建立一个玩游戏的深度学习神经网络
Posted 小熊大AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了建立一个玩游戏的深度学习神经网络相关的知识,希望对你有一定的参考价值。
在学习之Keras后,我决定给自己一个挑战,一个简单有趣的挑战,制作一个会自己玩游戏的神经网络。本文将会分为四部分来讲解我是如何做到这些的。
第一部分是构建游戏。
我在PyGame中编写游戏,但由于本文不是如何用Python构建游戏,所以我将跳过我创建游戏的方式,实际上只是用Google搜索“learn PyGame”并花一个小时来学习就可以了,实际上非常简单。
游戏其实非常简单。它看起来如下所示:
玩家是黑色方框子,障碍是黑色三角形。唯一的控制是使用空格键跳过。
最初游戏非常简单和容易,但是当我创建神经网络时,我将使它变得更加复杂和困难。
在这次测试中,我认为神经网络的得分超过了300分。在一次运行中,我已经让它达到了数千分!
现在,我们来讨论如何做到这一点。
以下是神经网络和游戏如何相互作用的概述。
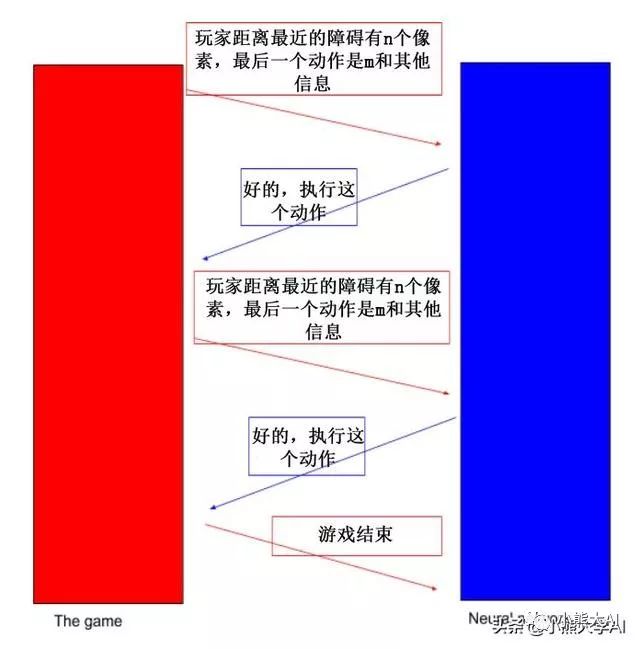
这就是游戏和神经网络是如何相互沟通的。
每隔几帧,游戏就会向神经网络发送一条重要消息,神经网络可以利用这些信息学习,然后做出决定并发送给游戏。游戏会做出这样的决定,让玩家采取相应的行动。
究竟神经网络和游戏在这种交流中会交换什么并不是目前主要关注的问题。现在,将神经网络和游戏视为独立的实体,它们各自做自己的事情,并在需要时相互交谈。
训练
为了让神经网络变得更好,我们需要让它学习。要做到这一点,我们需要有关神经网络执行的操作是否正确的信息。为此,我们将使用score。
在两个项目上的得分发生了变化 -
当玩家成功穿越障碍并跳过障碍时,以及当玩家没有跳跃并且仍然停留在地面上时。得分增加的原因很明显。如果神经网络没有因为保持静止而获得奖励,那么理想的策略就是始终跳跃。作为一个神经网络,它学会不断地跳跃。因此,当它不需要跳跃时,我们需要奖励它。这就是为什么我们在没有跳跃的情况下给它+1分。
游戏将发送到神经网络的关键信息之一是最后一个动作是什么以及它如何影响分数。如果分数增加,则意味着最后一个动作是成功的动作,并且神经网络将其添加到其训练数据中,否则神经网络忽略最后一个动作。
当您实际查看代码并自行进行更改并查看神经网络的行为时,这些概念将更容易理解。
最后,对于最初的几次运行,神经网络将作出一些随机决定来学习。一个蹒跚学步的孩子第一次走路时撞到了桌子,然后哭了起来。这个蹒跚学步的孩子学会了不靠近桌子。这就是我们的神经网络最初会做的事情。它将进行随机跳跃,如果这些跳跃不起作用,它将从中学习,并利用这些信息在下一场比赛中做出更好的决定。
第二部分与游戏互动
在安装Pygame之前,请确保已安装Python。你会注意到有两个版本的Python:Python 2和Python 3。就我个人而言,我建议你使用Python 2和Pygame,因为Python 2更普遍,并且Pygame模块不支持Python 3。我假设您已经获取了游戏并安装了带有pip的pygame。让我们从实际运行游戏开始:
