深度学习在CV领域已触及天花板?
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习在CV领域已触及天花板?相关的知识,希望对你有一定的参考价值。
机器之心原创
编辑:Haojin Yang
随着深度学习研究的不断深入,越来越多的领域应用到了深度学习。但是,深度学习取得成功的同时,也不可避免地遭受到越来越多的质疑,特别是在CV领域。本文没有对他人的观点直接做出批判,而是从深度学习的本质出发,探讨它的优势以及相关局限性,最后对深度学习可能的应对方法和未来展开讨论。本文作者为王子嘉,帝国理工学院人工智能硕士在读。
1. 深度学习从未停止前进
图像数据的特征设计,即特征描述,在过去一直是计算机视觉(Computer Vision, CV)头痛的问题,而深度学习在计算机视觉领域的兴起使得这一领域不再需要很多的人为干预,大大降低了对专业知识的需求(见下图)。对应的,围绕着深度学习开始出现大量的炒作,这样的炒作使得很多人开始对深度学习产生怀疑,但是同样不得忽视的是深度学习在计算机视觉任务上已经获得的大量成功。
(图源:https://trantorinc.com/blog/top-computer-vision-trends-2019/)
CNN 从 AlexNet 之后,新模型以肉眼可见的速度在增长,比较经典的如 LeNet(1998)、AlexNet(2012)、ZF-net(2013)、GoogleNet(2014)、VGG(2014)、ResNet(2015);2014 年提出的 GAN 更是一个里程碑式的突破。但近年来,CV 领域虽然新论文不断,但更多的是在填前人挖好的坑(改进模型),比如 2018 的 BigGAN 以及今年的的 Mask Scoring RCNN 等,都没有引起很大的轰动。相比之下,NLP 继 BERT 之后又出现了 XLNet,就显得热闹的多。对应的,对于 Deep Learning 在 CV 领域是否触顶的质疑声也开始变得更加强烈。
对此问题,本文不会做直接评判,而是首先简单介绍什么是 Deep Learning,再介绍 Deep Learning 的优势,然后介绍当下较为主流的对于 Deep Learning 的批判,最后两个部分会对 Deep Learning 可能的应对方法和未来展开讨论。
1.1 什么是深度学习
想要了解什么是深度学习,最简单的方法莫过于打开一个深度学习课程或者入门书籍,看一下它的目录,就大概了解深度学习包括什么了。本文引用 Lecun 在 2015 年曾经给深度学习下过的定义——深度学习方法由多个层组成,用于学习具有多个等级的数据特征。所以有些学者也把深度学习叫做分级学习(Hierarchical Learning)。
如今的深度学习不只是本文在开头提及的 Deep CNN,它还包括 Deep AE(AutoEncoder,如 Variational Autoencoders, Stacked Denoising Autoencoders, Transforming Autoencoders 等)、R-CNN(Region-based Convolutional Neural Networks,如 Fast R-CNN,Faster R-CNN,Mask R-CNN,Multi-Expert R-CNN 等)、Deep Residual Networks(如 Resnet,ResNeXt)、Capsule Networks、GAN(Generative Adversarial Network) 等,以及 RNN、LSTM 等处理用于处理序列类数据的 Recurrent 类模型。
1.2 深度学习的优势
深度学习之所以能在 CV 领域火起来,除了本文开头提及的减少了特征提取的麻烦外,还有其他的优势。比如它是端到端模型;训练中的特征提取器,甚至于训练出的模型都可以用于其他任务;它可以获得相较于传统方法更好的效果;同时它还是由极其简单的组件组成的。本文将就这几个优势分别进行阐述。
自动特征提取
