世界欠他一个图灵奖! LSTM之父的深度学习“奇迹之年” Posted 2021-04-20 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世界欠他一个图灵奖! LSTM之父的深度学习“奇迹之年”相关的知识,希望对你有一定的参考价值。
【新智元导读】 LSTM的发明人、著名深度学习专家Jürgen Schmidhuber详细论述了近30年前,即1990~1991年之间他和团队进行的许多研究。他们的早期思想为当今的许多深度学习前沿研究奠定了基础,包括 LSTM、元学习、注意力机制和强化学习等。 > >>
近日,LSTM 的发明人、著名深度学习专家 Jürgen Schmidhuber 发表了一篇长文,详细论述了近 30 年前,即 1990~1991 年之间他和团队进行的许多研究。
Jürgen 表示,深度学习革命背后的许多基本思想,是在 1990~1991 年不到 12 个月的时间里,在慕尼黑理工大学 (TU Munich) 产生的,而这些思想为当今的许多深度学习前沿研究奠定了基础,包括 LSTM、元学习、注意力机制和强化学习等。
Jürgen 称这一年为 “ 奇迹之年 ”。 尽管当时他们发表的工作几乎无人问津,但四分之一个世纪后,基于这些想法的神经网络不断得到改进,其应用出现在智能手机等 30 多亿设备、每天被使用数十亿次,在全世界消耗大量的计算资源。
在 AI 领域,深度学习三巨头 Geoffrey Hinton、Yoshua Bengio 和 Yann LeCun 人尽皆知,Jürgen Schmidhuber 的知名度却远不及三人,尽管他发明的 LSTM 被认为是教科书级别的贡献。他 是被图灵奖遗忘的大神。 在Hinton 等三巨头获图灵奖之时,Jürgen 却得到了很大的呼声:“为什么Jürgen 没有得图灵奖?”
Jürgen Schmidhuber 是瑞士 Dalle Molle 人工智能研究所的联合主任,他 1997 年提出的 LSTM 现在被广泛应用在谷歌翻译、苹果 Siri、亚马逊 Alex 等应用中,可谓是深度学习领域最商业化的技术之一。
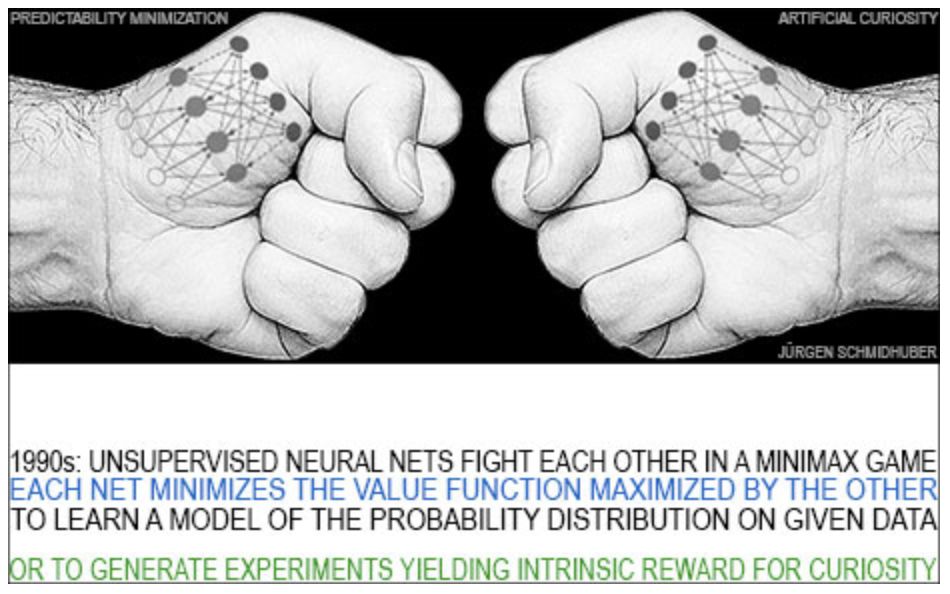
除了 LSTM 之外,Jürgen Schmidhuber “引以为傲” 的还有他在 1992 年提出的 PM(Predictability Minimization)模型。他坚持认为现在大火的 GAN 就是 PM 的变种,两者的区别就在于方向是反的,为此,Jürgen 还和 GAN 的提出者 Ian Goodfellow 有过线上线下激烈的交锋,引起业界广泛讨论。
至于对深度学习三巨头 Hinton、Bengio 和 LeCun,Jürgen Schmidhuber 也打过几轮口水仗,认为三人在自己的圈子里玩,对深度学习领域其他更早期先驱人物的贡献则只字不提。
是否人们对 Jürgen Schmidhuber 的贡献认知过少?这篇文章详述了 Jürgen 和他的团队在 “奇迹之年” 做出的许多研究,提出的许多思想,非常值得一看。
第 1 节:第一个非常深的神经网络,基于无监督预训练 (1991)
第 2 节:将神经网络压缩 / 蒸馏成另一个 (1991)
第 3 节:基本的深度学习问题:梯度消失 / 爆炸 (1991)
第 4 节:长短时记忆网络:有监督深度学习 (1991 年以来的基本想法)
第 5 节:通过对抗生成神经网络的人工好奇心 (1990)
第 6 节:通过最大化学习神经网络学习进度的人工好奇心 (1991)
第 7 节:用于无监督数据建模的对抗网络 (1991)
第 8 节:端到端可微快速权重:让神经网络学习编程神经网络 (1991)
