深度学习如何大规模产业化?百度CTO王海峰CNCC2019深度解读 Posted 2021-04-20 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习如何大规模产业化?百度CTO王海峰CNCC2019深度解读相关的知识,希望对你有一定的参考价值。
10 月 17 日-19 日,2019 年中国计算机大会(CNCC2019)在苏州举办,本届大会以「智能+引领社会发展」为主题,1000 家机构的代表、8000 余人参展参会。
百度首席技术官王海峰在会上发表题为《深度学习平台支撑产业智能化》的演讲,分享了百度关于深度学习技术推动人工智能发展及产业化应用的思考,并深度解读百度飞桨深度学习平台的优势,以及与百度智能云结合助力产业智能化的成果。
各位专家,各位来宾大家上午好!
非常荣幸有机会参加世界计算机大会,非常感谢中国计算机学会及大会的邀请。
今天我跟大家分享的题目是《深度学习平台支撑产业智能化》。
我们都知道,从 18 世纪 60 年代开始,人类已经经历了三次工业革命。
第一次工业革命为我们带来了机械技术,第二次带来了电气技术,第三次带来了信息技术。
我们回顾这三次工业革命的历史会发现,驱动每一次工业革命的核心技术都有非常强的通用性。
虽然它可能是从某一个行业开始,比如机械技术最开始从纺织等行业开始,但最后都会应用于生产生活的方方面面,有非常强的通用性。
除了通用性以外,这些技术都会推动人类进入一个新的工业大生产阶段,而支撑这个工业大生产的技术有几个特点:
标准化、自动化、模块化。
而我们现在正处于第四次工业革命的开端,人工智能则是新一轮科技革命和产业变革的一个核心驱动力量。
人工智能会推动我们人类社会逐渐进入智能时代。
回顾人工智能技术的发展,人工智能技术的发展阶段有很多分类维度,我理解大概可以归结为:
最早期更多都是在用人工的规则,我 26 年前进入这一行的时候,其实也是在用人工规则来开发机器翻译系统;
后来逐渐开始机器学习,尤其是统计机器学习,在很长的一段时间里占主流地位,也产生了很大的影响,带来了很多应用产业的价值;
深度学习是机器学习的一个子方向,现在,深度学习逐渐成为新一代人工智能最核心的技术。
举几个例子,文字识别 OCR 技术早期是用规则+机器学习的方法来做,那时候,一个 OCR 技术系统可能会分为几部分,从区域检测、行分割、字分割、单字识别、语言模型解码、后处理等一步步做下来。
加入深度学习技术后,我们开始使用大数据进行训练,而且阶段目标也很明确,我们找到一些深度学习的特征,这个时候一个 OCR 系统就简化到只需要检测、识别两个过程,典型的基于深度学习的 OCR 系统大概是这样。
随着深度学习技术进一步发展,我们开始在 OCR 里面进行多任务的联合训练、端到端学习、特征复用/互补,这个时候,甚至这两个阶段也不用区分了,而是一体化地就把一个文字识别的任务给做了。
我们再看机器翻译。
26 年以前我进入人工智能领域就是在做机器翻译,当时我们用数以万计的规则写出一个翻译系统,其中包括很多语言专家的工作。
20 多年以前,我们做的这个系统曾得到全国比赛的第一,但是这个系统想继续发展,进入一个大规模产业化的阶段,仍然面临着很多问题。
比如说人工规则费时费力,而且随着规则的增加,冲突也越来越严重,挂一漏万,总是很难把所有的语言现象都覆盖到。
后来,统计机器翻译在机器翻译领域占据最主流技术的地位,像百度翻译八年以前上线的第一个版本的系统,其实就是统计机器翻译。
统计机器翻译的过程当中,仍然要一步一步来做,比如说先做统计的词对齐,然后做短语的提取,再做结构的对齐等等,其中也涉及到人工特征的提取、定向的优化,仍然很复杂。
大概四年多以前,百度上线了世界上第一个大规模的、基于神经网络的翻译产品,这时候我们可以进行端到端的学习了。
当然了,这样一个神经网络,或者说是深度学习的系统,也有它的不足之处,现在真正在线上跑的、每天服务数以亿计人的翻译系统,其实是以神经网络的机器翻译方法为主体,同时融合了一些规则、统计的技术。
刚才说起,随着深度学习的发展,这些技术越来越标准化、自动化。
大家可以看到深度学习有一个很重要的特点,就是通用性。
我们之前做机器学习的时候,有非常多的模型大家都耳熟能详,比如说 SVM、CRF 等等。
深度学习出现以后,人们发现,几乎我们看到的各种问题它都能很不错的解决,甚至能得到目前最佳的解决效果,这和以前的模型各有擅长不一样,它具有很强的通用性。
