一个高度近视眼的深度学习实践
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个高度近视眼的深度学习实践相关的知识,希望对你有一定的参考价值。
傍晚,忙了一天的 Ray 终于下班了,摘下眼镜休息下疲劳的双眼,他走到公交车站等 23 路公交车准备回家。
对于一个高度近视眼的人来说,Ray 每天都有很多烦恼,因为他看迎面而来的人是这样婶儿的。
每次公交车要过来,他都看不清车身上的号码,这严重影响他挤车的战斗力。
别问我他为什么不戴眼镜,爱臭美的近视眼们都知道为啥。他想起以前在国外出差,公交车上的号码总是以很大的字号印在车身上,就算视力不好也可以看得很清楚。
每到这个时候,Ray 都想跟市政建设提个意见,要是公交车的号码能来个大字版的,那多方便啊!

天色越来越晚,好几辆公交车驶过去了,他还站在原地,这会儿又一辆车来了,他打算先上车问一下司机。一只脚刚踏上车,话还没说出来,就被一个大姐撞飞了。他捂着胳膊问:“司机师傅,这是 23 路吗?”司机没好气地说:“你逗我呢,外面不写着呢嘛,你是不认字吗?”Ray 无辜地说:“我是看不清。”司机一脸黑线,打发他赶快往后走。这样尴尬的场景已经不是第一次了,他倍感无助。
忽然,天灵盖被一个灵感击中,大脑伸了一个懒腰,一个 idea 就这样诞生了:“要不做一个手机 App 吧,可以用手机拍摄车身照片,然后自动识别照片中公交车的号码,这样问题不就解决了嘛!”

正在暗自窃喜时,他转念一想又似乎想得过于美好了,要怎么识别车上的号码呢?拍下来的照片受到光照、形状、颜色、角度等诸多因素的影响,这样的话问题开始有一点变复杂了。
Ray 想起了做图像处理的朋友 Cavy,也许他有办法。于是他把自己的想法跟 Cavy 说了一遍。两人兴高采烈地探讨起这个问题。
Cavy:“你觉得深度学习算法怎么样?是不可以考虑下?”
Ray:“就是那个打败人类顶尖围棋高手的深度学习吗?太深奥了吧!”
Cavy:“没错!就是那个深度学习。其实它的原理并不复杂,不过你要会一些高数的基础知识才行。”