1、运行:Python enemy.py
2、运行:Python player.py
3、运行:Python game.py
你应该看到如下界面:
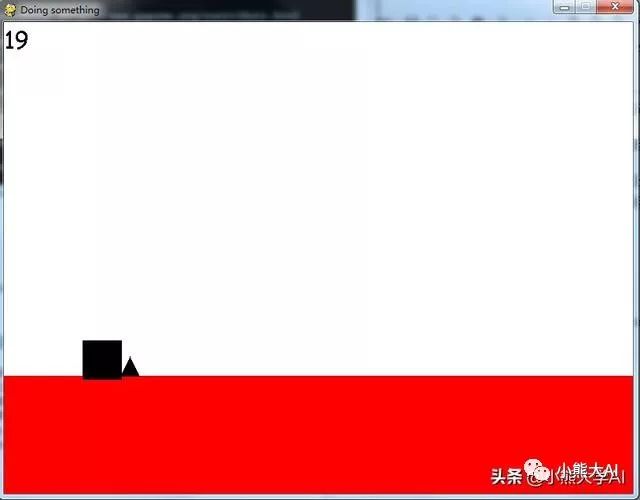
空格键是跳跃按钮。使用“W”和“S”来增加和减少游戏的整体速度(这实际上会改变帧率)。
请注意,神经网络实际上并不关心游戏的速度,它在一定数量的帧之后运行,而不是秒数。这意味着如果它在50帧之后运行,那么如果游戏以50帧每秒的速度运行,它将每秒运行一次,如果游戏以100帧每秒的速度运行,它将每秒运行两次。神经网络作为一种计算机程序,可以适应游戏的速度。我添加了W和S响应按键只是为了观察神经网络在你想做决定的时候通过降低帧率或增加帧率来快速前进。
无论如何,让我们进一步讨论如何使程序与游戏进行交互。根据第一部分的视图我们可以得到让神经网络来告诉游戏该做什么。现在这是一个非常具有挑战性的任务,所以让我们把注意力放在一些更简单的事情上,制作一个程序,就像我们的神经网络一样与游戏交互,但没有实际的神经网络。
先让我们创建一个nn.py文件。
我们创建一个Wrapper类,这个Wrapper类的init方法除了在game.py中调用函数“controlled_run()”外,实际上没有做什么。这是神经网络与游戏沟通的开始。我们的神经网络告诉游戏开始。它传递两个关键信息,一个是它自己,另一个是一个整数,它只告诉游戏运行了多少次。它有一个叫做control的方法,游戏调用这个方法控制并传递一个包含重要信息的字典,比如当前的分数,下一个障碍有多远等等。然后,神经网络在控制函数中执行它需要做的事情。函数的末尾是将控制权返回给游戏。让我用图表来更好地说明它。
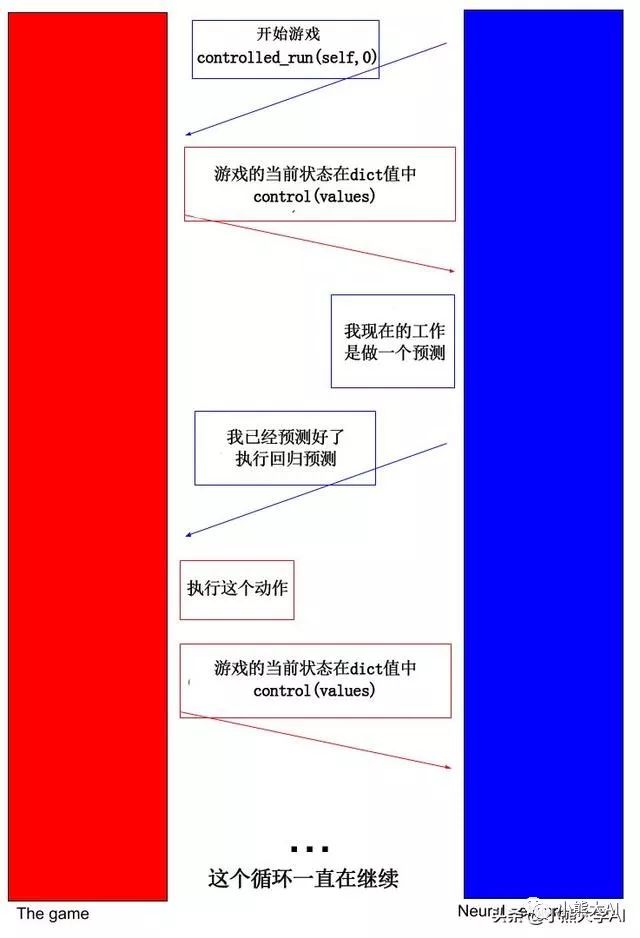
我希望你对正在发生的事情有个大概的了解,我们开始执行编码。我们将从编写Wrapper类开始:
from game import controlled_run
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
# Do some work here
# Finally, return the prediction
def gameover(self, score):
# The game has completed. Do cleanup stuff here
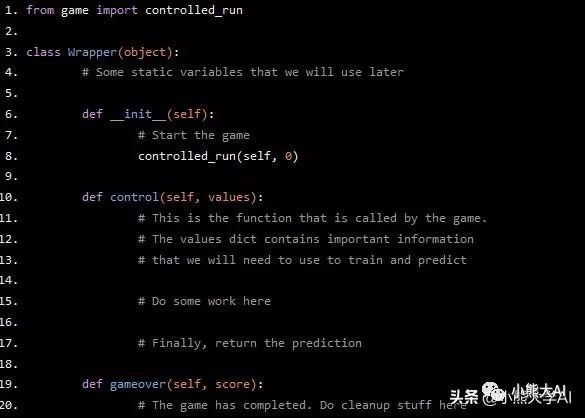
现在发生的事情应该很清楚了。让我们从实际的代码段填充函数开始。
先暂时忘记神经网络,让我们专注于与游戏沟通。对controlled_run函数的调用已经存在,这将启动游戏。游戏会在一段时间后调用函数control,然后我们需要做出预测并将其返回到游戏中。
我们可以告诉游戏现在做两件事,要么跳跃要么什么都不做。
