深度学习笔记:前向网络
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习笔记:前向网络相关的知识,希望对你有一定的参考价值。
编辑整理:Hoh
内容来源:作者授权
出品社区:DataFun
注:欢迎转载,转载请注明出处
▌10.1.1 网络结构
前向神经网络由若干层隐藏层和一层输出层构成,网络中层和层之间为全连接方式,连接权重参数及偏执权值即为要训练的参数。隐藏层由若干神经元组成,每层一般采用统一的激活函数,实际上应用中所有隐藏层常常采用统一的激活函数。训练过程中在输出层之后加入损失函数即可进行网络中涉及参数的训练。
如下为一个包含两层隐藏层的前向网络:
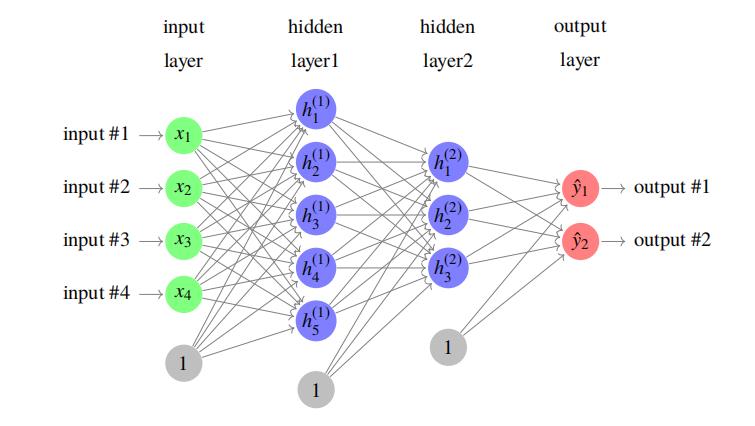
输入层为向量 x∈R4,第一层隐藏层输出向量为 h(1)∈R5,输入层和隐藏层间的连接权重参数为 W(1)∈R5×4,对应的偏执项为 b(1)∈R5,第二层隐藏层输出向量为 h(2)∈R3, 和前一层的连接权重参数为 W(2)∈R3×4,对应的偏执项为 b(2)∈R3,输出层输出向量为 yˆ,和前一层的连接权重参数为 W(3)∈R2×3,对应的偏执项为 b(3)∈R2。假设隐藏层统一采用 ReLU 激活函数,输出层采用 Identity 映射,若问题为分类问题,则对输出层统一应用 Softmax 归一化操作,则输出 yˆi 为当前输入输入属于该类别的概率。该网络结构对应的数据变换如下:
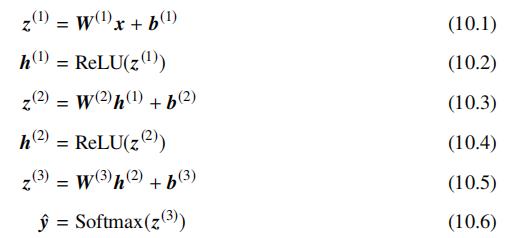
要训练该网络只需要在网络的最后一层引入 Cross-Entropy Loss,及标注类别 y:
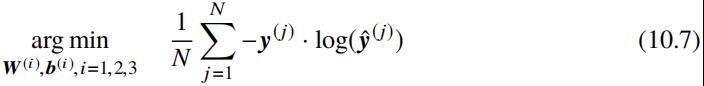
通过随机梯度下降算法优化权重参数及偏执项,最小化损失函数。在前向网络的基础上,下面我们来回顾该网络类型在不同类型的问题上的应用。
▌10.1.2 语言模型
语言模型的任务是预测一句话发生的概率,即:

由贝叶斯法则可知,上述公式可变换为:
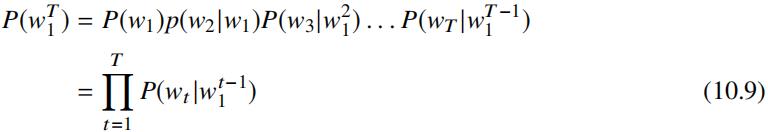
由上述公式可知,若直接估计上述公式中概率 P(wi| w1i-1),则序列会变得极其稀疏,以致在训练样本中对应的统计量不够充分,一般采用 n-gram(譬如 n=3),及假设每个词发生的概率仅依赖于历史 n-1 个词,在该假设下:
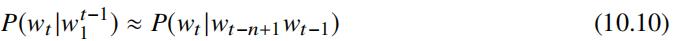
若采用传统的语言模型模型,则可以通过若干平滑算法估计上述 n-gram 的概率。这里我们看一下如何通过前向神经网络估计给定历史 n 个词时,当前词发生的概率。
Yoshua Bengio 等人于 2003 年提出了 ( A Neural Probabilistic Language Model ) 基于前向神经网络的语言模型架构如下所示:
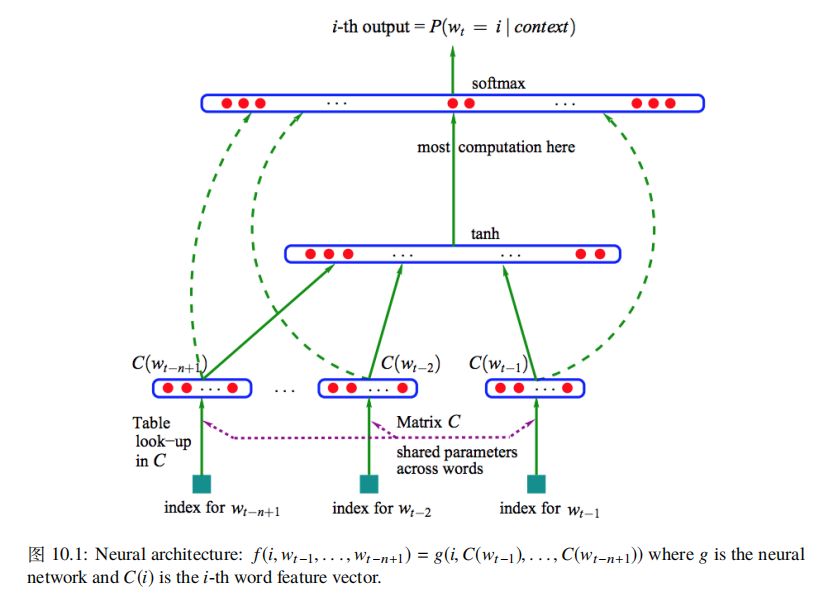
该网络架对应的公式如下:
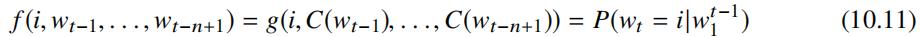
其中 C 表示将词映射为词向量操作,可以表示为 |V|×m 的矩阵,该矩阵的第 i 行特征向量 C(i) 表示词 wi,函数 g 表示词向量操作之上的网络架构,对应的变换如下:
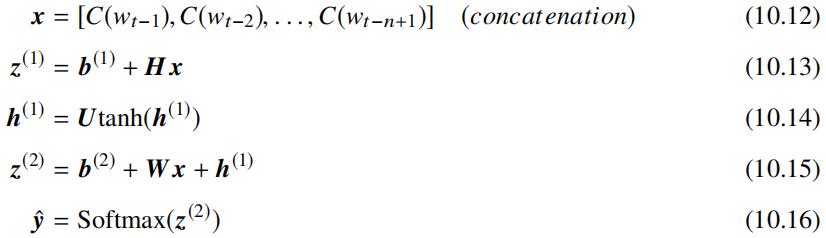
其中 x∈R(n-1)m,H∈Rh×(n-1)m,b(1)∈Rh,W∈R|V|×(n-1)m,b(2)∈R|V|,训练该网络架构中的参数可以通过最小化 Cross-Entropy Loss 完成。
▌10.1.3 排序问题
这里讨论的排序问题为网页搜索或相似问题上的排序任务,该类问题为,给定查询 Q,对文档 D1, . . ., D2 进行排序。因此这类问题可以转化为计算 Q 和每个 Di 的相关性得分,基于该得分对文档进行排序。Po-Sen Huang 等人 ( Learning Deep Structured Semantic Models for Web Search using Clickthrough Data ) 给出了基于用户点击数据学习查询和文档相关性的 DSSM 模型,该模型的架构如下所示:
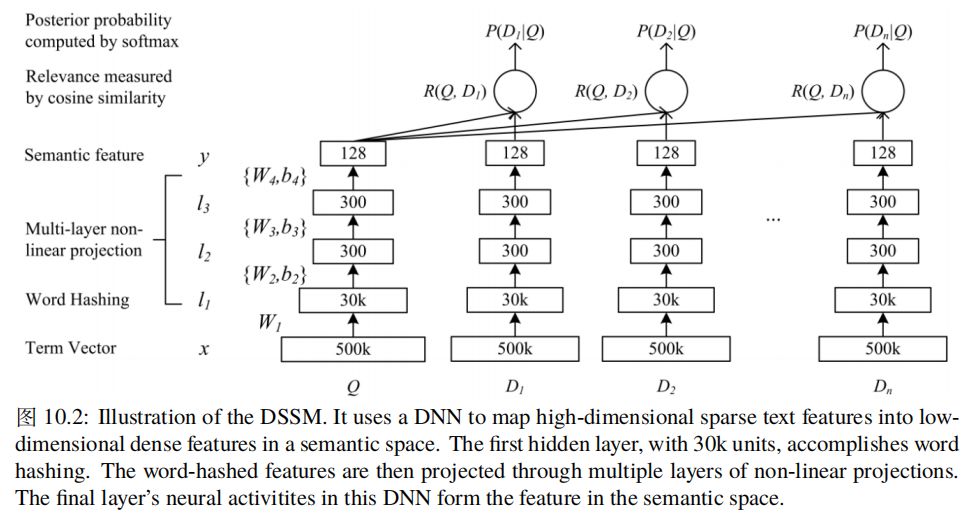