Ray:“数学......我看我还是先从原理来了解下吧!”

Cavy:“那我简单跟你说说。深度学习是基于神经网络,而神经网络是基于人类大脑的神经网络。人脑的神经网络是由许许多多神经元组成的网络。还是先从人脑的神经元说起。”
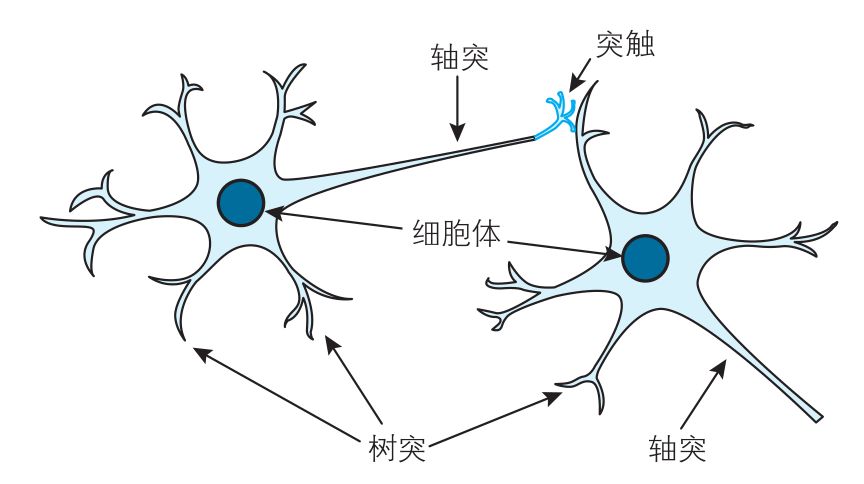
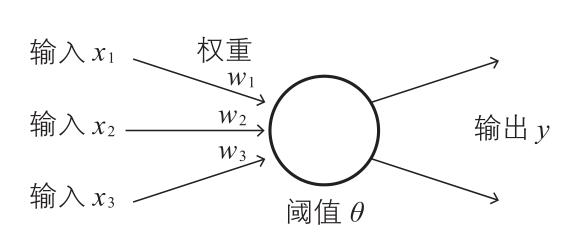
“神经元包含了轴突、树突、细胞体等,树突负责从其他神经元接收信息,细胞体负责处理接收到的信息,轴突负责把细胞体处理后的信息输出到其他神经元。细胞体判断输入信号加权之和如果超过某个固定的阈值,就通过轴突发出信号(0或1),这个过程称为点火。可以抽象为数学模型如下(称为神经单元):
点火可以用数学式子表示为:
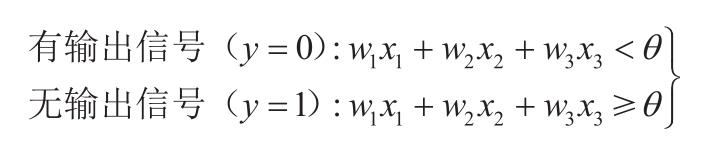
我们引入加权输入z:
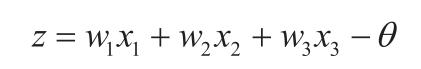
点火式子可以用单位阶跃函数y=u(z)表示。”
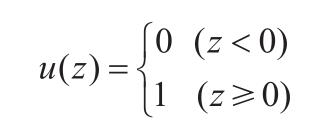
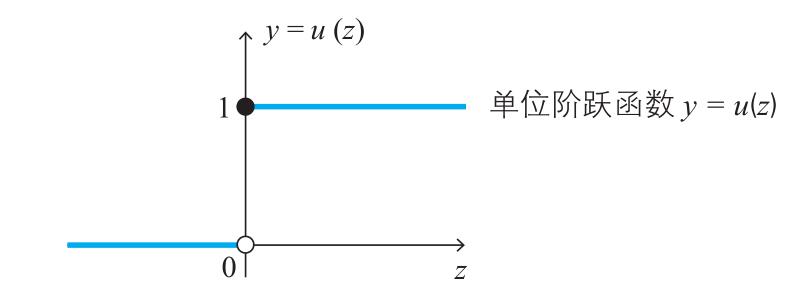
Ray:“单位阶跃函数有间断点,这看起来有点棘手啊。”
Cavy:“我们可以用其他函数 y=a(z)(称为激活函数)来代替单位阶跃函数,将间断点光滑化,常用的是 Sigmoid 函数。此外,为了使式子形式统一,我们把 -θ 替换为偏置 b。加权输入表示为:
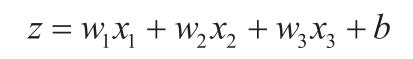
Sigmoid 函数定义如下:
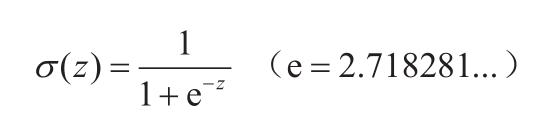
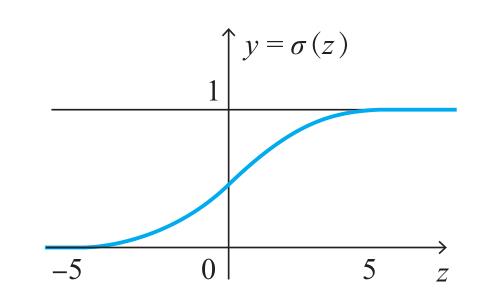
Ray:“额......说慢点。意思是,Sigmoid 是个光滑函数,处理起来方便许多。神经网络就是将这些神经单元连接起来的,对吧?”