第 9 节:通过神经网络学习序列注意力 (1990)
第 11 节:用循环神经世界模型做规划和强化学习 (1990)
第 12 节:将目标定义作为额外的 NN 输入 (1990)
第 13 节:作为 NN 输入 / 通用值函数的高维奖励信号 (1990)
第 15 节:用网络来调整网络 / 合成梯度 (1990)
第 16 节:在线递归神经网络的 O (n^3) 梯度 (1991)
第 19 节:从无监督预训练到纯粹监督学习 (1991-95 和 2006-11)
第 20 节:20 世纪 90 年代 FKI 人工智能技术报告系列
人脑大约有 1000 亿个神经元,每个神经元平均与其他 1 万个神经元连接。有些是输入神经元,将数据 (声音、视觉、触觉、疼痛、饥饿) 喂给其他神经元。其他的是控制肌肉的输出神经元。大多数神经元隐藏在思考发生的位置。你的大脑显然是通过改变连接的强度或权重来学习的,这些强度或权重决定了神经元之间的相互影响的强度,而这些神经元似乎编码了你一生的经历。人工神经网络 (NNs) 与之类似,它能比以前的方法更好地学习识别语音、手写文字或视频、最小化痛苦、最大化乐趣、驾驶汽车,等等。
当前的商业应用大多集中在监督学习,使神经网络模仿人类教师。在许多试验中,Seppo Linnainmaa 于 1970 年提出的梯度计算算法,今天通常称为反向传播或自动微分的反向模式,以逐步削弱某些神经网络连接和加强其他连接的方式,使神经网络行为越来越像老师。
今天最强大的神经网络往往都非常深,也就是说,它们有许多层神经元或许多后续的计算阶段。然而,在 20 世纪 80 年代,基于梯度的训练并不适用于深度神经网络,只适用于浅层神经网络。
这个问题在循环神经网络 (RNN) 中表现得最为明显。与更有限的前馈神经网络 (FNN) 不同,RNN 具有反馈连接。这使得 RNN 功能强大,通用的并行序列计算机可以处理任意长度的输入序列 (例如语音或视频)。原则上,RNN 可以实现在笔记本电脑上运行的任何程序。如果我们想要构建一个通用人工智能 (AGI),那么它的底层计算基础必须是类似于 RNN 的东西 ——FNN 从根本上是不够的。RNN 与 FNN 的关系就像普通计算机与计算器的关系一样。
特别是,与 FNN 不同,RNN 原则上可以处理任意深度的问题。然而,20 世纪 80 年代早期的 RNN 在实践中未能学习到深层次的问题。我想克服这个缺点,实现基于 RNN 的 “通用深度学习”。
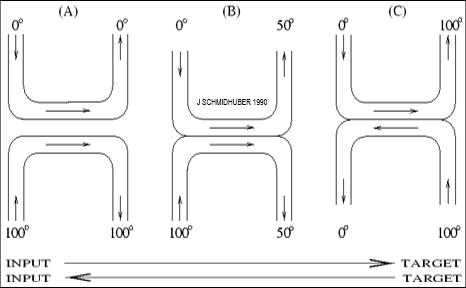
1、第一个非常深的神经网络,基于无监督预训练 (1991)
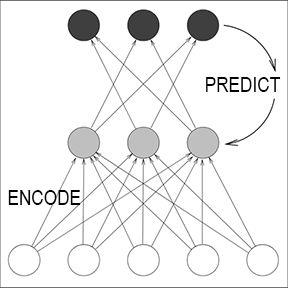
我克服上面提到的深度学习问题的第一个想法是,通过对一组分层的 RNN 进行无监督预训练来促进深度 RNN 中的监督学习 (1991),从而得到了
第一个 “非常深的神经网络”
,我称之为Neural Sequence Chunker。换句话说,chunker 学习压缩数据流,使得深度学习问题不那么严重,可以通过标准的反向传播来解决。尽管那时的计算机比现在慢一百万倍,但到 1993 年,我的方法已经能够解决以前无法解决的 “深度学习” 任务,神经网络的层数超过了 1000 层。1993 年,我们还发布了一个后续版本的 Neural History Compressor。
据我所知, Sequence Chunker 也是第一个由在不同时间尺度上运行的 RNN 组成的系统。几年后,其他人也开始发表关于多时间尺度的 RNN 的研究。
