工程之道,解读业界最佳的深度学习推理性能优化方案 Posted 2021-04-19 我爱计算机视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程之道,解读业界最佳的深度学习推理性能优化方案相关的知识,希望对你有一定的参考价值。
本文转载自旷视研究院
MegEngine 「训练推理一体化」的独特范式,通过静态图优化保证模型精度与训练时一致,无缝导入推理侧,再借助工业验证的高效卷积优化技术,打造深度学习推理侧极致加速方案,实现当前业界最快运行速度。
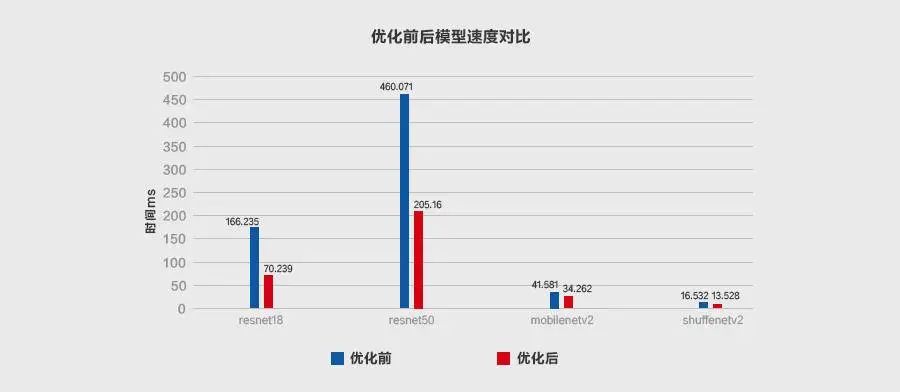
本文从推理侧的数据排布(Inference Layout)讲起,接着介绍MegEngine的Im2col+MatMul、Winograd、Fast-Run工程优化实践。经典的轻量卷积神经网络实验表明,经过MegEngine加速,ResNet18和ResNet50最高加速比可达2x以上,ShuffleNet V2和MobileNet V2执行效率也得到显著提升,实现了业界当前最佳推理性能。
深度学习是一个端到端的自动化系统,在数据驱动之下,算法历经训练测试、工程部署、推理实现三个环节。深度学习技术能否最终落地为产品,细粒度满足不同场景需求,深度学习框架的推理性能优化是一个关键变量。
针对不同硬件设备对性能的苛刻要求,业界一般做法是开发一套推理专用框架,不足是造成了训练与推理的分裂。
MegEngine
(中文名:天元)「训练推理一体化」的独特范式,可以实现训练与推理的精确等价性,避免转换可能带来的精度损失。
1)工程部署时的静态图优化,保证模型精度和训练时一致
2)推理实现时的卷积优化,保证模型运算的最快速度。两者最终的优化目标是实现模型推理又「好」又「快」。
深度学习中,卷积种类众多,计算也最为耗时,成为首要优化对象,而推理侧卷积优化更是重中之重。如何让深度学习模型鲁棒运行和推理,即在不同硬件平台(比如CPU)上,针对目标架构(比如X86/ARM)做计算优化,实现最快运行速度,是一个长久存在的挑战。
MegEngine秉持极致的
「工程之道」
,针对CPU推理的卷积优化,做了细致而系统的工程创新,不断逼近加速极限。本文是MegEngine卷积优化技术的
「综述篇」
,基于已有工作,做了多项技术的工程优化,包括
