深度学习模型介绍AlexNetVGG--笔记
Posted 我和我的技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习模型介绍AlexNetVGG--笔记相关的知识,希望对你有一定的参考价值。
一.AlexNet:2012 年,Hinton及其学生 提出
1.使用ReLU 函数:如下图所示,达到25%的训练误差,使用ReLU函数比使用tanh函数(虚线)快六倍;(文中图片全部来自网络)
2.使用2个GPU(GTX 580 GPU )并行运算;
3.使用了局部归一化响应(Local Response Normalization);
4.利用重叠池化来降低过拟合,核大小为3×3,stride步长为2;
5.下面对该模型的整体结构进行介绍,下图为该模型的体系结构。
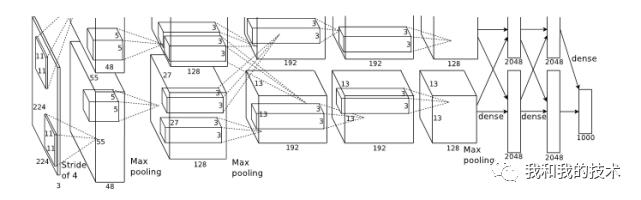
(1)总体结构共有8层,包括5个卷积层与3个全连接层。
最后一个全连接层输出1000维softmax,该softmax会产生1000类标签分布;
第2、4、5卷积层的核只与位于同一GPU上的前一层的核相连接;
第3卷积层的核与第2层的所有核映射相连;
全连接层的神经元与前一层的所有神经元相连接;
第1,2卷积层之后是响应归一化层;
最大池化层在响应归一化层和第5卷积层之后;
ReLU非线性应用在每个卷积层和全连接层的输出上;
(2)第1卷积层使用96个核对224 × 224 × 3的输入图像进行滤波,核大小为11 × 11 × 3,步长为4(核映射中相邻神经元感受野中心之间的距离);
第2卷积层使用第1卷积层的输出作为输入(响应归一化和池化),并使用256个核进行滤波,核大小为5 × 5 × 48;
第3,4,5卷积层互相连接,中间没有接入池化层或归一化层;
第3卷积层有384个核,核大小为3 × 3 × 256,与第2卷积层的输出(归一化,池化)相连;
第4卷积层有384个核,核大小为3 × 3 × 192;
第5卷积层有256个核,核大小为3 × 3 × 192;
每个全连接层有4096个神经元;
6. 减少过拟合
该神经网络结构有6000万参数,有2种解决过拟合的方法。
(1)增加数据集:
第一是通过图像变换和水平翻转实现:
训练时,从256×256图像上随机提取224×224图像块,在提取的图像块上进行训练;测试时,提取5个224 × 224的图像块(四个角上的图像块和中心的图像块)和它们的水平翻转(因此总共10个图像块)进行预测,然后对网络在10个图像块上的softmax层进行平均;
第二是对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%;
(2)Dropout:
通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束。
7.细节问题
利用随机梯度下降进行训练,batch size为128,动量为0.9,权重衰减为0.0005;
该模型利用均值为0,标准差为0.01的高斯分布对每一层的权重进行初始化;
在第2,4,5卷积层和全连接隐层将神经元偏置初始化为1,其他层神经元偏置初始化为0;
所有层使用相同的学习率,学习率初始值为0.01。
参考链接里有该模型相关代码,这里不再列出。
参考链接:
1.https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf;
2.https://www.jianshu.com/p/ea922866e3be;
3.https://baike.baidu.com/item/AlexNet/22689612?fr=aladdin;