这项工作发表十多年后,一种用于更有限的前馈神经网络的类似方法出现了,称为深度置信网络 (DBN)。该论文的证明基本上就是我在 1990 年代早期为我的 RNN 堆栈使用的证明:每一个更高的层都试图减少下面层中数据表示的描述长度 (或负对数概率)。
在上述基于无监督预训练的深度学习网络之后不久,深度学习问题也通过我们的纯监督 LSTM 得以克服。
当然,前馈神经网络的深度学习开始得更早,早在 1965 年,Ivakhnenko 和 Lapa 就发表了第一个通用的、用于任意层数的深度多层感知器的学习算法。但是,与 Ivakhnenko 在 70 年代和 80 年代提出的深度 FNN 网络不同,我们的深度 RNN 具有通用的并行训练计算架构。到上世纪 90 年代初,大多数神经网络研究仍局限于相当浅的网络,后续计算阶段少于 10 个,而我们的方法已经支持了 1000 多个这样的阶段。我想说的是,是我们让神经网络变得如此之深,尤其是 RNN,它是所有网络中最深、最强大的。
2、将神经网络压缩 / 蒸馏成另一个 (1991)
我在上述有关 Neural History Compressor 的论文中还介绍了一种将网络层次结构压缩到单个深度 RNN 的方法,从而学会了解决非常深入的问题。将一个神经网络的知识转移到另一个神经网络的一般原理是,假设教师 NN 已学会预测数据,通过训练学生 NN 模仿教师 NN 的行为,它的知识可以压缩到学生 NN 中。
我称之为将一个网络的行为 “collapsing” 或 “compressing” 到另一个。今天,这个概念已经被广泛使用,也被称为将教师网络的行为 “蒸馏”(distilling) 或 “克隆” 到学生网络。
3、基本的深度学习问题:梯度消失 / 爆炸 (1991)
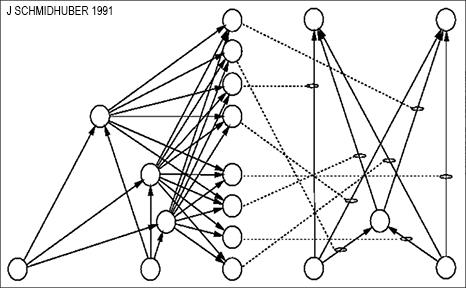
前文我们指出深度学习很难。但为什么很难呢?一个主要原因是,我喜欢称之为 “基本深度学习问题”,由我的学生 Sepp Hochreiter 1991 年在他的毕业论文 [VAN1] 中提出和分析。
作为论文的一部分,Sepp 实现了上述 (第 1 节) 的 Neural History Compressor 和其他基于 RNN 的系统 (第 11 节)。但是,他做了更多的工作:他的工作正式表明,深度神经网络遭受梯度消失或梯度爆炸问题:在典型的深度网络或循环网络中,反向传播的错误信号要么迅速缩小,要么超出界限。在这两种情况下,学习都会失败。这种分析引出了 LSTM 的基本原理 (第 4 节)。
长短时记忆神经网络 (LSTM) 克服了 Sepp 在其 1991 年的毕业论文中提出的基本深度学习问题。我认为这是机器学习历史上最重要的论文之一。它还通过我们在 1995 年的技术报告 [LSTM0] 中所称的 LSTM 的基本原理为解决这个问题提供了重要的见解。这导致了下面描述的大量后续工作。
明年,我们将庆祝 LSTM 首次投稿时未能通过同行评审 25 周年。在 1997 年主要的同行评审出版物 [LSTM1](现在是神经计算历史上引用最多的文章) 之后,LSTM 得到了进一步的改进。一个里程碑是带有 forget gate [LSTM2] 的 “vanilla LSTM 架构”——1999-2000 年的 LSTM 变体,现在每个人都在使用,例如,在谷歌的 Tensorflow 中。LSTM 的遗忘门实际上是一种端到端可微的快速权值控制器,我们在 1991 年也介绍了这种控制器。
Alex 是我们第一次成功地将 LSTM 应用于语音的主要作者 (2004)[LSTM14]。2005 年,第一个具有时间反向完全传播功能的 LSTM 和双向 LSTM 发布 [LSTM3](现在广泛使用)。2006 年的另一个里程碑是用于同时对齐和识别序列的训练方法 “连接时间分类” 或 CTC。自 2007 年以来,CTC 成为基于 LSTM 的语音识别的关键。例如,在 2015 年,CTC-LSTM 组合显著改善了谷歌的语音识别 [GSR15]。
