豆瓣8.1分,用5张图教会你深度学习
Posted 行动派DreamList
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了豆瓣8.1分,用5张图教会你深度学习相关的知识,希望对你有一定的参考价值。

1956年的夏天,一场在美国达特茅斯大学召开的学术会议,多年以后被认定为全球人工智能研究的起点。
2016年的春天,一场AlphaGo与世界顶级围棋高手李世石的人机世纪对战,把全球推上了人工智能浪潮的新高。
2016年被称为“人工智能元年”,这一年爆发了全球性的人工智能潮流。以谷歌、Facebook、微软为首的全球三大AI巨头都在逐渐将公司的发展重心转移到人工智能方面来。
2019年1月25日,谷歌旗下的DeepMind开发的全新AI程序AlphaStar,在《星际争霸2》人机大战比赛中,以10:1的战绩,全面击溃了人类职业高手。
在围棋世界里,动作空间只有361种,而《星际争霸2》大约是10的26次方种。这场比赛可以说是人工智能在竞技游戏领域的一次里程碑式的胜利。
无论是AlphaGo还是AlphaStar,它们的主要工作原理都是“深度学习”。
“深度学习”是机器学习的一个领域,其形式是模拟人类大脑的神经网络进行计算和学习。
万维钢老师在《精英日课》中,通过清晰生动的案例,为我们解读了深度学习领域的一种重要模型——卷积神经网络。

神经网络与深度学习
为什么要了解深度学习?
首先,“深度学习”现在太热门了,图形识别、语音识别、汽车导航全都能用上,非常值钱。更重要的是,“深度学习”算法包含精妙的思想,能够代表这个时代的精神。
这个思想并不难,但是一旦领会了,你就能窥探一点脑神经科学和现代工程学。

▲《深度学习:智能时代的核心驱动力量》特伦斯·谢诺夫斯基 著 中信出版集团 2019.02
不知道你注意到没有,你的手机相册,知道你每一张照片里都有什么东西。不管你用的是 iPhone还是安卓,相册都有一个搜索功能,你输入“beach”,它能列举所有包含海滩的照片;输入“car”,它能列举画面中有汽车的照片,而且它还能识别照片中的每一个人。
每拍摄一张照片,手机都自动识别其中的典型物体。这是一个细思极恐的技术。怎么才能教会计算机识别物体呢?
01 没有规则的学习
不到十年之前,人们总认为模式识别方面人脑比计算机厉害,甚至谷歌投入巨大精力研究都做不到从照片里识别出一只猫。然而,从2012年开始,“深度学习”让计算机识别图形的能力突然变得无比强大,甚至已经超过了人类。
首先来看人是怎么识别猫的。观察一下这张图,你怎么判断这张照片里有没有猫呢?

