深度学习编译器综述
Posted 宇航智控
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习编译器综述相关的知识,希望对你有一定的参考价值。

深度学习编译器综述

深度学习技术的发展对各个科学领域产生了深远的影响,现有流行的DL编程框架有各有优劣,在支持新兴的DL模型时,如何将深度学习模型快速便捷地部署到各种硬件平台上,这一需求推动了深度学习编译技术的发展。最近,北航学者撰写了一篇关于目前深度学习编译器的综述论文《The Deep Learning Compiler: A Comprehensive Survey》,参考了107篇参考文献,从各个方面对现有的DL编译器进行了全方面的比较,并详细分析了多级IR设计和优化技术,最后指出了研究发展方向。
在不同DL硬件上部署各种深度学习模型的困难推动了DL编译器的研究和开发。业界已经提出了几种DL编译器,如Tensorflow XLA和TVM。DL编译器以不同DL框架中描述的DL模型作为输入,为不同DL硬件生成优化的代码作为输出。但现有综述中没有一个全面分析DL编译器的设计特征。本文通过以下方式对现有DL编译器进行了全面说明,包括详细剖析常用设计,重点是面向DL的多级IR,以及前端/后端优化。此外,还对多级IR设计和编译器优化技术进行了详细分析。最后,提出了一些DL编译器潜在的研究方向和建议。
关键词:
神经网络,深度学习(DL),编译器,中间表示(IR),优化
1
引言
深度学习的发展已对各个科学领域产生了深远的影响。现有流行的DL编程框架有各有优缺点,在支持新兴的DL模型时,互操作性对于减少冗余的工程工作尤为重要。本文将编译器设计分解为前端,多级IR和后端,对现有DL编译器进行全面描述,特别着重于IR设计和优化方法。本文主要做出了以下贡献:
从硬件支持,DL框架支持,代码生成和优化等各个方面对现有DL编译器进行了全面比较,可以用作为用户选择合适的DL编译器的指南。
剖析了现有DL编译器的一般设计,并详细分析了多级IR设计和编译器优化技术,例如数据流级优化,硬件固有映射,内存延迟隐藏和并行化。
为DL编译器的未来发展提供了一些见解,包括自动调整、多面体编译器、量化、可微分编程和隐私保护,希望以此来促进DL编译器社区中的研究。
本文的其余部分安排如下。第2节介绍了DL编译器的背景知识,包括DL框架,DL芯片以及特定硬件(FPGA)的DL编译器。第3节详细介绍了现有DL编译器之间的比较。第4节介绍DL编译器的一般设计,重点介绍IR和前端/后端优化。第五节总结了论文并强调了未来的发展方向。
2
背景
2.1深度学习框架
在本小节中提供了流行的DL框架的概述。讨论可能并不详尽,但旨在为DL从业人员提供指导。图1展示了DL框架的概况和ONNX支持的框架。本文着重于DL编译器的研究工作,这些编译器提供了更通用的方法来有效地在各种硬件上执行各种DL模型。

Fig. 1. DL framework landscape: 1)Currently popular DL frameworks; 2)Historical DL frameworks; 3)ONNX supported frameworks
2.2深度学习硬件
1)通用硬件-用于DL模型的最具代表性的通用硬件是GPU,它可通过多核体系结构实现高度并行性。
2)专用硬件-专用硬件完全定制用于DL计算,以将性能和能效提高到极致。DL应用程序和算法的迅速扩展促使许多初创公司开发专用的DL硬件。最知名的专用DL硬件是Google的TPU系列。
3)神经形态硬件-神经形态芯片使用电子技术来模拟生物大脑。这种代表产品是IBM的TrueNorth和英特尔的Loihi。
2.3特定硬件的DL编译器
现场可编程门阵列(FPGA)是可重编程集成电路,其中包含一组可编程逻辑块。程序员可以在制造后对其进行配置。针对FPGA的特定硬件DL编译器将DL模型或领域特定语言(DSL)作为输入,进行领域特定(关于FPGA和DL)的优化和映射,然后生成HLS或Verilog/VHDL,最后生成比特流。根据基于FPGA的加速器的生成架构,它们可以分为两类:处理器架构和流传输架构[91]。本文重点关注可应用于除绑定到FPGA以外的更广泛DL硬件的通用DL编译技术。
3
DL编译器的比较
在本节中,我们比较了几种流行的DL编译器,包括TVM,TC,Glow,Graph,PlaidML和XLA。表1从各个方面显示了不同DL编译器的详细比较,其中“✓”表示支持,“×”表示不支持,而“-”表示正在开发。注意,这里使用TVM表示VTA,Relay和autoTVM的工作。另外,PlaidML与nGraph紧密结合,因此在比较期间将它们一起考虑。此外,对于DL编译器的性能比较,读者可以参考。
Table 1. The detailed comparison of popular DL compilers.