在 21 世纪初,我们展示了 LSTM 如何学习传统模型 (如隐马尔可夫模型) 无法学习的语言 [LSTM13]。这花了一段时间;但到了 2016~2017 年,谷歌翻译 [GT16] 和 Facebook 翻译 [FB17] 均基于两个连接 LSTM,一个用于输入文本,一个用于输出翻译,性能比以前的翻译模型要好得多。
2009 年,我的博士生 Justin Bayer 是一个自动设计类似 LSTM 架构的系统的主要作者,该系统在某些应用程序中表现优于普通 LSTM。2017 年,谷歌开始使用类似的 “神经架构搜索”[NAS]。
5、通过对抗生成神经网络的人工好奇心 (1990)
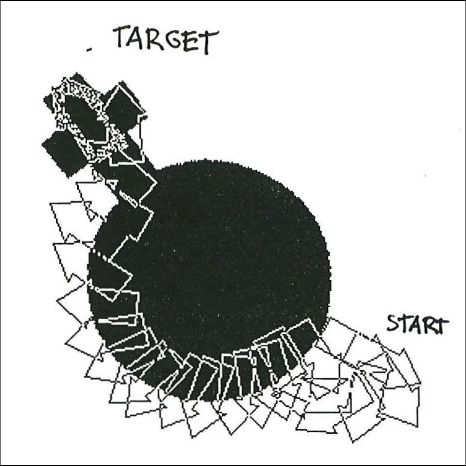
当人类与世界互动时,他们学会预测自己行为的后果。他们也很好奇,设计实验得出新的数据,从中他们可以学到更多。为了构建好奇的人工智能体,我在 1990 年介绍了一种新型的主动无监督学习或自监督学习。它基于一个极小极大博弈,其中一个神经网络最小化另一个神经网络最大化的目标函数。我把这两种无监督的对抗性神经网络之间的决斗称为对抗性好奇心 (Adversarial Curiosity)[AC19],以区别于人工好奇心 (Artificial Curiosity)。
6、通过最大化学习神经网络学习进度的人工好奇心 (1991)
在这里,我重点介绍 1991 年 [AC91] [AC91b] 对对抗性好奇心 (Adversarial Curios
AC1990 世界模型 M 的误差 (待最小化) 是控制器 C 的奖励 (待最大化)。这在许多确定性环境中是一个很好的探索策略。然而,在随机环境中,这可能会失败。C 可能会学习把重点放在 M 总是由于随机性或由于其计算限制而得到高预测误差的情况上。
因此,正如 1991 年的论文指出的,在随机环境中,C 的奖励不应该是 M 的误差,而应该是 M 的误差在后续训练迭代中的一阶导数的近似,即 M 的改进。这一认识指导了许多相关的后续工作。
1990 年我第一次研究对抗性生成网络后不久,我介绍了一个非监督对抗性极小极大值原理的变体。神经网络最重要的任务之一就是学习图像等给定数据的统计量。为了实现这一点,我再次在一个极小极大博弈中使用了梯度下降 / 上升的原理,在这个博弈中,一个神经网络最小化了另一个神经网络最大化的目标函数。这两个无监督的对抗性神经网络之间的决斗被称为可预测性最小化 (Predictability Minimization, PM)。(与后来的 GAN 相反,PM 是一个纯粹的极大极小博弈)。
第一个使用 PM 的实验是在大约 30 年前进行的,当时其计算成本大约是现在的 100 万倍。当计算成本在 5 年后便宜了 10 倍时,我们可以证明,应用于图像的半线性 PM 变体会自动生成特征检测器。
8、端到端可微快速权重:让神经网络学习编程神经网络 (1991)
一个典型的神经网络比神经元有更多的连接。在传统的神经网络中,神经元激活变化快,而连接权值变化慢。也就是说,大量的权重无法实现短期记忆或时间变量,只有少数神经元的激活可以。具有快速变化的 “快速权重”(fast weights) 的非传统神经网络克服了这一限制。