计算机视觉领域的主要研究重点是从数字图像中检测和提取有用的特征。这些特征提供了图像的大量信息,并且可以直接影响到最后任务的效果。因此过去出现了很多很优秀的手动的特征提取器,比如尺度不变特征变换(SIFT),Gabor 滤波器和定向梯度直方图(HOG)等,它们也一直是特征提取的计算机视觉焦点,并取得了很好的效果。
而深度学习的优势在于它做到了直接从大型图像数据集中自动学习复杂且有用的特征,可以从神经网络模型的提供的图像中学习并自动提取各种层次的特征。举个很简单的例子,当把深度神经网络的每一层中提取到的特征画出来,最底层可能提取的是轮廓类的特征,而最高层可能提取的就是最基本的线条类的特征。而现在各种比赛(如 ILSVRC)和标准集中从复杂的人工特征检测器(如 SIFT)向深度卷积神经网络过渡就很好的证明深度学习网络的确很好的解决了这一问题。
端到端(end-to-end)
端到端模型解决了 CV 中需要使用模块的任务的问题。这类任务中每个模块都是针对特定任务而设计的,例如特征提取,图像对齐或分类任务。这些模块都有自己的输入输出,模块的一端是原始图像,另一端就是这个模块的输出,当然深度学习模型也可以作为这些模块中的一部分。然后这些模块组成一个整体,从而完成最后的任务。
但是深度学习模型自己也可以完成整个任务(端到端),它可以只使用一个模型,这个模型同时包含多个模块(比如特征提取和分类),这样使得其可以直接在原始图像上训练并进行图像分类。这种端到端的方法也有取代传统方法的趋势。比如在物体检测和人脸识别中,这种端到端的模型就会同时训练多个模块的输出(如类和边界框)和新损失函数(如 contrastive 或 triplet loss functions)从而得到最终的模型。
模型迁移
深度神经网络一般会在比传统数据集大得多的数据集(数百万乃至数十亿张图片)上训练。这允许模型学习到所有照片的普遍特征和特征的层次结构。这一点被很多人注意到,并提出了迁移学习的概念,这个概念也在一定程度上缓解了深度学习对数据的依赖。
更好的效果
深度学习带给 CV 最大的好处就是它所具有的更好的性能。深度神经网络性能的显着提高正是深度学习领域迅速发展的催化剂。比如前文提到的 Alex Net 就以 15.8% 的 top-5 错误率获得了 2012 年 ILSVRC 的冠军,而当年的第二名却有 26.2% 的错误率。而这些模型也很快应用在 CV 的各个领域,并解决了很多曾经很难解决的问题
简单的组件
我们可以发现 CV 领域里大部分优秀的深度学习网络都是基于相同的元素——卷积层和 Pooling 层,并将这些元素进行不同的组合。卷积网络是一种专门处理网格结构数据的网络,并可以将这些模型进行扩展。目前看来,这种方法已经在二维图像上取得了不小的成功。
2. 深度学习的局限性
尽管深度学习有很多优势,也取得了不小的成绩,但是也有很多局限性导致其在前几年的飞速发展后似乎进入了一个瓶颈期。Gary Marcus 曾经说过,深度学习是贪婪,脆弱,不透明和浅薄的。这些系统很贪婪,因为它们需要大量的训练数据;它们是脆弱的,因为当神经网络应用在一些不熟悉的场景时,面对与训练中使用的示例不同的场景,它并不能很好的完成任务;它们是不透明的,因为与传统的可调试代码不同,神经网络的参数只能根据它们在数学中的权重来解释,因此,它们是黑盒子,其输出很难解释;它们是浅薄的,因为它们的训练缺乏先天知识,对世界没有常识。
贪婪
前文中提到过深度学习的一大优势就是当你给你的网络更多的数据时,相应的你也会获得更好的结果。但是如果把这句话反过来说,这个优势就变成了问题——想要获得更好的结果,你就需要大量的标注数据。
脆弱
当下的深度学习网络在做分类的时候,很难输出一个百分百肯定的结果,这也就意味着网络并没有完全理解这些图片,只能通过各种特征的组合来完成大概的预测。而不管我们用来训练的图片库有多大,都是有限的,从而有些图片是没有在我们的训练库内的(对抗样本),这些图片很可能跟我们已有的图片具有极其类似的特征,从而出现下图中将对抗样本完全分错类的情况。

(图源:[3])
可以想象,一辆自动驾驶汽车可以行驶数百万英里,但它最终会遇到一些没有经验的新事物;一个机器人可以学会拿起一个瓶子,但如果让他拿起一个杯子,它就得从头学起。
同时,当在图片中掺杂一些人类不可见的噪音,或是对背景进行一些改变,都可能会让模型的预测出错。下图就是一个改变背景的例子,从下图可以看出,当背景物品从自行车变为吉他之后,这只猴子被预测成了一个人,这大概是因为模型在训练的时候认为人比猴子要更可能有一把吉他。