Cavy:“是的,看来你还可以嘛!也不是一点都不懂。其实它把多个神经单元按照一定的层次结构连接起来就形成神经网络。以公交车号码识别为例,我们把公交车号码识别的问题简化一下。假设我们需要在 4*3 像素的单色二值图像中识别数字 0 和 1。可以分 3 层来组织神经网络,分别是输入层、隐藏层和输出层。如下图所示:
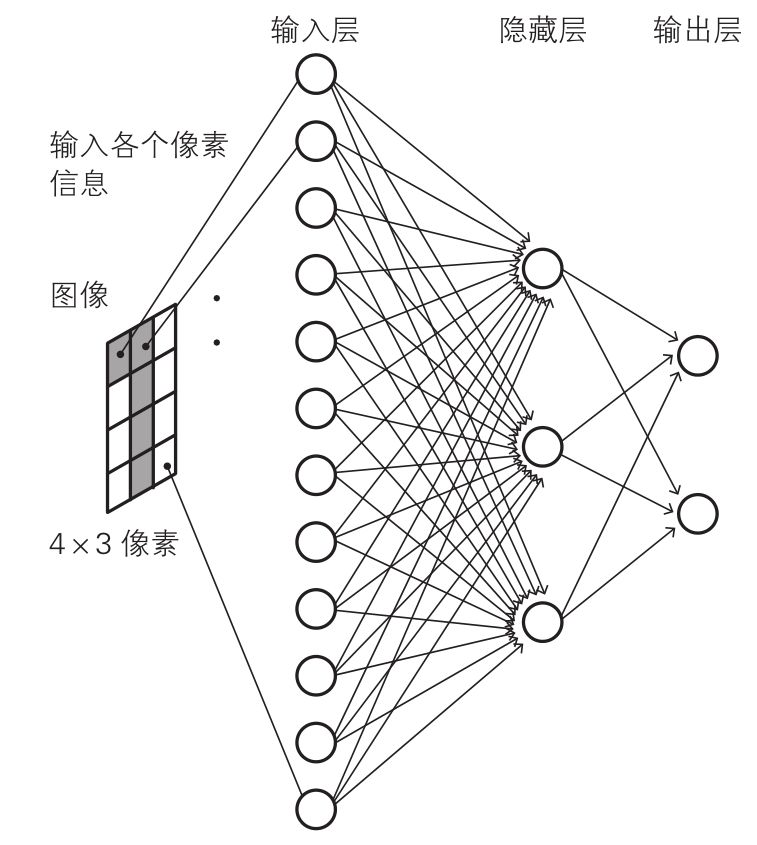
输入层有 12 个神经单元,每个神经单元对应一个像素位置(一共有4*3=12个),从图像读取像素信息。隐藏层有 3 个神经单元,负责提取图像的特征。输出层有 2 个神经单元负责输出整个网络的判断结果,上方神经单元的输出值较大则表示网络识别出数字 0,反之如果输出层下方神经单元的输出值较大则表示网络识别出数字 1。
我们约定变量和参数的表示。我们对层从左到右编号,左边输入层为层 1,中间隐藏层为层 2,右边输出层为层 3。变量和参数如下表所示。
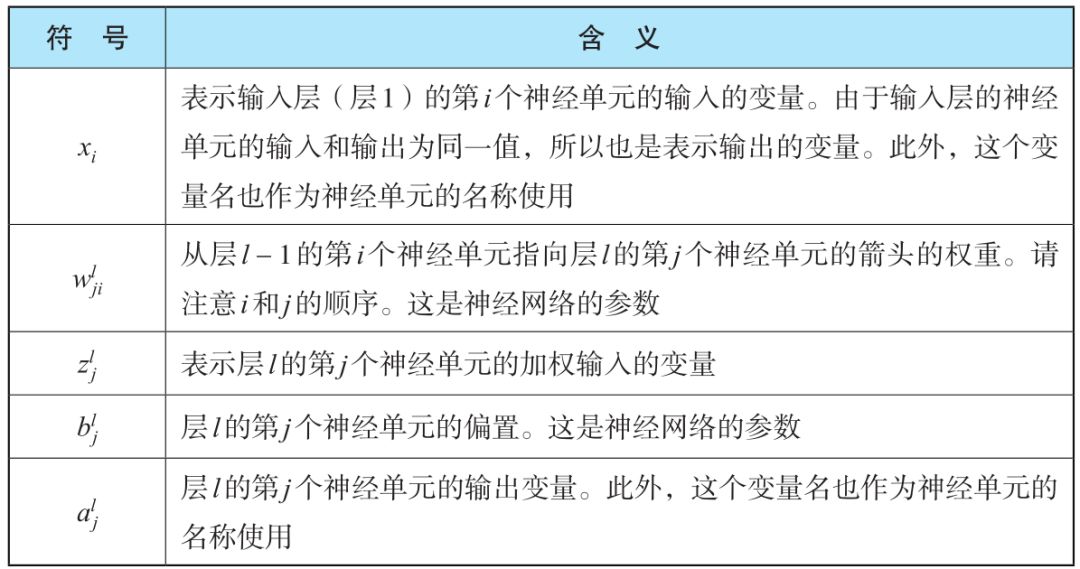
利用这个表格的符号,神经网络可以表示如下:
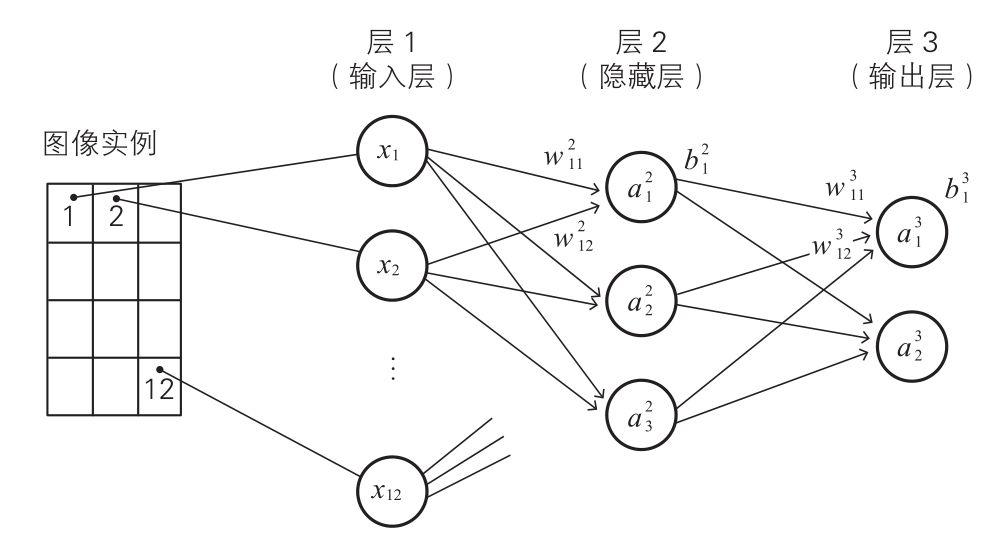
我们写出各层的关系式。输入层比较简单,神经单元的输入值与输出值相同,关系式如下:
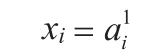
隐藏层中,激活函数为 a(z),关系式如下:
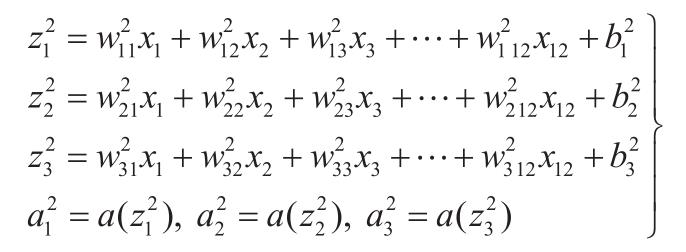
同样地,输出层的关系式如下:
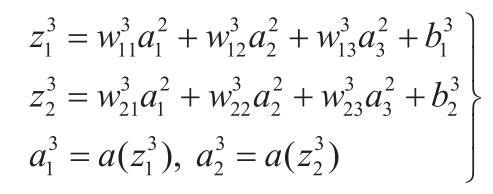
有了以上关系式,如果确定权重、偏置等参数,我们就得到一个可以识别 4*3 像素图片中数字 0 和 1 的神经网络。”
“艾玛......让我缓缓,说太多了,口干舌燥的。”Cavy边说边喝了口水。

Ray:“我觉得我们可以预先准备一些图像数据并标记好答案,通过调整神经网络的权重和参数,使神经网络的输出与图像数据吻合,这样就可以了。”