神经网络的动态连接或快速权值是由 Christoph v. d. Malsburg 于 1981 年提出的,其他学者对此进行了进一步的研究。然而,这些作者并没有提出端到端可微分的系统,通过梯度下降学习来快速操作快速权重存储。我在 1991 年发表了这样一个系统,其中慢速神经网络学习控制独立的快速神经网络的权值。也就是说,我将存储和控制分开,就像在传统计算机中那样,但是以完全的神经方式 (而不是以混合方式)。后续的许多工作基于这一方法。
我还展示了如何快速使用权重进行元学习或 “学习如何学习”(learning to learn),这是我自 1987 年以来的主要研究课题之一。
顺便一提,同年我们在 Deep RL (但没有快速权重) 方面也做了相关工作,据我所知,这是第一篇标题包含 "learn deep” 这个词组的论文 (2005 年)。
如今,最著名的基于快速权重的端到端可微分神经网络实际上就是我们的原始 LSTM 网络,其遗忘门学会控制内部 LSTM 单元自循环连接的快速权重。所有主要的 IT 公司现在都大量使用 LSTM,而这可以追溯到 1991 年。
与传统的神经网络不同,人类使用连续的目光移动和选择性注意力来检测和识别模式。这可能比传统的高度并行的 FNN 方法更有效。这就是为什么我们在 30 年前提出了序列注意力学习神经网络。不久之后,我还明确地提到了 “内部注意力焦点” 的学习。
因此,在那个时候,我们已经有了两种现在常见的神经序列注意力类型:通过神经网络中的乘法单元来实现端到端可微分的 “软” 注意力,以及在强化学习环境下的 “硬” 注意力。后来的大量后续工作都基于此。如今,许多人都在使用序列注意力学习网络。
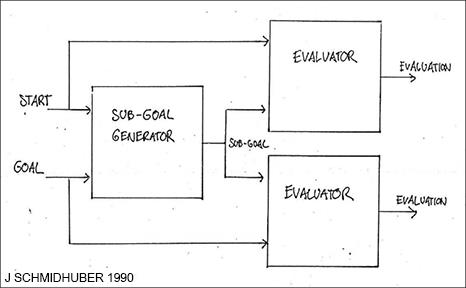
传统强化学习不能分层地将问题分解为更容易解决的子问题。这就是为什么我在 1990 年提出了分层 RL (HRL),使用端到端可微分的基于神经网络的子目标生成器,以及学习生成子目标序列的循环神经网络。RL 系统获得形式 (start、goal) 的额外输入。评估器 NN 学会预测从 start 到 goal 的奖励 / 成本。基于 RNN 的子目标生成器也可以看到 (start, goal),并使用评估器 NN (的副本) 通过梯度下降来学习一系列成本最低的中间子目标。RL 系统试图使用这样的子目标序列来实现最终目标。
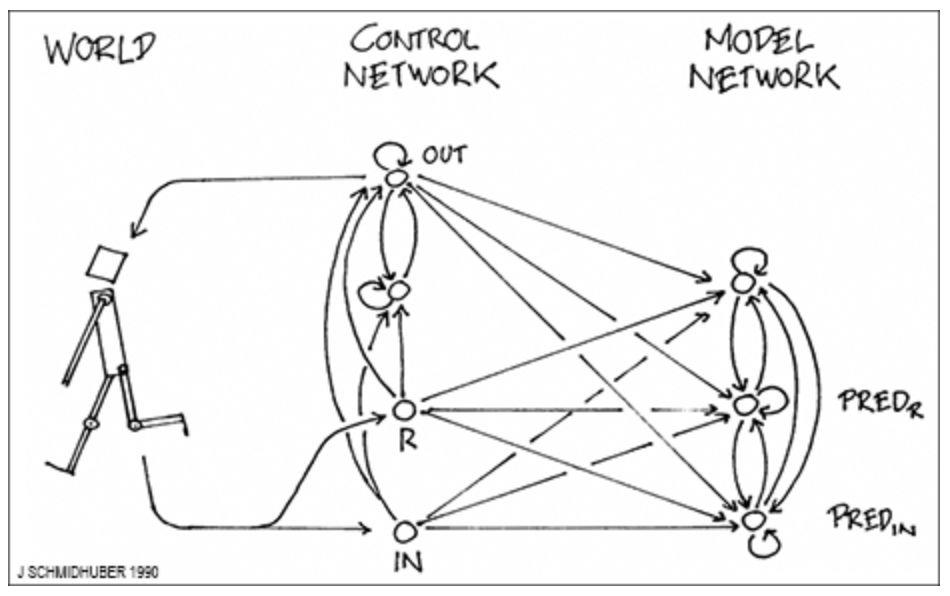
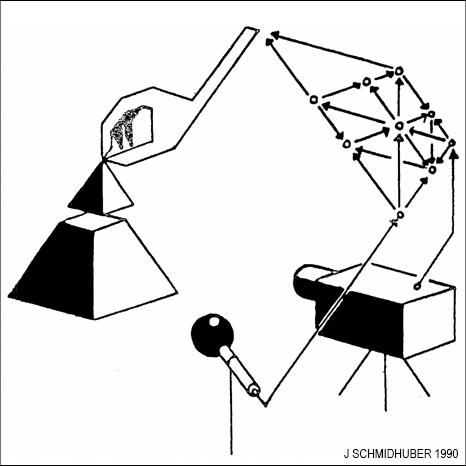
1990 年,我介绍了基于两个 RNN 的组合 (分别称为控制器 C 和世界模型 M) 的强化学习和规划。M 学习预测 C 行为的后果。C 学习使用 M 提前规划几个时间步骤,并选择最大化预测累积奖励的动作序列。基于此也有许多后续研究。
12. 将目标定义作为额外的 NN 输入 (1990)
今天的强化学习神经网络中广泛使用的一个概念是使用额外的目标定义输入模式来编码许多任务,以便神经网络知道下一步该执行哪个任务。我们在 1990 年的许多工作中提出了这一概念。
具有端到端可微子目标生成器的分层强化学习 (Hierarchical RL) 也使用一个带有任务定义输入 (start, goal) 的神经网络,学习预测从 start 到 goal 的成本。(四分之一个世纪后,我以前的学生 Tom Schaul 在 DeepMind 提出了 “通用值函数逼近器”。
后来的大量工作都是基于此的。例如,我们的 POWERPLAY RL 系统 (2011) 也使用任务定义输入来区分任务,不断地创造自己的新目标和任务,以一种主动的、部分不受监督的或自我监督的方式,逐步学习成为一个越来越通用的问题解决者。具有高维视频输入和内在动机的 RL 机器人 (如 PowerPlay) 在 2015 年学会了探索。
13、作为神经网络输入的高维奖励信号 / 通用价值函数 (1990 年)