深度学习所处的位置,一方面它会向下对接芯片,像我们开发的深度学习框架,也会跟各个芯片厂商联合进行优化,前天我们还跟华为芯片一起做了一个联合优化的发布;
向上它会承接各种应用,不管是各种模型,还是真正的产品。
所以我们认为深度学习框架会是智能时代的一个操作系统。
我们真正把深度学习大规模产业化的时候,也会面临一些要解决的问题,比如说,开发这样一个深度学习的模型或者是系统,实现起来很复杂,开发效率很低,也很不容易;
而在训练的时候,我们在真正工业大生产中用的这些模型,比如说百度的产品,都是非常庞大的模型,进行超大的模型训练很困难;
到了部署阶段,还要考虑推理速度是不是够快,以及部署成本是不是可控合理。
针对这几个方面,我们开发了百度的深度学习平台「飞桨」,英文我们叫 PaddlePaddle。
我们认为它已经符合标准化、自动化、模块化的工业大生产特征。
飞桨底层的核心框架包括开发、训练、预测。
开发既可以支持动态图,也可以支持静态图;
训练可以支持大规模的分布式训练,也可以支持这种工业级的数据处理;
同时可以有不同版本部署在服务器上、在端上,以及做非常高效的压缩、安全加密等等。
核心框架之上有很多基础模型库,比如说自然语言处理的基础模型库、计算机视觉的基础模型库等等。
同时也会提供一些开发的套件,再往上会有各种工具组件,比如说网络的自动训练、迁移学习、强化学习、多任务学习等等。
此外,为了真正支撑各行各业的应用,我们提供很多使用者不需要理解底层这些技术、可以直接调用的服务平台。
比如 EasyDL,就是可以定制化训练和服务的,基本上可以不用了解深度学习背后的原理,零门槛就可以用它来开发自己的应用;
AI Studio 则是一个实训平台,很多大学也在用这样的平台上课、学习;
当然,还包括端计算模型生成平台。
飞桨是一个非常庞大的平台,我们着重在四方面发力、且具有领先性的技术。
首先从开发的角度,我们提供一个开发便捷的深度学习框架;
而从训练的角度,可以支持超大规模的训练;
从部署的角度,可以进行多端、多平台的高性能推理引擎的部署;
同时提供很多产业级的模型库。
从开发的角度,飞桨提供一个开发便捷的深度学习框架。
一方面,大家知道这些软件系统都是很多程序员
另外一个方面是设计网络结构,深度学习发展很多年,多数深度学习的系统网络都是人类专家来设计的,但是,设计网络结构是很专、很不容易的一件事情。
所以,我们开发网络结构的自动设计。
现在机器自动设计的网络,在很多情况下已经比人类专家设计的网络得到的效果还好。
另一个方面,大规模训练面临的挑战。
飞桨支持超大规模的特征、训练数据、模型参数、流式学习等等。
我们开发的这套系统现在已经可以支持万亿级参数模型,不止是能支持这样的训练,同时可以支持实时的更新。
说到多端多平台,飞桨能很好的支撑从服务器到端、不同的操作系统之间,甚至不同框架之间的无缝衔接。
这里是一些具体的数据,大家可以看到,我们通用架构的推理,它的速度是非常快的。
同时,刚才我提到的跟华为的合作,我们针对华为的 NPU 做了定向的优化,使它的推理速度得到进一步的提升。
另外一方面,所有这些基础框架,与真正的开发应用之间还有一步,我们定向地为不同的典型应用提供很多官方的模型库,比如说语言理解的、增强学习的、视觉的等等。
飞桨的这些模型都在大规模的应用中得到过验证,同时我们也在一些国际的比赛中测试了这些模型,夺得了很多个第一。
刚才讲的是基本的框架模型等等,另一方面,我们还有完备的工具组件,以及面向任务的开发套件,以及产业级的服务平台。
举几个例子,比如说语言理解,大家知道现在语言理解,我们也都基于深度学习框架来做,像百度的 ERNIE。
一方面,我们现在用的深度学习技术是从海量的数据里进行学习,但是它没有知识作为前提。
百度开发了一个非常庞大的,有 3000 多亿个事实的知识图谱,我们用知识来增强基于深度学习的语言理解框架,就产生了 ERNIE。
另一方面,我们又加入了持续学习的技术,从而让 ERNIE 有一个非常好的表现。
下面浅蓝色的线是现在 SOTA 最好的结果,我们用 ERNIE+百科知识——我们知识图谱也有很多来源——加进去以后,大家可以看到有很明显的提升。
我们更高兴地看到,持续加入不同的知识,比如加入对话知识、篇章结构知识等等,这个系统还可以进一步提升它的性能。
这是前面讲的一系列套件之一,可以零门槛进入的定制化训练和服务平台。
我们这些平台,希望能降低门槛,帮助各行各业来加速整个技术创新。
现在大概是什么状态呢?