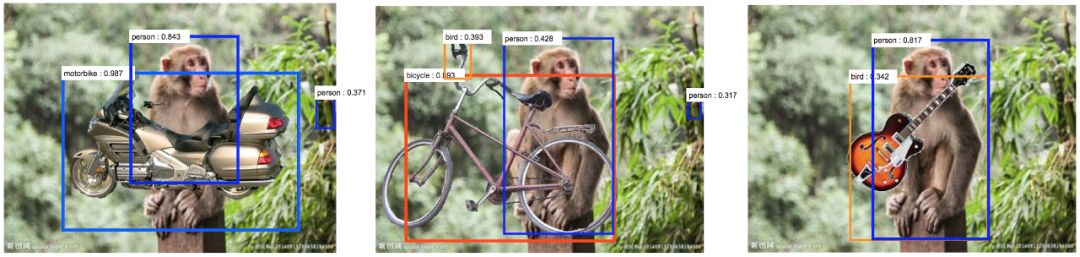
(图源:https://thegradient.pub/the-limitations-of-visual-deep-learning-and-how-we-might-fix-them/)
最后,深度学习大多是基于卷积的,卷积可以很好的处理二维图像,但是对三维图像的处理效果却不甚理想。
不透明
深度学习说到底还是一个数学模型,虽然本源是来自于人类的大脑的工作机制,但是还是无法真的理解这个模型的各个参数的含义,从而导致整个深度学习网络成为了一个黑盒模型,除了一些超参以外,很难进行内部的调参。
浅薄
当下的深度学习网络大部分倾向于表征学习,而非真正的智能,很依赖于其训练数据,很难从有限的数据中学习到全局的东西;同时在一些不断变化的情景下,这些网络也很难有很好的表现。换句话说,这些网络缺少「创造力」和「想象力」。
3. 深度学习的应对
仔细观察上述缺点的话,不难发现深度学习目前能解决的就是数据的问题,而至于其「智能」的问题,可能需要一个新的框架来实现了。本文剩下的部分主要陈述深度学习为了解决上述缺陷而兴起的部分领域,以及这些领域较新的论文与进展。
数据合成
为了解决数据问题,最简单也最直接的方法就是合成更多的数据。在过去的一年中,数据合成一直是计算机视觉研究的一个巨大趋势。它们由人工生成,可以用来训练深度学习模型。例如,SUNCG 数据集可以用于模拟室内环境,Cityscapes 数据集用于驾驶和导航,合成人的 SURREAL 数据集用于学习姿势估计和跟踪。
除了这些数据集,还有一些论文也在就如何更好的使用合成数据以及如何更好的合成数据做出研究:
这篇聚焦于数据质量的论文 [5] 在 Auto City 数据集上进行实验,最终证明分割任务的效果确实与生成标记所花费的时间量密切相关,但与每个标签的质量无关;[9] 使用了一个利用合成预想来训练的多任务深度网络,使得特征学习可以从不同的信息源中学习,极大减少了标注数据所需的时间;[13] 提出了一种基于合成数据训练的实物检测系统。
迁移学习
迁移学习现在在 CV 领域很受欢迎,简单的说,迁移学习就是在一个很大的数据库上对模型进行预训练,再将这个预训练过的模型用于其他任务上,有点类似于 NLP 中的 Word Embedding。
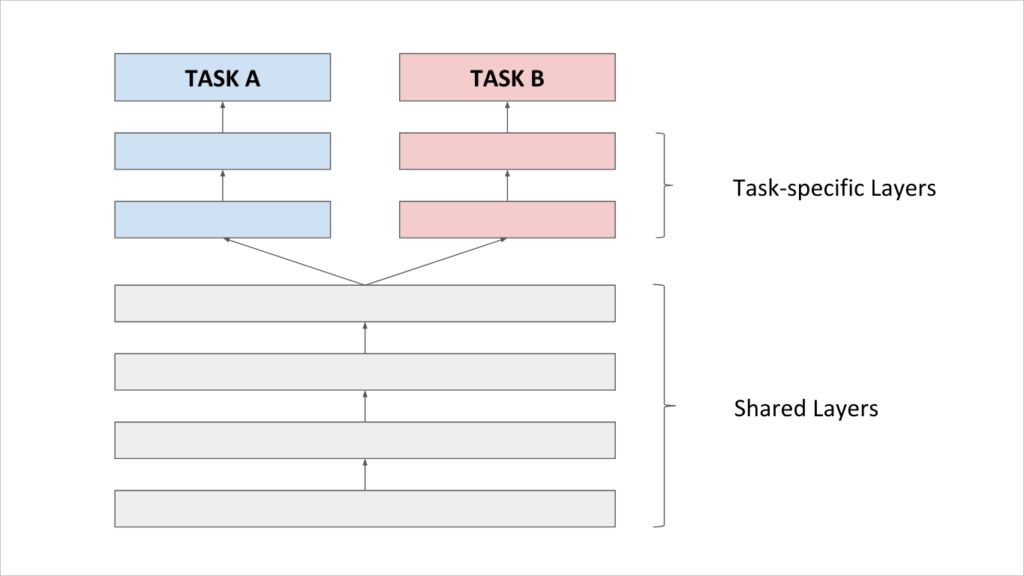
(图源:https://trantorinc.com/blog/top-computer-vision-trends-2019/)
举个例子,假设你有一个经过训练的 ML 模型 A 来识别动物的图片,你可以用 A 来训练识别狗的图片的模型 D。就数据而言,训练 D 需要向 A 添加一些额外的层,但是大大减少了训练 D 所需的数据量。
迁移学习是一个很大的领域,最近发表的与迁移学习相关的论文也很多,本文只挑选几篇较新且已发表的的论文进行简单介绍:
[7] 中提出了基于不完整实例的对抗模仿学习——Action-Guided Adversarial Imitation Learning (AGAIL),它在基本的 GAN 中(Generator + Discriminator 的组合)加入了一个 guide,从而达到从不完整实例中学习的目的;[8] 中提出了两种提升 CNN 表征泛化度的方法,其中一种依赖于分类学知识,另一种是利用微调进行重训练,并提出了一种衡量迁移学习泛化度的集成方法;[14] 虽然还没经过 peer-review,但是其使用 GAN 进行化妆迁移的想法很具有启发性,不同于传统的 GAN,本文使用了两个编码器,一个身份编码器(identity encoder)和一个化妆风格编码器(Makeup encoder),并使用一个解码器将两个编码器的输出重建成人脸,最后还有一个鉴别器来鉴别人脸的真假。
3D 对象理解
前文说过,当前的卷积层和 Pooling 层在二维数字图像中有很好的应用,但是 3D 对象理解对于深度学习系统成功解释和现实世界导航至关重要。例如,网络可能能够在街道图像中定位汽车,为其所有像素着色,并将其分类为汽车。但它是否真的了解图像中的汽车相对于街道中的其他物体的位置?
