GitHub代码库:深度学习模型压缩与加速
Posted 计算机视觉life
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GitHub代码库:深度学习模型压缩与加速相关的知识,希望对你有一定的参考价值。
快速获得最新干货
https://github.com/666DZY666/model-compression
目前已经有170+ star,欢迎大家 watch,star,fork。
model-compression
"目前在深度学习领域分两个派别,一派为学院派,研究强大、复杂的模型网络和实验方法,为了追求更高的性能;另一派为工程派,旨在将算法更稳定、高效的落地在硬件平台上,效率是其追求的目标。复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。所以,卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,深度学习模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一"
项目简介
基于pytorch实现模型压缩(1、量化:8/4/2 bits(dorefa)、三值/二值(twn/bnn/xnor-net);2、剪枝:正常、规整、针对分组卷积结构的通道剪枝;3、分组卷积结构;4、针对特征A二值的BN融合)
目前提供
-
1、普通卷积和分组卷积结构 -
2、权重W和特征A的训练中量化, W(32/8/4/2bits, 三/二值) 和 A(32/8/4/2bits, 三/二值)任意组合 -
3、针对三/二值的一些tricks:W二值/三值缩放因子,W/grad(ste、saturate_ste、soft_ste)截断,W三值_gap(防止参数更新抖动),W/A二值时BN_momentum(<0.9),A二值时采用B-A-C-P可比C-B-A-P获得更高acc -
4、多种剪枝方式:正常剪枝、规整剪枝(比如model可剪枝为每层剩余filter个数为N(8,16等)的倍数)、针对分组卷积结构的剪枝(剪枝后仍保证分组卷积结构) -
5、batch normalization的融合及融合前后model对比测试:普通融合(BN层参数 —> conv的权重w和偏置b)、针对特征A二值的融合(BN层参数 —> conv的偏置b)
代码结构
环境要求
-
python >= 3.5 -
torch >= 1.1.0 -
torchvison >= 0.3.0 -
numpy
使用
量化
W(FP32/三/二值)、A(FP32/三/二值)
--W --A, 权重W和特征A量化取值
cd WbWtAb
-
WbAb
python main.py --W 2 --A 2
-
WbA32
python main.py --W 2 --A 32
-
WtAb
python main.py --W 3 --A 2
-
WtA32
python main.py --W 3 --A 32
W(FP32/8/4/2 bits)、A(FP32/8/4/2 bits)
--Wbits --Abits, 权重W和特征A量化位数
cd WqAq
-
W8A8
python main.py --Wbits 8 --Abits 8
-
W4A8
python main.py --Wbits 4 --Abits 8
-
W4A4
python main.py --Wbits 4 --Abits 4
-
其他bits情况类比
剪枝
稀疏训练 ——> 剪枝 ——> 微调
cd prune
正常训练
python main.py
稀疏训练
-sr 稀疏标志, --s 稀疏率(需根据dataset、model情况具体调整)
-
nin(正常卷积结构)
python main.py -sr --s 0.0001
-
nin_gc(含分组卷积结构)
python main.py -sr --s 0.001
剪枝
--percent 剪枝率, --normal_regular 正常、规整剪枝标志及规整剪枝基数(如设置为N,则剪枝后模型每层filter个数即为N的倍数), --model 稀疏训练后的model路径, --save 剪枝后保存的model路径(路径默认已给出, 可据实际情况更改)
-
正常剪枝
python normal_regular_prune.py --percent 0.5 --model models_save/nin_preprune.pth --save models_save/nin_prune.pth
-
规整剪枝
python normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_preprune.pth --save models_save/nin_prune.pth
或
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_preprune.pth --save models_save/nin_prune.pth
-
分组卷积结构剪枝
python gc_prune.py --percent 0.4 --model models_save/nin_gc_preprune.pth
微调
--refine 剪枝后的model路径(在其基础上做微调)
python main.py --refine models_save/nin_prune.pth
剪枝 —> 量化(注意剪枝率和量化率平衡)
剪枝完成后,加载保存的模型参数在其基础上再做量化
剪枝 —> 量化(8/4/2 bits)(剪枝率偏大、量化率偏小)
cd WqAq
-
W8A8 -
nin(正常卷积结构)
python main.py --Wbits 8 --Abits 8 --refine ../prune/models_save/nin_refine.pth
-
nin_gc(含分组卷积结构)
python main.py --Wbits 8 --Abits 8 --refine ../prune/models_save/nin_gc_refine.pth
-
其他bits情况类比
剪枝 —> 量化(三/二值)(剪枝率偏小、量化率偏大)
cd WbWtAb
-
WbAb -
nin(正常卷积结构)
python main.py --W 2 --A 2 --refine ../prune/models_save/nin_refine.pth
-
nin_gc(含分组卷积结构)
python main.py --W 2 --A 2 --refine ../prune/models_save/nin_gc_refine.pth
-
其他取值情况类比
BN融合
cd WbWtAb/bn_merge
--W 权重W量化取值(据训练时W量化(FP/三值/二值)情况而定)
融合并保存融合前后model
python bn_merge.py --W 2
或
python bn_merge.py --W 3
融合前后model对比测试
python bn_merge_test_model.py
模型压缩数据对比(示例)
注:可在更冗余模型、更大数据集上尝试其他组合压缩方式
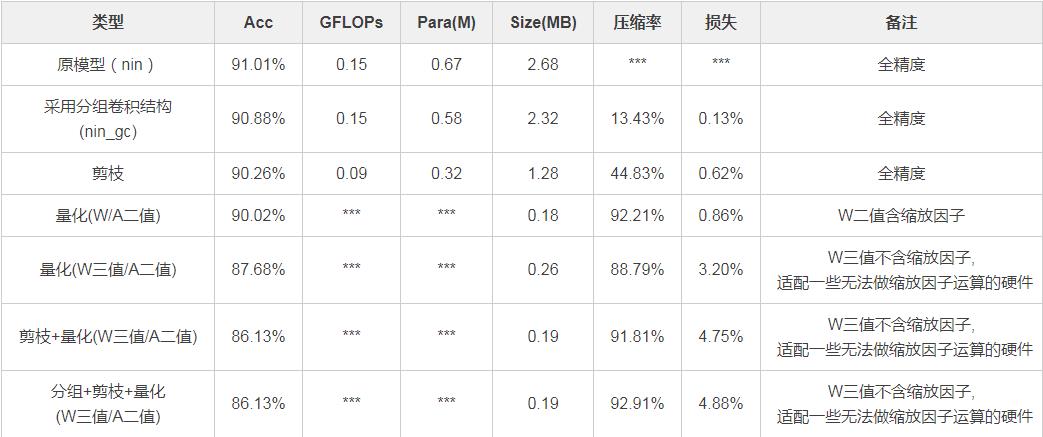
-
1、使用示例部分细节说明 -
2、参考论文及工程 -
3、imagenet测试(目前cifar10)
后续扩充
-
1、Nvidia、Google的INT8量化方案 -
2、对常用检测模型做压缩 -
3、部署(1、针对4bits/三值/二值等的量化卷积;2、终端DL框架(如MNN,NCNN,TensorRT等))
https://github.com/666DZY666/model-compression
交流群

投稿、合作也欢迎联系:simiter@126.com
长按关注计算机视觉life
推荐阅读
最新AI干货,我在看
点阅读原文即可跳转
以上是关于GitHub代码库:深度学习模型压缩与加速的主要内容,如果未能解决你的问题,请参考以下文章