Cavy:“Bingo!这就涉及到神经网络的学习了。其实我们的目标是神经网络的输出值(预测值)与预先标记的答案(正解)总体误差达到最小。假设我们有 64 张图像作为学习数据,图像与正解对应如下:
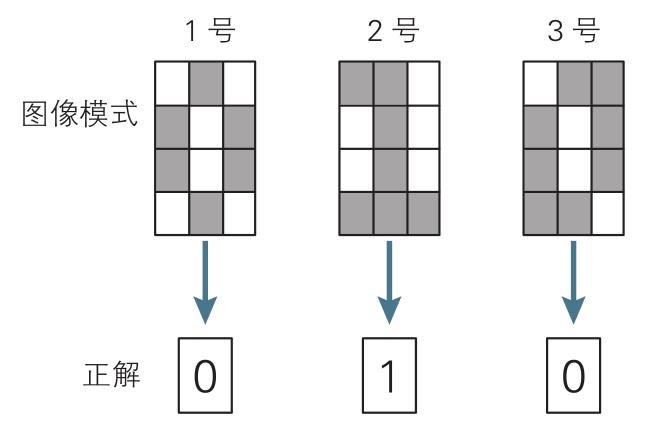
我们引入 2 个变量 t1、t2 作为正解变量,取值如下:

我们用平方误差 C 作为目标函数,定义如下:
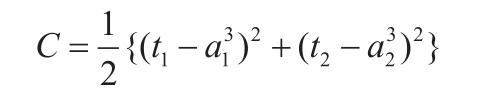
把 64 张输入图像的平方误差加起来,
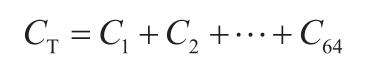
得到的总体误差 CT 称为神经网络的代价函数。”
Ray:“数学上应该有很多最优化数值方法求代价函数 CT 最小值。”
Cavy:“我们通常考虑梯度下降法。这个可厉害了,梯度下降法的原理就跟下山类似,从一个初始位置:
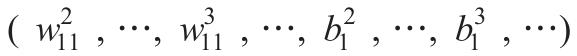
沿着梯度的反方向(局部下降最快)走一定的步长 η(学习率)。
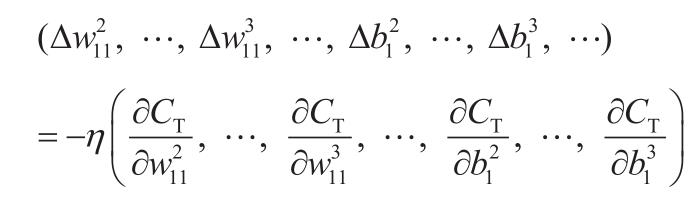
到一个新的位置:
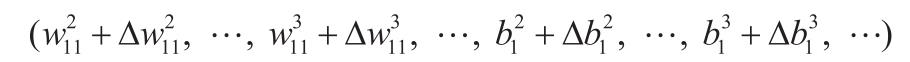
如此迭代若干次后达到最小值点。这里的关键是梯度的计算。”
Ray:“导数计算看起来非常繁杂,不好计算,有点难度。”
Cavy:“为了避免繁杂的导数计算,我们首先引入神经单元误差:
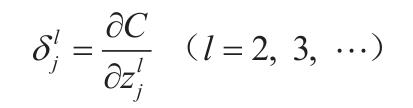
通过数学推导,可以把梯度分量用神经单元误差表示如下:
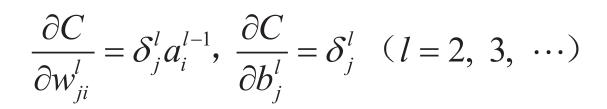
而神经单元误差有如下漂亮的递推关系(m 为层 l+1 的神经单元数目):
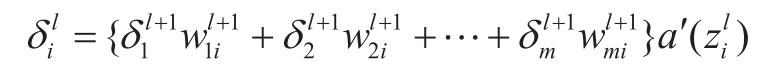
用以上式子逐层递推计算,就可以避免繁杂的偏导数。这就是误差反向传播法。”