二.VGG--2014年ILSVRC竞赛的第二名
1. VGG论文给出了一个重要结论:卷积神经网络的深度增加(16-19层)和小卷积核(3×3)的使用对网络的最终分类识别效果有很大的作用;
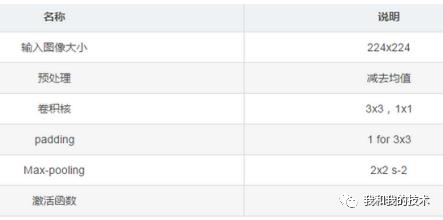
2. 网络结构如下图所示:
通过增加更多的卷积层来稳定地增加网络的深度,在所有层中都使用了非常小的(3×3)卷积滤波器。
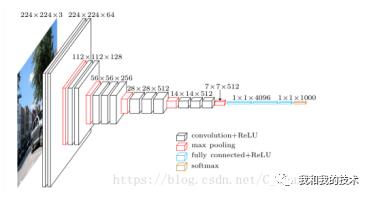
3*3卷积核作用:多个卷积核叠加,增加空间感受野,减少参数;
1*1卷积核作用:降维,增加非线性性。
3.没有使用AlexNet中的LRN,因为其在VGG网络中没有效果,且该操作会增加内存和计算;
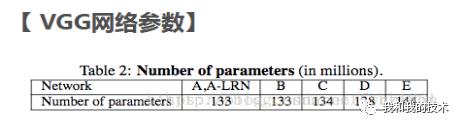
4.(1)下表1解释:从网络A中的11个权重层(8个conv和3个fc层)到网络E中的19个权重层(16个conv和3个fc层)。连接层的宽度(信道的数量)相当小,从第一层的64开始,然后在每个最大汇聚层之后增加2倍,直到达到512。
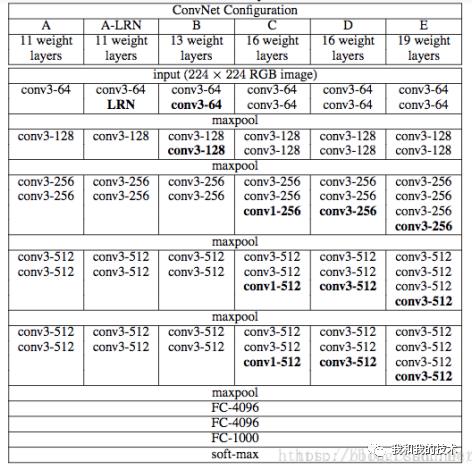
(2) 下表2解释:下表2展示了表1中每个配置的参数。
5.问答
问答1:为什么3个3x3的卷积可以代替7x7的卷积?
--3个3x3的卷积,使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性;
--减少参数个数。对于C个通道的卷积核,1个7x7卷积层需要72C2=49C2个参数, 3个3x3卷积的参数个数为3∗32C2=27C2,参数大大减少,计算量降低;
问答2: 1x1卷积核的作用?
--在不影响卷积层的接收场的情况下增加决策函数的非线性的方法;
--在相同维数(输入和输出通道数相同)的空间上的线性投影,但通过校正函数引入了额外的非线性;
问答3:网络深度对结果的影响?(同年google也独立发布了深度为22层的网络GoogleNet)
--VGG与GoogleNet模型都很深
--都采用了小卷积
--VGG只采用3x3,而GoogleNet采用1x1, 3x3, 5x5,模型更加复杂(模型开始采用了很大的卷积核,来降低后面卷机层的计算)
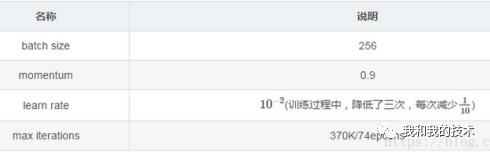
6.下表列出VGG模型的一些参数:batch size、动量、学习率、最大迭代次数;
7. 正则化方法:

说明:虽然模型的参数和深度相比AlexNet有了很大的增加,但是模型的训练迭代次数却要求更少,这是因为:a)正则化+小卷积核,b)特定层的预初始化。
8.初始化策略:
首先,随机初始化网络结构A(表1中的A,A的深度较浅);
利用A的网络参数,给其他模型进行初始化(初始化前4层卷积+全连接层,其他的层采用正态分布随机初始化,均值mean为0,方差var=10−2, 偏差biases为0),最后证明,即使随机初始化所有的层,模型也能训练的很好。
9.训练输入:
采用随机裁剪的方式,获取固定大小224x224的输入图像。并且采用了随机水平镜像和随机平移图像通道(不太明白如何实现?)来丰富数据。
10. 训练图像大小:
令S为图像的最小边,如果最小边S=224,则直接在图像上进行224x224区域随机裁剪,这时相当于裁剪后的图像能够几乎覆盖全部的图像信息;
如果最小边S>>224,那么做完224x224区域随机裁剪后,每张裁剪图,只能覆盖原图的一小部分内容。
注:因为训练数据的输入为224x224,从而图像的最小边S,不应该小于224