你可能会说,这很简单,所有人都知道猫长什么样——好,那请问猫长什么样?
你也许可以用科学语言描写“三角形”是什么样的——这是一种图形,它有三条直线的边,有三个顶点。可是你能用比较科学的语言描写猫吗?它有耳朵、有尾巴,但这么形容远远不够,最起码你得能把猫和狗区分开来才行。
再看下面这张图片,你怎么判断 ta 是男还是女呢?
▲图片来自 design.tutsplus.com
你可能会说女性长得更秀气一些——那什么叫“秀气”?是说眉毛比较细吗?是轮廓比较小吗?
这是一个非常奇怪的感觉。你明明知道猫长什么样,你明明一眼就能区分男性和女性,可是说不清是怎么看出来的。
古老的计算机图形识别方法,就是非要规定一些明确的识别规则,让计算机根据规则判断,结果发现非常不可行。
人脑并不是通过什么规则做的判断。那到底是怎么判断的呢?
02 神经网络
神经网络计算并不是一项新技术,几十年前就有了,但是一开始并不被看好。《深度学习》的作者谢诺夫斯基,上世纪80年代就在研究神经网络计算,那时候他是一个少数派。
1989年,谢诺夫斯基到麻省理工学院计算机实验室访问。气氛不算融洽,那里的人都质疑他的方法。午餐之前,谢诺夫斯基有五分钟的时间,给所有人介绍一下他讲座的主题。谢诺夫斯基临场发挥,以食物上的一只苍蝇为题,说了几句话。
谢诺夫斯基说,你看这只苍蝇的大脑只有10万个神经元,能耗那么低,但是它能看、能飞、能寻找食物,还能繁殖。MIT有台价值一亿美元的超级计算机,消耗极大的能量,有庞大的体积,可是它的功能为什么还不如一只苍蝇?
在场的教授都未能回答好这个问题,倒是一个研究生给出了正确答案。他说这是因为苍蝇的大脑是高度专业化的,进化使得苍蝇的大脑只具备这些特定的功能,而我们的计算机是通用的,你可以对它进行各种编程,它理论上可以干任何事情。
这个关键在于,大脑的识别能力,不是靠临时弄一些规则临时编程。大脑的每一个功能都是专门的神经网络长出来的,那计算机能不能效仿大脑呢?
谢诺夫斯基说,大脑已经给计算机科学家提供了四个暗示。
第一个暗示:大脑是一个强大的模式识别器。人脑非常善于在一个混乱的场景之中识别出你想要的那个东西。比如你能从满大街的人中,一眼就认出你熟悉的人。
第二个暗示:大脑的识别功能可以通过训练提高。
第三个暗示:大脑不管是练习还是使用识别能力,都不是按照各种逻辑和规则进行的。我们识别一个人脸,并不是跟一些抽象的规则进行比对。我们不是通过测量这个人两眼之间的距离来识别这个人。我们一眼看过去,就知道他是谁了。
第四个暗示:大脑是由神经元组成的。我们大脑里有数百亿个神经元,大脑计算不是基于明确规则的计算,而是基于神经元的计算。
这就是神经网络计算要做的事情。
03 什么是“深度学习”
下面这张图代表一个最简单的计算机神经网络。
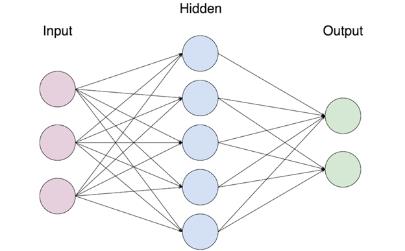
▲图片来自 hackernoon.com
它从左到右分为三层。
第一层代表输入的数据,第二和第三层的每一个圆点代表一个神经元。第二层叫“隐藏层”。第三层是“输出层”。
数据输入进来,经过隐藏层各个神经元的一番处理,再把信号传递给输出层,输出层神经元再处理一番,最后作出判断。
从下面这张图,你可以看到它的运行过程。
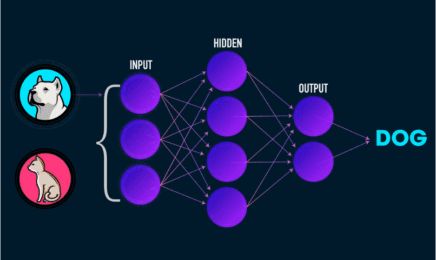
▲图片来自 Analytics India Magazine
那什么叫“深度学习”呢?
最简单的理解,就是中间有不止一层隐藏层神经元的神经网络计算。“深度”的字面意思就是层次比较“深”。
接着看下面这张图,你可以看到,左边是简单神经网络,右边是深度学习神经网络。
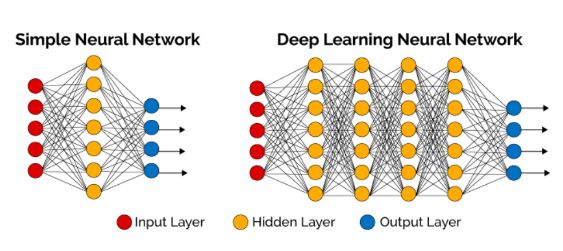
▲图片来自 Towards Data Science 网站
计算机最底层的单元是晶体管,而神经网络最底层的单元就是神经元。神经元是什么东西呢?我们看一个最简单的例子。
下面这张图表现了一个根据交通信号灯判断要不要前进的神经元。它由三部分组成:输入、内部参数和输出。