上述架构图中 Term Vector 这一层采用的词表大小为 500k,因此对于的向量维度为 500k,即将 query 和 doc 切词后,采用 one-hot 编码方案表示为 500k 大小的词向量,若直接将该词向量应用于前向网络,则 W1R500k×30k,若采用 flfloat32 类型存储该权重矩阵,则需要约 56GB 大小内存或显存空间,为了解决该问题,l1 层的变换采用 Word Hashing 的方案,即将所有词(譬如:good)加上头尾表示符 #(譬如:#good#),在此基础上将所有词表示为字构成的 3 元(譬如:#go, goo, ood, od#),经过该处理后,词表大小由 500k 降低至 30k。因此查询 Q 和文档 D 最终均采用三元词表表示,该词表大小 30k。假设 x 表示输入词向量,y 表示输出向量。该网络架构对应的公式如下:
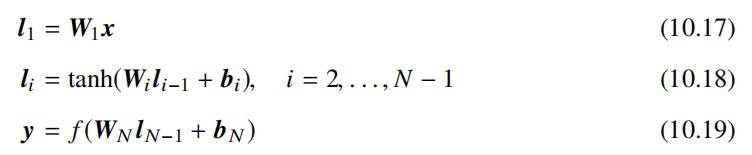
查询 Q 和文档 D 间的语义相似度为通过如下公式衡量:
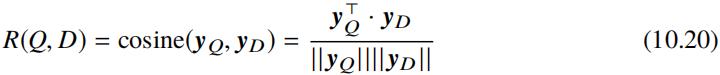
由网络架构图可知上述公式中的 yQ 和 yD 为查询和文档的语义向量表示。应用于网页搜 索时,可以根据文档和当前查询的语义相关性得分进行排序。
现在我们来看如何对 DSSM 网络进行训练,假设给定查询 Q 及返回的文档列表 D1, . . ., Dn,假设该查询下发生点击的文档为 D+ 为相关文档,没有发生的点击的文档为不相关文档,假设集合 D 表示要排序的文档集合,集合 D 由文档 D+ 及 4 个随机抽取的未点击文档集 {Dj- : j = 1, . . ., 4} 构成。因此给定查询 Q 和文档 D 和查询的语义相似度得分后,可以计算每个文档 D 在查询 Q 下的相似度后验概率概率如下:
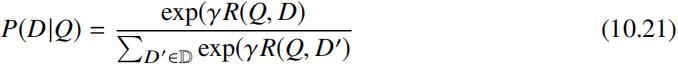
上述公式中 γ 为平滑系数,可以通过验证集调优选取。因此可以通过最小化如下Cross Entropy Loss 完成网络架构中的参数训练:
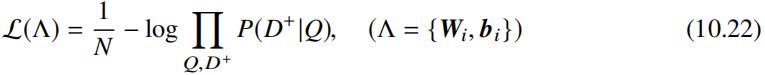
▌10.1.4 推荐问题
我们日常生活中不论看新闻资讯还是看长短视频或访问电子商务类网站,一般都能得到我们喜欢的信息,这背后推荐技术起到了至关重要的作用,这类技术一般涉及到对四类
信息的处理,这四类信息分别为:
用户维度:年龄、性别、位置、标签等
用户行为维度:用户过去点击过的商品或新闻列表或看的视频列表等
场景维度:用户当前访问所用的设备、时间、语言等信息
