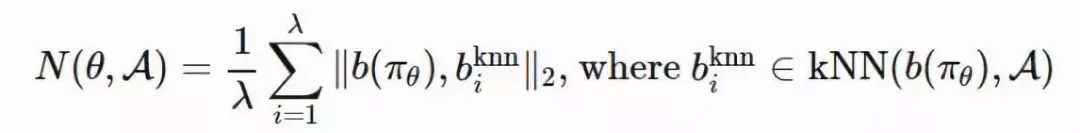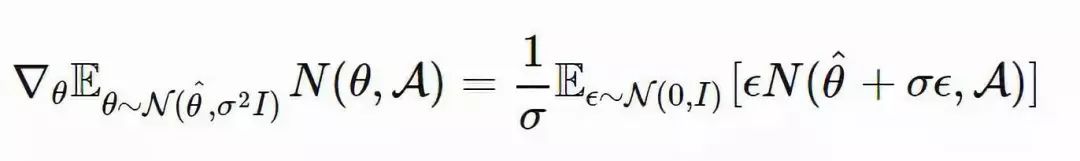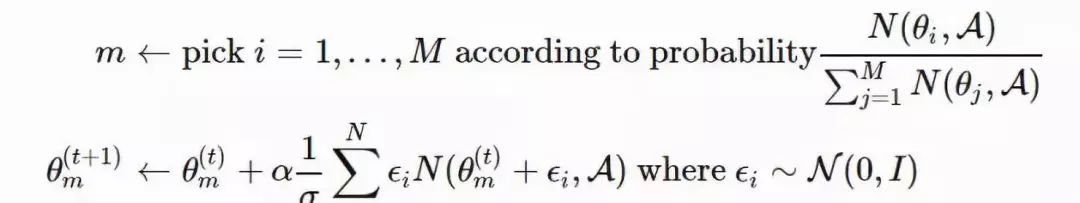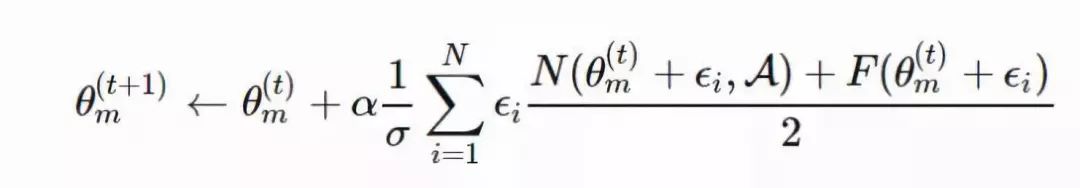标准差 σ 决定了探索的程度:当 σ 越大时,我们就可以在更大的搜索空间中对后代种群进行采样。在简单高斯演化策略中,σ(t+1) 与 σ(t) 密切相关,因此算法不能在需要时(即置信度改变时)迅速调整探索空间。「协方差矩阵自适应演化策略」(CMA-ES)通过使用协方差矩阵 C 跟踪分布上得到的样本两两之间的依赖关系,解决了这一问题。新的分布参数变为了:其中,σ 控制分布的整体尺度,我们通常称之为「步长」。在我们深入研究 CMA-ES 中的参数更新方法前,不妨先回顾一下多元高斯分布中协方差矩阵的工作原理。作为一个对称阵,协方差矩阵 C 有下列良好的性质(详见「Symmetric Matrices and Eigendecomposition」:http://s3.amazonaws.com/mitsloan-php/wp-faculty/sites/30/2016/12/15032137/Symmetric-Matrices-and-Eigendecomposition.pdf;以及证明:http://control.ucsd.edu/mauricio/courses/mae280a/lecture11.pdf):
C 始终是对角阵
C 始终是半正定矩阵
所有的特征值都是非负实数
所有特征值都是正交的
C 的特征向量可以组成 Rn 的一个标准正交基
令矩阵 C 有一个特征向量 B=[b1,...,bn] 组成的标准正交基,相应的特征值分别为 λ12,…,λn2。令 D=diag(λ1,…,λn)。C 的平方根为: 相关的符号和意义如下:
xi(t)∈Rn:第 t 代的第 i 个样本yi(t)∈Rn:xi(t)=μ(t−1)+σ(t−1)yi(t)μ(t):第 t 代的均值σ(t):步长C(t):协方差矩阵B(t):将 C 的特征向量作为行向量的矩阵D(t):对角线上的元素为 C 的特征值的对角矩阵pσ(t):第 t 代中用于 σ 的演化路径pc(t):第t 代中用于 C 的演化路径αμ:用于更新 μ 的学习率ασ:pσ 的学习率dσ:σ 更新的衰减系数Αcp:pc 的学习率αcλ:矩阵 C 的秩 min(λ, n) 更新的学习率αc1:矩阵 C 的秩 1 更新的学习率