Ray:“这个方法很精妙!那回到我的问题,实际的公交车号码由 0-9 共十个数字组成,这就需要更多的神经单元组成更大的神经网络了。”
Cavy:“可以用卷积神经网络(CNN)来减少神经元数量,简化网络,提高效率。卷积神经网络是深度学习的一种实现方式,它是由输入层、隐藏层和输出层组成。它的隐藏层具有一定结构,由卷积层和池化层组成。卷积层的神经单元负责扫描图像,找出特征在图像中的分布。池化层神经单元负责整合卷积层的结果。这样只需用较少的基本特征就可以进行图像识别。”
Ray:“emmmm......话说我觉得我还是要深入了解一下才行,跟你比还是差点火候。”
Cavy:“看你还算机灵,送你一本学深度学习的书吧。兄弟有空记得看看。这本《动手学深度学习》我就送你了。这个书里包含了书籍和视频,还有专门的讨论区,亚马逊专家会不定时给予回复,其他的小伙伴也会给帮助,一定要看!!你要想学深度学习看这个可以了”
Ray:“听起来还不错!希望能拯救我的秃头。”(狗头.jpg)

☟☟☟
《动手学深度学习 (平装)》
出版时间:2019年6月

扫码查看详情
《动手学深度学习 (平装)》
出版时间:2019年6月
扫码查看详情
编辑推荐:
亚马逊科学家李沐等重磅作品;
交互式实战环境下动手学深度学习的全新模式,原理与实战完美结合
韩家炜/Bernhard Schölkopf/周志华/张潼/余凯/漆远/沈强 联袂推荐
加州大学伯克利等全球15 所知名大学用于教学;
本书旨在向读者交付有关深度学习的交互式学习体验。书中不仅阐述深度学习的算法原理,还演示它们的实现和运行。
与传统图书不同,本书的每一节都是一个可以下载并运行的 Jupyter 记事本,它将文字、公式、图像、代码和运行结果结合在了一起。此外,读者还可以访问并参与书中内容的讨论。
那这本大神新作
是否很贵呢?
在CSDN当然是不贵的
现在购买可享受8.5折优惠价
扫描下方二维码即可购买!

以上是关于一个高度近视眼的深度学习实践的主要内容,如果未能解决你的问题,请参考以下文章
学习参考+《深度学习基于Keras的Python实践》PDF+ 源代码+魏贞原