当深度学习遇到3D Posted 2021-04-20 老顾谈几何
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当深度学习遇到3D相关的知识,希望对你有一定的参考价值。
2019年10月底11月初,国际计算机视觉大会(ICCV 2019)在韩国首尔举行,参会学者多达七千五百多人,创了历史记录。大会接收论文一千多篇,排在前几位的论文关键词是:图像(image),物体(object),检测(detection),三维(3D)和视频(video)。
会址选在首尔经济最为发达的江南区,特指汉江南岸靠近景福宫的区域,由于鸟叔脍炙人口的“江南Style”而闻名遐迩。大会在coex商业中心举行,门口硕大的金色雕塑,描绘了鸟叔骑马揽缰的手势。这里旅店赌场环绕,食肆酒楼鳞次栉比。各色亲民食品琳琅满目,朝鲜冷面,越南河粉,中东烤肉,美式牛排。游客熙熙攘攘,人声鼎沸。令人感动的是商业中心的黄金地带,居然矗立着规模宏大的开放式图书馆,由书籍砌成的墙壁直达天顶。这在灯红酒绿的商业气氛中,流出一股清新的书香。
图1. 首尔 coex 中心,starfield 图书馆。
韩国非常注重保存和弘扬传统文化。在周边的商铺中,老顾看到了很多中国东北的传统玩具,触发了几乎已经遗忘的儿时记忆。例如弹弓,冰猴儿(陀螺),嘎拉哈儿,麦芽糖,打糕,高丽纸扇,狼毫毛笔。老顾童年有很多朝鲜族的同学,印象中他们都非常直爽豪迈,能歌善舞。小学时候,音乐课上教授朝鲜歌谣《桔梗谣》、《阿里郎》,每逢文艺汇演必有朝鲜太平鼓舞、新罗筝弹奏。古老的东北亚文化,在首尔的现代社会中被保存发展,实在令人欣慰。
在大会上,老顾和朋友们组织了“计算机视觉中的统计深度学习”的workshop,遇到了很多老朋友,也结交了很多新同道。老顾一位毕业多年的学生目前在首尔做教授,他和他的导师请老顾品尝了韩国著名的人参鸡。老顾的一位朝鲜族教授朋友也请老顾品尝了正宗的韩式烧烤。和他们深入的交谈,使得老顾深深感到朝鲜和韩国的民众都对自己的民族充满了深沉的热爱,民族分裂的悲剧反而激发他们更为强烈的爱国心和历史责任感。韩国教授笑谈韩国总统是世上最为危险的职业。当谈到韩国前总统卢武铉为理想而殉道,大家都肃然起敬。朝鲜族教授谈到民族分裂,难抑内心悲怆。
在统计深度学习的workshop上,老顾汇报了近期和丘成桐先生合作的工作,用最优传输的几何理论来解释对抗生成网络。
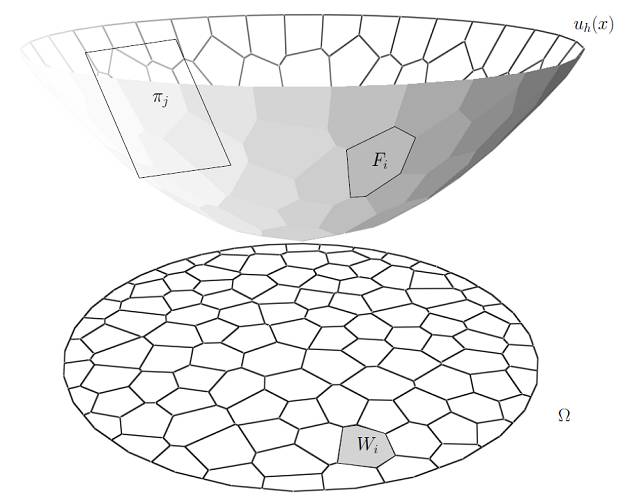
我们倾向于认为 , 统计深度学习的理论框架 可 以用 范畴语言来描述,范畴为 {流形上的概 率分布 ,流形间的变换 } 。 数据 集是 流形上的分布, 深度神经网络 表达流形间的变换。 生成模型是 随机采样, 图像去噪 是 向流形投影, 迁移学习是 计算流形 间的 映射 , 对抗样本是寻找 分布之间的 缝隙 。我们用下面的例子加以佐证。
深度学习成功的本质原因在于深度学习方法抓住了数据的内在模式,而数据的内在模式可以归结为流形分布律:一类自然的数据可以表示成低维流形上的一个概率分布,而这个低维流形嵌入在高维的数据空间之中。如图5所示,人脸图片是一类自然数据,每张图片被视为一个点,这类数据被视为一个点云,嵌入在图像空间之中。图像空间的维数等于每张图片的像素个数乘以通道数目(512x512x3),大约78万维。而人脸图片点云集中在某个低维流形附近,此流形的维数大约一百几十维左右。人脸图片点云在此流形上的分布不是均匀的,不同的民族和年龄对应的分布也不相同。