这个神经元的输入就是红灯、黄灯和绿灯这三个灯哪个亮了。我们用1表示亮,0表示不亮,那么按照顺序,“1,0,0” 这一组输入数字,就代表红灯亮,黄灯和绿灯不亮。
神经元的内部参数包括“权重(weight)”,它对每个输入值都给一个权重,比如图中给红灯的权重是 -1,黄灯的权重是 0,给绿灯的权重是1。另外,它还有一个参数叫“偏移(bias)”,图中偏移值是-0.5。
神经元做的计算,就是把输入的三个数字分别乘以各自的权重,相加,然后再加上偏移值。比如现在是红灯,那么输入的三个数值就是1、0、0,权重是 -1、0、1,所以计算结果就是:
1×(-1) + 0×0 + 0×1 - 0.5 = -1.5。
输出是做判断,判断标准是如果计算结果大于 0 就输出“前进”命令,小于 0 就输出“停止”命令。现在计算结果小于0,所以神经元就输出“停止”。
这就是神经元的基本原理。真实应用中的神经元会在计算过程中加入非线性函数的处理,并且确保输出值都在 0 和 1 之间。
本质上,神经元做的事情就是按照自己的权重参数把输入值相加,再加入偏移值,形成一个输出值。如果输出值大于某个阈值,我们就说这个神经元被“激发”了。
神经元的内部参数,包括权重和偏移值,都是可调的。用数据训练神经网络的过程,就是调整更新各个神经元的内部参数的过程。神经网络的结构在训练中不变,是其中神经元的参数决定了神经网络的功能。
接下来我们要用一个实战例子说明神经网络是怎样进行图形识别的。我们要用一个简单的神经网络识别手写的阿拉伯数字。

案例:计算机如何识别手写数字
用神经网络识别手写的阿拉伯数字,是一个非常成熟的项目,网上有现成的数据库和很多教程。有个叫迈克尔·尼尔森(Michael Nielsen)的人只用了74行Python程序代码就做成了这件事。
给你几个手写阿拉伯数字,可能是信封上的邮政编码也可能是支票上的钱数,你怎么教会计算机识别这些数字呢?
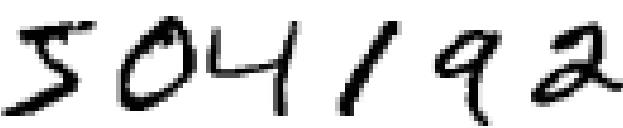
01 简化
想要让计算机处理,首先要把问题“数学化”。写在纸上的字千变万化,我们首先把它简化成一个数学问题。我们用几个正方形把各个数字分开,就像下面这张图一样。

