深度学习需要多强的数学基础?
Posted 雷课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习需要多强的数学基础?相关的知识,希望对你有一定的参考价值。

打开深度学习, 对于大部分小白, 编程已然令人生畏, 而更加令人难以接受的,那么,深度学习里的数学到底难在哪里? 寻常人等又有如何路径走通, 请听我慢慢解析。
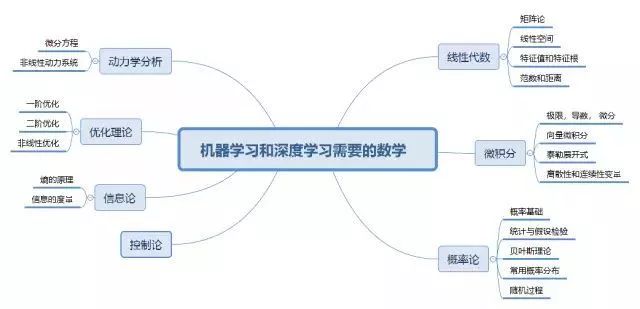

线性代数:

想要学习深度学习, 你第一个需要理解透彻的学问是线性代数。 为什么? 因为深度学习的根本思想就是把任何事物转化成高维空间的向量, 强大无比的神经网络, 说来归齐就是无数的矩阵运算和简单的非线性变换的结合。 这样把图像啊, 声音啊这类的原始数据一层层转化为我们数学上说的向量。
什么image to vector, word to vector 这些, 都在说的一件事情就是这类数学转化, 不同类型(我们通常称为非结构化数据)的数据最终成为数学上不可区分的高维空间的向量,所谓万类归宗。 线性代数,就是对于这一类高维空间运算做的默认操作模式,可谓上帝的魔术之手。

因此你要驾驶深度学习这个跑车, 线性代数关系你到是否理解发动机的原理。
线性代数核心需要掌握的是线性空间的概念和矩阵的各项基本运算,对于线性组合, 线性空间的各类概念, 矩阵的各种基本运算, 矩阵的正定和特征值等等都要有非常深厚的功力。





概率论:
概率论基础 : 概率论事整个机器学习和深度学习的语言 , 因为无论是深度学习还是机器学习所做的事情是均是预测未知。 预测未知你就一定要对付不确定性。 整个人类对不确定性的描述都包含在了概率论里面。
概率论你首先要知道的是关于概率来自频率主义和贝叶斯主义的观点, 然后你要了解概率空间这一描述描述不确定事件的工具, 在此基础上, 熟练掌握各类分布函数描述不同的不确定性。
我们最常用的分布函数是高斯, 但是你会发现高斯是数学书里的理想, 而真实世界的数据, 指数分布和幂函数分布也很重要, 不同的分布对机器学习和深度学习的过程会有重要的影响,比如它们影响我们对目标函数和正则方法的设定。懂得了这些操作, 会对你解决一些竞赛或实战里很难搞定的corner case大有裨益。
一个于概率论非常相关的领域-信息论也是深度学习的必要模块,理解信息论里关于熵,条件熵, 交叉熵的理论, 有助于帮助我们了解机器学习和深度学习的目标函数的设计, 比如交叉熵为什么会是各类分类问题的基础。

微积分:
微积分和相关的优化理论算是第三个重要的模块吧,线性代数和概率论可以称得上是深度学习的语言,那微积分和相关的优化理论就是工具了。 深度学习, 用层层迭代的深度网络对非结构数据进行抽象表征, 这不是平白过来的,这是优化出来的,用比较通俗的话说就是调参。 整个调参的基础,都在于优化理论, 而这又是以多元微积分理论为基础的。这就是学习微积分也很重要的根源。

优化理论:
机器学习里的优化问题,往往是有约束条件的优化,所谓带着镣铐的起舞 , 因此拉格朗日乘子法就成了你逃不过的魔咒。
优化理论包含一阶和二阶优化,传统优化理论最核心的是牛顿法和拟牛顿法。
由于机器学习本身的一个重要内容是正则化,优化问题立刻转化为了一个受限优化问题。这一类的问题,在机器学习里通常要由拉格朗日乘子法解决。
传统模型往往遵循奥卡姆剃刀的最简化原理,能不复杂就不复杂。 而深度学习与传统统计模型的设计理念区别一个本质区别在于,深度模型在初始阶段赋予模型足够大的复杂度,让模型能够适应复杂的场合,而通过加入与问题本身密切相关的约束: 例如全职共享,和一些通用的正则化方法:例如dropout, 减少过拟合的风险。
而正因为这种复杂度, 使得优化变得更加困难,主要由于:
1. 维度灾难, 深度学习动辄需要调整几百万的参数,是一个计算量超大的问题。
2.目标函数非凸, 具有众多的鞍点和极小值。 我们无法直接应用牛顿法等凸优化中的常见方法,而一般用到一阶优化(梯度下降),这看起来是比支持向量机里的二阶优化简单,然而正是因为缺乏很好的系统理论, 边角case变得特别多,反而最终更难。
3.深度, 由于深,造成反向传播的梯度往往越来越弱, 而造成梯度消失问题。 各类深度学习的领先算法往往是围绕解决梯度消失问题。