因此,深度学习的核心任务有两个:降维和概率变换。降维就是将数据流形从图像空间映射到隐空间,即所谓的编码映射,将每张人脸图片映射到隐空间的一个点,即特征向量。编码映射的逆映射为解码映射,将隐空间映射回数据流形。所谓概率变换,就是在隐空间或者图像空间中,将一个概率分布变换成另外一个概率分布。
图2. 不保概率分布的降维。
我们用一个玩具例子来加以解释。如图 2 所示,假设 我们关心的数据集是弥勒佛 曲面上的 均匀分布,二维的 弥勒 佛流形嵌入在三维的背景空间之中。 降维操作 的目的是将弥勒佛映射到 平面 上 (隐空间) 。 这样的 映射 有无穷多个,图2中的降维 映射 没有保持测度。 我们在 平面圆盘上均匀采样, 拉回到弥勒佛上,采样不再均匀。
图3. 概率变换。
这时,我需要进行概率变换,如图3所示,我们求取圆盘到自身的一个映射,使得概率密度高的区域扩张,概率密度低的区域收缩,最后密度分布均匀。这一步可以用最优传输理论来解决。
图4. 保概率分布的降维。
经过降维和概率变换之后,我们得到图4的结果。如果我们在平面圆盘上均匀采样,就得到弥勒佛上的均匀采样。
图5. 基于最优传输理论生成的人脸图片。
实际应用中的生成模型和这一框架没有本质不同,只是规模扩大了很多,以至于无法直接看清。比如,我们希望生成逼真的人脸图片,我们先在人脸流形上稠密采样(就是收集大量人脸图片),得到人脸图片所组成的 点云,我们用这个点云来离散逼近人脸图片的数据流形;然后,我们用深度学习的方法,例如自动编码器(autoencoder),将流形编码到隐空间,同时将隐空间解码到原来的数据流形上。注意所有的计算都是基于离散的点云,如果我们用ReLU深度神经网络,那么编码映射和解码映射被表示成分片线性映射。这一点非常类似传统的有限元方法(finite element method);在隐空间,我们将单位立方体内的均匀分布,用最优传输映射(optimal transportation map),映射到人脸图片集合在隐空间上的分布。生成人脸图片的过程如下:我们产生一个均匀分布的随机样本,用最优传输映射到隐空间数据分布中的一个样本,再用解码映射,映射到数据流形上的一个点,结果就是一张逼真的人脸图片。如图5所示,所有的人脸图片都是如此随机生成。
图6. 最优传输映射的几何理论,亚历山大定理。
如上所述,整个过程中至关重要的一步是图3中的概率变换,这一步可以用经典的最优传输理论来解决。奇妙的是,这一理论具有完美的几何解释。如图6所示,给定一个凸多面体,如果我们知道每个面的法向量,和每个面的投影面积,那么亚历山大(Alexandrov)断言我们可以确定多面体的形状。Alexandrov定理和最优传输映射实际上是等价的。我们可以用几何算法来完成概率变换的任务,从而将深度学习黑箱的一部分变得透明。
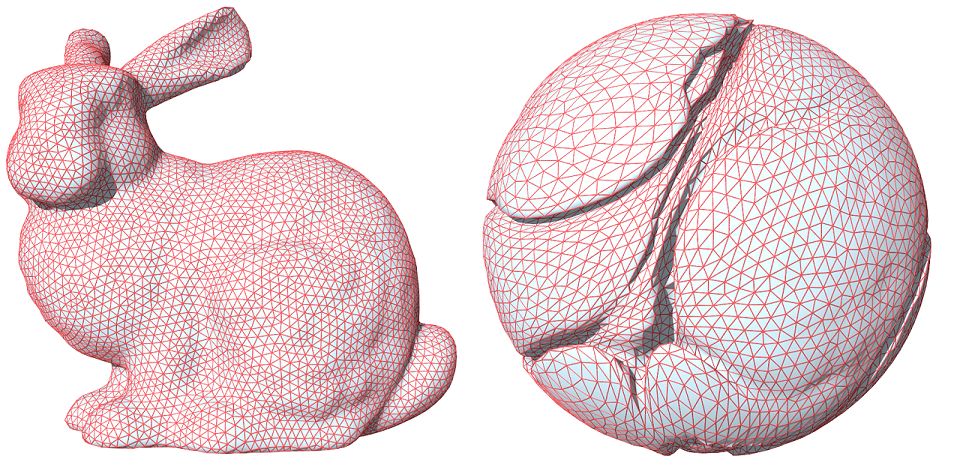
图7. 模式崩溃的几何解释。
