深度学习基础之 Dropout
Posted 机器学习算法与自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基础之 Dropout相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
作 者 | Irfan Danish
在少量训练数据情况下,深度学习的神经网络模型很容易出现过拟合。
我们知道,将具有不同配置的卷积神经网络模型组合可以减少过拟合,但代价是需要额外的训练和维护多个模型。
单个模型可以模拟具有大量不同网络体系结构,在训练期间随机删除节点。这称为"dropout",它提供了一种非常廉价且有效的正则化方法,以减少过拟合并改进各种深度神经网络中的泛化误差。
在这篇文章中,你会发现使用dropout正则化可以减少过拟合,并能够改进深度神经网络的泛化性。
阅读本文后,您将知道:
神经网络中的大权重是复杂网络过拟合训练数据的一个标志。
在网络中删除节点是一种简单而有效的正则化方法。
使用dropout时,建议建立一个多次训练和使用权重约束的大型网络。
概述
本教程分为五个部分。它们是:
-
过拟合问题 -
随机丢失节点 -
如何使用dropout -
使用dropout的示例 -
使用降序正则化的方法
过拟合问题
在相对较小的数据集上训练大型神经网络可能过拟合训练数据。
这是模型在训练数据中学习到了统计噪声的结果,当新数据(例如测试数据集)评估模型时,会出现性能不佳。由于过拟合,泛化性的错误增加。
减少过拟合的一种方法是在同一数据集上训练所有可能的不同神经网络,并采用对每个模型的预测结果取平均的方法。这在实践中是不可行的,单可以使用不同模型的小集合进行近似。

无限计算的条件下,对固定的模型进行"规范化"的最佳方法是对参数的所有可能设置的预测进行平均,在给定训练数据的情况下按概率对每个设置进行加权。
—— Dropout :防止神经网络过拟合的简单方法
(Link:)
整体近似的一个问题是,它需要多个模型训练和存储,这可能是一个挑战,因为如果模型很大,会需要几天或几周来训练和调整。
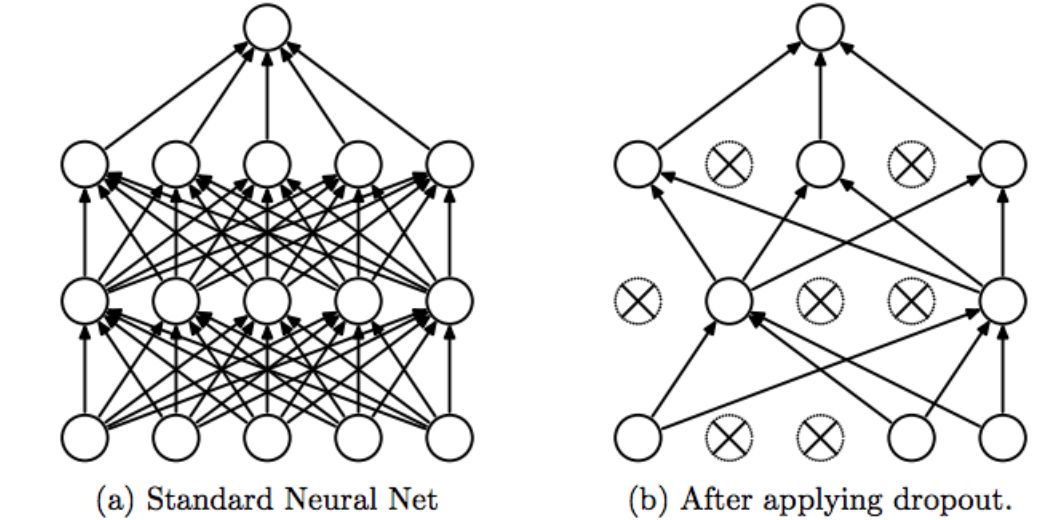
随机丢失节点
Dropout策略是一种近似同时训练许多不同的卷积神经网络的正则化方法。
在训练过程中,一些层的输出被随机忽略或“丢弃”,这种效果使原本的图层看起来像具有不同节点数,并且与前一个图层的连接关系也发生了变化。实际上,在训练期间对图层的每次更新都会对设置图层的不同“视图”执行。
通过丢弃一个单元,意味着暂时将其从网络中删除,以及其所有传入和传出连接。
—— Dropout :防止神经网络过拟合的简单方法
Dropout 会使训练过程变得嘈杂,迫使图层中的节点对输入承担或多或少的责任。
这种概念表明,网络层会共同自适应纠正以前层的错误,进而使模型更加健壮。
……节点单元可能会改变,以弥补其他节点单元的错误。这可能导致复杂的相互适应。这反过来又会导致过拟合,因为这些相互适应并没有泛化到看不见的数据。[…]
—— Dropout :防止神经网络过拟合的简单方法
Dropout模拟来自给定层的稀疏激活,有趣的是,这反过来又鼓励网络实际学习稀疏表示作为副作用。因此,它可以用作输出正则化的替代,以鼓励自动编码器模型中的稀疏表示。
我们发现作为退出的副作用,隐藏单元的激活变得稀疏,即使不存在诱导稀疏的正则化。
—— Dropout :防止神经网络过拟合的简单方法