为了便于阅读,我在game.py中定义了两个可以导入的变量。这些变量是DO_NOTHING和JUMP。我们将在control函数的末尾返回其中一个,一旦游戏完成,游戏将调用函数gameover来做清理工作。
让我们在control()中返回JUMP操作并运行我们的程序:
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
print (values)
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
# Let's return only JUMP now
return JUMP
def gameover(self, score):
# The game has completed. Do cleanup stuff here
# Don't worry about this function right now
pass
if __name__ == '__main__':
w = Wrapper()
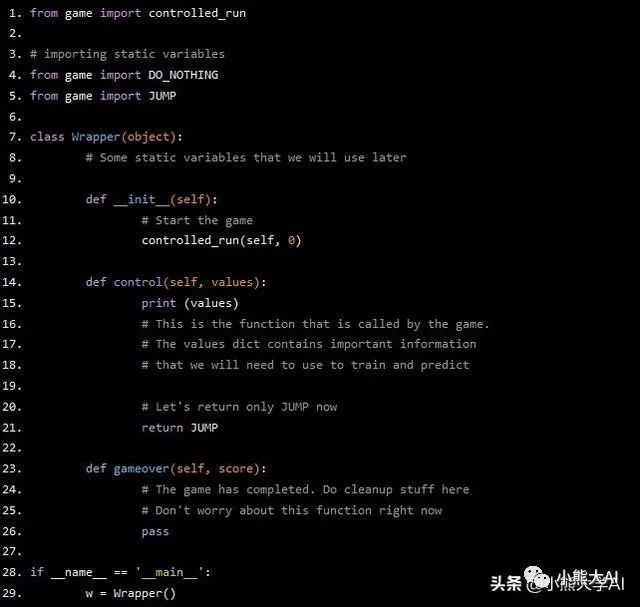
尝试运行该程序,如果您的代码与上面的列表完全相同,它应该运行正常。
玩家会不断跳跃,甚至会获得一点分数。此外,您还可以看到游戏运行过程中您从control函数控件中获得的值。
这就是游戏开始时dict的样子。
{'action': 0, 'closest_enemy': -1, 'score_increased': 0, 'old_closest_enemy': -1}

这里的动作是上次运行神经网络时执行的动作,最接近的障碍是最近的障碍离开玩家的像素数(我们将使用它进行预测)(如果有,则为-1)如果得分没有增加,则增加为0,如果在最后一次动作后得分增加,则增加1分,最后,old_closest_enemy是神经网络发送动作时障碍和玩家之间的像素数(我们将使用这个进行训练)。
这是障碍实际存在时dict值的另一个副本。
{'action': 1, 'closest_enemy': 667, 'score_increased': 0, 'old_closest_enemy': 976}

这里有很多东西需要消化,所以如果需要的话,请花点时间,确保你对我在最后几行说的内容有一些概念。
现在,我们已经对我们得到的信息有了一些概念,让用户输入玩家应该做什么。
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# Let's ask for input
print ("Enter 1 for JUMP and 0 for DO_NOTHING")
action = int(input())
return action
def gameover(self, score):
# The game has completed. Do cleanup stuff here
# Don't worry about this function right now
pass