最优传输理论的解释进一步揭示了深度学习所面临的本质困难:模式崩溃。如图7所示,我们用Alexandrov定理来计算实心兔子内部的均匀分布和球体内部的均匀分布之间的最优传输映射。我们看到兔子边界曲面的像在球体内部形成复杂的皱褶,因此从球体到兔子的保概率映射在这些皱褶处间断。这意味着概率变换映射通常是非连续的,但是深度神经网络(DNNs)只能表达连续映射。这一本质矛盾,使得对抗生成网络的训练难以收敛,经常发生模式崩溃(mode collapse)。
在过去二十年里,计算机视觉大会的规模扩张了两个数量级,这在很大程度上归功于深度学习领域爆炸式的发展。
传统的计算机视觉研究模式注重从理论上解释现象,用变分法、偏微分方程来描述自然或者工程现象,建立数理模型,用数学算法求解方程,得到结果。为了保证理论的严密性,我们需要证明解的存在性,唯一性,解的正则性;算法的收敛性,稳定性,离散解到连续解的收敛性。这需要多年学习艰深的理论,对于复杂的偏微分方程,每一项成果都要耗费多年的心血。
统计学习
的模式
注重收集输入
、输出数据集,拟合出相应的
映射
,从而直接得到
“端到端
”的
系统。
统计学习的
研究过程
省略了数理建模
,
同时也不必
分析
解的存在性、唯一性、正则性,以及
算
法的稳定性
、收敛性
。
从理论
角度而言,这一研究范式极大地降低了
理论研究的难度。
但是,
由于研究的随机性
增加,对于工程
能力的要求有相应提高。
由于对学生
理论素养的要求
降低,大量年轻学生投入到这一领域。
对于这一研究范式的转变,学者们的反应是不同的。数学家朋友们对于大会上深度学习的论文演讲不太满意。他们倾向于认为深度学习的演讲内在的严密性、系统性、可重复性都差强人意,用模糊的直觉代替严格的逻辑,用以偏概全的实验结果来代替理论推导,用统计的相关性代替数理的因果性,因此很难真正令人信服。数学家们认为深度学习会遇到发展的瓶颈,到那时必然会回归理论。
计算机科学家们
倾向认为
数学家们的观点比较迂腐,
不能因为严密性要求
而
阻碍大胆尝试
,
目前理论解释苍白
无力而无法 跟随
实践
如火如荼的迅猛发展
。
其实,目 前 统计深度学习主要是归纳总结经验公式,犹如历史上的开普勒。他基于前人世代积累的观测结果,总结出了天体运行的开 普勒 三大定律。这些定律是唯象理论,即虽然它们可以精确预测天体的运行轨道,天体在特定时间的位置
和速度
,但它们知其然不知其所以然,无法给出完美解释。
而传统的研究方法注重理论解释,犹如牛顿。
牛顿给出的力学三大定律,真正解释了天体运行规律,除了蕴含了开普勒定律,还可以适用于动力学领域。
对于急功近利的商业应用而言,唯象的经验公式足够满足要求。或者一种现象背后,无法确定存在确定性的客观规律,例如金融市场,这时经验公式成为首选。目前的计算机算力比十年前增长了数十万倍,采集数据的技术发展更是一日千里,这些都为统计深度学习的爆发提供了条件。到目前为止,深度学习几乎成为视觉大会的主流。整个大会洋溢着异常亢奋的情绪,无数年轻的面孔,喷发着火热的激情。似乎对于所有的问题,只要知道存在输入、输出之间的映射,那么深度学习方法都可以放手一搏。
但是,经验公式无法揭示深刻的自然规律,超越经验公式而建立理论,一直是人类智力文化发展的主流。纯粹数学的发展一直主要以自身的逻辑自洽为推动力,对于经验公式的依赖非常有限。很多抽象的几何理论也无法收集数据,例如曲面上的双曲度量,虽然理论上我们知道其存在性,但是它们无法等距嵌入到三维空间之中,因此在现实世界中,我们无法直接观测到双曲曲面。理论物理也是如此,广义相对论的建立,也是先从理论进行突破,从而预言了引力波的存在, 几十年后人类才真正才实现了观测 。
