深度学习之Keras检测恶意流量
Posted FreeBuf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之Keras检测恶意流量相关的知识,希望对你有一定的参考价值。
Keras介绍
Keras是由 Python 编写的神经网络库,专注于深度学习,运行在 TensorFlow 或 Theano 之上。TensorFlow和Theano是当前比较流行的两大深度学习库,但是对初学者来说相对有些复杂。Keras 使用简单,结构清晰,底层计算平台可基于 TensorFlow 或 Theano 之上,功能强大。Keras 可运行于 Python 2.7 或 3.5 环境,完美结合于 GPU 和 CPU,基于 MIT license 发布。Keras 由 Google 工程师François Chollet开发和维护。
安全能力&感知攻击
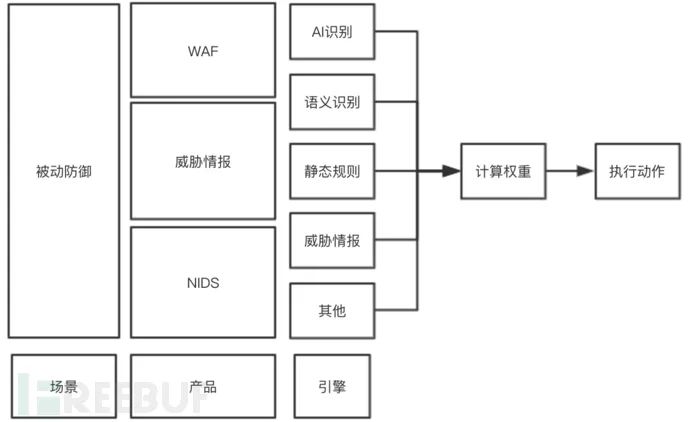
如何监控感知一个安全的应用边界,提升边界的安全感知能力尤为重要,那么常见七层流量感知能力又有哪些?
静态规则检测方式,来一条恶意流量使用规则进行命中匹配,这种方式见效快但也遗留下一些问题,举例来说,我们每年都会在类似 WAF、NIDS 上增加大量的静态规则来识别恶意攻击,当检测规则达到一定数量后,后续新来的安全运营同学回溯每条规则有效性带来巨大成本、规则维护的不好同样也就暴露出了安全风险各种被绕过的攻击未被安全工程师有效识别、规则数量和检测效果上的冗余也降低了检测效率、海量的攻击误报又让安全运营同学头大,想想一下每天你上班看到好几十页的攻击告警等待确认时的表情 凸 (艹皿艹) 凸。
如何使用多引擎的方式对数据交叉判断,综合权重计算形成报告,提升安全运营通过对七层恶意流量的感知能力同时攻击降低漏报率,其中是有很多种引擎或方案可以考虑的,比如最近几年流行的语义识别、AI 识别等等,本文主要说一下通过其中一种 AI 方式进行补充交叉识别恶意攻击。
常见攻击&XSS
在 Web 漏洞中常见的数量最多的漏洞应该是 XSS 了,XSS 跨站脚本 (Cross Site Script),在 Web 页面中,导致攻击者可以在 Web 页面中插入恶意 javascript 代码 (也包括 VBScript 和 ActionScript 代码等),用户浏览此页面时,会执行这些恶意代码,从而使用户受到攻击。
有的安全同学可能非常不屑,认为这是垃圾洞有些 src 确实也这么认为的看到 xss 直接忽略,说 xss 垃圾的理由很多,比如什么现在都上 https、http-only。你是打不到我的核心 Cookies 的一样没用,其实想想笔者也在刚入行的时候在某 SRC 日夜审洞,一边审核一边骂这些都是垃圾洞没鸟用。等到笔者真正在进行渗透的时候发现一个垃圾 XSS 洞也可以有很多种高级玩法,比如可以用 XSS 嗅探内网,用 XSS 获取 redis-shell、struts-shell、后渗透等。
实现思路
用神经网络搭建一个 XSS 攻击感知器,一般我们说达到 3 层的神经网络才称为深度神经网络,而组成神经网络的就是感知器,本次使用输入的 XSSplayload 预测使用二分类的方式判断是否为 xss。
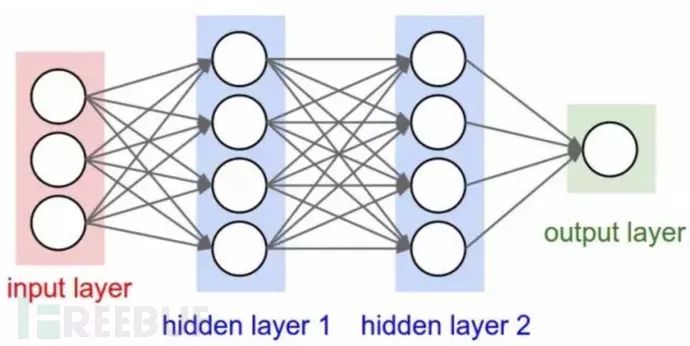
进入正文,使用 AI 模型达到的效果,测试结果在测试集与验证集上准确率和召回率都达到 95% 以上,预测效果:
恶意流量:/examples/jsp/jsp2/el/search=<SCript>alert('xss')</scRIpt>恶意流量:/iajtej82.dll?<img src='javascript:alert(cross_site_scripting.nasl);'>恶意流量:/examples/jsp/jsp2/el/search=<prompt>alert(/1/)</prompt>恶意流量:/cgi-bin/index.php?gadget=glossary&action=viewterm&term=<script>alert('jaws_xss.nasl');</script>恶意流量:/fmnveedu.htm?a=<marquee loop=1 width=0 onfinish=confirm(1)>0</marquee>
数据集结构,准备了两个文本文档,黑白样本各 10+万,其中恶意样本内容如下,每行代表一个 xss 的 playload。