传统的 RL 是基于一维奖励信号的。然而,人类拥有数百万种信息传感器,可以感知不同类型的信息,如疼痛和快乐等。据我所知,参考文献 [AC90] 是第一篇关于 RL 的论文,涉及多维度、向量值的奖励信号,这些信号通过许多不同的传感器传入,这些传感器的累积值是可以预测的,而不仅仅是单个标量的总体奖励。比较一下后来的通用值函数 (general value function,GVF)。与以往的 adaptive critics 不同,它是多维和周期性的。
与传统的 RL 不同,这些奖励信号也被用作控制器 NN 学习执行动作的信息输入,以实现累积奖励的最大化。
我在 1990 年发表的论文 “Augmenting the Algorithm by Temporal Difference Methods” 中,也结合了基于动态规划的时域差分法来预测一个基于梯度的世界预测模型的累积奖励,以计算单独控制网络的权重变化。四分之一个世纪后,DeepMind 将其变体称为确定性策略梯度算法 (Policy Gradient algorithm, DPG)。
1990 年,我提出了各种学习调整其他 NNs 的 NNs。在这里,我将重点讨论 “递归网络中的局部监督学习方法”。待最小化的全局误差度量是 RNN 输出单元在一段时间内接收到的所有误差的总和。在常规反向传播中,每个单元都需要一个堆栈来记住过去的激活,这些激活用于计算误差传播阶段对权重变化的贡献。我没有使用堆栈形式的无限存储容量,而是引入了第二种自适应 NN,该算法可以学习将 RNN 的状态与相应的误差向量相关联。这些局部估计的误差梯度(而非真实梯度)被用于调整 RNN。
与标准的反向传播不同,该方法在空间和时间上都是局部的。四分之一个世纪后,DeepMind 将其称为 “合成梯度”(Synthetic Gradients)。
16、在线递归神经网络的 O (n^3) 梯度 (1991)
1987 年发表的固定大小的存储学习算法用于完全循环连续运行的网络,它要求每个时间步长进行 O (n^4) 计算,其中 n 是非输入单元的数量。我提出了一种方法,该方法计算完全相同的梯度,需要固定大小的存储,其顺序与之前的算法相同。但是,每个时间步长的平均时间复杂度只有 O (n^3) 。然而,这项工作并没有实际意义,因为伟大的 RNN 先驱 Ron Williams 首先采用了这种方法。
顺便说一句,我在 1987 年也犯了类似的错误,当时我发表了我认为是第一篇关于遗传编程 (GP) 的论文,也就是关于自动进化的计算机程序。直到后来我才发现,Nichael Cramer 早在 1985 年就已经提出了 GP。从那以后,我一直在努力做正确的事情。至少我们 1987 年的论文 [GP1] 似乎是第一篇在 GP 上使用循环和可变大小代码的论文,也是第一篇在 GP 上使用逻辑编程语言实现的论文。
神经热交换器 (Neural Heat Exchanger) 是一种用于深度多层神经网络的监督学习方法。它的灵感来自物理热交换器。输入 “加热”,同时通过许多连续的层进行转换,目标从深层管道的另一端进入并 “冷却”。与反向传播不同,该方法完全是局部的。这使得它的并行实现变得微不足道。自 1990 年以来,它是在各大学的不定期演讲中首次提出的,与亥姆霍兹机器 (Helmholtz Machine) 关系密切。同样,实验是由我的学生 Sepp Hochreiter 进行的。
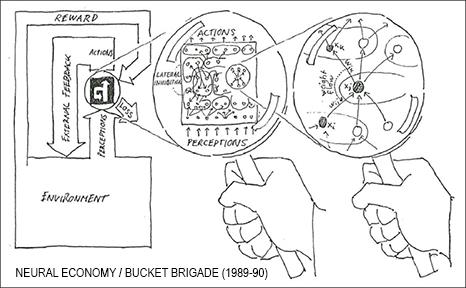