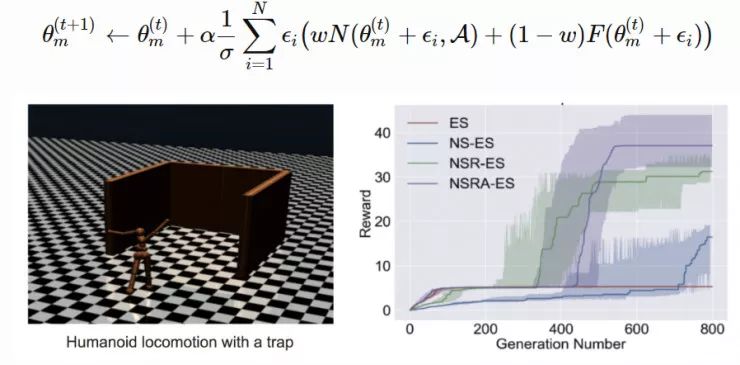
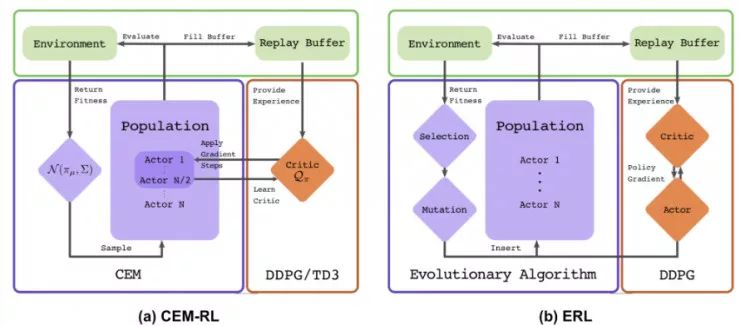
图 5:使用演化策略训练一个强化策略的算法(图片来源:论文「ES-for-RL」,https://arxiv.org/abs/1703.03864)为了使算法的性能更加鲁棒,OpenAI ES 采用了虚拟批量归一化(Virtual BN,用于计算固定统计量的 mini-batch 上的批量归一化方法),镜面采样(Mirror Sampling,采样一对 (−ϵ,ϵ) 用于估计),以及适应度塑造(Fitness Shaping)技巧。2、使用演化策略进行探索在强化学习领域,「探索与利用」是一个很重要的课题。上述演化策略中的优化方向仅仅是从累积返回函数 F(θ) 中提取到的。在不进行显式探索的情况下,智能体可能会陷入局部最优点。新颖性搜索(Novelty-Search)演化策略(NS-ES,详见 Conti 等人于 2018 年发表的论文「Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents」,论文地址:https://arxiv.org/abs/1712.06560)通过朝着最大化「新颖性得分」的方向更新参数来促进探索。「新颖性得分」取决于一个针对于特定领域的行为特征函数 b(πθ)。对 b(πθ) 的选择取决于特定的任务,并且似乎具有一定的随机性。例如,在论文里提到的人形机器人移动任务中,b(πθ) 是智能体最终的位置 (x,y)。1. 将每个策略的 b(πθ) 加入一个存档集合 A。2. 通过 b(πθ) 和 A 中所有其它实体之间的 K 最近邻得分衡量策略 πθ 的新颖性。(文档集合的用例与「情节记忆」很相似)在这里,演化策略优化步骤依赖于新颖性得分而不是适应度: NS-ES 维护了一个由 M 个独立训练的智能体组成的集合(「元-种群」),M={θ1,…,θM}。然后选择其中的一个智能体,将其按照与新颖性得分成正比的程度演化。最终,我们选择出最佳策略。这个过程相当于集成,在 SVPG 中也可以看到相同的思想。其中,N 是高斯扰动噪声向量的数量,α 是学习率。NS-ES 完全舍弃了奖励函数,仅仅针对新颖性进行优化,从而避免陷入极具迷惑性的局部最优点。为了将适应度重新考虑到公式中,研究人员又提出了两种变体。NSR-ES:NSRAdapt-ES (NSRA-ES):自适应的权重参数初始值为 w=1.0。