if __name__ == '__main__':
w = Wrapper()
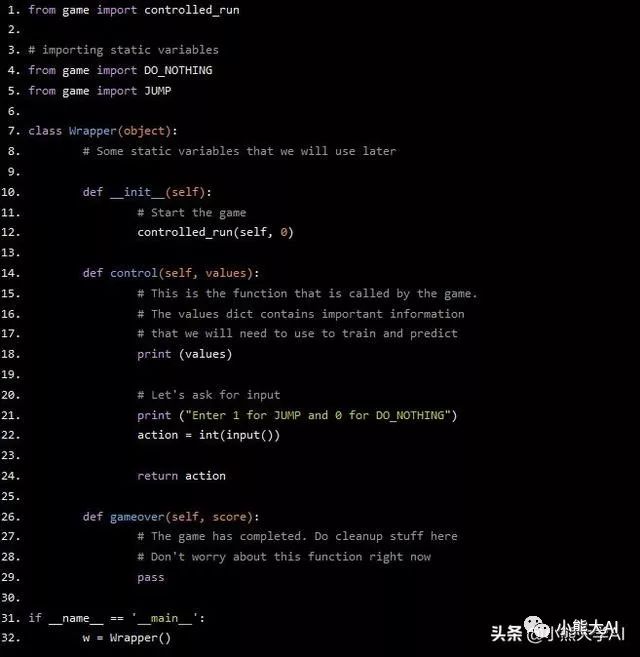
这里我没有做太多修改。再次运行程序,看看你得到了什么。
你现在应该处在神经网络的位置。获取dict值并返回玩家是否应该跳跃。这正是神经网络应该做的。
最后,让我们处理gameover函数,这样我们就可以在每次失败时重新启动游戏。我将声明两个全局变量,一个表示我们可以玩的游戏总数,另一个用于计算游戏运行数量。这样我们才能最终退出程序。
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 5
games_count = 0
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# Let's ask for input
print ("Enter 1 for JUMP and 0 for DO_NOTHING")
action = int(input())
return action
def gameover(self, score):
global games_count
games_count += 1
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, 0)
if __name__ == '__main__':
w = Wrapper()
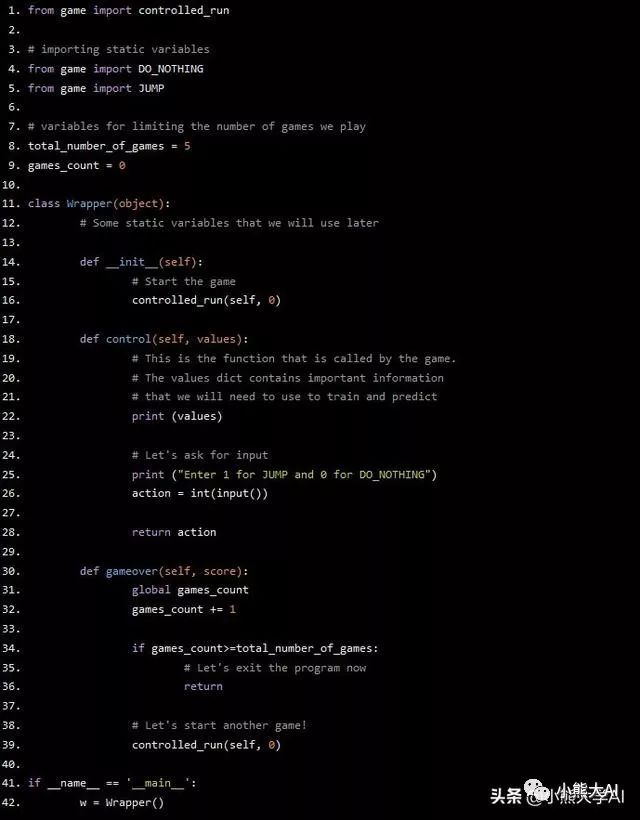
我们现在已经编写了gameover函数。一个很小的细节是,每当我们调用函数controlled_run时,都会将第二个参数作为0传入。第二个参数应该表示我们玩过的游戏数量。0显然不正确。幸运的是,我们有一个全局变量games_count记录我们玩的游戏数量,我们可以在这里。只需稍微改动一下,如下所示:
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 5
games_count = 0
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# Let's ask for input
print ("Enter 1 for JUMP and 0 for DO_NOTHING")
action = int(input())
return action
def gameover(self, score):
global games_count
games_count += 1
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, games_count)
if __name__ == '__main__':
w = Wrapper()
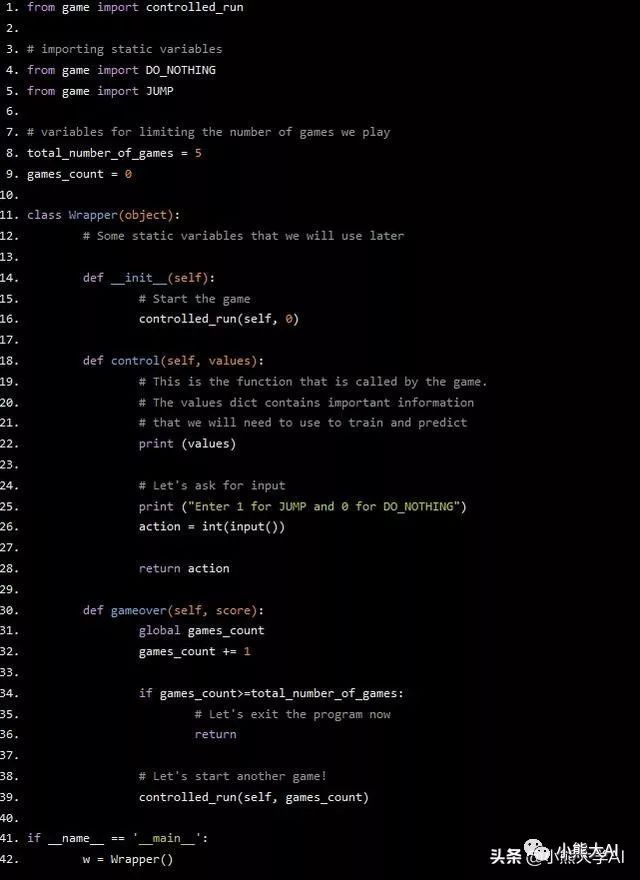
现在,我们可以在窗口标题中看到我们正在进行的游戏的数量了!