<script>cou006efiru006d`1`</script> <ScRiPt>cou006efiru006d`1`</ScRiPt> <img src=x onerror=cou006efiru006d`1`> <svg/onload=cou006efiru006d`1`> <iframe/src=javascript:cou006efiru006d%28 1%29> <h1 onclick=cou006efiru006d(1)>Clickme</h1> <a href=javascript:prompt%28 1%29>Clickme</a> <a href="javascript:cou006efiru006d%28 1%29">Clickme</a> <textarea autofocus onfocus=cou006efiru006d(1)> <details/ontoggle=cou006efiru006d`1`>clickmeonchrome <p/id=1%0Aonmousemove%0A=%0Aconfirm`1`>hoveme <img/src=x%0Aonerror=prompt`1`> <iframe srcdoc="<img src=x:x onerror=alert(1)>"> "><h1/ondrag=cou006efiru006d`1`)>DragMe</h1>
对于文本类的特征工程有很多实现的方式这里我们用最简单的 ord 函数将所有字符转换为 ASCII 字符进行向量化python ord 作用,对基础字符进行常规化操作转小写、去标点、将字符串拆分,这里的拆分其实并不需要拆分那么多,只要最大情况下可以保留特征即可。
def handle(self, payload):payload = urllib.parse.unquote(payload.lower().strip())# 数字泛化为"0"payload = re.sub("d+", '0', payload)# 分词r = '''(?x)[w.]+?(|)|"w+?"|'w+?'|http://w|</w+>|<w+>|<w+|w+=|>|[w.]+''' """原始链接/0_0/e/data/ecmseditor/infoeditor/epage/tranflash.php?a=0"><script>alert(/0/)</script>< 1 分词链接['0_0/e/data'/ecmseditor/infoeditor/epage/tranflash.php?', 'a=', '0', '>', '<script>', 'alert(', '0', ')', '</script>']"""nltks = nltk.regexp_tokenize(payload, r)temp = []for item in nltks:if len(item) <= 3 or len(item) >= 10:continueelse:for char in item:temp.append(ord(char))return temp
正常样本集参考,没有条件的同学将 URL 请求参数里的 key-value 里的 value 都提取出来每行一个放到文本里进行训练也可以,因为真正在预测的时候我们都是直接将 URL 中的 value 进行提取预测。
b1498592370545=1&v=13111002&COLLCC=3442798258&t=check&rec=stratus&etyp=connect&zone=zibo5_cnc&url=119.188.143.32&errCnt=327&uid=d0a47beafc75e1549c7fdc23530fd959&uif=CNC|BeiJing-114.251.186.13&tvid=7706069409&defi=2&dlod=1&darea=1&ppapi=false&trkip=119.188.143.32&trkon=0&ver=3.1.0.15&dur=36431783 cn_600022,cn_600516,cn_000002,cn_600519,cn_000651,cn_600887,cn_002415,cn_601288,cn_000333,_=1498179095094&list=sh600030 q=marketStat,stdunixtime&_=1498584939540_=1498584888937/&list=FU1804,FU0,FU1707,FU1708,FU1709,FU1710,FU1711,FU1712callback=_ntes_quote_callback54388229_=1498552987540&list=hf_OIL
