一篇关于深度学习编译器架构的综述论文
Posted CVer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇关于深度学习编译器架构的综述论文相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
https://zhuanlan.zhihu.com/p/139552817
本文已由原作者授权,不得擅自二次转载
arXiv上面看到的综述“The Deep Learning Compiler: A Comprehensive Survey”,2020年2月上传第一版,4月已经是第三版。

摘要:正是深度学习硬件上部署各种模型的困难推动了社区深度学习编译器的研究和开发。工业界和学术界已经提出了几种深度学习编译器,例如Tensorflow XLA和TVM。深度学习编译器将不同框架描述的深度学习模型为某个硬件平台生成优化的代码。但是,目前还都没有全面分析深度学习编译器这种独特设计架构。本文详细剖析常用的设计思想,对现有的深度学习编译器进行全面总结,重点是面向深度学习的多级中间表示(IR)以及前后端的优化。具体来说,作者从各个方面对现有编译器做全面比较,对多级IR的设计进行了详细分析,并介绍了常用的优化技术。最后,文章强调对今后编译器潜在研究方向的一些见解。基本上这是深度学习编译器设计体系结构(不是硬件方面)的第一个综述。
注:5年前在Intel曾经和哈佛大学教授H T Kung(孔祥重)合作一个GPU compiler项目。90年代孔教授在CMU的时候曾经提出著名的systolic array,谷歌推出的神经网络芯片TPU v1就是基于这种结构。我以前在学校读研究生(雷达信号处理)的时候也设计过SVD的systolic阵列实现方法。在Intel做的项目中,我带一个孔教授的博士生做intern,利用machine learning方法学习如何最优化矩阵乘法(分解),基于计算速度/功耗的测度。当时采用的方法,是延续了孔教授实验室的工作。同时,教授另外一个博士生在Intel其他组做intern,把这个方法用于开源Caffe代码Open CL实现的优化。作为本文共同作者的杨广文教授,是我当时在清华大学计算机系的同学。