Inference Layout、Im2col+MatMul、Winograd、Fast-Run
。后续会有相关技术的详解篇。
推理侧卷积计算优化方面,首先面临的问题是feature map的
数据排布
(Tensor Layout),选择合适的数据排布不仅会使卷积优化事半功倍,还可作为其他优化方法的基础,比如
Im2col、Winograd、Fast-Run
。
NHWC:[Batch, Height, Width, Channels]
NCHW:[Batch, Channels, Height, Width]
NCHWX:[Batch, Channels/X, Height, Width, X=4/8]
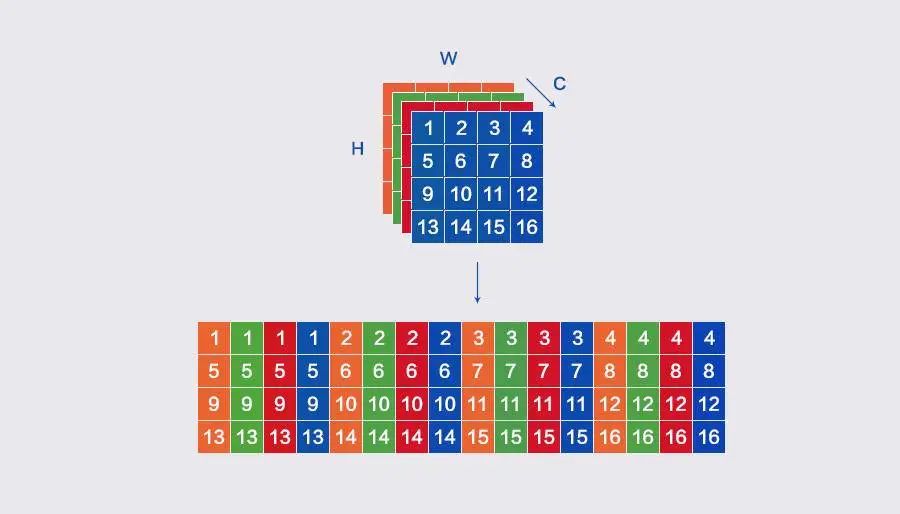
数据的排布对卷积计算有着整体性的直接影响。NHWC和NCHW的空间复杂度相同,区别在于访存行为,NCHWX介于两者之间,但是有其他优点。
NCHWX在NCHW的基础上转换而来,其原理可参考下图。
MegEngine选择NCHWX作为CPU推理实现的数据排布(Inference Layout),有如下3个原因:
适配SIMD指令,比如Arm Neon上,用4个浮点数填满一条SIMD向量,减少边界判断的次数;
对Cache更友好,比如计算卷积时读取feature map,实现多个通道连续访问;
易于进行padding,减少边界分支判断,代码逻辑简单。
Im2col+MatMul
是一种针对深度神经网络卷积计算的高效实践方法。Im2col(Image to Column)把输入feature map按照卷积核的形式一一展开并拼接成列,接着通过高性能MatMul(Matrix Multiplication) Kernel进行矩阵乘,得到输出feature map,具体原理可参考论文[1],它的本质是把卷积运算转换成矩阵运算。
Im2col+MatMul在做算法创新的同时,也产生了一些新问题:
Im2col转换之后,所得数据数倍/数十倍于输入feature map;
Im2col转换之后,数据内存占用超过L2 Cache,对Cache不友好;
Im2col转换之后,MatMul要再操作一次数据PACK。
针对这些问题,MegEngine结合自身工业实践,做了两方面的工程优化:
1)进行Im2col+MatMul分块操作,减少访存缺失;
2)融合Im2col+MatMul的PACK操作,减少数据访存。