条目维度:当前条目的 id,标签信息等
通过前向神经网络融合这四类信息,最终表现为用户 U ( User ) 对当前条目 I ( Item ) 感兴趣的概率。因此这类问题最终转化为二分类问题,即用户点击当前条目的概率,可以通过 logistic regression 表示,模型参数搜索可以通过最小化 Cross-Entropy Loss 完成。这里以 Youtube 视频推荐为例来看前向网络在推荐问题上的应用,Paul Covington 等人 ( Deep Neural Networks for YouTube Recommendations ) 给出了前向网络在 Youtube 推荐问题上的两阶段应用,推荐架构总体如下所示:
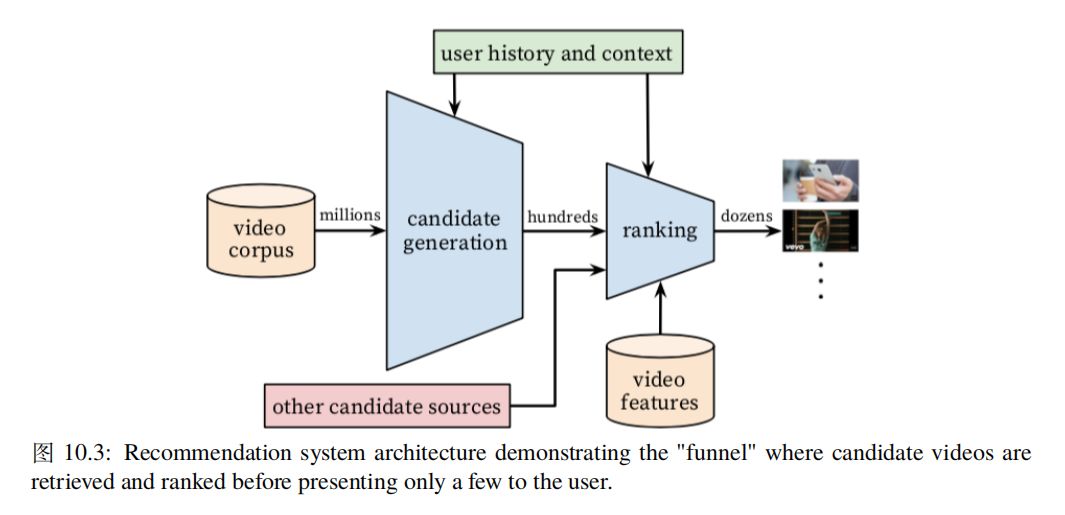
从上述推荐架构图可见,推荐过程分为两个阶段:
备选生成阶段:该阶段需要从 Youtube 全量数据中生成几百个视频备选
排序阶段:该阶段对几百个视频备选进行精排序以便优化用户观看时长
1. 备选生成
该阶段需要从 Youtube 全量数据中生成几百个视频备选,这篇 Paul Covington 等人将该问题看成是一个极端多分类问题,及给定用户 U 和场景 C (Context) 的情况下,用户在时间 t 观看 (wt) 全量库 V 中视频 i 的概率,公式描述如下:
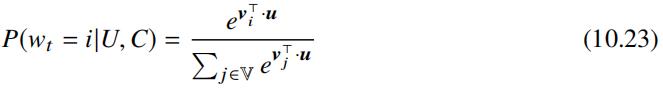
其中 u ∈ Rd 表示用户维度的向量表示,vj 表示每个备选视频的向量表示。考虑到全量视频库 V 视频数一般为百万级,因此若直接将上述公式应用于 Cross-Entropy Loss,则学习效率低下,文章中提及了 Sebastien Jean 等人 ( On Using Very Large Target Vocabulary for Neural Machine Translation ) 在机器翻译领域解决大词表导致归一化计算开销较高问题的工作,但其紧接着提及针对每个正样本最小化正类别的交叉熵损失,同时抽样若干负类别最小化负样本交叉熵损失,因此分析其训练方法更加类似于 Tomas Mikolov 等人采用的负样本采样方法,而且问题定义类似,均是学习向量表示。