如果算法的性能经过了很多代之后没有变化,我们就开始降低 w。然后,当性能开始提升时,我们停止降低 w,反而增大 w。这样一来,当性能停止提升时,模型更偏向于提升适应度,而不是新颖性。图 6:(左图)环境为人形机器人移动问题,该机器人被困在一个三面环绕的强中,这是一个具有迷惑性的陷阱,创造了一个局部最优点。(右图)实验对比了 ES 基线和另一种促进探索的变体。(图片来源,论文「NS-ES」,https://arxiv.org/abs/1712.06560)3、CEM-RL图 7:CEM-RL 和 ERL 算法(https://papers.nips.cc/paper/7395-evolution-guided-policy-gradient-in-reinforcement-learning.pdf)的架构示意图(图片来源:论文「CEM-RL」,https://arxiv.org/abs/1810.01222)CEM-RL 方法(详见 Pourchot 和 Sigaud 等人于 2019 年发表的论文「CEM-RL: Combining evolutionary and gradient-based methods for policy search」,论文地址:https://arxiv.org/abs/1810.01222)结合了交叉熵方法(CEM)和 DDPG 或 TD3。在这里,CEM 的工作原理与上面介绍的简单高斯演化策略基本相同,因此可以使用 CMA-ES 替换相同的函数。CEM-RL 是基于演化强化学习(ERL,详见 Khadka 和 Tumer 等人于 2018 年发表的论文「Evolution-Guided Policy Gradient in Reinforcement Learning」,论文地址:https://papers.nips.cc/paper/7395-evolution-guided-policy-gradient-in-reinforcement-learning.pdf)的框架构建的,它使用标准的演化算法选择并演化「Actor」的种群。随后,在这个过程中生成的首次展示经验也会被加入到经验回放池中,用于训练强化学习的「Actor」网络和「Critic」网络。工作流程:1. πμ 为 CEM 种群的「Actor」平均值,使用随机的「Actor」网络对其进行初始化。2. 「Critic」网络 Q 也将被初始化,通过 DDPG/TD3 算法对其进行更新。3. 重复以下步骤直到满足要求:
在分布 N(πμ,Σ) 上采样得到一个「Actor」的种群。