大家知道有几种流行的深度学习框架,例如TensorFlow,PyTorch,MXNet和CNTK。尽管这些框架的优缺点还要取决于设计,互操作性可以减少重复的模型训练工作。 ONNX(The Open Neural Network Exchange)就是这个目的,它定义了表示深度学习模型的统一格式,以促进不同框架之间的模型转换。市面上已经有不少公司开发出各种深度学习硬件平台,比如互联网巨头Google TPU,Hisilicon NPU和Apple的Bonic,处理器供应商NVIDIA Turing和Intel NNP,服务提供商Amazon Inferentia和阿里巴巴的含光),甚至是创业公司的Cambricon和Graphcore。一般这些硬件可分为以下几类:1)具有软硬件协同设计的通用硬件;2)完全为深度学习模型定制的专用硬件;3)受生物脑科学启发的类神经硬件。举个例子,在通用硬件(CPU/GPU)添加特殊硬件组件以加速DL模型,如AVX512矢量单元和张量核。Google TPU之类的专用硬件,设计专用集成电路(例如矩阵乘法引擎和高带宽内存)将性能和功耗效率提升到了极致。在可预见的将来,深度学习硬件的设计将变得更加多样化。
由于硬件多样性,重要的工作就是如何将计算有效地映射。通用硬件对高度优化的线性代数库,例如BLAS库(MKL和cuBLAS)依赖比较多。以卷积运算为例,深度学习框架将卷积转换为矩阵乘法,然后在BLAS库中调用GEMM函数。此外,硬件供应商还发布了特别的优化库(例如MKL-DNN和cuDNN),包括正向和反向卷积、池化、规范化和激活等操作符。他们还开发了更高级的工具来进一步加快深度学习操作。例如,TensorRT支持图形优化(层融合)和基于大量优化GPU内核的低比特量化。专用硬件,则会提供类似的开发库。但是,过于依赖库无法有效利用深度学习芯片。