现在问题变成给你一个包含一个手写数字的正方形区域,你能不能识别是什么数字?
再进一步,我们忽略字的颜色,降低正方形的分辨率,就考虑一个28×28=784个像素的图像。我们规定每一个像素值都是0到1之间的一个小数,代表灰度的深浅,0表示纯白色,1表示纯黑。这样一来,手写的数字“1”就变成了下面这个样子 ——
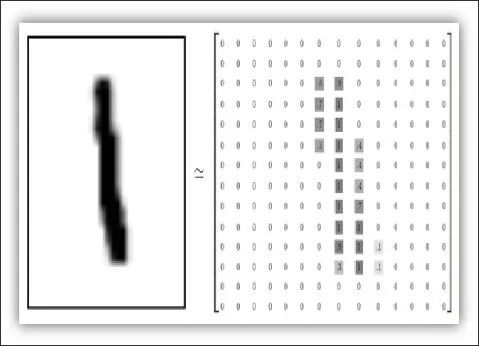
▲图片来自packtpub.com, The MNIST dataset,实际分辨率是28×28。
这就完全是一个数学问题了。现在无非就是给你784个0-1之间的数,你能不能对这组数做一番操作,判断它们对应的是哪个阿拉伯数字。输入784个数,输出一个数。
这件事从常理来说并不是一点头绪都没有。比如任何人写数字“7”,左下角的区域应该是空白的,这就意味着784个像素点中对应正方形左下角区域那些点的数值应该是0。再比如说,写“0”的时候的中间是空的,那么对应正方形中间的那些像素点的数值应该是0。
然而,这种人为找规律的思路非常不可行。
首先你很难想到所有的规则,更重要的是很多规则都是模糊的——比如,7的左下角空白,那这个空白区域应该有多大呢?不同人的写法肯定不一样。
肯定有规律,可我们说不清都是什么规律,这种问题特别适合神经网络学习。
02 设定
我们要用的方法叫做“误差反向传播网络”,
它最早起源于1986年发表在《自然》杂志上的一篇论文,这篇论文的被引用次数已经超过了4万次,是深度学习的里程碑。
根据尼尔森的教程,我们建一个三层的神经网络,就是下面这张图 ——
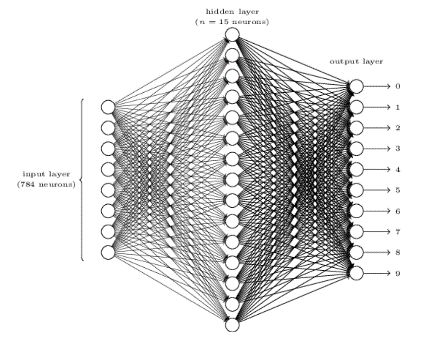
第一层是输入数据,图中只画了8个点,但其实上有784个数据点。第二层是隐藏层,由15个神经元组成。第三层是输出层,有10个神经元,对应0-9这10个数字。
每个神经元都由输入、权重和偏移值参数、输出三个部分组成。隐藏层15个神经元中的每一个都要接收全部784个像素的数据输入,总共有784×15=11760个权重和15个偏移值。第三层10个神经元的每一个都要跟第二层的所有15个神经元连接,总共有150个权重和10个偏移值。这样下来,整个神经网络一共有11935个可调参数。
理想状态下,784个输入值在经过隐藏层和输出层这两层神经元的处理后,输出层的哪个神经元的输出结果最接近于1,神经网络就判断这是哪一个手写数字。
03 训练
网上有个公开的现成数据库叫“MNIST”,其中包括6万个手写的数字图像,都标记了它们代表的是哪些数字。

我们要做的是用这些图像训练神经网络,去调整好那11935个参数。我们可以用其中3万个图像训练,用剩下3万个图像检验训练效果。
这个训练调整参数的方法,就是“误差反向传播”。比如我们输入一个数字“7”的图像。
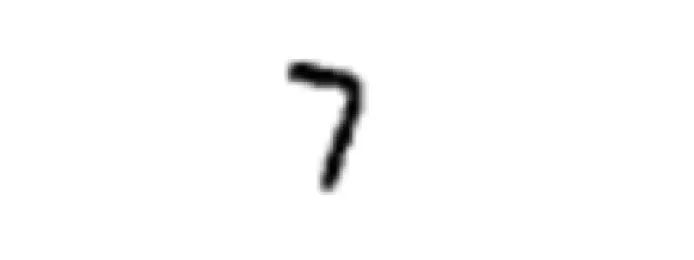
神经网络实际收到的是784个像素值。经过两层神经元的传播计算,理想情况下,输出层的7号神经元的输出值应该最接近于1,其他的都很接近于0。一开始结果并不是这么准确,我们要用一套特定的规则去调整各个神经元的参数。
参数调整有个方向,叫做“误差梯度”。比如对输出层的7号神经元来说,调整方向就是要让它的输出值变大;对其他9个神经元,调整方向则是让输出值变小。这个调整策略是看哪个输入信息对结果的影响大,对它的权重的调整就要大一点。
几万个训练图像可能会被反复使用多次,神经网络参数不断修改,最终将会达到稳定。慢慢地,新图像喂进来,这11935个参数的变化越来越小,最终几乎不动了。那就是说,这个识别手写数字的神经网络,已经练成了。事实证明这个简单网络的识别准确率能达到95%!
在理论上,这个方法可以用来学习识别一切图像。你只要把一张张的图片喂给神经网络,告诉它图上有什么,它终将自己发现各个东西的像素规律……但是在实践上,这个方法非常不可行。