因为Dropout的下一层的输出是随机采样的,因此在训练过程中,它具有减小网络容量或细化网络的效果。因此,当使用Dropout时,可能需要更宽的网络,例如更多的节点。
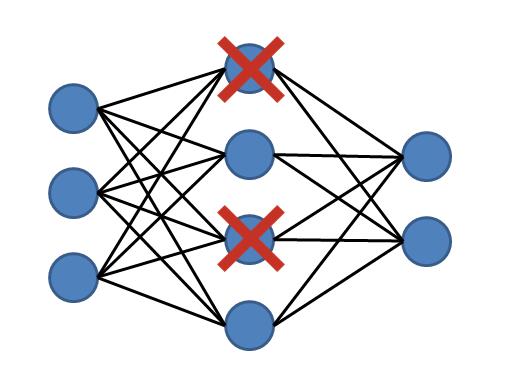
如何进行Dropout?
随机失活是在神经网络中每层中实现。
它可以与大多数类型的层一起使用,例如密集完连接层、卷积层和循环层(如长短期内存网络层)。
随机失活可以在网络中的任何或这所有的隐藏图层,以及可见层或输入层上都可以实现,但它不在输出层中使用。
术语"dropout"是指在神经网络中丢弃节点单元(隐藏和可见的图层)。
—— Dropout :防止神经网络过拟合的简单方法
随机失活作为引入的一个新的超参数,指定图层输出单元被丢弃的概率
或者相反地,指定了图层输出所保留单元的概率。这个详细解释可能不同论文和程序中有所不同。
一个大家公共使用的值是隐藏层节点的输出保留的概率为 0.5,可见层输出保留的概率接近 1.0(如 0.8)。
在最简单的情况下,每个单元都保留一个独立于其他单元的固定概率 p,其中 p 可以使用验证集,也可以简单地设置为 0.5,这似乎接近于各种网络和任务的最佳值。但是,对于输入单元,最佳保留概率通常接近 1 而不是 0.5。
—— Dropout :防止神经网络过拟合的简单方法
随机失活在训练过后的测试阶段并不使用。
由于随机失活的使用,网络的权重会比正常的网络权重大。因此在,最终在网络模型权重保存之前,权重首先根据随机失活的比例进行了缩放。然后,保存的网络可以用于正常的测试。
如果在训练期间一个单元节点的保留概率p ,则该单元的传出权重在测试时乘以 p。
—— Dropout :防止神经网络过拟合的简单方法
这种权重的重新缩放也可以在训练时间进行,在小批次结束时的权重更新之后执行。这有时被称为"反向dropout",不需要在训练期间修改权重。Keras 和 PyTorch 深度学习库都以这种方式实现dropout的。
在测试时,我们通过随机失活的比例缩减输出结果。[...]请注意,此过程可以通过在训练时执行操作并在测试时使输出保持不变来实现,这通常是在实践中实现的过程。
— 第109页, Deep Learning With Python(https://amzn.to/2wVqZDq)
随机失活在实践中的效果很好,或许可以取代权重正则化(如权重衰减)和活动正则化(例如表示稀疏性)的需要。
...与其他标准、计算成本低廉的正则器(如权重衰减、滤波器规范约束和稀疏活动正则化)相比,随机失活更有效。随机失活也可与其他形式的正则化方法相结合,以便进一步改善模型。
— 第265页, 深度学习(https://amzn.to/2NJW3gE)
使用随机失活的示例
本节总结了最近研究论文中使用随机失活的一些例子,就如何以及在哪里使用随机失活提供了建议。
Geoffrey Hinton等人在其2012年的论文中首次引入了"通过防止特征检测器共同适应来改善神经网络"的随机失活,将该方法应用于一系列不同的神经网络,用于不同问题类型。改进的结果,包括手写数字识别 (MNIST)、照片分类 (CIFAR-10) 和语音识别 (TIMIT)。
我们使用相同的随机失活率 – 所有隐藏单元的 50% 随机失活率和可见单元的 20% 随机失活率
Nitish Srivastava等人在其 2014 年期刊论文中介绍了名为" 随机失活 :防止神经网络过度拟合的简单方法",这些论文用于各种计算机视觉、语音识别和文本分类任务,并发现它始终能够改善每个问题的性能。