为此深度学习专家们提出了可以准确地表示物体在空间中的位置的点云(point cloud)。点云是 3D 空间中的一组数据点。简单地说,物体表面上的每个点都有三维坐标(X,Y,Z),称为点云。其中,PointNet++ [4] 就是一种很好的利用点云的深度学习模型。
除了点云,[11] 延伸了 2017 年出现的 Mask R-CNN,提出一种 3D Mask R-CNN 架构,它使用时空卷积来提取特征并直接识别短片中的姿势。完整的架构如下所示。它在姿势估计和人体追踪方面实现了当前最优结果。
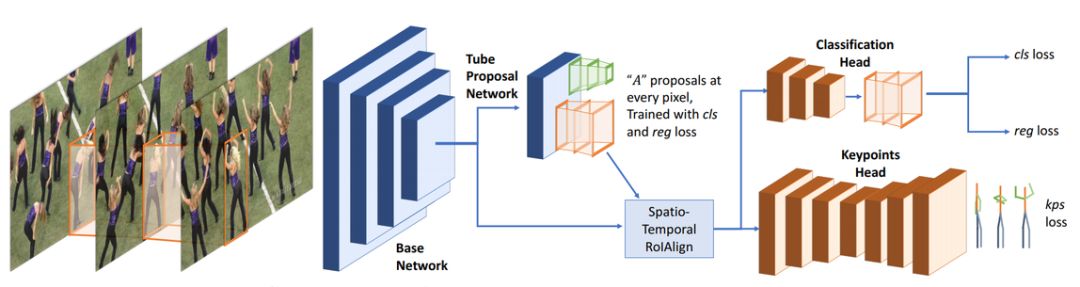
(图源自论文)
[12] 提出了一种行人重识别(person re-identification)的新方法,这个问题一般是通过基于检索的方法来解决的,即求导查询图像与来自某个嵌入空间的存储图像之间的相似度度量,而本文中的框架将姿势信息直接嵌入到 CNN 中,并设计了一个新的无监督重排序方法。完整的框架如下图所示,其中 Baseline Architecture 使用的是 ResNet-50,同时一个简单的 View Predictor 与 Baseline Architecture 一起提供了姿态信息作为后面的输入。
(图源自论文)
域适应(Domain Adaptation)
严格来说,域适应应该也算迁移学习的一种,不过上文提到的迁移学习主要说的是样本迁移。域适应的目的其实跟数据合成类似,都是为了得到更多的有标注数据。简单来说,就是用任务 A 的数据来为任务 B 准备数据,或者说是将这个数据改造成适合任务 B 的数据。
举一个例子,利用相似性学习的无监督域适应 [1] 使用对抗性网络来处理域适应。作者使用一个网络从有标记源中提取特征,又利用另一个网络从未标记的目标域中提取特征,这些特征的数据分布相似但不同。为了标记来自目标域的图像,作者将图像的嵌入与来自源域的原型图像的嵌入进行比较,然后将最近邻居的标签分配给它。另一个域适应的例子是 [15],文中提出了一种图像到图像的转换,主要用了 3 种主要技术:(i)domain-agnostic feature extraction(无法区分领域的特征的提取),(ii)domain-specific reconstruction(嵌入可以被解码回源域和目标域),和(iii)cycle consistency(正确学习映射)。从根本上来说,这个方法的目的就是找到从源数据分布到目标数据分布的映射结构。
除了上面的例子,最近 [10] 也提出了一种利用 Bayesian 来做域适应的方法。
(图源:[1])
4. 总结
由本文可见,当下深度学习有自己的优势,也有一定的局限性,而深度学习专家们也在尽力解决这些局限性。对于深度学习的未来,我相信除了它自己的改进外,它也会在一些新兴领域如 NLP 与 CV 结合的产物——Visual Question Answering(VQA)中大放异彩。当然,未来也很有可能会出现更加智能的模型来代替现在的深度学习模型。
References
[1] Pedro Oliveira Pinheiro. Unsupervised domain adaptation with similarity learning. CoRR, abs/1711.08995, 2017.
[2] Matiur Rahman Minar and Jibon Naher. Recent advances in deep learning: An overview. CoRR, abs/1807.08169, 2018. [3] Alan L. Yuille and Chenxi Liu. Deep nets: What have they ever done for vision? CoRR, abs/1805.04025, 2018.
[4] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. CoRR, abs/1706.02413, 2017.