我们现在需要做的就是用神经网络代替用户来玩游戏。
第三部分进行神经网络的编码
我们需要做几件事:
获取训练数据
实现神经网络
让神经网络做一些随机的事情来训练它
获取训练数据
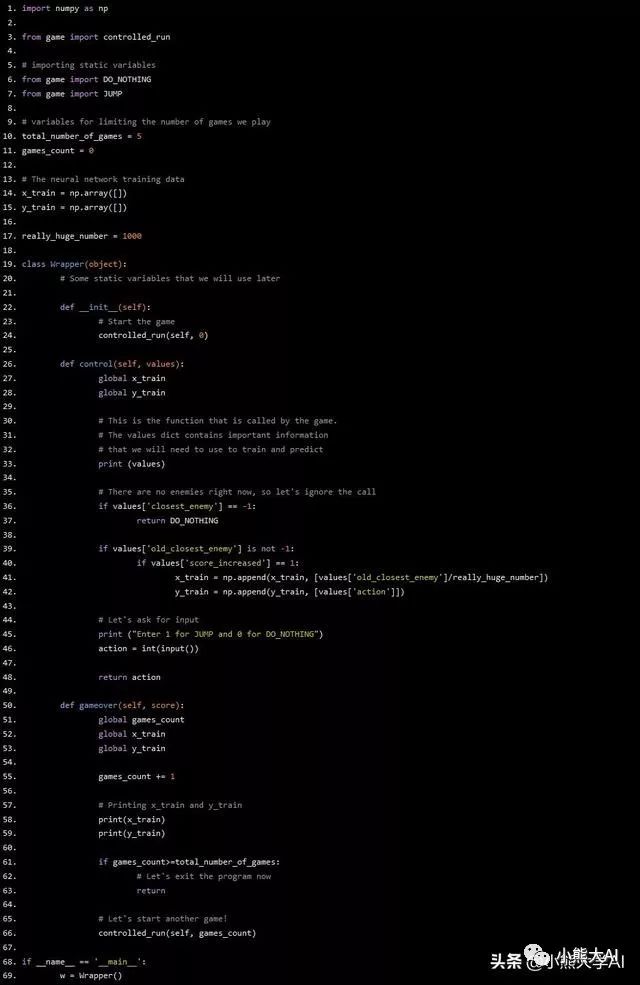
我们需要做的是创建两个列表(这里的列表是指numpy列表)x_train和y_train,每当我们的神经网络做出正确的决策时(即得分增加),我们将玩家和障碍之间的距离添加到x_train中,并将决策添加到y_train中。这形成了我们的training_data。
第一步是在我们的Wrapper类定义之上创建x_train和y_train列表。然后,每当做出决定时,检查分数是否增加,是否将其添加到我们的列表中。
在我们把这些写进代码之前还有一件事。要正确训练神经网络,输入范围需要控制在0-1内。但我们的情况并非如此。我们需要做的只是一个简单的除法来解决这个问题。任何障碍和玩家之间的最大距离大约是1000。我们除以1000就可以了。最后,我们在gameover函数中输出numpy数组。
代码如下所示:
import numpy as np
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 5
games_count = 0
# The neural network training data
x_train = np.array([])
y_train = np.array([])
really_huge_number = 1000
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
global x_train
global y_train
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# There are no enemies right now, so let's ignore the call
if values['closest_enemy'] == -1:
return DO_NOTHING
if values['old_closest_enemy'] is not -1:
if values['score_increased'] == 1:
x_train = np.append(x_train, [values['old_closest_enemy']/really_huge_number])
y_train = np.append(y_train, [values['action']])
# Let's ask for input
print ("Enter 1 for JUMP and 0 for DO_NOTHING")
action = int(input())
return action
def gameover(self, score):
global games_count
global x_train
global y_train
games_count += 1
# Printing x_train and y_train
print(x_train)
print(y_train)
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, games_count)
if __name__ == '__main__':
w = Wrapper()
现在可以运行游戏,看看更改是否按照应有的方式运行。
实现神经网络
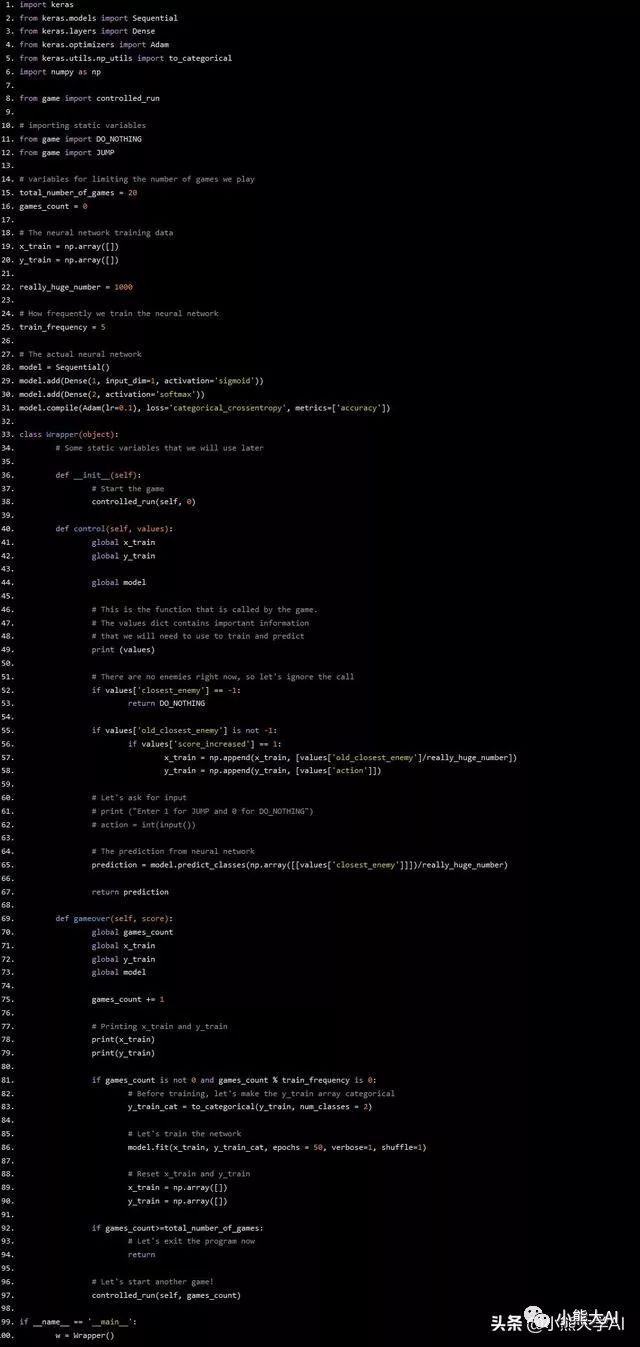
正如大多数人可能已经想到的那样,神经网络可以非常简单。这是一个简单的线性分类。虽然你可以在每一层中尝试任意数量的层和神经元,但是这样的神经网络会变得越来越复杂。现在,我们只需要一个两层的神经网络。第一层有一个神经元和两个输出神经元。
在创建神经网络之前,我们需要弄清楚它何时会开始学习。我将实现每10次游戏教一次神经网络,您可以根据需要更改它。在gameover函数中,这是一个简单的if语句。当我们训练神经网络时,我们也将清空x_train和y_train数组。
代码如下所示:
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
import numpy as np
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 20
games_count = 0
# The neural network training data
x_train = np.array([])
y_train = np.array([])
really_huge_number = 1000
# How frequently we train the neural network
train_frequency = 5
# The actual neural network
model = Sequential()
model.add(Dense(1, input_dim=1, activation='sigmoid'))
model.add(Dense(2, activation='softmax'))
model.compile(Adam(lr=0.1), loss='categorical_crossentropy', metrics=['accuracy'])
class Wrapper(object):
# Some static variables that we will use later
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
global x_train
global y_train
global model
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# There are no enemies right now, so let's ignore the call
if values['closest_enemy'] == -1:
return DO_NOTHING
if values['old_closest_enemy'] is not -1:
if values['score_increased'] == 1:
x_train = np.append(x_train, [values['old_closest_enemy']/really_huge_number])
y_train = np.append(y_train, [values['action']])
# Let's ask for input
# print ("Enter 1 for JUMP and 0 for DO_NOTHING")
# action = int(input())
# The prediction from neural network
prediction = model.predict_classes(np.array([[values['closest_enemy']]])/really_huge_number)