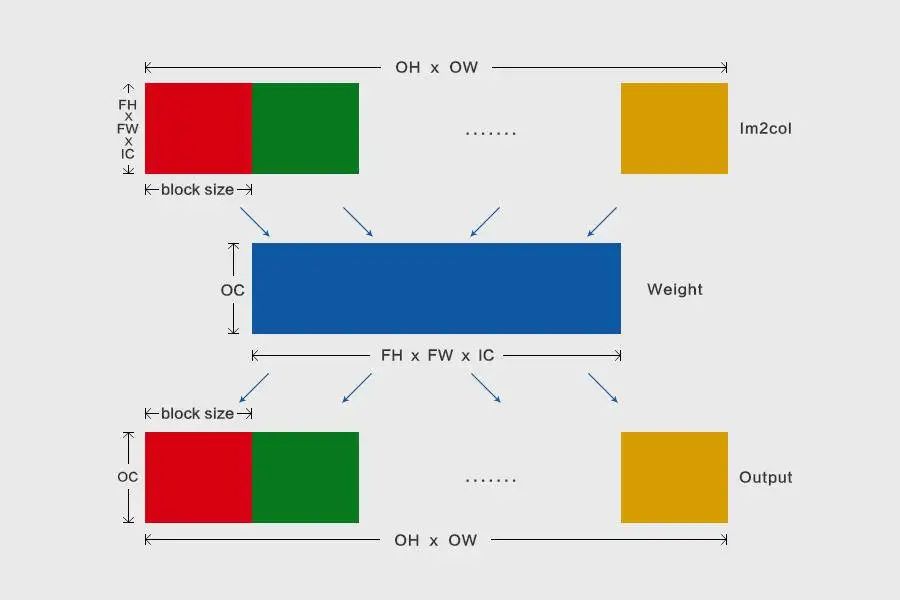
Im2col+MatMul优化卷积计算时,比如输出feature map的数据格式为 [n, oc, oh, ow],卷积核的大小为fh*fw,那么Im2col转换之后的数据格式为 [n, fh*fw*ic, oh*ow]。MegEngine的分块操作在oh*ow维度上,分块大小通过公式
计算,确保Im2col之后的数据完全保存于L2 Cache。
分块之后,不仅可以减少内存占用,还将提升数据访存效率,其原理图如下所示,把Im2col转换数据在其oh*ow维度上切块,接着,每个分块和weight进行矩阵乘,获取输出oh*ow维度上的一个分块:
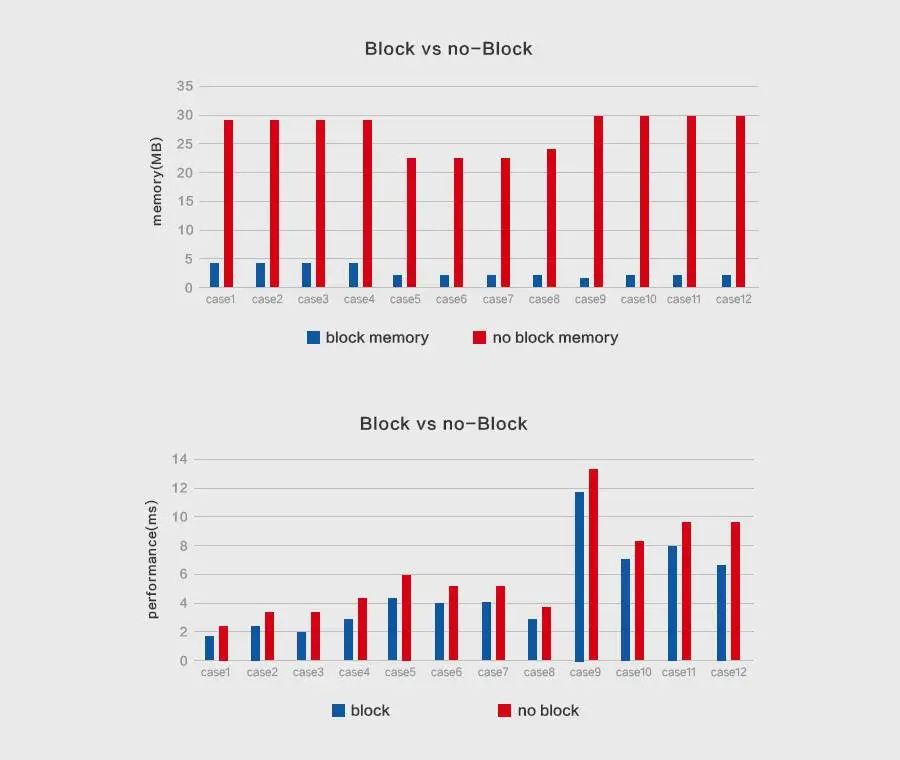
为验证分块操作的有效性,MegEngine开展了相关对比实验,在进行单层卷积计算时,给出了采用MegEngine Im2col分块操作前后的内存/性能数据的对比,其中内存占用节省了数十倍,计算性能也显著提升:
Im2col+MatMul的PACK融合操作将会减少数据访存。具体而言,Im2col转换之后的数据,在MatMul计算时需要一次数据PACK[3],实际上这对Im2col数据做了两次读写,造成了不必要的访存,因此,MegEngine通过Im2col+MatMul的PACK融合,减少了一次内存读写。
下面是Im2col+MatMul的PACK融合优化前后,卷积计算的性能测试对比,个别Case最大提升可达
18%
:
在深度神经网络中,卷积计算占据了绝大部分的时/空复杂度,Im2col+MatMul可以提高访存友好性,但无益于时间复杂度的减少,因此卷积计算优化实践中诞生了Winograd算法,具体数学原理可参见论文[2]。
Winograd算法主要应用于卷积核为3x3,步幅为1的2D卷积神经网络,其参数表示为F(mxm, rxr),其中mxm是运算之后输出块的大小,rxr是卷积核的大小,以F(2x2, 3x3)和F(6x6, 3x3)使用最多,前者加速比可达2.25x,后者加速比则高达5.06x [2]。
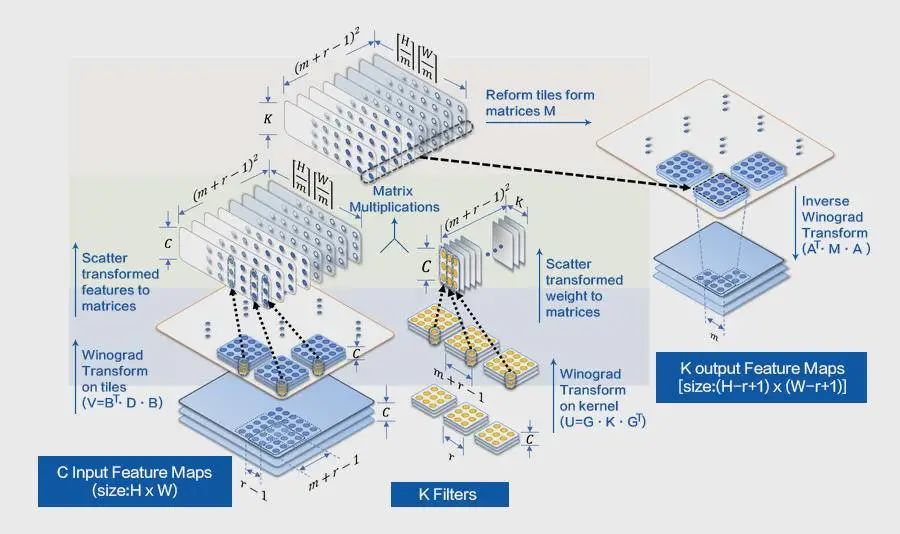
Winograd算法的本质是以加法换乘法,其计算优化的一般流程如上图所示(注:出自[3]),可分为3步:
把输入的feature map和weight进行矩阵转换;
把转换后feature map和weight做批量矩阵乘;
输入转换要计算整个feature map,数据读写对Cache不友好;
feature map转换之后,矩阵乘时需要再PACK,数据访存增加;
输出转换读取批量矩阵乘之后结果时,两次连续读写间隔较大,对Cache不友好。
针对上述问题,MegEngine结合自身多年深度学习实践,对Winograd算法的整个计算流程做了工程优化,主要有:
输入转换时,分块feature map的全部tiles,随后只计算一个分块的数据;
调整分块大小适配CPU L1 Cache,使得矩阵乘不需要PACK;
结合NCHWX数据排布,通过SIMD指令优化输入/输出转换。
由此,MegEngine对整个输入feature map进行分块,每次Winograd完整流程只计算一个分块的nr个tiles,该分块大小的计算公式为:
,即保证每个批量矩阵的输入数据(除了转换之后的weight数据)保存于L1 Cache,则矩阵乘时不PACK也不会出现访存缺失。
根据上述公式和L1 Cache大小,可计算出nr_tiles大小;但是,每个卷积的ic不同,最优分块也不同,MegEngine将通过下文介绍的Fast-Run机制做局部搜索,发现最优的分块大小。
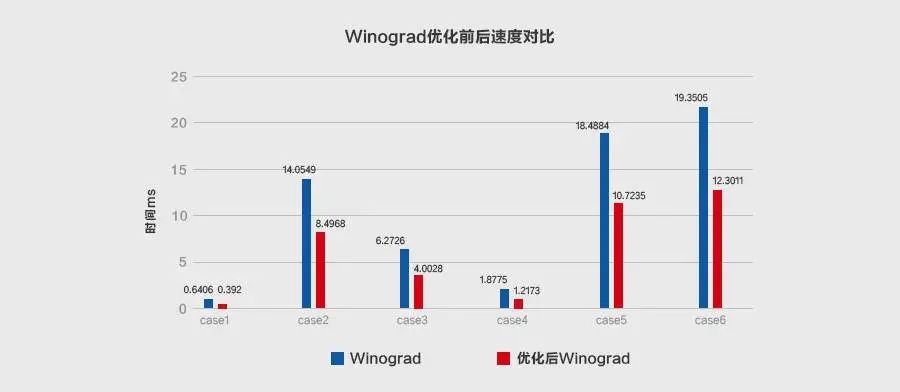
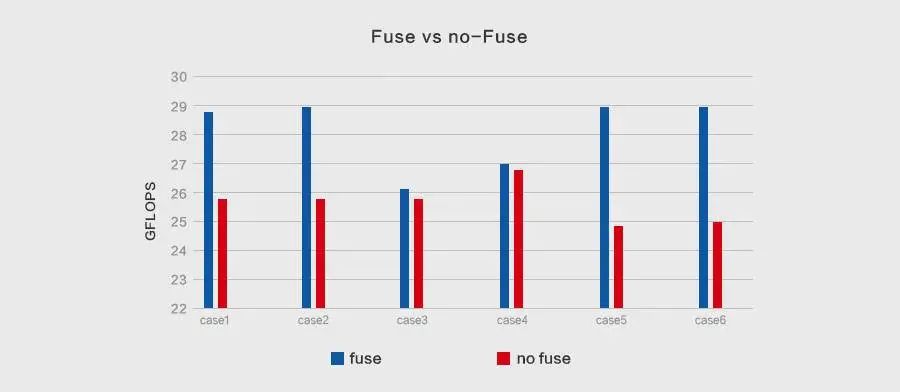
在不同的输入尺寸和算法参数F=(6x6,3x3)的情况下,原始Winograd和MegEngine优化后的Winograd之间做了加速对比实验,证明后者性能提升效果显著,具体结果如下:
卷积计算有多种优化实现,侧重点也各有不同,比如Im2col可以
平衡内存占用和运行速度
,Direct
直接进行卷积计算优化
,Winograd则是
优化计算复杂度
。每种优化实现都在特定的输入参数下有一定的优势,并随着推理平台的不同而发生变化,因此不够灵活,无法选择最优实现。上述实现的启发式偏好如下所示:
为使每个部署模型在运行推理时,最佳地实现每个卷积,MegEngine从自身工业实践获得启发,通过Fast-Run机制进行局部搜索,以改进传统的启发式方法,不遗余力地完善深度学习产品性能。