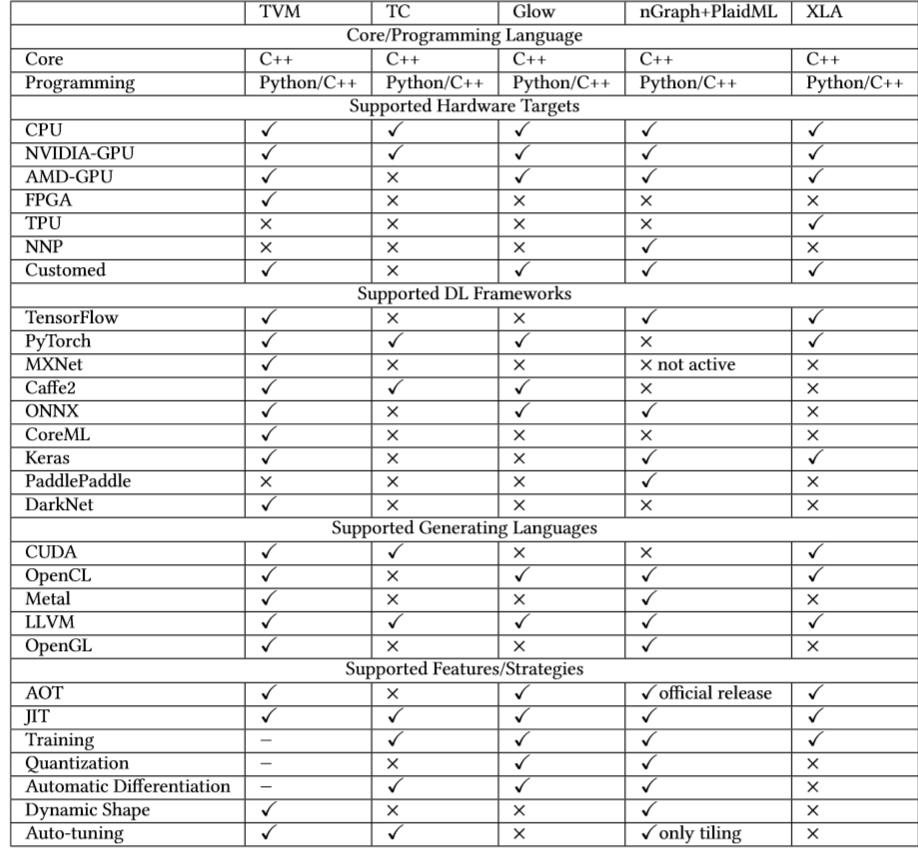
表1从5个方面对比流行DL编译器的特点:
(1)核心/编程语言;
(2)支持的硬件平台;
(3)支持的DL框架;
(4)支持的生成语言;
(5)支持的功能/策略;
4
DL编译器的通用设计
4.1设计概述
DL编译器的通用设计主要包括两部分:编译器前端和编译器后端,如图2所示。中间表示(IR)分布在前端和后端。通常,IR是程序的抽象,用于程序优化。具体而言,DL模型在DL编译器中转换为多级IR,其中高级别IR位于前端,低级IR位于后端。表2列出了不同DL编译器中的IR实现。基于高级IR,编译器前端负责与硬件无关的转换和优化。基于低级IR,编译器后端负责特定硬件的优化、代码生成和编译。
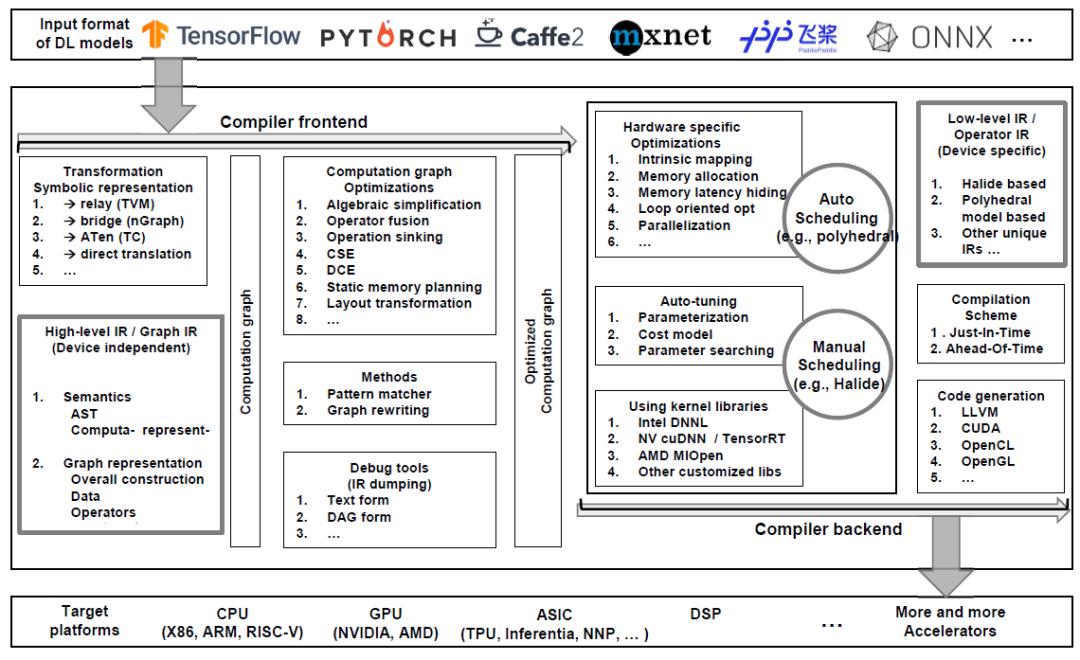
Fig. 2. The overview of commonly adopted design of DL compilers.
4.2高级IR
为了克服传统编译器采用的IR限制了DL模型中使用的复杂计算的表达的问题,现有的DL编译器利用图IR和经过特殊设计的数据结构来进行有效的代码优化。
4.3低级IR
与高级IR相比,低级IR以更细粒度的表示形式描述了DL模型的计算,该模型通过提供接口来调整计算和内存访问,从而实现了与目标有关的优化。它还允许开发人员在编译器后端使用成熟的第三方工具链,例如Halide [77]和多面模型[13]。将低级IR可分为三类:基于Halide的IR,基于多面体模型的IR和其他独特的IR。
4.4前端优化