首先我们获取到所有的正常样本和恶意样本,将正常样本标记为』0′,将恶意样本标记为』1′,将数据集拼接后按 30%,70&进行分割,其中 30% 作测试集。这里因为 keras 限定 input_shape 输入必须是固定长度,所以将 xss 的 playload 最大特征限制到最大 50 纬,未达到 50 维的用 0 补齐,超过 50 维度的截断,label 用 keras 自带的 One-Hot Encoding 编码实现一个 shape = (len(样本数量),2),
def run(self):gx = []bx = []gy = []by = []for data in c.load(goodXss):data = c.handle(data)if len(data) == 0:continueelse:gx.append(data)gy.append(0)for data in c.load(badXss):data = c.handle(data)if len(data) == 0:continueelse:bx.append(data)by.append(1)x_train, x_test, y_train, y_test = train_test_split(gx + bx, gy + by, test_size=0.3, random_state=100)y_train = keras.utils.to_categorical(y_train, num_classes=2)y_test = keras.utils.to_categorical(y_test, num_classes=2)x_train = pad_sequences(x_train, maxlen=50, value=0.)x_test = pad_sequences(x_test, maxlen=50, value=0.)c.train(x_train, x_test, y_train, y_test)
训练方法由于我们使用的是一个二分类问题,损失函数用』categorical_crossentropy』,考虑到我们会训练很多次,所以建议将 mode_name 按时间来命名单独放到一个文件夹里,因为 keras 是底层调用的 tensordlow,所以在 callbacks 上回调一下 tensorboard,这样我们后续在用 tensorboard 进行查看的时候可以很快的进行模型区分,设置好梯度步长就可以准备训练了。
先了解什么是卷积神经网络
卷积神经网络(CNN),是一种前馈神经网络,对于大型图像处理和文本处类处理都有出色表现。CNN 最主要的两个概念,卷积层 (convolutional layer) 和池化层 (pooling layer)
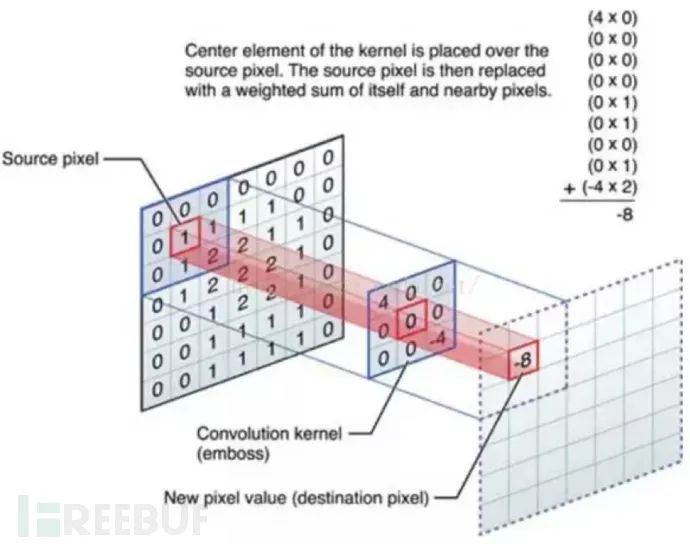
卷积层提取图像文本的特征,并且卷积核的权重是可以学习的,在高层神经网络中,卷积操作能突破传统滤波器的限制,根据目标函数提取出想要的特征
池化层可以降低网络的复杂度,简单来说,卷积层用一个窗口去对输入层做卷积操作,池化层也用一个窗口去对卷积层做池化操作,常见的池化层方式包括最大池化层(max pooling)和平均池(average pooling)。
最大池化 (max pooling),在选中区域中找最大的值作为采样后的值。
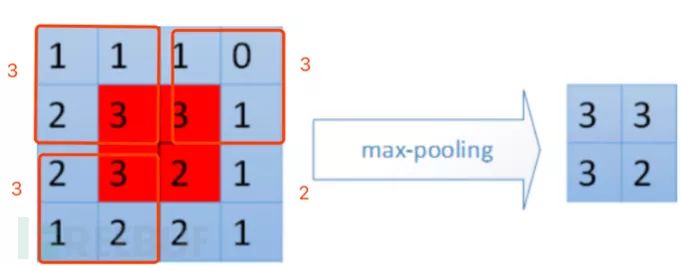
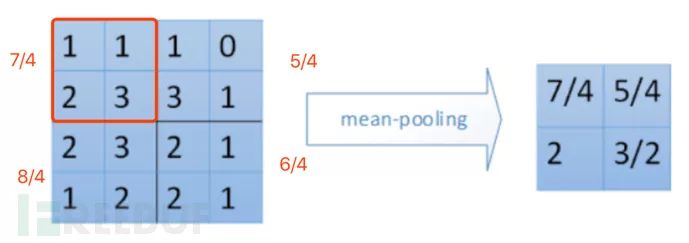
平均值池化 (mean pooling),把选中的区域中的平均值作为采样后的值。
def train(self, x_train, x_test, y_train, y_test):model = self.NnModel()OPTIMIZER = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)model.compile(loss="categorical_crossentropy", optimizer=OPTIMIZER,metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])model.summary()model_name = "xss-cnn-32x2-{}".format(int(time.time()))tensorboard = TensorBoard(log_dir='./'.format(model_name))model.fit(x_train, y_train, batch_size=128, epochs=3, callbacks=[tensorboard])train_score = model.evaluate(x_train, y_train, verbose=0)print('Train loss:', train_score[0])print('Train accuracy:', 100 * train_score[1])test_score = model.evaluate(x_test, y_test, verbose=0)print('Test loss:', test_score[0])print('Test accuracy:', 100 * test_score[1])model.save(model_name)
构建模型层为方便演示,这里使用的是 Embedding 做词向量化三层卷积,输入特征纬度为(None,50,使用 keras 自带的 BatchNormalization 进行标准化。
def CnnModel(self, input_shape):model = Sequential()model.add(Embedding(input_dim=65025,output_dim=50,input_length=50))model.add(BatchNormalization())model.add(Conv1D(filters=32, kernel_size=3, strides=1, activation='relu'))model.add(BatchNormalization())model.add(Conv1D(filters=64, kernel_size=3, strides=1, activation='relu'))model.add(BatchNormalization())model.add(Conv1D(filters=128, kernel_size=3, strides=1, activation='relu'))model.add(MaxPooling1D(pool_size=2))model.add(Flatten())model.add(Dense(2, activation='softmax'))return model
预测
预测模块之间读取模型,对输入 playload 进行 padding 即可实现预测
def perdict(self, modelName, playload):model = keras.models.load_model(modelName)pd = self.handle(playload)playloads = pad_sequences([pd], maxlen=50, value=0.)result = model.predict_classes(playloads, batch_size=1)print("XSS==>" if result == [1] else "None==>", playload)if __name__ == '__main__':badXss = "./badxss.txt"goodXss = "./goodxss.txt"testXss = "./test-xss.txt"num_classes = 2c = CNNXSS()c.run()list = [x.strip().lower() for x in open(testXss).readlines()] for k, v in enumerate(list): c.perdict('xss-cnn-32x2-1577157928.h5', v.strip())
后话
为什么使用神经网络不使用机器学习的方式,因为笔者很懒不想做太多特征工程 ( ̄3 ̄)a 本文用最简单的 CNN 神经网络方式来实现检测 XSS,同样的该模型不能直接拿来使用,模型层需要考虑使用更多的卷积层池化层进防止过拟合,特征工程需要重点考虑 get、post、请求参数的特征特异性互斥性,词向量间上下文关系(Embedding)等。相信在做好特征工程和模型后验证效果会继续提高,况且感受到类似结合 AI 的商业安全产品在市面上也渐渐的在增多,建设甲方安全的思路都在逐步在进行统一化,如何拿出新的产出弥补传统 web 安全的不足,也算是一种趋势吧。

FreeBuf+ FreeBuf+小程序:把安全装进口袋 Mini Program
精彩推荐
以上是关于深度学习之Keras检测恶意流量的主要内容,如果未能解决你的问题,请参考以下文章