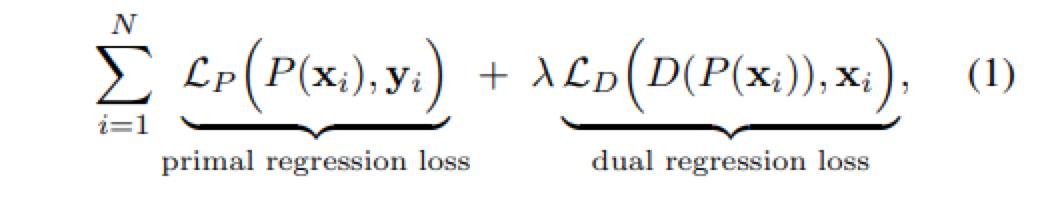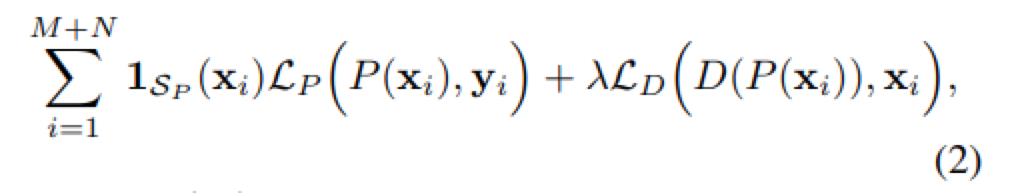深度学习工程师必看:更简单的超分辨重构方法拿走不谢
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习工程师必看:更简单的超分辨重构方法拿走不谢相关的知识,希望对你有一定的参考价值。

作者 | Yong Guo, Jian Chen等
出品 | AI科技大本营(ID:rgznai100)
通过学习从低分辨率(LR)图像到高分辨率(HR)图像之间的非线性映射函数,深度神经网络在图像超分辨率(SR)任务上取得了较好的性能。
但是,现有的SR方法存在两个缺点:第一,学习从LR到HR图像的映射函数通常是一个不适定问题,因为存在无限的HR图像可以降采样为同一LR图像,这使得很难找到一个好的解决方案。第二,成对的LR-HR数据在实际应用中可能并不适用,因为图像退化的方法通常是未知的。对于这种更一般的情况,现有的SR模型通常会产生较差的性能。
为了解决上述问题,本文提出了一种对偶回归方法,它通过引入对LR数据的附加约束来减少函数的解空间。
具体而言,除了学习从LR到HR图像的映射外,本文方法还学习了另外的对偶回归映射,用于估计下采样的内核并重建LR图像,从而形成了一个闭环,可以提供额外的监督。
更关键的是,由于对偶回归过程不依赖于HR图像,因此我们可以直接从LR图像中学习。从这个意义上讲,我们可以轻松地将SR模型适应于真实场景的数据,例如来自YouTube的原始视频。实验结果证明了本文方法是优于现有方法,且能在真实场景上取得较好的结果。
深度神经网络(DNN)已成为许多实际应用的主力军方法,包括图像分类,视频理解等等。
最近,图像超分辨率(SR)已成为一个热门的方向,它主要是学习从低分辨率(LR)图像到高分辨率(HR)图像之间的非线性映射。目前已经提出了许多基于深度学习的超分辨重构方法。但是,这些方法主要有两个局限:
第一,学习从LR到HR图像的映射通常是一个不适定问题,因为存在无限多可能的HR图像可以降采样获得相同的LR图像。这会导致LR映射到HR图像的解空间变得极大。因此很难在如此大的空间中学习到好的解决方案,模型性能受到限制。为了提高SR的性能,可以通过增加模型的复杂度来设计有效的模型,例如EDSR,DBPN和RCAN。但是,这些方法仍然存在解空间大的问题,从而导致超分辨性能有限,不会产生细致的纹理(见图1)。因此,如何减少映射函数的解空间以提高SR模型的性能成为了比较重要的问题。
第二,当无法获取配对的数据时,很难获得较好的SR模型。这是由于大多数SR方法都依赖于成对的训练数据,即HR图像及其Bicubic降级后的LR图。但是实际情况是,未配对的数据通常更多。而且,真实世界的数据不一定与通过特定的降采样方法(例如,双三次)获得的LR图像具有相同的分布。因此,能处理实际场景的SR模型是非常具有挑战性的。更关键的是,如果我们将现有的SR模型直接应用于现实世界的数据,它们通常会带来严重的泛化性问题,并产生较差的性能。因此,如何有效利用未配对的数据以使SR模型适应实际应用是一个比较重要的问题。
在本文中,作者提出了一种新的对偶回归方法,该方案形成了一个闭环用以增强SR性能。
为了解决第一个问题,本文引入了一个额外的约束来减少可能的解空间,以使超分辨图像可以重构输入的LR图像。
理想情况下,如果来自LR→HR的映射是最佳的,那么可以对超分辨图像进行降采样以获得相同的输入LR图像。在这样的约束下,我们能够估计出下采样内核,从而减少可能的函数空间,找到从LR到HR较好的映射。因此,这会变得更容易获得好的SR模型(请参见图1中的比较)。
为了解决第二个问题,由于LR图像的回归不依赖于HR图像,因此我们的方法可以直接从LR图像中学习。通过这种方式,本文方法可以轻松地将SR模型调整为适用于现实世界中的LR数据,例如来自Youtube的原始视频。实验证明了本文的方法优于SOTA方法。
-
本文通过引入其他约束条件提出了对偶回归方法,以便形成闭环的映射,可以增强SR模型的性能。此外,本文还从理论上分析了该方案的泛化能力,从而进一步证实了该方案是优于现有的方法。