评估一半「Actor」的种群。将适应度得分用作累积奖励 R,并将其加入到经验回放池中。
将另一半「Actor」种群与「Critic」一同更新。
使用性能最佳的优秀样本计算出新的 πmu 和 Σ。也可以使用 CMA-ES 进行参数更新。
六、拓展:深度学习中的演化算法
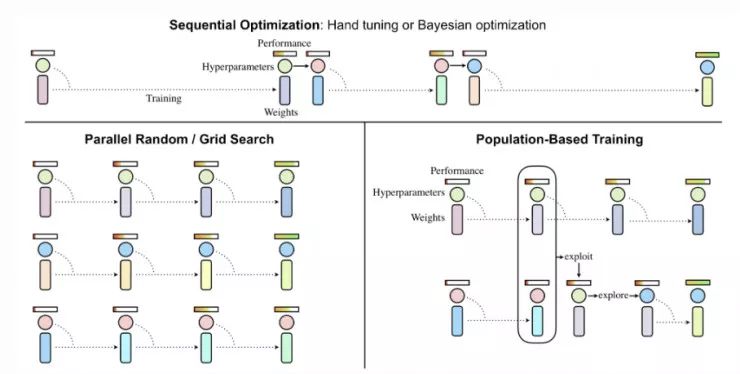
(本章并没有直接讨论演化策略,但仍然是非常有趣的相关阅读材料。)演化算法已经被应用于各种各样的深度学习问题中。「POET」(详见 Wang 等人于 2019 年发表的论文「Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions」,论文地址:https://arxiv.org/abs/1901.01753)就是一种基于演化算法的框架,它试图在解决问题的同时生成各种各样不同的任务。关于 POET 的详细介绍请参阅下面这篇关于元强化学习的博文:https://lilianweng.github.io/lil-log/2019/06/23/meta-reinforcement-learning.html#task-generation-by-domain-randomization。另一个例子则是演化强化学习(ERL),详见图 7(b)。下面,我将更详细地介绍两个应用实例:基于种群的训练(PBT),以及权重未知的神经网络(WANN) 1、超参数调优:PBT图 8:对比不同的超参数调优方式的范例(图片来源:论文「Population Based Training of Neural Networks」,https://arxiv.org/abs/1711.09846)基于种群的训练(PBT,详见 Jaderberg 等人于 2017 年发表的论文「Population Based Training of Neural Networks」,论文地址:https://arxiv.org/abs/1711.09846)将演化算法应用到了超参数调优问题中。它同时训练了一个模型的种群以及相应的超参数,从而得到最优的性能。PBT 过程起初拥有一组随机的候选解,它们包含一对模型权重的初始值和超参数 {(θi,hi)∣i=1,…,N}。我们会并行训练每个样本,然后周期性地异步评估其自身的性能。当一个成员准备好后(即该成员进行了足够的梯度更新步骤,或当性能已经足够好),就有机会通过与整个种群进行对比进行更新:
「exploit()」:当模型性能欠佳时,可以用性能更好的模型的权重来替代当前模型的权重。