卷积网络如何实现图像识别
计算机不怕“笨办法”,但是哪怕你能让它稍微变聪明一点,你的收获都是巨大的。
01 “笨办法”和人的办法
下面这张图中有一只猫、一只狗、绿色的草地和蓝天白云。它的分辨率是350×263,总共92050个像素点。考虑到这是一张彩色照片,每个像素点必须用三个数来代表颜色,这张图要用27万个数来描写。

要想用误差反向传播神经网络识别这样的图,它第二层每一个神经元都要有27万个权重参数。要想识别包括猫、狗、草地、蓝天白云这种水平的常见物体,它的输出层必须有上千个神经元才行。这样训练一次的计算量将是巨大的 —— 但这还不是最大的难点。
最大的难点是神经网络中的参数越多,它需要的训练素材就越多。并不是任何照片都能用作训练素材,你必须事先靠人工标记照片上都有什么东西作为标准答案,才能给神经网络提供有效反馈。
这么多训练素材上哪找呢?
我听罗胖跨年演讲学到一个词叫“回到母体”,意思大约是从新技术后退一步,返回基本常识,也许能发现新的创新点。现在我们回到人脑,想想为什么简单神经网络是个笨办法。
人脑并不是每次都把一张图中所有的像素都放在一起考虑。我们有一个“看什么”,和一个“往哪看”的思路。
让你找猫,你会先大概想象一下猫是什么样子,然后从一张大图上一块一块地找,你没必要同时考虑图片的左上角和右下角。这是“往哪看”。
还有,当你想象猫的时候,虽然不能完全说清,但你毕竟还是按照一定的规律去找。比如猫身上有毛,它有两个眼睛和一条尾巴等等。你看的不是单个的像素点,你看的是一片一片的像素群的模式变化。这是“看什么”。
我理解“卷积网络”,就是这两个思路的产物。
02 竞赛
斯坦福大学的华裔计算机科学家李飞飞,组织了一个叫做ImageNet的机器学习图形识别比赛,从2010年开始每年举行一次。这个比赛每年都给参赛者提供一百万张图片作为训练素材!其中每一张图都由人工标记了图中的每个物体。