我们针对不同域的数据集上的分类问题对神经网络随机失活进行了训练。我们发现,与不使用随机失活的神经网络相比,随机失活提高了所有数据集的泛化性能。
在计算机视觉问题上,通过网络的各个层,结合最大标准权重约束,使用不同的随机失活率。
对于网络的不同层(从输入到卷积层到全连接层),将单元保留为 p = (0.9、 0.75、 0.5、 0.5、 0.5) 的概率应用于网络的所有层。此外,c = 4 的最大规范约束用于所有权重。[...]
文本分类任务使用了更简单的配置。
我们在输入层中使用了保留 p = 0.8 的概率,在隐藏层中使用了 0.5 的概率。所有图层都使用了 c = 4 的最大规范约束。
Alex Krizhevsky等人在其著名的2012年论文《图像分类与深层卷积神经网络》中,利用卷积神经网络和随机失活取得了(当时)在ImageNet数据集上使用深度卷积神经的图片分类的最先进的结果。
我们在前两个全连接的层(模型)中使用随机失活。在没有随机失活的情况下,我们的网络表现出很大的过拟合。使用随机失活大约使收敛所需的迭代次数翻倍。
George Dahl 等人在 2013 年题为"使用校正的线性单位和随机失活改进 LVCSR 的深度神经网络"的论文中,使用具有修正线性激活函数和随机失活的深层神经网络,实现了(当时)最先进的结果。标准语音识别任务。他们使用贝叶斯优化过程来配置激活功能的选择和随机失活概率。
...贝叶斯优化过程可知,随机失活对于我们训练的sigmoid网没有帮助。一般来说,ReLUs 和随机失活似乎一起使用效果更好。
使用随机失活正则化的步骤
本节提供了一些有关在神经网络中使用随机失活正则的提示。
-
与所有网络类型一起使用
随机失活正则化是一种通用方法。它可以与大多数,也许所有类型的神经网络模型一起使用,尤其是最常见的网络类型的多层感知器、卷积神经网络和长期短期记忆循环神经网络。
对于 LSTM,最好对输入和循环连接使用不同的失活率。
-
随机失活率
随机失活超参数的默认解释是在图层中训练给定节点的概率,其中 1.0 表示没有丢弃节点,0.0 表示图层没有输出。
隐藏层中随机失活的良好值介于 0.5 和 0.8 之间。输入图层使用较大的随机失活率,例如 0.8。
使用更大的网络
较大的网络(更多层或更多节点)更容易使训练数据过拟合,这是很常见的。
使用随机失活正则化时,可以使用较大的网络,而过拟合的风险较小。事实上,可能需要一个大型网络(每层更多的节点),因为随机失活会可能降低网络的容量。
一条好的经验法则是,在使用随机失活前,将图层中的节点数除以建议的随机失活率,并将其用作新网络中使用随机失活的节点数。例如,具有 100 个节点且建议的随机失活率为 0.5 的网络在使用随机失活时将需要 200 个节点 (100 / 0.5)。
如果 n 是任何层中的隐藏单位数,p 是保留单位的概率 [...] 良好的随机失活网络应至少具有 n/p 单位。
—— Dropout :防止神经网络过拟合的简单方法
网格搜索参数
与其猜测合适的网络dropout 率,不如系统地测试不同的dropout 率。
例如,测试1.0到0.1之间的值,增量为0.1。
这将帮助您发现什么最适合您的特定模型和数据集,以及模型对辍学率的敏感程度。一个更敏感的模型可能是不稳定的,并可能受益于规模的增加。
使用权重约束
网络权重将随着层激活的概率移除而增大。
较大的权重大小可能表示网络不稳定。