为解决这些依赖库和工具的缺点,减轻手动优化每个硬件运行模型的负担,深度学习社区诉诸于专门的编译器。已经有几种流行的编译器出现,例如TVM,Tensor Comprehension,Glow,nGraph和Tensorflow XLA(Accelerated Linear Algebra)。编译器将深度学习框架描述的模型在各种硬件平台上生成有效的代码实现,其完成的模型定义到特定代码实现的转换将针对模型规范和硬件体系结构高度优化。具体来说,它们结合了面向深度学习的优化,例如层融合和操作符融合,实现高效的代码生成。此外,现有的编译器还采用了来自通用编译器(例如LLVM)的成熟工具链,对各种硬件体系结构提供了更好的可移植性。与传统编译器类似,深度学习编译器也采用分层设计,包括前端、中间表示(IR)和后端。但是,这种编译器的独特之处在于多级IR和特定深度学习模型实现优化的设计。
如图是深度学习框架概况:1)当前流行的框架;2)历史框架;3)支持ONNX格式的框架。

The Open Neural Network Exchange(ONNX),定义了可扩展的计算图模型,可以将不同框架构建的计算图轻松转换为ONNX,这样在不同框架之间转换模型变得容易。ONNX已集成到PyTorch、MXNet和PaddlePaddle中。对于尚不直接支持的多个框架(例如TensorFlow和Keras),ONNX对它们添加了转换器。
下表是一些常用编译器的对比:
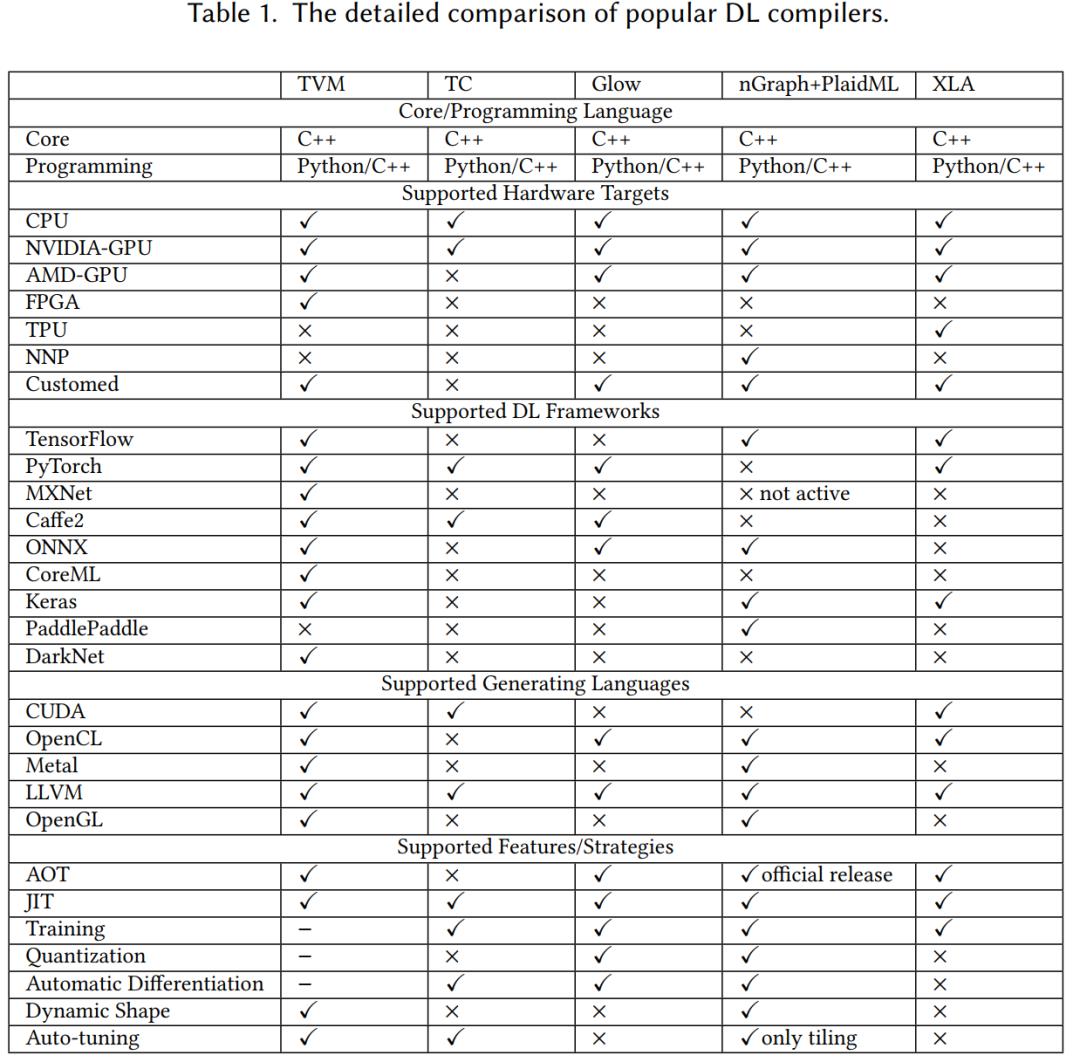
其中缩写:just-in-time compilation (JIT)和ahead-of-time compilation (AOT)
深度学习编译器普遍采用的设计架构如图所示:
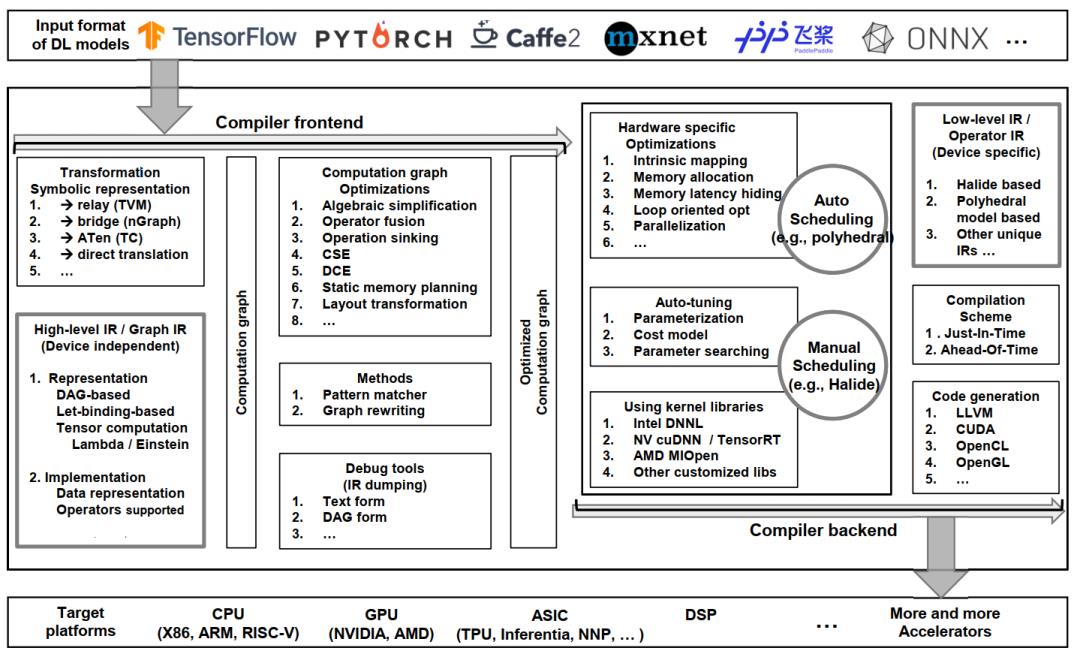