「explore()」:如果模型权重被重写,「explore」步骤会使用随机噪声扰动超参数。
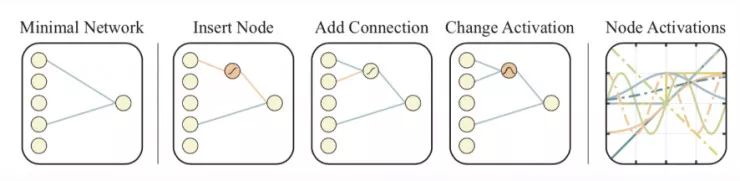
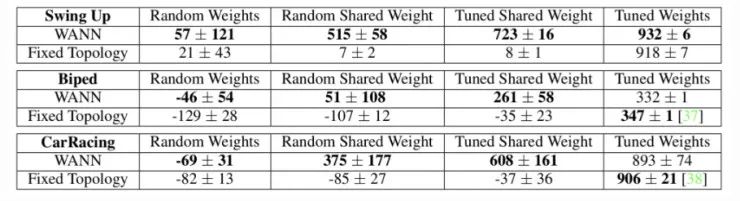
在这个过程中,只有性能良好的模型和超参数对会存活下来,并继续演化,从而更好地利用计算资源。图 9:基于种群的训练算法示意图。(图片来源,论文「Population Based Training of Neural Networks」,https://arxiv.org/abs/1711.09846) 2、网络拓扑优化:WANN权重未知的神经网络(WANN,详见 Gaier 和 Ha 等人于 2019 年发表的论文「Weight Agnostic Neural Networks」,论文地址:https://arxiv.org/abs/1906.04358)在不训练网络权重的情况下,通过搜索最小的网络拓扑来获得最优性能。由于不需要考虑网络权值的最佳配置,WANN 更加强调网络架构本身,这使得它的重点与神经网络架构搜索(NAS)不同。WANN 在演化网络拓扑的时候深深地受到了一种经典的遗传算法「NEAT」(增广拓扑的神经演化,详见 Stanley 和 Miikkulainen 等人于 2002 年发表的论文「Efficient Reinforcement Learning through Evolving Neural Network Topologies」,论文地址:http://nn.cs.utexas.edu/downloads/papers/stanley.gecco02_1.pdf)的启发。WANN 的工作流程看上去与标准的遗传算法基本一致:1. 初始化:创建一个最小网络的种群。2. 评估:使用共享的权重值进行测试。3. 排序和选择:根据性能和复杂度排序。4. 变异:通过改变最佳的网路来创建新的种群。图 10: WANN 中用于搜索新网络拓扑的变异操作。(从左到右分别为)最小网络,嵌入节点,增加连接,改变激活值,节点的激活。在「评估」阶段,我们将所有网络权重设置成相同的值。这样一来,WANN 实际上是在寻找可以用最小描述长度来描述的网络。在「选择」阶段,我们同时考虑网络连接和模型性能。图 11:将 WANN 发现的网络拓扑在不同强化学习任务上的性能与常用的基线 FF 网络进行了比较。「对共享权重调优」只需要调整一个权重值。 如图 11 所示,WANN 的结果是同时使用随机权重和共享权重(单一权重)评估得到的。有趣的是,即使在对所有权重执行权重共享并对于这单个参数进行调优的时候,WANN 也可以发现实现非常出色的性能的拓扑。