为了抵消这种影响,可以施加权重约束,以强制层中所有权重的范数(大小)低于指定值。例如,建议最大范数约束值在3到4之间。
[…]我们可以使用最大范数正则化。这将限制每个隐藏单元的传入权重向量的范数受常数c的约束。c的典型值范围为3到4。
—— Dropout :防止神经网络过拟合的简单方法
这确实引入了一个额外的超参数,可能需要对模型进行优化。
使用较小的数据集
与其他规范化方法一样,对于训练数据量有限且模型可能过拟合训练数据的问题,随机失活更为有效。
问题在于,如果存在大量的训练数据,则使用随机失活可能受益较少。
对于非常大的数据集,正则化方法很少会减少一般性误差。在这些情况下,使用随机失活和较大模型的计算成本可能超过正则化的好处。
— 第265页, 深度学习(https://amzn.to/2NJW3gE)
进一步阅读
如果你希望更深入,本节将提供有关该主题的更多资源。
书
第7.12节:Dropout,深度学习(https://amzn.to/2NJW3gE)
第4.4.3节:添加Dropout,Python深度学习(https://amzn.to/2wVqZDq)
论文
通过防止特征检测器的协同适应来改进神经网络(https://arxiv.org/abs/1207.0580)
Dropout:防止神经网络过度拟合的简单方法(http://jmlr.org/papers/v15/srivastava14a.html)
使用校正线性单元和Dropout改进LVCSR的深层神经网络(https://ieeexplore.ieee.org/document/6639346/)
作为适应性正规化的Dropout训练(https://arxiv.org/abs/1307.1493)
帖子
基于keras的深度学习模型中的Dropout正则化(https://machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/)
如何利用lstm网络进行时间序列预测(https://machinelearningmastery.com/use-dropout-lstm-networks-time-series-forecasting/)
文章
Dropout(神经网络),维基百科(https://en.wikipedia.org/wiki/Dropout_(neural_networks))
正则化,cs231n用于视觉识别的卷积神经网络(http://cs231n.github.io/neural-networks-2/#reg)
“Dropout”是怎么产生的?有“啊哈”的时候吗?(https://www.reddit.com/r/MachineLearning/comments/4w6tsv/ama_we_are_the_google_brain_team_wed_love_to/d64yyas)
总结
在这篇文章中,你发现了使用Dropout正则化来减少过拟合,并改进深度神经网络的泛化。
具体来说,你学到了:
神经网络中的权值是一个更复杂的网络过拟合训练数据的迹象。
使用概率剔除网络中的节点是一种简单有效的正则化方法。
在使用Dropout时,建议使用一个具有更多训练和使用权重约束的大型网络。
推荐阅读:
以上是关于深度学习基础之 Dropout的主要内容,如果未能解决你的问题,请参考以下文章
深度学习入门基础CNN系列——批归一化(Batch Normalization)和丢弃法(dropout)