具体而言,首先,在目标设备上使用目标模型参数搜索所有已实现的算子;接着,记录并保存同时适配目标设备和目标模型的最优算子;最后,在推理时使用最优算子进行计算。
Fast-Run机制有着较强的自适应性,弥补了启发式机制的一些的缺陷,从根本上确保了目标模型的算子最为适配目标设备,从而发挥出最佳性能。
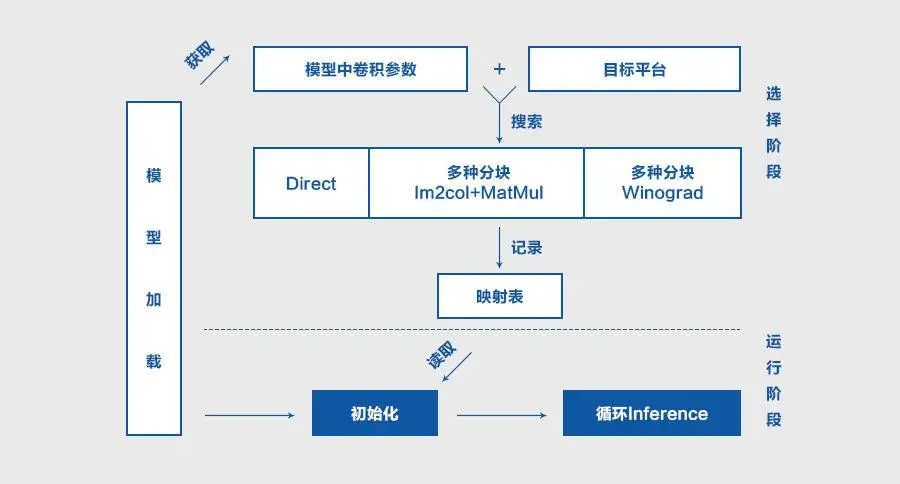
Fast-Run机制的本质是寻找最优算子,其工程实现分为选择和执行两个阶段:
选择阶段,测速模型每个算子,选出最优实现,保存算子名称和最优实现的映射表;
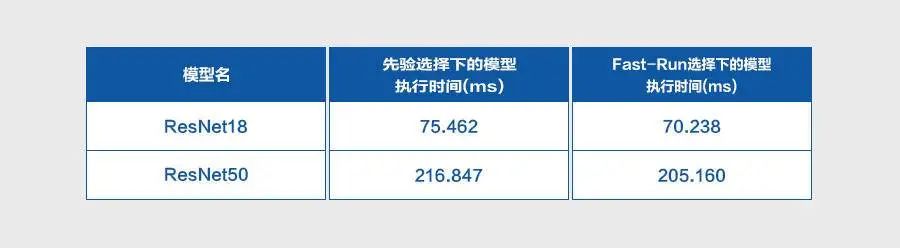
经典卷积网络上的实验测试证明了Fast-Run机制的自适应优势,优化效果明显,其模型执行效率优于先验选择下的执行效率,具体结果如下所示:
深度学习算法在数据的加持之下,迭变权重,更新参数,积累知识,以深度学习产品的方式与这个世界交互。「好而快」是衡量这种交互的不二圭臬。这里,「好」或者精度,对应于静态图优化,「快」或者速度,对应于卷积计算优化,「好而快」是精度和速度的权衡,对应于深度学习框架。
MegEngine「训练推理一体化」有着独特优势,相较推理专用框架,更利于在「好」的基础上做到「快」。通过上文,MegEngine在一系列经典的轻量级卷积网络上,做了集成式卷积优化实验,ResNet18和ResNet50最高加速比可达2x以上,ShuffleNet V2和MobileNet V2执行效率获得大幅提升,实现了当前业界最佳的推理性能。
这些技术将在今年6月底发布的MegEngine Beta版本中有所体现,敬请期待。下一步,MegEngine将尝试全局混合Layout和混合精度优化,探索更低精度的量化(4bit/1bit),以及采用多级分块适配CPU多级Cache大小,最大化访存友好性,不断逼近推理侧的加速极限。
[1] Kumar Chellapilla, Sidd Puri, Patrice Simard. High Performance Convolutional Neural Networks for Document Processing. Tenth International Workshop on Frontiers in Handwriting Recognition, Université de Rennes 1, Oct 2006, La Baule (France).