实际训练过程中可以采用带权重的负采样 ( Negative Sampling with Importance Weighting ) 方法,对于每个正样本采样的负样本数为几千个。如下是 Tomas Mikolov 等人 ( Distributed Representations of Words and Phrases and their Compositionality ) 给出的带权重负采样方法:
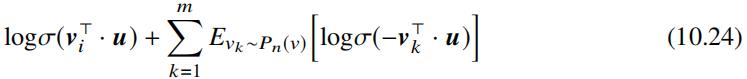
上述公式中 vi 表示正样本,vk 表示负样本。Pn(v) 表示采样权重,Mikolov 等人在文章中建议采用一元权重,在 Youtube 视频推荐场景下可以考虑采用视频观看时长 Tvk 来类似每个词发生的次数,并对该该值取 3/4 次方,概率质量函数如下:

可以看到对公式10.24取负,并最小化该值,即可以搜索网络架构中涉及的权重参数。
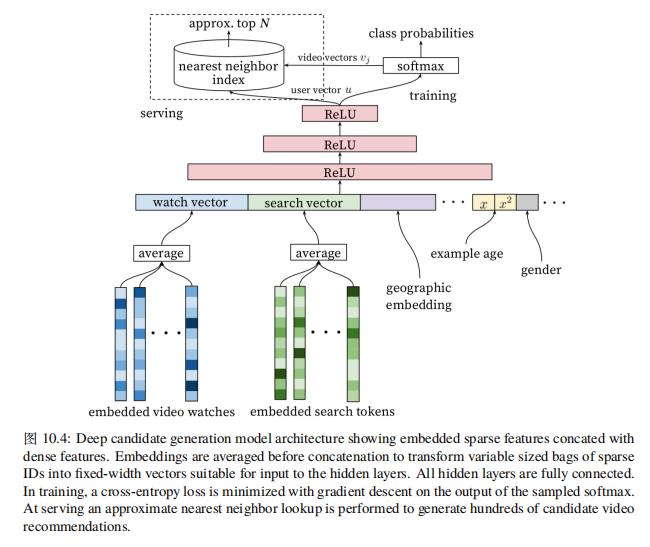
下面我们来看如何通过前向网络将用户表示为向量 u,将视频表示为向量 v,视频向量表示可以通过查 embedding 表直接生成,考虑到视频自身属性不会发生变化,因此召回阶段可以这样表示。Paul Covington 等人给出图10.4描述的备选生成网络架构。这里不对该前向网络进行进一步解释,具体可参考该论文。通过备选生成网络生成几百个备选视频后需要对这些视频进行进一步排序,以便优化最终的观看时长。
2. 排序
该阶段的主要任务是预测训练样本的期望观看时长,训练样本中的正样本为有点击的视频曝光,负样本为无点击的视频曝光,每条正样本含有用户观看视频的时长信息。为了预测用户对视频的期望观看时长,Paul Covington 等人采用了加权逻辑回归方法。模型训练采用 Cross-Entropy Loss 对逻辑回归函数进行训练,训练时对正样本采用观看时长进行加权,负样本的对应的加权系数为 1。通过该方法逻辑回归函数学习到的 odds 即为用户 U 观看视频 I 的期望时长。
这里有必要对 odds 进行一定的解释,odds 表示样本属于某个类别的概率和不属于该类别的概率的比值,公式如下:

考虑到对于所有正样本均引入了观看时长 Ti 作为样本权重,因此正样本发生的概率由 P(y = true|xi) 变为 TiP(y = true|xi),因此有:
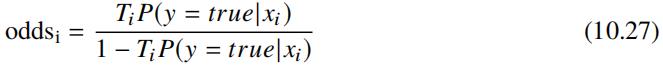
考虑到 P(y = true|x) 很小,上式可进一步简化为如下形式:
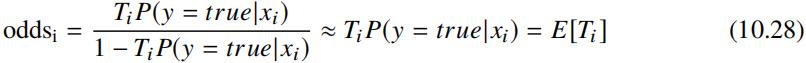
由上述公式可见采用观看时长 Ti 对正样本进行加权后,oddsi 即为用户的观看的期望。
下面我来求取 odds 对应的计算形式,对 odds 取自然对数,即可得到公式:

其中 Θ 表示模型参数,f 表示样本 x 对应的特征向量。上述公式中的左边部分称为 logit 函数:
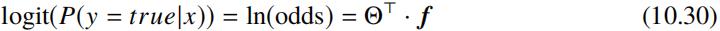
对上述公式两边进行指数变换,即得到 odds 的计算形式:

上述公式即为论文中提及的用于 Youtube 线上视频排序阶段采用的排序公式,该公式对应用户 U 观看视频 I 的期望观看时长。排序阶段采用的前向网络架构如下所示:
这里不对该前向网络进行进一步解释,具体可参考该论文。最后需要说明的是无论是备选生成网络还是排序网络,在输入层均涉及到大量的离散特征需要进行向量化映射操作,并将映射后的向量作为上层网络的输入,考虑到离散特征的规模往往在十亿以上的级别,因此可以将上层稠密网络和输入层的向量化映射在模型定义层面分开处理,譬如在 tensorflow 中可以以 placeholder 的形式定义对应的下层网络的向量化映射的输入,这样拆分带来的好处是在训练阶段可以采用参数服务器进行模型训练,并在保存模型阶段将上层模型和稀疏映射向量分开保存,这样线上服务时可以在 tensorflow serving 中只加载上层稠密模型,并将稀疏特征对应的向量存储到 redis 这类分布式存储中。
——END——
文章推荐:
DataFun:
专注于大数据、人工智能领域的知识分享平台。
一个「在看」,一段时光! 以上是关于深度学习笔记:前向网络的主要内容,如果未能解决你的问题,请参考以下文章 深层神经网络——吴恩达DeepLearning.ai深度学习笔记之神经网络和深度学习 斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时12&&13 斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时8&&9