return prediction
def gameover(self, score):
global games_count
global x_train
global y_train
global model
games_count += 1
# Printing x_train and y_train
print(x_train)
print(y_train)
if games_count is not 0 and games_count % train_frequency is 0:
# Before training, let's make the y_train array categorical
y_train_cat = to_categorical(y_train, num_classes = 2)
# Let's train the network
model.fit(x_train, y_train_cat, epochs = 50, verbose=1, shuffle=1)
# Reset x_train and y_train
x_train = np.array([])
y_train = np.array([])
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, games_count)
if __name__ == '__main__':
w = Wrapper()
你现在可以运行代码,但你会发现我们的神经网络工作方式存在一些缺陷。它总是在跳跃。在一开始这是完全随机的行为,每个预测都是跳跃这意味着神经网络永远不会学会什么,我们需要在代码中添加一些随机性。
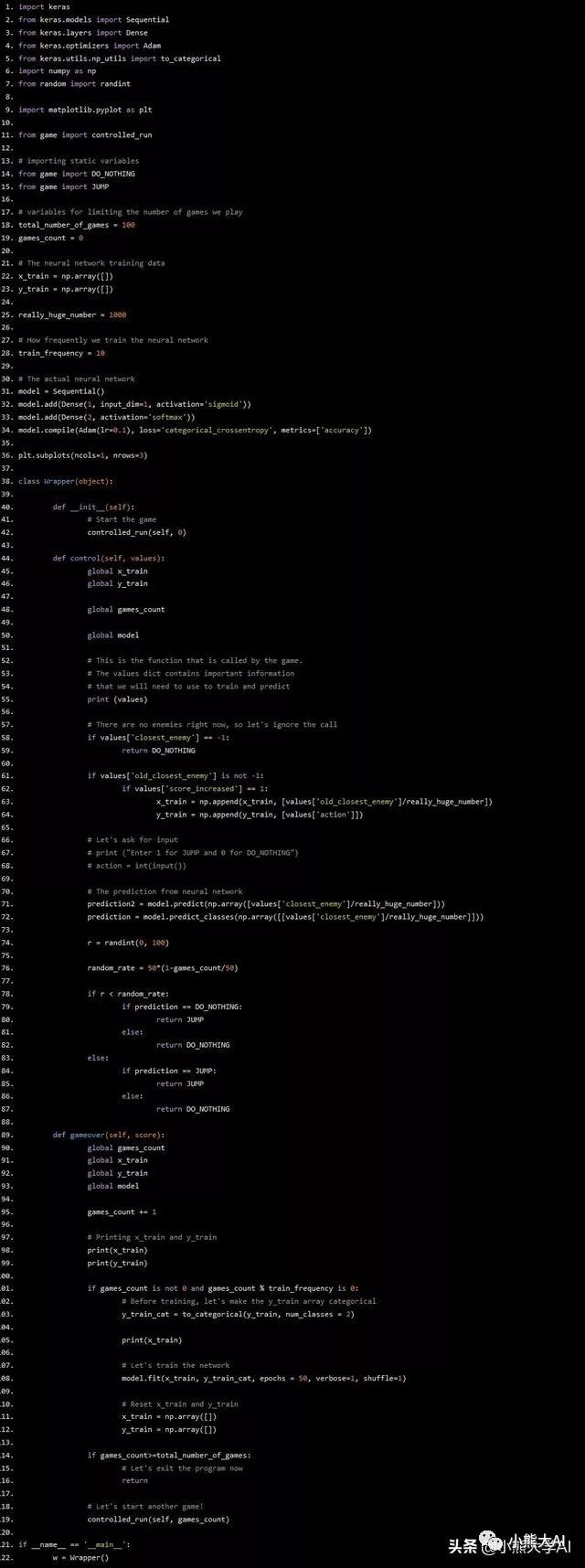
将随机性添加到神经网络
你可以按照你想要的任何方式做到,但我的一般想法是,随机性应该是巨大的,然后慢慢减少。我开始尝试一些数学函数来做到这一点,我没有花很多时间在它上面。我只是用一些二次函数和线性函数开做这个实验,但我发现最好的是一个非常简单的线性函数。
y = 50(1-x / 50)
这里,y是所采取的动作与神经网络预测相反的概率,x是运行计数器。随着run_counter的增加,随机率下降并最终在x = 50时或当我们进入第50局时达到0。
代码如下所示:
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
import numpy as np
from random import randint
import matplotlib.pyplot as plt
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 100
games_count = 0
# The neural network training data
x_train = np.array([])
y_train = np.array([])
really_huge_number = 1000
# How frequently we train the neural network
train_frequency = 10
# The actual neural network
model = Sequential()
model.add(Dense(1, input_dim=1, activation='sigmoid'))
model.add(Dense(2, activation='softmax'))
model.compile(Adam(lr=0.1), loss='categorical_crossentropy', metrics=['accuracy'])
plt.subplots(ncols=1, nrows=3)
class Wrapper(object):
def __init__(self):
# Start the game
controlled_run(self, 0)
def control(self, values):
global x_train
global y_train
global games_count
global model
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# There are no enemies right now, so let's ignore the call
if values['closest_enemy'] == -1:
return DO_NOTHING
if values['old_closest_enemy'] is not -1:
if values['score_increased'] == 1:
x_train = np.append(x_train, [values['old_closest_enemy']/really_huge_number])
y_train = np.append(y_train, [values['action']])
# Let's ask for input
# print ("Enter 1 for JUMP and 0 for DO_NOTHING")
# action = int(input())
# The prediction from neural network
prediction2 = model.predict(np.array([values['closest_enemy']/really_huge_number]))
prediction = model.predict_classes(np.array([[values['closest_enemy']/really_huge_number]]))
r = randint(0, 100)
random_rate = 50*(1-games_count/50)
if r < random_rate:
if prediction == DO_NOTHING:
return JUMP
else:
return DO_NOTHING
else:
if prediction == JUMP:
return JUMP
else:
return DO_NOTHING
def gameover(self, score):
global games_count
global x_train
global y_train
global model
games_count += 1
# Printing x_train and y_train
print(x_train)
print(y_train)
if games_count is not 0 and games_count % train_frequency is 0:
# Before training, let's make the y_train array categorical
y_train_cat = to_categorical(y_train, num_classes = 2)
print(x_train)
# Let's train the network
model.fit(x_train, y_train_cat, epochs = 50, verbose=1, shuffle=1)
# Reset x_train and y_train
x_train = np.array([])
y_train = np.array([])
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, games_count)
if __name__ == '__main__':
w = Wrapper()
运行上面的代码,你可以看到你的神经网络学习的情况。(在开始时按几次W来加快速度)
第四部分让神经网络学会玩游戏
我们几乎完成了我们的程序。神经网络运行得非常好,剩下要做的就是可视化神经网络。
我们将使用matplotlib来实现这一点。Matplotlib是一个非常有名的python库,它可以帮助绘制图形。
运行pip3 install matplotlib来安装matplotlib库。
我们将绘制三件事情:
每场比赛的得分
我们的数据
每10场比赛的平均得分
让我们首先添加每局比赛的得分图表。
我将在Wrapper类中创建一个静态方法并使用全局数组,现在,这可能不是编写代码的最佳时机,但是对于我们这个相对较小的示例,它是可行的。
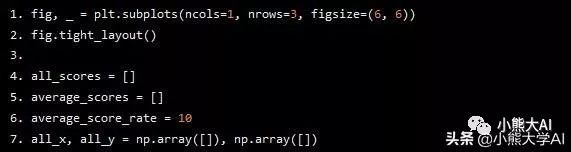
我定义的变量如下所示:
fig, _ = plt.subplots(ncols=1, nrows=3, figsize=(6, 6))
fig.tight_layout()
all_scores = []
average_scores = []
average_score_rate = 10
all_x, all_y = np.array([]), np.array([])
形象化的方法如下:
@staticmethod
def visualize():
global all_x
global all_y
global average_scores
global all_scores
global x_train
global y_train
plt.subplot(3, 1, 1)
x = np.linspace(1, len(all_scores), len(all_scores))
plt.plot(x, all_scores, 'o-', color = 'r')
plt.xlabel("Games")
plt.ylabel("Score")
plt.title("Score per game")
plt.subplot(3, 1, 2)
plt.scatter(x_train[y_train==0], y_train[y_train==0], color='r', label='Stay still')
plt.scatter(x_train[y_train==1], y_train[y_train==1], color='b', label='Jump')
plt.xlabel('Distance from the nearest enemy')
plt.title('Training data')
plt.subplot(3, 1, 3)
x2 = np.linspace(1, len(average_scores), len(average_scores))
plt.plot(x2, average_scores, 'o-', color = 'b')
plt.xlabel("Games")
plt.ylabel("Score")
plt.title("Average scores per 10 games")
plt.pause(0.001)
最后,在gameover函数和其他一些地方做了一些小修改,最终的代码如下所示:
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
import numpy as np
from random import randint
import matplotlib.pyplot as plt
from game import controlled_run
# importing static variables
from game import DO_NOTHING
from game import JUMP
# variables for limiting the number of games we play
total_number_of_games = 100
games_count = 0
# The neural network training data
x_train = np.array([])
y_train = np.array([])
really_huge_number = 1000
# How frequently we train the neural network
train_frequency = 10
# The actual neural network
model = Sequential()
model.add(Dense(1, input_dim=1, activation='sigmoid'))
model.add(Dense(2, activation='softmax'))
model.compile(Adam(lr=0.1), loss='categorical_crossentropy', metrics=['accuracy'])
fig, _ = plt.subplots(ncols=1, nrows=3, figsize=(6, 6))
fig.tight_layout()
all_scores = []
average_scores = []
average_score_rate = 10
all_x, all_y = np.array([]), np.array([])
class Wrapper(object):
def __init__(self):
# Start the game
controlled_run(self, 0)
@staticmethod
def visualize():
global all_x
global all_y
global average_scores
global all_scores
global x_train
global y_train
plt.subplot(3, 1, 1)
x = np.linspace(1, len(all_scores), len(all_scores))