我在 TUM 的博士论文发表于 1991 年,总结我自 1989 年以来的一些早期工作,包括第一个强化学习 (RL) 神经经济(Neural Bucket Brigade),学习算法,具有端到端微分子目标生成器的分层 RL(HRL),通过两个称为控制器 C 和世界模型 M 的 RNN 的组合进行 RL 和规划,序列注意力学习 NN,学会调整其他 NN 的 NN (包括 “合成梯度”),以及用于实施好奇心的无监督或自我监督的生成对抗网络。
当时,其他人的神经网络研究受到统计力学的启发。我在 1990-91 年的工作体现了另一种面向程序的机器学习观点。
库尔特・哥德尔 (Kurt Godel) 在 1931 年创立了理论计算机科学,他用基于整数的通用编码语言表示数据 (如公理和定理) 和程序 (如对数据进行操作的证明生成序列)。他展示了数学,计算和人工智能的基本极限。
正如我在 1990 年以来经常指出的,NN 的权值应该被看作是它的程序。一些人认为深层神经网络的目标是学习观测数据的有用的内部表示,但我一直倾向于认为,神经网络的目标是学习程序 (参数),并计算此类表示。受 Gödel 的启发,我构建了神经网络,其输出是其他 NN 的程序或权重矩阵,甚至是可以运行和检查自己的权重变化算法或学习算法的自引用 RNN。与 Gödel 的工作不同的是,通用编程语言不是基于整数,而是基于实数值,因此典型 NN 的输出就其程序而言是可微分的。也就是说,一个简单的程序生成器(有效的梯度下降过程)可以在程序空间中计算一个方向,在该方向上可以找到更好的程序,尤其是更好的程序生成程序。自 1989 年以来,我的许多工作都充分利用了这一事实。
19、从无监督预训练到纯粹监督学习 (1991-1995 年和 2006-2011)
如第一节所述,我的第一个非常深的深度学习网络是 1991 年的 RNN 堆栈,它使用无监督的预训练来学习深度大于 1000 的问题。但是,此后不久,我们发表了更多克服深度学习问题的通用方法,无需进行任何无监督的预训练,将无监督的 RNN 栈替换为纯监督的长短时记忆网络 (LSTM)。也就是说,由于 LSTM 不需要无监督的训练,无监督训练已经失去了重要性。事实上,从无监督的训练到纯粹的监督学习的转变早在 1991 年就开始了。
在 2006 年到 2010 年之间也发生了类似的转变,这次是针对不太常用的前馈神经网络 (FNNs),而不是递归神经网络 (RNNs)。同样,我的小实验室在这个转变中起到了中心作用。2006 年,FNNs 中的监督学习是通过对 FNN 堆栈的无监督预训练来实现的。但在 2010 年,我们的团队和我的博士后 Dan Ciresan 证明,深度 FNNs 可以通过简单的反向传播进行训练,在重要的应用中完全不需要无监督的预训练。我们的系统在当时广泛使用的图像识别基准 MNIST 上创下了新的性能记录。一位评论者称这是 “唤醒了机器学习社区”。今天,很少有商业 DL 应用仍然基于无监督的预训练。
我在瑞士人工智能实验室 IDSIA 的团队进一步完善了上述关于 FNNs 中纯粹监督式深度学习的工作 (2010),将传统的 FNNs 替换为另一种 NN 类型,即 convolutional NNs 或 CNNs。这是一个实际的突破,并在 2011 年 5 月 15 日至 2012 年 9 月 10 日期间连续 4 次在重要计算机视觉比赛中获胜。
20、20 世纪 90 年代 FKI 人工智能技术报告系列
事后看来,许多后来被广泛使用的 “现代” 深度学习的基本思想,都是在柏林墙倒塌后不久的、不可思议的 1990-1991 年,在慕尼黑大学 (TU Munich) 发表的:无监督或自我监督、数据生成、对抗网络 (认为好奇心和相关概念,见第 5 节);深度学习的基本问题 (梯度消失 / 爆炸) 及其解决方案 (a) 针对深度 (周期性) 网络的无监督预训练 (第 1 节) 和 (b) 通向 LSTM 的基本简介 (第 4 节)。