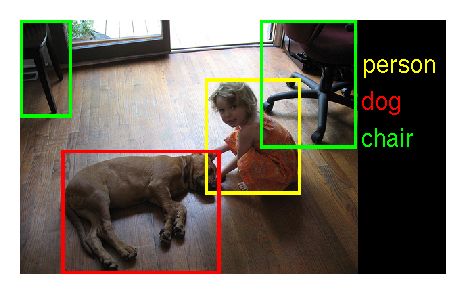
图片素材中共有大约一千个物体分类。这就意味着,对每一种物体,人工智能都有大约一千次训练机会。
比赛规则是参赛者用这一百万张图片训练自己的程序,然后让程序识别一些新的图片。每张新图片有一个事先设定的标准答案,而参赛者的程序可以猜五个答案,只要其中有一个判断跟标准答案相符合,就算识别结果准确。
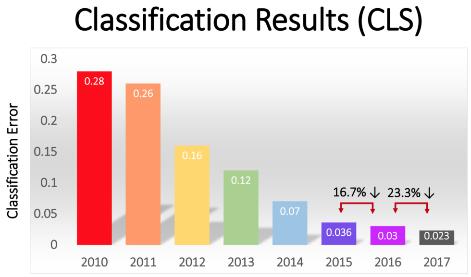
上图是历届比赛冠军的成绩。2010和2011年,最好成绩的判断错误率都在26%以上,但是2012年,错误率下降到了16%,从此之后更是直线下降。2017年的错误率是2.3%,这个水平已经超过人类。
那2012年到底发生了什么呢?发生了“卷积网络”。
03 卷积网络
2012年的冠军是多伦多大学的一个研究组,他们使用的方法就是卷积网络。正是因为这个方法太成功了,“深度学习”才流行起来,现在搞图形识别几乎全都是用这个方法。获奖团队描述卷积网络的论文的第一作者叫艾利克斯·克里泽夫斯基(Alex Krizhevsky),当时他只是一个研究生,这篇论文现在被人称为“AlexNet” 。
简单来说,AlexNet的方法是在最基本的像素到最终识别的物体之间加入了几个逻辑层,也就是“卷积层”。“卷积”是一种数学操作,可以理解成“过滤”,或者叫“滤波”,意思是从细致的信号中识别尺度更大一点的结构。每一个卷积层识别一种特定规模的图形模式,然后后面一层只要在前面一层的基础上进行识别,这就解决了“看什么”和“往哪看”的问题。
比如说我们要搞人脸识别,卷积网络方法把问题分解为三个卷积层。
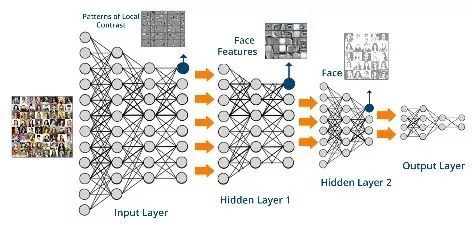
▲图片来自cdn.edureka.co
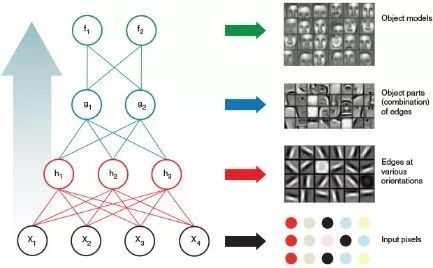
第一层,是先从像素点中识别一些小尺度的线条结构。第二层,是根据第一层识别出来的小尺度结构识别像眼睛、耳朵、嘴之类的局部器官。第三层,才是根据这些局部器官识别人脸。其中每一层的神经网络从前面一层获得输入,经过深度学习之后再输出到后面一层。
AlexNet的论文提到,他的识别系统足足分了五个卷积层,每一层都由很多个“特征探测器”组成。第一层有96个特征探测器,各自负责探测整个图形中哪些地方有下面这96种特征中的一种。

比如说,第一层的第一个特征探测器,专门负责判断图中哪里有像下面这样,从左下到右上的线条结构。

这个特征探测器本身也是一个神经网络,有自己的神经元——而这里的妙处在于,它的每一个神经元只负责原始图像中一个11×11小区块。考虑到三种颜色,输入值只有 11×11×3= 363个。而且因为这个探测器只负责探测一种结构,每个神经元的参数都是一样的!这就大大降低了运算量。
第一层的其他探测器则负责判断像垂直条纹、斑点、颜色从亮到暗等各种小结构,一共是96种。
也就是说,卷积网络的第一层先把整个图像分解成11×11的区块,看看每个区块里都是什么结构。为了避免结构被区块拆散,相邻的区块之间还要有相当大的重叠。经过第一层的过滤,我们看到的就不再是一个个的像素点,而是一张小结构的逻辑图。
然后第二卷积层再从这些小结构上识别出更大、更复杂也更多的结构来。以此类推,一直到第五层。下面这张图表现了从第一层到第三层识别的模块(灰色)和对应的实例(彩色)。