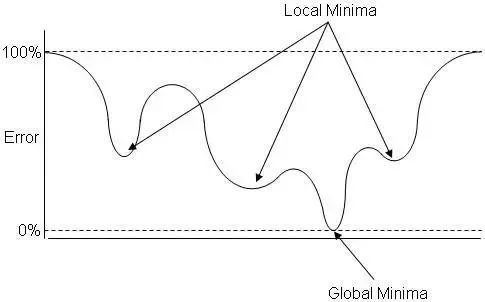
图: 臭名昭著的局部极小值问题。
我们用一些非常简单的实例说一下深度学习的几个主要应用方向与数学的结合:

阶段1:
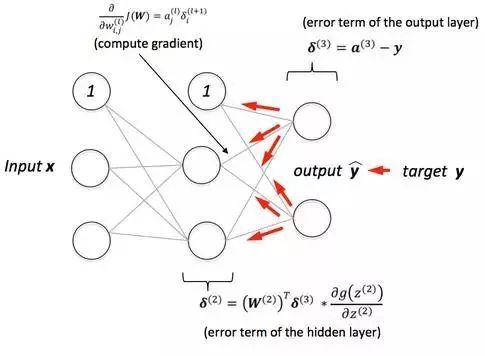
多层神经网络(DNN)的前传与回传(BP)算法 。
理解DNN的前向传递过程, 这个过程里包含了线性代数的空间变换思想和简单的高数。
这算是第一难度梯级, 你需要掌握的是BP算法, 这里含有多元微积分一个最基本的法则: 链式求导和jacobian矩阵。 在此处你会对维度产生全新的认识。

阶段2:
深度学习的中流砥柱CNN卷积运算 : 这里应用的数学是卷积本身, 你要通过高数掌握卷积的本质, 体会它与相关性, 傅立叶变换等运算之间的联系。 这部分也属于高数内容, 而卷积运算本身也需要强大的线性代数基础。

阶段3:
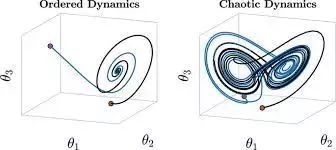
RNN网络与微分方程。RNN似乎包含比别家算法多很多的数学知识,因为RNN的运算和调参你需要理解一些非线性动力系统的基础知识。如定点,边缘稳定性和混沌。非线性动力学是物理的内容, 但是大部分讲的是数学, 这点物理系的学的会很有优势。
阶段4:
深度强化学习。 这时候你的数学工具要包含bellaman 方程,控制论的一些基础知识,更多关于马尔可夫过程和时间序列的知识。简单的控制论你看看会很好的助力你对整个机器学习用于机器人控制的理解,而马尔科夫决策树的基础知识学了你会觉得什么阿尔法狗阿尔法元都挺简单的。

阶段5:
生成式模型与GAN对抗网络。这部分的数学难度应该与深度强化学习在同一难度上。 需要对概率论有比较深的理解。 最基础的生成模型你要理解玻尔兹曼机这个与统计物理渊源很深的模型,需要较深的概率统计知识。 GAN生成对抗模型的目标函数含有了大名鼎鼎的博弈论思想。纳什均衡都进来了啊, 虽然这时候的优化理论已经飞一样的难, 你还是会有一种融汇贯通的感觉。

阶段6:
信息瓶颈理论? 计算神经科学前沿? 铁哥恭喜你此处要告别尘缘了。 深度学习的尽头必然要与我们对认知和信息本质的基础认识相连。 此处针对希望做深度学习研究的人员。


基础教材推荐:

陈希孺院士的《概率论与数理统计》,这是一本数理统计的入门级教材。最好的统计中文教材。参考评论 https://d.cosx.org/d/14990-14990
龚升的《简明微积分》。这本教材是我见过的最与众不同的写作结构,不是按常规教材那样讲导数、微分、微分的应用然后是不定积分、定积分。如果觉得难, 入门从同济大学的微积分教材入手也不错。
线性代数: Introduction to Linear Algebra (Gilbert Strang) MIT的教授,网上还有视频。

雷课:
让教育更有质量,
让教育更有想象!

以上是关于深度学习需要多强的数学基础?的主要内容,如果未能解决你的问题,请参考以下文章