我们当时还引入了序列注意力学习 NN,这是另一个流行的概念。再加上前面提到的所有其他东西,从分层强化学习 (第 10 节) 到使用循环神经网络的世界模型进行规划 (第 11 节) 等等。
当然,人们不得不等待速度更快的计算机来将这些算法商业化。然而,到 2010 年中期,我们的算法被苹果,谷歌,Facebook,亚马逊,三星,百度,微软等公司大量使用,每天在数十亿台计算机上运行。
大多数上述结果实际上是首次发表是在慕尼黑工业大学的 FKI 技术报告系列,为此,我手工画了很多插图,本文的插图就是其中一些。FKI 系列现在在人工智能的历史中起着重要作用,因为它引入了几个重要概念:用于非常深的神经网络的无监督预训练、将一个 NN 压缩 / 蒸馏成另一个、长短期记忆、通过神经网络使学习进度最大化的好奇心 (Artificial Curiosity)、端到端快速权重和学会编程其他神经网络的神经网络、通过 NN 学习序列注意力、将目标定义命令作为额外的 NN 输入、分层强化学习等等。
特别是,其中一些概念现在已经在整个 AI 研究领域被广泛使用:使用循环神经世界模型进行规划、作为额外的 NN 输入的高维奖励信号 / 通用值函数、确定性策略梯度、NN 既具有生成性又具有对抗性、人工好奇心和相关概念。1990 年代以后的引人注目的 FKI 技术报告描述了大幅压缩 NN 以提高其泛化能力的方法。
深度学习是在官方语言不是英语的地方被发明的。第一个具有任意深度的神经网络始于 1965 年的乌克兰 (当时是苏联)。五年后,现代反向传播方法在芬兰出现 (1970)。基本的深度卷积神经网络架构是在 20 世纪 70 年代的日本发明的,到 1987 年,卷积网络与权重共享和反向传播相结合。无监督或自我监督的对抗网络起源于慕尼黑 (1990 年),慕尼黑也是 20 世纪 80 年代第一批真正的自动驾驶汽车的诞生地。基于反向传播的深度学习的基本问题也诞生于慕尼黑 (1991)。第一个克服这个问题的 “现代” 深度学习网络也是如此,它们通过 (1) 无监督的预训练;和 (2) 长短时记忆 [LSTM] 克服这个问题,LSTM “可以说是最具商业价值的人工智能成果”。LSTM 是在瑞士进一步发展起来的,这也是第一个在图像识别竞赛获胜的基于 GPU 的 CNN (2011 年),也是第一个在视觉模式识别中超越人类的神经网络 (2011 年),以及第一个有超过 100 层、非常深的前馈神经网络。
当然,深度学习只是 AI 的一小部分,主要局限于被动模式识别。我们将其视为通过元学习或 “learning to learn 算法”(1987 年发表) 研究更一般的人工智能的副产品,具有人工好奇心和创造力的系统发明了自己的问题并设定自己的目标 (1990 年),演化计算 (1987 年) 和 RNN 进化 & 压缩网络搜索,在现实的部分可观测的环境中的强化学习 (RL) 智能体,通用人工智能,最优通用学习机器,如 Gödel machine (2003-),对运行在通用计算机上的程序的最优搜索,如 RNN,等等。
当然,AI 本身只是一个更宏伟计划的一部分,它将宇宙从简单的初始条件推向越来越深不可测的复杂性。最后,即使这个令人敬畏的过程可能也只是所有逻辑上可能存在的宇宙中更宏大、更有效的计算的一小部分。
http://people.idsia.ch/~juergen/deep-learning-miraculous-year-1990-1991.html
以上是关于世界欠他一个图灵奖! LSTM之父的深度学习“奇迹之年”的主要内容,如果未能解决你的问题,请参考以下文章