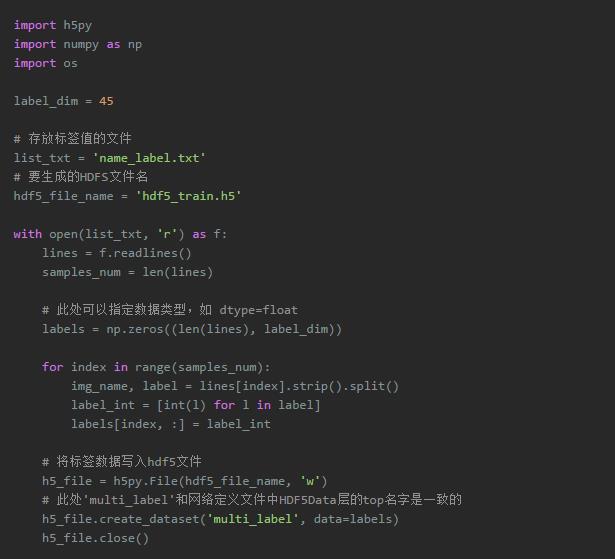
其中,name_label.txt存放了图像名称和标签,当然这里我们只需要读取其中的标签。这样的话,hdf5_train.h5里面就储存了所有图像对应的标签,每个标签包含多个0或1的值。需要注意的是,在制作图像数据LMDB文件时候的name.txt中的文件名一定要和name_label.txt中标签一一对应。
3
利用LMDB和HDF5进行训练
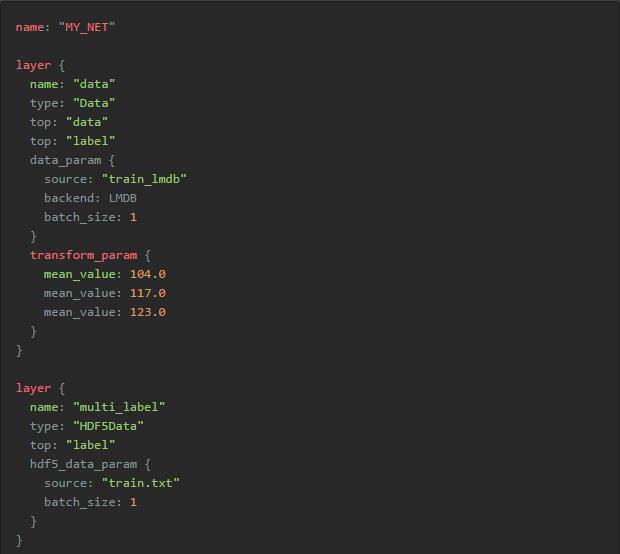
train.txt内容示例如下:
04
利用LMDB文件实现多标签制作训练
其实不论是第一种利用HDF5结合Slice标签的策略,亦或是第二种LMDB结合HDF5实现多标签的策略,都存在局限性。 因此还有第三种更方便但执行起来会有点麻烦的方法,那就是直接修改caffe网络源码使其满足多标签的输入。
1
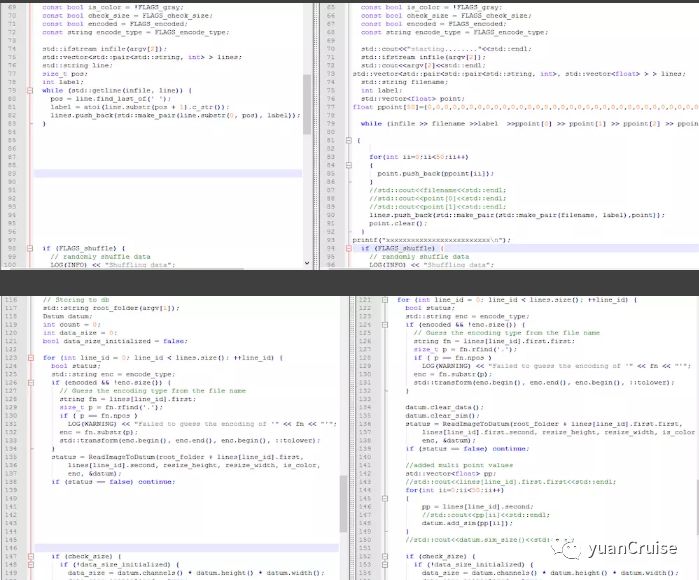
修改convert_imageset
就是一些宏的定义,这里不首先功能,当然这里的具体实现要看你所添加的新层所对应的功能。
2
修改caffe.proto

3
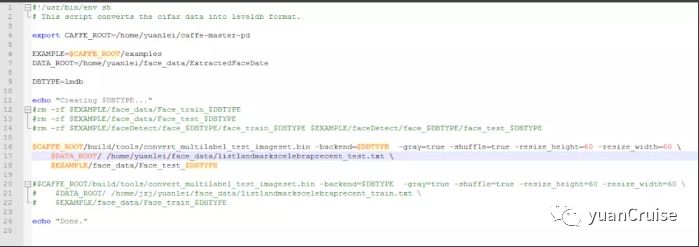
利用sh文件生成LMDB
4
利用LMDB进行训练
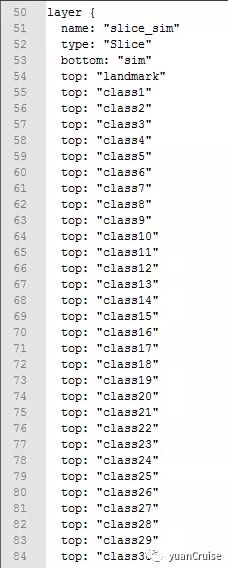
需要注意的是利用sim输出后,需要用Slice层将多标签进行切分。

各个文件源码请点击原文查阅!


人生苦短,怎能只会Python?!
微信扫描二维码关注
以上是关于深度学习Caffe | 多标签训练的三种策略的主要内容,如果未能解决你的问题,请参考以下文章