[2] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. The European Conference on Computer Vision (ECCV), 2018, pp. 116-131.
[3] Lavin, A. and Gray, S. Fast algorithms for convolutional neural networks. In CVPR, 2016.
[4] Feng Shi,Haochen Li,Yuhe Gao,Benjamin Kuschner,Song-Chun Zhu. Sparse Winograd Convolutional neural networks on small-scale systolic arrays. FPGA, Volume abs/1810.01973, 2019, Pages 118.
模型压缩、网络压缩、神经网络加速、轻量级网络设计、知识蒸馏、应用部署、MNN、NCNN等技术,
若已为CV君其他账号好友请直接私信。
微博知乎:@我爱计算机视觉
投稿:amos@52cv.net
网站:www.52cv.net
在看,让更多人看到
以上是关于工程之道,解读业界最佳的深度学习推理性能优化方案的主要内容,如果未能解决你的问题,请参考以下文章
地址标准化服务AI深度学习模型推理优化实践
深度解读58本地服务Flutter落地实践:两点优化建议,四个避坑经验
地址标准化服务AI深度学习模型推理优化实践
巨详细!使用OpenCV和OpenVINO轻松创建深度学习应用
解读业界5种主流的深度网络模型
技术解读倚天 ECS 实例 — Arm 芯片的 Python-AI 算力优化
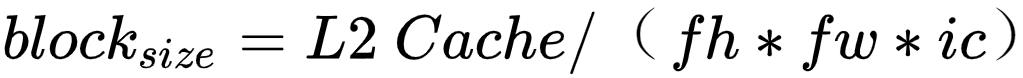 计算,确保Im2col之后的数据完全保存于L2 Cache。
计算,确保Im2col之后的数据完全保存于L2 Cache。
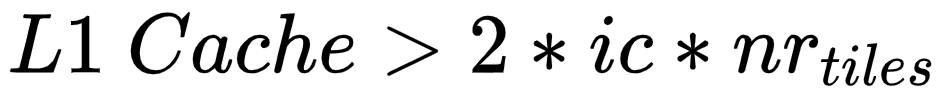 ,即保证每个批量矩阵的输入数据(除了转换之后的weight数据)保存于L1 Cache,则矩阵乘时不PACK也不会出现访存缺失。
,即保证每个批量矩阵的输入数据(除了转换之后的weight数据)保存于L1 Cache,则矩阵乘时不PACK也不会出现访存缺失。