plt.plot(x, all_scores, 'o-', color = 'r')
plt.xlabel("Games")
plt.ylabel("Score")
plt.title("Score per game")
plt.subplot(3, 1, 2)
plt.scatter(x_train[y_train==0], y_train[y_train==0], color='r', label='Stay still')
plt.scatter(x_train[y_train==1], y_train[y_train==1], color='b', label='Jump')
plt.xlabel('Distance from the nearest enemy')
plt.title('Training data')
plt.subplot(3, 1, 3)
x2 = np.linspace(1, len(average_scores), len(average_scores))
plt.plot(x2, average_scores, 'o-', color = 'b')
plt.xlabel("Games")
plt.ylabel("Score")
plt.title("Average scores per 10 games")
plt.pause(0.001)
def control(self, values):
global x_train
global y_train
global games_count
global model
# This is the function that is called by the game.
# The values dict contains important information
# that we will need to use to train and predict
print (values)
# There are no enemies right now, so let's ignore the call
if values['closest_enemy'] == -1:
return DO_NOTHING
if values['old_closest_enemy'] is not -1:
if values['score_increased'] == 1:
x_train = np.append(x_train, [values['old_closest_enemy']/really_huge_number])
y_train = np.append(y_train, [values['action']])
# Let's ask for input
# print ("Enter 1 for JUMP and 0 for DO_NOTHING")
# action = int(input())
# The prediction from neural network
prediction2 = model.predict(np.array([values['closest_enemy']/really_huge_number]))
prediction = model.predict_classes(np.array([[values['closest_enemy']/really_huge_number]]))
r = randint(0, 100)
random_rate = 50*(1-games_count/50)
if r < random_rate:
if prediction == DO_NOTHING:
return JUMP
else:
return DO_NOTHING
else:
if prediction == JUMP:
return JUMP
else:
return DO_NOTHING
def gameover(self, score):
global games_count
global x_train
global y_train
global model
global all_x
global all_y
global all_scores
global average_scores
global average_score_rate
games_count += 1
# Printing x_train and y_train
print(x_train)
print(y_train)
all_x = np.append(all_x, x_train)
all_y = np.append(all_y, y_train)
all_scores.append(score)
Wrapper.visualize()
if games_count is not 0 and games_count % average_score_rate is 0:
average_score = sum(all_scores)/len(all_scores)
average_scores.append(average_score)
if games_count is not 0 and games_count % train_frequency is 0:
# Before training, let's make the y_train array categorical
y_train_cat = to_categorical(y_train, num_classes = 2)
print(x_train)
# Let's train the network
model.fit(x_train, y_train_cat, epochs = 50, verbose=1, shuffle=1)
# Reset x_train and y_train
x_train = np.array([])
y_train = np.array([])
if games_count>=total_number_of_games:
# Let's exit the program now
return
# Let's start another game!
controlled_run(self, games_count)
if __name__ == '__main__':
w = Wrapper()
你可以运行代码,你可以看到你的神经网络学会玩这个游戏并且玩得越来越好。最终,神经网络变得如此之好以至于它似乎永远不会出错。
结论
你已经学会了如何使用Keras来制作一个进行游戏的神经网络,里面的许多参数可以进行各自的修改,可以试验不同的方式来制作一个更适合于自己的神经网络,以至于可以运用到更多的地方。
文中提到的PyGame、游戏或者全部代码可以直接私信我,感谢您的阅读!可以关注我的飞聊来与我进行互动!
以上是关于建立一个玩游戏的深度学习神经网络的主要内容,如果未能解决你的问题,请参考以下文章