令人忧虑的是目前年轻学生趋之若鹜地争当开普勒,没有人再学习艰深的理论,这样会引发牛顿式人才的断层。与深度学习相比,学习几何拓扑、偏微分方程,需要太长的时间,并且在信息工业市场,经济回报率非常之低。但是金融市场,目前需要顶级人才具有雄厚的数理基础,而非以前所重 视口才和情商。 目前,美国金融市场的量化交易人才,多培养自欧洲和中国,几乎没有美国本土人才。 在未来,这一现象将会进一步加剧。
虽然这届视觉大会正值深度学习巅峰,传统方法依然占据举足轻重的地位。大会的最佳论文(马 尔奖 )颁给了从单张自然图像建立的对抗生成网络【1】。数学家的朋友们并不觉得结果有多惊艳,用传统的基于变分原理的方法,完全可以达到同样的效果,并且可以节省大量的硬件资源。
最佳学生论文体现了复古思潮。计算机视觉最初的目的是从二维图像恢复三维几何,这篇文章研究了这一古老问题的最简单版本【2】。假设三维空间中给定一些点,并且这些点经过一些直线。我们有多张关于这些点、线的照片,从这些照片如何恢复这些点、线的三维坐标,以及所有相机相对于世界坐标系的旋转和平移;给定点线的不同空间构型和照片的张数,如何才能保证存在有限个真实解。
这一问题非常基本而古老,解决方法也非常经典。这一问题代数化之后,最后归结为求解多项式环中特定理想的生成元,用经典的Grobner基方法加以求解,同时推广到不同构型的时候, 可以应用
同 伦
算法。
我们知道,人工智能有两大分支:
联结主义和符号主义,统计深度学习属于
联结主义,目的在于学习各种概率分布,而符合主义主要用于概念之间的逻辑推理。符合主义 的最主要算法就是Grobner基方法和吴方法。而同伦方法和不动点理论相结合,正是求解代数系统的通用方法。
长期以来,人们一直认为统计学习的方法只能处理低层次感知问题,对于高层次的认知问题应该采用符号主义方法。这两大方向的融合,将是人工智能发展的未来。
人类记忆力和运算能力和计算机无法相比,但是人类具有从现象提取抽象概念的能力,而这正是符号主义和连接主义之间的桥梁,也是人类与计算机智慧的本质差别。
我们看一个简单的例子,魔方的上帝之数(God's number)。求解魔方这一问题不大不小,非常适合比较不同算法之间的优劣。上帝之数问题是说,从魔方的任何状态只需要至多20步就可以恢复到原始状态。
我们
来看
传统方法
。关于魔方的所有可能的操作构成一个非阿贝尔群,我们称之为魔方群。魔方有6个基本操作,成为魔方群的生成元。魔方群作用在 魔方 的状态 空间上,这一空间非常庞大,相应的魔方群有 个元素。 我们做魔方群的Caley图如下:每个节点代表一个操作,如果两个操作相差一个生成元,则我们连上一条边。上帝之数意味着魔方图Caley图的直径为20。
传统的方法是基于群论【5】,我们将魔方群分解成子群的乘积,每个子群再进行进一步的分解,直至所有的子群、商群结构足够简单,可以被人类的心智所充分理解。例如,每个魔方有12个角块,每个角块有3个面;有8个棱块,每个棱块有两个面。所有变换角块的位置,但是保持角块定向的操作 构成一个子群;所有 变换角块的定向,但是保持角块位 置的操作 构成另一个子群。关于棱块也存在相应的两个子群。魔方群可以分解成这四个 ,这些子群可以进一步分解。但是当子群分解进一步精细化之后,陪集的数目达到数十亿之多,远远超过人类脑力能够驾驭的范围。最后用谷歌计算机群来检验了所有的陪集,从而“验证 ”了上帝之数的确是20。但是,这一方法无法被称为是“证明”。我们期望人类能够找到更为巧妙的分解方式,使得魔方群的结构更加简明地显现出来,使得每个组成部分都可以被人类心智所理解。