[5] Aleksandar Zlateski, Ronnachai Jaroensri, Prafull Sharma, and Fr´edo Durand. On the importance of label quality for semantic segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[6] Artidoro Pagnoni, Stefan Gramatovici, and Samuel Liu. PAC learning guarantees under covariate shift. CoRR, abs/1812.06393, 2018.
[7] Mingfei Sun and Xiaojuan Ma. Adversarial imitation learning from incomplete demonstrations. CoRR, abs/1905.12310, 2019.
[8] Y. Tamaazousti, H. Le Borgne, C. Hudelot, M. E. A. Seddik, and M. Tamaazousti. Learning more universal representations for transferlearning. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2019.
[9] Zhongzheng Ren and Yong Jae Lee. Cross-domain self-supervised multitask feature learning using synthetic imagery. CoRR, abs/1711.09082, 2017.
[10] Jun Wen, Nenggan Zheng, Junsong Yuan, Zhefeng Gong, and Changyou Chen. Bayesian uncertainty matching for unsupervised domain adaptation. CoRR, abs/1906.09693, 2019.
[11] Rohit Girdhar, Georgia Gkioxari, Lorenzo Torresani, Manohar Paluri, and Du Tran. Detect-and-track: Efficient pose estimation in videos. CoRR, abs/1712.09184, 2017.
[12] M. Saquib Sarfraz, Arne Schumann, Andreas Eberle, and Rainer Stiefelhagen. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. CoRR, abs/1711.10378, 2017.
[13] Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. CoRR, abs/1804.06516, 2018.
[14] Honglun Zhang, , Wenqing Chen, Hao He, and Yaohui Jin. Disentangled makeup transfer with generative adversarial network. CoRR, abs/1804.06516, 2019.
[15] Zak Murez, Soheil Kolouri, David J. Kriegman, Ravi Ramamoorthi, and Kyungnam Kim. Image to image translation for domain adaptation. CoRR, abs/1712.00479, 2017.
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于深度学习在CV领域已触及天花板?的主要内容,如果未能解决你的问题,请参考以下文章
深度学习面临天花板,亟需更可信可靠安全的第三代AI技术|AI ProCon 2019