这类编译器的通用设计体系结构主要包含两部分:编译器前端和编译器后端。中间表示(IR)横贯前端和后端。通常IR是程序的抽象,用于程序优化。具体而言,深度学习模型在编译器中转换为多级IR,其中高级IR驻留在前端,而低级IR驻留在后端。基于高级IR,编译器前端负责独立于硬件的转换和优化。基于低级IR,编译器后端负责特定于硬件的优化、代码生成和编译。
注:关于硬件实现的编译器比较参考综述文章【101】,本文重点是设计架构的比较。
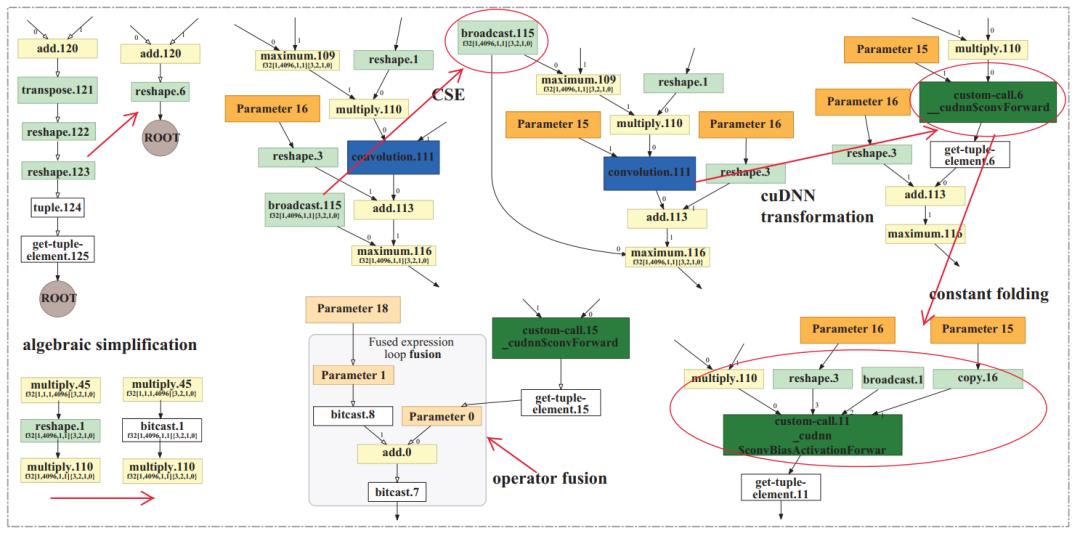
如图所示是前端优化的例子,Tensorflow XLA的computation graph optimization。
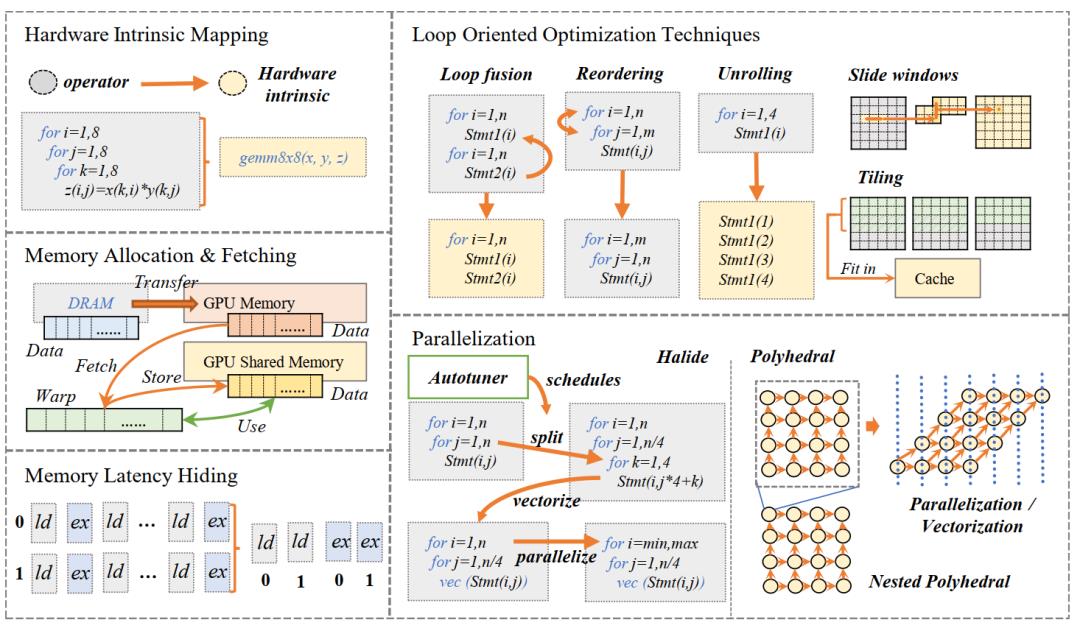
后端优化跟硬件有关,如图是特定硬件采用的优化方法归纳:
最后,文章给出一些前沿研究方向:
动态形状和前/后处理(Dynamic shape and pre/post processing)
高级自动调节(Advanced auto-tuning)
多面体模型(Polyhedral model)
子图分解(Subgraph partitioning)
量化
差分编程(Differentiable programming)
隐私保护
参考文献
【101】Y Xing, J Weng, Y Wang, L Sui, Y Shan, and Y Wang. “An In-depth Comparison of Compilers for Deep Neural Networks on Hardware”. IEEE International Conference on Embedded Software and Systems (ICESS). 2019.
论文下载
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1400+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

请给CVer一个在看!
以上是关于一篇关于深度学习编译器架构的综述论文的主要内容,如果未能解决你的问题,请参考以下文章