现代的方法采用阿尔法零的方法【4】,即摒弃所有人类的知识,用增强学习的方法来自行求解魔方,积累经验,提高求解效率。计算机可以在几分钟之内穷尽一个人终身所能够尝试的所有解法,通过在魔方群的Caley图中间随机行走,总结规律,提高预见,优化解法。这种方法目前能够在60%的情形下,达到最优解。依然无法和群论加计算的方法所匹敌。
魔方问题中所需要的群论知识是比较基本的。那么,增强学习方法能否自行从海量的摸索中提炼出抽象的群论概念,发现一些基本的引理,从而不再需要人类的理论指导,达到最优?这 个
问题击中了人工智能的软肋:
自行提取抽象概念
。
目前
符号主义的方法可以完成
符号演算
,
但是将
实际的
命题转换成
符号
,以及演算过程的中间结果的直观
理解
,
却只能由人类完成
。
由此可以,提取抽象
概念是
人类智能和
人工智能
的一个本质差别。
这一命题
只能用伽罗华 域
理论来证明。
高等动物都和人类有类似的感情,但是抽象概念的能力却是人类所特有的。
老顾辅导过中学生,仔细考察过他们抽象思维能力的发展。
虽然他们没有学过群论,但是他们都能够自行悟出基本的群论概念和定理,例如群元素阶的概念。
这似乎是人类生来 与
之的能力。
人类的知识积累,也是逐步将抽象的概念进一步抽象到更高的层次。
那么,计算机是否具有归纳总结出抽象概念的能力呢?希尔伯特曾经坚信形式化的公理方法可以统一数学,最终哥德尔的不完备定理证明了公理化方法内在局限。那么,图灵机是否能够提取抽象概念?或许也存在某个类似的哥德尔定理,使得这种能力 成
为
人类在计算机面前保住的最后一道防线。
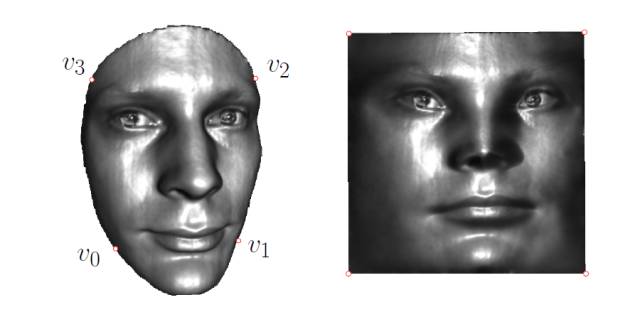
在今年的视觉大会中,深度学习方法生成3D形状成为热门专题。有多篇论文讨论如何生成三维人脸或者人体模型。这里,三维曲面的表示成为关键。
例如
,
我们希望
生成
三维人脸
曲面
。根
据实际观察,大多数人脸曲面具有确定规律,所有的三维人脸曲面应该分布在某个流形附近。
我们在每
张人脸曲面
上一致
采样n个点,将人脸曲面表示成一个三维点云。
如果我们随机打乱每个点云中采样点的顺序,那么人脸曲面数据集的流形结构将不再被保持。
换句话就是说,人脸曲面点
云中,每个点的次序具有语义信息,例如所有人脸曲面点云中 第
k个点都代表鼻尖。
这意味着,在3D数据准备过程中,人脸曲面需要先被配准(registration)。
另外的方法是将人脸曲面参数化,将曲面映射到平面正方形,然后用参数域上的每个像素来记录三维曲面上相应点的位置,得到一张几何图像。我们用几何图像作为生成模型的输入来进行训练。同样的,参数域上每个像素 的位置应该具有语义信息,例如在所有人脸的几何图像中,左眼角都具有相同的参数坐标。这些人脸曲面需要事先被配准。
如图9所示,从左至右,TexShape 【3】系统从一张输入图片生成纹理图像(texture),法向贴图(normal map)和几何图像 (geometry image),最后生成三维人体曲面模型。所有的中间数据都在参数域上表示。参数坐标的语义一致性要求曲面事先被配准。