参考文献
[1] Nikolaus Hansen. “The CMA Evolution Strategy: A Tutorial” arXiv preprint arXiv:1604.00772 (2016).[2] Marc Toussaint. Slides: “Introduction to Optimization”[3] David Ha. “A Visual Guide to Evolution Strategies” blog.otoro.net. Oct 2017.[4] Daan Wierstra, et al. “Natural evolution strategies.” IEEE World Congress on Computational Intelligence, 2008.[5] Agustinus Kristiadi. “Natural Gradient Descent” Mar 2018.[6] Razvan Pascanu & Yoshua Bengio. “Revisiting Natural Gradient for Deep Networks.” arXiv preprint arXiv:1301.3584 (2013).[7] Tim Salimans, et al. “Evolution strategies as a scalable alternative to reinforcement learning.” arXiv preprint arXiv:1703.03864 (2017).[8] Edoardo Conti, et al. “Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents.” NIPS. 2018.[9] Aloïs Pourchot & Olivier Sigaud. “CEM-RL: Combining evolutionary and gradient-based methods for policy search.” ICLR 2019.[10] Shauharda Khadka & Kagan Tumer. “Evolution-guided policy gradient in reinforcement learning.” NIPS 2018.[11] Max Jaderberg, et al. “Population based training of neural networks.” arXiv preprint arXiv:1711.09846 (2017).[12] Adam Gaier & David Ha. “Weight Agnostic Neural Networks.” arXiv preprint arXiv:1906.04358 (2019).via https://lilianweng.github.io/lil-log/2019/09/05/evolution-strategies.html 点击“阅读
原文
”查看 深度学习的图像修复
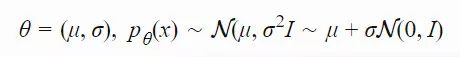
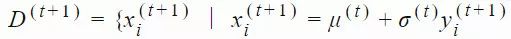
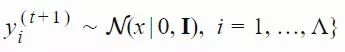
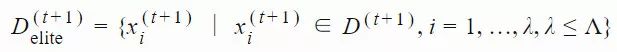
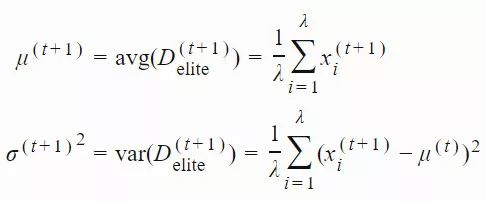
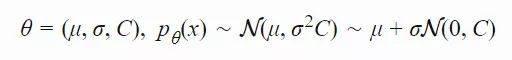
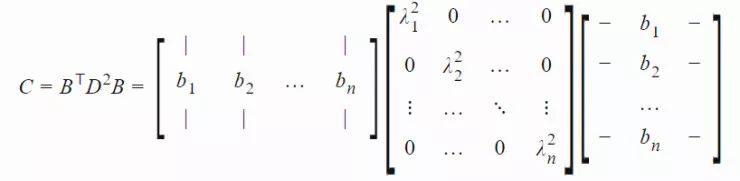
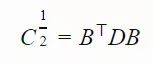
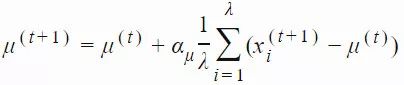
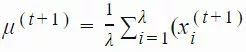
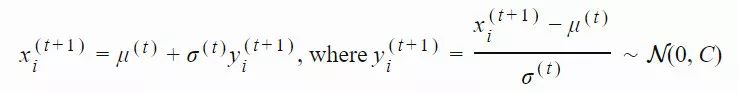
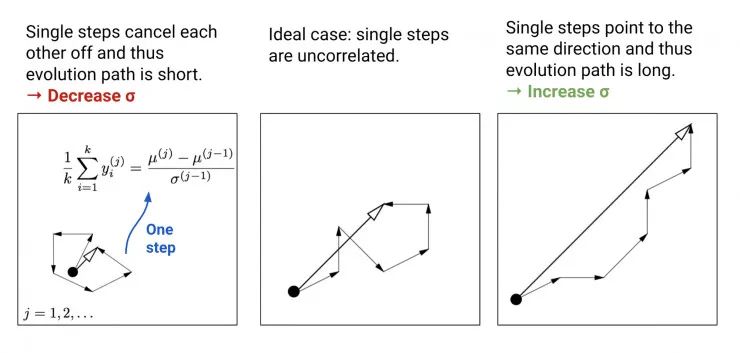
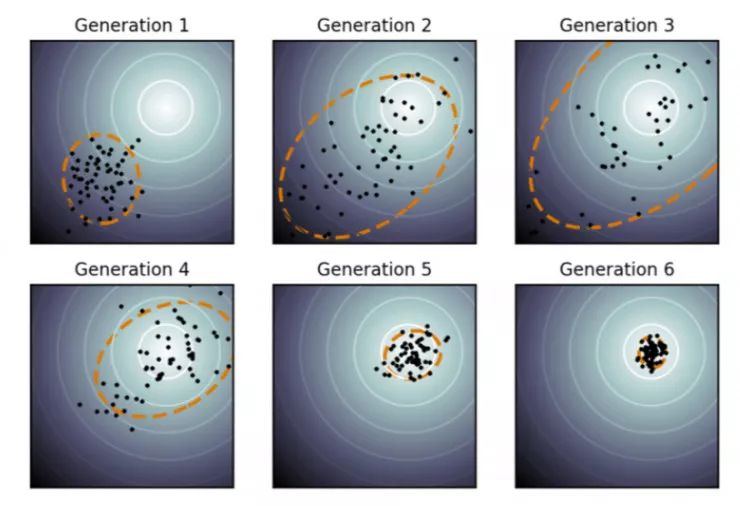
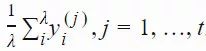 ,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
,构建了一个演化路径(evolution path)pσ。通过比较该路径与随机选择(意味着每一步之间是不相关的)状态下期望会生成的路径长度,我们可以相应地调整 σ(详见图 2)。
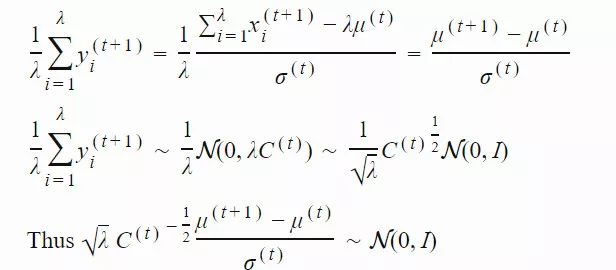
的工作原理如下:
将各主轴的长度放缩到相等的状态。