构造计算图后,前端将应用图级优化。因为图提供了计算的全局概述,所以更容易在图级发现和执行许多优化。这些优化仅适用于计算图,而不适用于后端的实现。因此,它们与硬件无关,这意味着可以将计算图优化应用于各种后端目标。
前端优化分为三类:1)节点级优化(如零维张量消除、Nop消除),2)块级优化(如代数简化、融合),以及3)数据流级优化(如CSE、DCE)。
前端是DL编译器中最重要的组件之一,负责从DL模型到高级IR(即计算图)的转换以及基于高级IR的独立于硬件的优化。尽管在不通过在DL编译器上前端的实现在高级IR的数据表示形式和运算符定义上有所不同,但与硬件无关的优化在节点级别,块级别和数据流级别这三个级别上相似。
4.5后端优化
4.5.1特定硬件的优化。
4.5.2自动调整。
4.5.3优化的内核库。
5
结论和未来方向
本综述对现有的DL编译器进行了全面分析。首先从各方面对现有的DL编译器进行了全面的比较,可以作为用户选择适合其方案的DL编译器的指南。然后深入研究现有DL编译器采用的通用设计,包括多级IR,前端和后端。文章详细介绍每个组件的设计理念和参考实现,重点针对DL编译器的独特IR和优化。在最后总结中,重点介绍了DL编译器的未来发展方向,希望为研究人员提供启示,主要包括一下几个方面内容。
动态形状和控制流程;
先进的自动调整;
多面体模型;
子图分区;
量化;
统一优化;
可微分编程;
图神经网络(GNN);
隐私保护。
附原文链接:
https://arxiv.org/abs/2002.03794v1
附原文链接:
https://arxiv.org/abs/2002.03794v1
end
以上是关于深度学习编译器综述的主要内容,如果未能解决你的问题,请参考以下文章