基于几何偏微分方程的曲面配准方法比深度学习方法更加简单和高效。从这一角度而言,3D深度学习的方法强烈依赖于传统几何方法。我们期待共形几何和最优传输映射的理论和方法,进一步
1. Tamar Rott Shaham, Tali Dekel and Tomer Michaeli, SinGAN: Learning a Generative Model from a Single Natural Images , ICCV20 19.
2. T.Duff, K. Kohn, A. Leykin, PLMP-Point-Line Minimal Problems in Complete Multi-View Visibility, ICCV2019.
3. T. Alldieck, G. Pons-Moll, C. Theobalt and M. Magnor, Tex2Shape: Detailed Full Human Body Geometry From Single Image, ICCV2019.
4. F. Agostinelli, S. McAleer, A. Shmakov and P. Baldi, Solving the Rubik's cube with deep reinforcement learning and search, Nature Machine Intelligence, 1 256-363 (2019).
5. Tomas Rokicki, Herbert Kociemba, Morley Davidson and John Dethridge, The diameter of the Rubik's cube group is twenty, SIAM J. Discrete Math, Vol 27, No.2, pp. 1082-1105, 2013.
【 老 顾 谈 几 何 】 邀 请 国 内 国 际 著 名 纯 粹 数 学 家 , 应 用 数 学 家 , 理 论 物 理 学 家 和 计 算 机 科 学 家 , 讲 授 现 代 拓 扑 和 几 何 的 理 论 , 算 法 和 应 用 。
以上是关于当深度学习遇到3D的主要内容,如果未能解决你的问题,请参考以下文章
深度学习新应用:在PyTorch中用单个2D图像创建3D模型
为了好好看球,学霸们用深度学习重建整个比赛3D全息图
那些年深度学习所踩过的坑-第一坑
图像转换3D模型只需5行代码,英伟达推出3D深度学习工具Kaolin
2020厦门大学综述翻译:3D点云深度学习(Remote Sensiong期刊)
国防科技大学发布最新「3D点云深度学习」综述论文,带你全面了解最新点云学习方法




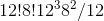 个元素。我们做魔方群的Caley图如下:每个节点代表一个操作,如果两个操作相差一个生成元,则我们连上一条边。上帝之数意味着魔方图Caley图的直径为20。
个元素。我们做魔方群的Caley图如下:每个节点代表一个操作,如果两个操作相差一个生成元,则我们连上一条边。上帝之数意味着魔方图Caley图的直径为20。