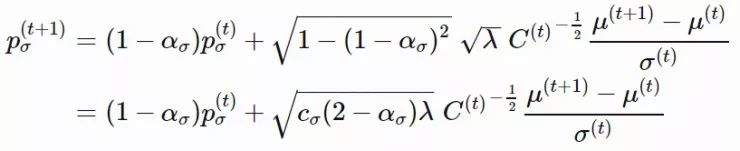
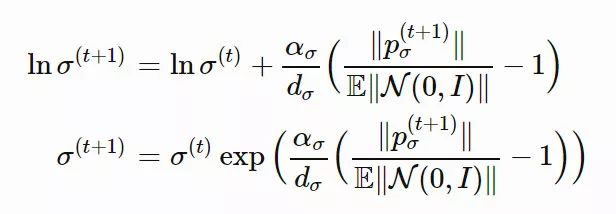
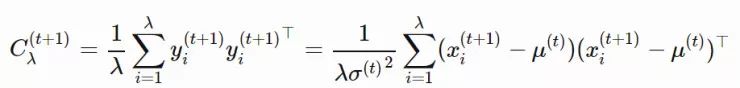
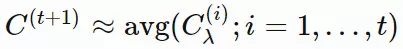
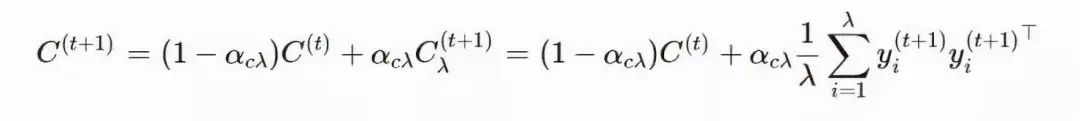
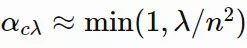
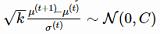 ,pc的计算方法如下:
,pc的计算方法如下:
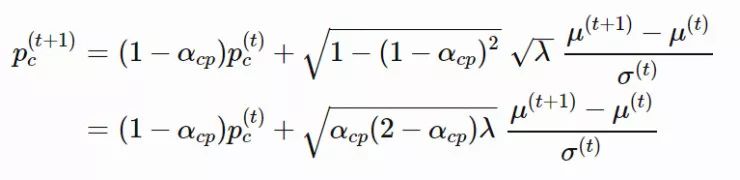
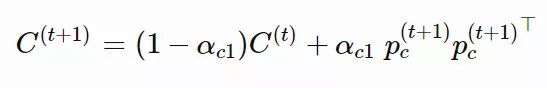
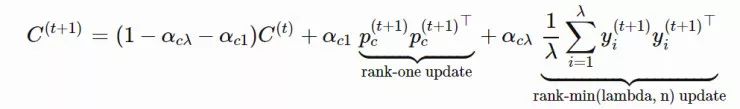

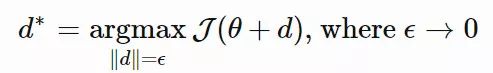
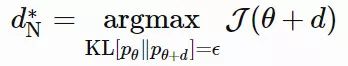
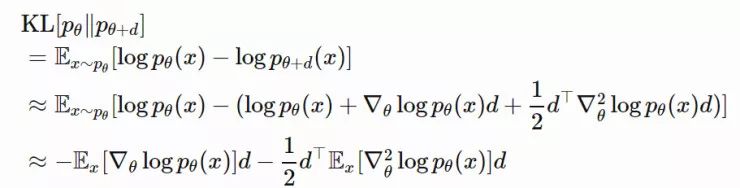
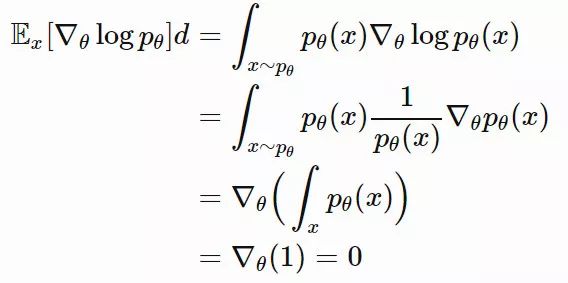
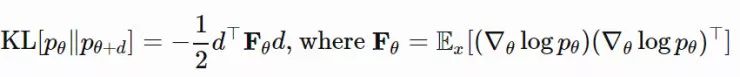
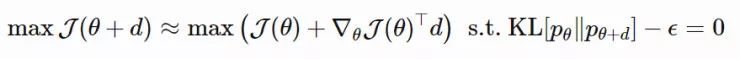
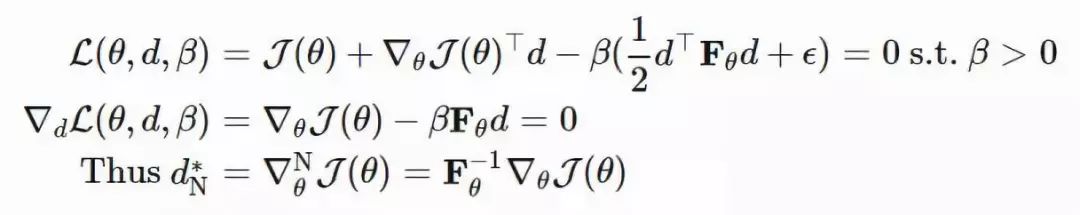 其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
其中 dN∗仅仅提取了忽略标量 β−1 的情况下,在 θ 上最优移动步长的方向。
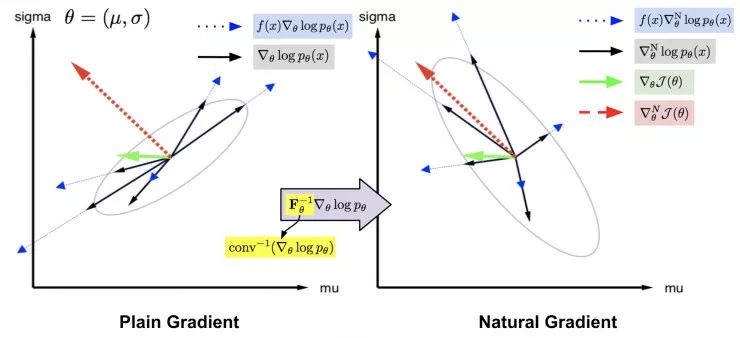
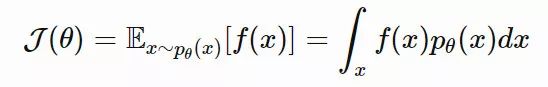

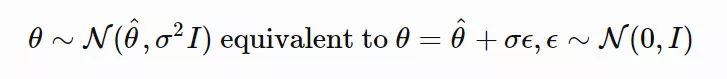
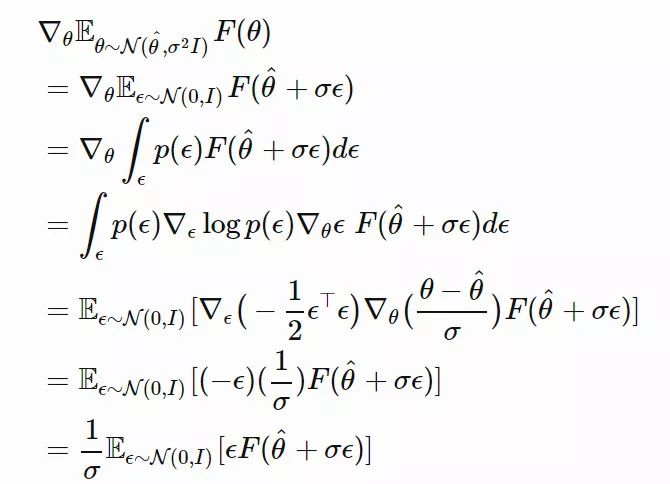
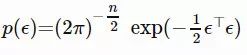 。
。
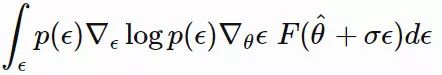 是我们用到的似然计算技巧。
是我们用到的似然计算技巧。