11. 数据生成方式:
首先对图像进行缩放变换,将图像的最小边缩放到S大小,然后
方法1: 在S=224和S=384的尺度下,对图像进行224x224区域随机裁剪
方法2: 令S随机的在[Smin,Smax][Smin,Smax]区间内值,缩放完图像后,再进行随机裁剪(其中Smin=256,Smax=512,Smin=256,Smax=512)
12. 预测方式:
作者考虑了两种预测方式:
方法1: multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均;
方法2: densely, 利用FCN的思想,将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积,这样最后可以得出一个预测的score map,再对结果求平均;
13. 实施细则:
利用数据并行性进行多GPU训练,将每一批训练图像分割成多个GPU批次,在每个GPU上并行处理。在计算GPU批处理梯度后,对它们进行平均,得到整个批处理的梯度。梯度计算在GPU上是同步的,因此与在单个GPU上进行训练时的结果完全相同。
14. 分类实验:
(1)数据集:基于ILSVRC-2012数据集(用于ILSVRC 2012-2014Chal-Lenges),该数据集包含1000个类的图像,并分为三组:训练(130万张图像)、验证(50k图像)和测试(100 k图像保留类标签)。
(2)采用两种衡量标准:前1位误差和前5位误差对克隆化性能进行评估;
前1位误差指的是一种多类分类错误,即错误分类图像的比例;
前5位误差指的是ILSVRC中使用的主要评价标准,被计算为图像的比例,使得地面真相类别超出了前5个预测类别(不明白?);+
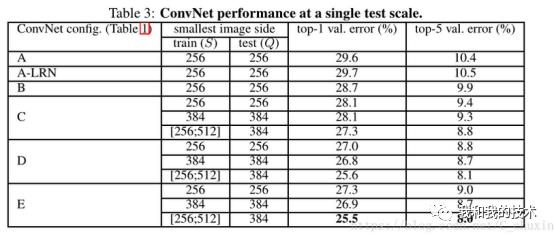
(3)单尺度评价(训练角度):
使用局部响应规范化(A-LRN网络)在模型A上没有起到好的效果,因此,不在更深的体系结构中使用LRN(B-E);
模型E(VGG19)的效果最好,即网络越深,效果越好;
同一种模型,训练时的随机scale jittering(s∈[256;512])比固定最小边(S=256或384)的图像上的训练结果要好得多,即使在测试时使用单一尺度。即scale jittering(将输入图像或者光流场的大小固定为 256×340,裁剪区域的宽和高随机从 {256,224,192,168} 中选择。最终,这些裁剪区域将会被resize到 224×224 用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动)数据增强能更准确的提取图像多尺度信息。
(4)多尺度评价(训练角度):
(5)多尺度裁剪(从测试输入的角度)
15. 效果分析:
模型E(VGG19)的效果最好,即网络越深,效果越好;
VGG模型不仅能够在大规模数据集上的分类效果很好,其在其他数据集上的推广能力也非常出色。
参考链接:
1.https://blog.csdn.net/C_chuxin/article/details/82833028;
2.https://blog.csdn.net/zhang_can/article/details/79618781;
3.https://blog.csdn.net/C_chuxin/article/details/82833070?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase;
以上是关于深度学习模型介绍AlexNetVGG--笔记的主要内容,如果未能解决你的问题,请参考以下文章