我们看到,第二个卷积层已经能识别圆形之类的结构,第三层已经能识别车轮和小的人脸。五个卷积层之外,AlexNet还设置了三个全局层,用于识别更大的物体。整个分层的结构是下面这样。
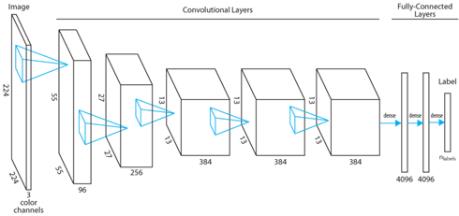
▲图片来自 Machine Learning Blog
这样分层方式有很多好处:第一,卷积层中的神经元只要处理一个小区域的数据,而且参数可以重复使用,大大减少了运算量。第二,因为可以一个区域一个区域地搜索,就可以发现小尺度的物体。
意识到图形识别有多难,你就能体会到AlexNet的识别水平有多神奇。下面这张图中有个红色的螨虫,它出现在图像的边缘,但是被正确识别出来了。

AlexNet还猜测它可能是蜘蛛、蟑螂、虱子或者海星,但是认为它是螨虫的可能性最高。这个判断水平已经超过了我,我都不知道那是个螨虫。
再比如下面这张图,标准答案是“蘑菇”,但AlexNet给的第一判断是更精确的“伞菌”,“蘑菇”是它的第二选项!

而现在基于类似的卷积网络方法的深度学习程序,水平已经远远超过了AlexNet。
04 深度学习(不)能干什么
AlexNet那篇论文的几个作者成立了一家创业公司,这家公司在2013年被Google收购了。半年之后,Google相册就有了基于图片识别的搜索能力。紧接着,Google就可以从自家拍摄的街景图像中识别每家每户的门牌号码了。Google还夺得了2014年的ImageNet竞赛冠军。
所以千万别低估工程师迭代新技术的能力。他们举一反三,一旦发现这个技术好,马上就能给用到极致。2012年之前深度学习还是机器学习中的“非主流”,现在是绝对主流。
深度学习能做一些令人赞叹的事情。比如说对于一个不太容易判断的物体,如果网络知道图中有草地,那么它就会自动判断这应该是一个经常放在户外的东西,而不太可能是一件家具。这完全是基于经验的判断,你不需要告诉它家具一般不放户外。看的图多了,它仿佛获得了一些智慧!一个生活经验少的人可做不到这一点。
但是蒂莫西·李也提醒了我们深度学习不能做什么。比如说把一个物体放大一点、或者旋转一个角度、或者调整一下光线,卷积网络就不知道那是同一个东西,它必须重新判断。深度学习完全是基于经验的判断,它没有任何逻辑推理能力。
在我看来,这种学习方法,就如同在数学考试前夜背诵习题集。你能猜对答案是因为你背诵过类似的题,但是你并不真的理解数学。
这样的算法会有创造力吗?深度学习能发现图像中从来没有被人命名过的“怪异”物体吗?我们见识了光凭经验的操作能强大到什么程度,但是我们也能看出来,它距离真正的智能还非常遥远。
《深度学习:智能时代的核心驱动力量》

想了解深度学习,读这一本就够了。文科生也能看得懂的前沿通识作品。世界十大AI科学家、美国四院院士力作,谷歌前云AI负责人李飞飞、AI教父杰弗里·辛顿重磅推荐,微软小冰之父李笛作序。深度学习会扩大你的认知,人工智能不是生存威胁。
老规矩,留言送书~评论区随机抽取10位读者,第二天早上10点开奖!
以上是关于豆瓣8.1分,用5张图教会你深度学习的主要内容,如果未能解决你的问题,请参考以下文章