现在我们已经服务了 150 多万的开发者,其中包括超过 6.5 万个企业。
在这个平台上,他们自己训练了已经有 16.9 万个模型。
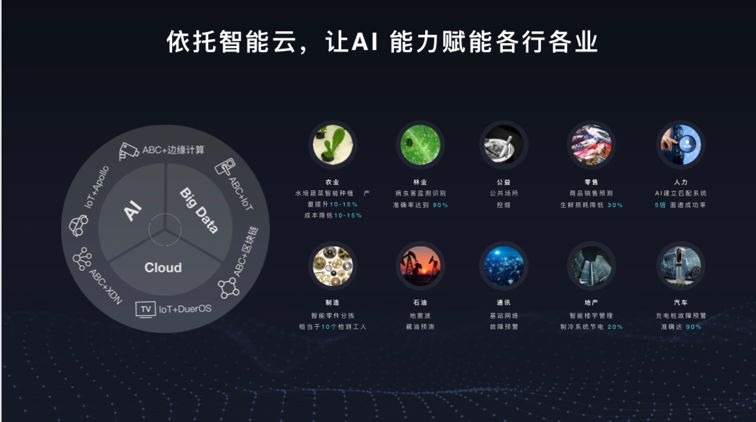
飞桨深度学习开源开放平台跟百度的智能云也有很好的结合,依托云服务更多的客户,让 AI 可以赋能各行各业。
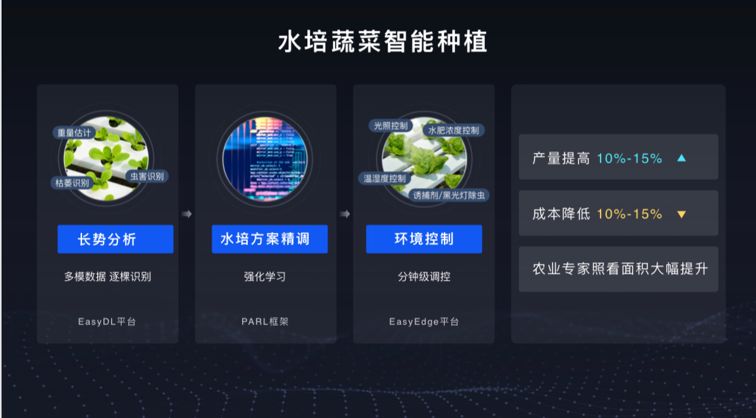
这里有一些例子,比如说在农业,我们帮助水培蔬菜的智能种植;
在林业,帮助病虫害的监测识别;
以及公共场所的控烟、商品销售的预测、人力资源系统的自动匹配、制造业零件的分拣,以及地震波、藏油预测,以及更广泛地覆盖通讯行业、地产、汽车等等领域,各行各业都基于这个平台都得到了智能化的升级。
比如水培蔬菜智能种植,我们通过深度学习平台支持它进行长势分析、水培方案的精调、环境的控制,使产量得以提高,同时成本得以降低。
智能虫情监测也是一样,系统的识别准确率已经相当于人类专家的水平,而且监控的周期也从一周缩短到一小时。
精密零件智能分拣的案例中,我们真正用这个深度学习系统的时候,还是有不少事情要做,比如说如何选择分拣的模型,中间也会涉及一些数据的标注,尤其是一些错误 case 的积累等等,然后在飞桨平台上进行训练升级。
这是一个工业安全生产监控的例子,昨天在另一个会上,有一个来宾问我,他们特别想在一些场景下,监控一些不当的环节,比如说生产环境里打手机、抽烟、跃过护栏等等。
这些都可以通过飞桨的平台自动实现。
在其他的行业中,比如国家重大工程用地的检测,智慧司法,以及 AI 眼底筛查都在应用飞桨,还有很多有温度的案例,比如 AI 寻人,一个孩子 4 岁的时候离家走失,27 年以后,通过人脸比对技术,又帮助这个家庭把孩子找回来了,实现了家庭的团聚。
截止到今年 6 月,百度 AI 寻人已经帮助 6700 个家庭团圆。
除此之外,还有 AI 助盲行动、AI 助老兵圆梦等等这些案例。
回到深度学习,刚才我说,各行各业都会从其中受益,实现自己的智能化升级。
这是一个第三方的报告,我们可以看到,深度学习给不同的行业都会带来提升,平均大概是 62% 的水平。
这就是我今天要分享的。
百度的飞桨深度学习平台非常愿意跟大家一起,帮助大家实现自己行业的智能化升级,推动人工智能的发展,谢谢大家!
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content @jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
以上是关于深度学习如何大规模产业化?百度CTO王海峰CNCC2019深度解读的主要内容,如果未能解决你的问题,请参考以下文章
百度Create AI开发者大会,百度CTO王海峰:“深度学习+”是创新发展新引擎
百度Create AI开发者大会,百度CTO王海峰:“深度学习+”是创新发展新引擎
百度Create AI开发者大会,百度CTO王海峰:“深度学习+”是创新发展新引擎
百度CTO王海峰:AI大生产平台再升级 助力中国科技自立自强
「深度学习+」阶段来了!百度王海峰:深度学习多维度逐渐成熟,创新创造大有可为...
北京人工智能产业联盟成立,百度CTO王海峰出任联盟理事长