-
本文研究了更通用的超分辨率情况,如没有相应HR数据的真实LR数据。利用提出的对偶回归方法,可以轻松地将深度模型调整为适用于现实世界的数据,例如YouTube的原始视频。
-
利用配对的训练数据和未配对的真实场景数据做了大量的SR实验,证明了本文所提出的对偶回归方法在图像超分辨率中的有效性。
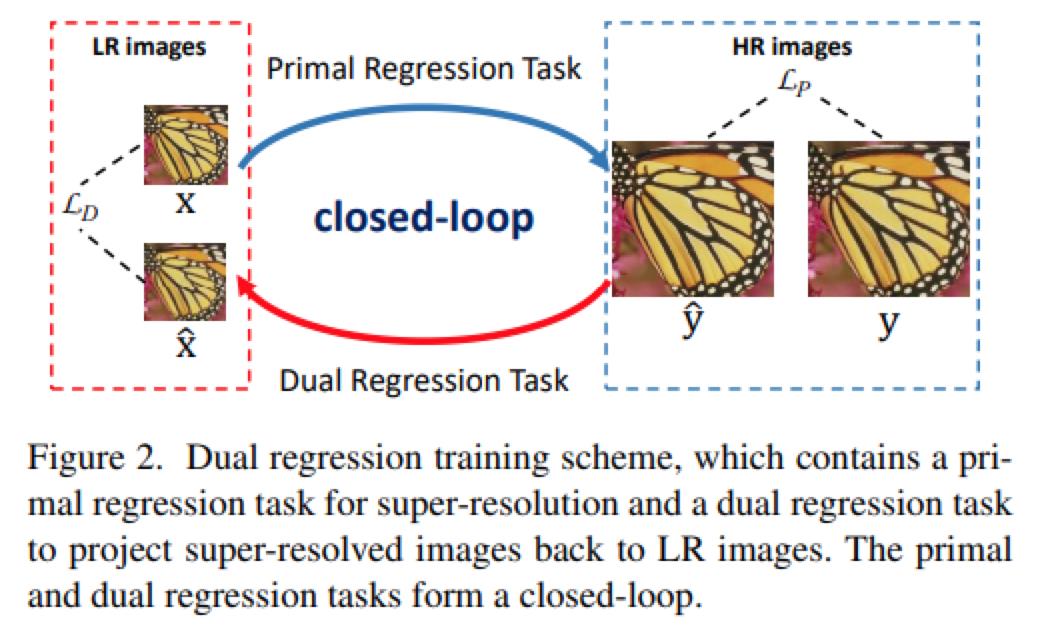
本文提出了一种对偶回归方法来处理配对的和非配对的训练数据,以实现超分辨率(SR)重构。总体的训练方案如图2所示。
针对配对的训练
数据,主要是
通过对LR数据引入了一个附加约束,除了学习LR 到HR的映射外,本文还学习了从超分辨图像到LR图像的逆映射。实际上,作者将SR问题公式化为涉及两个回归任务的对偶回归模型。损失函数如下图所示,包含两部分,一个是P网络的损失,一个是D网络的损失,权重推荐设置为0.1。
针对未配对的训练
数据,作者还考虑了
更一般的SR情况,对应真实场景的数据,是没有对应的HR数据可以用于训练。因此作者提出了一种有效的训练方法,可以使SR模型更适应新的LR数据,训练算法如下所示。
这是一种半监督的学习方法,使用配对的数据训练P网络,使用没有配对的数据训练D网络。目标函数如下,其中当使用有标签的数据时,1Sp为1,当使用没有标签的数据时,1Sp为0。
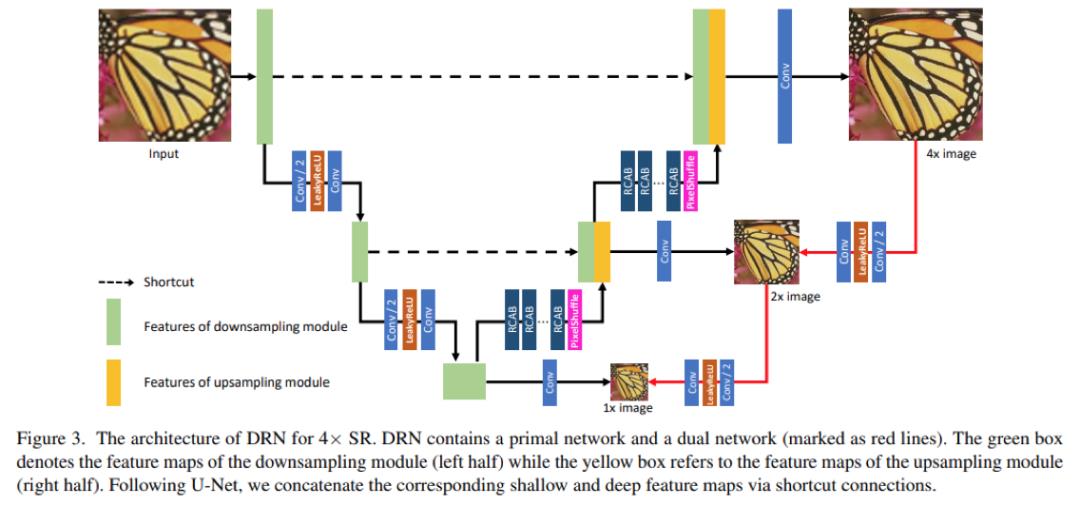
网络的整体结构如下图所示,它是基于U-Net设计的超分辨网络。本文的DRN模型由两部分组成:原始网络和对偶网络。作者还给出了详细的理论证明,这里就不赘述了,详情可以参见论文。
作者在具有成对的Bicubic数据和不成对的真实数据情况下,对图像超分辨率任务进行了广泛的对比实验。所有实现均是基于PyTorch框架。测试数据集是五个基准数据集,包括SET5,SET14,BSDS100,URBAN100和MANGA109。评价指标是常用的PSNR和SSIM。训练集是DIV2K和Flickr2K数据集。
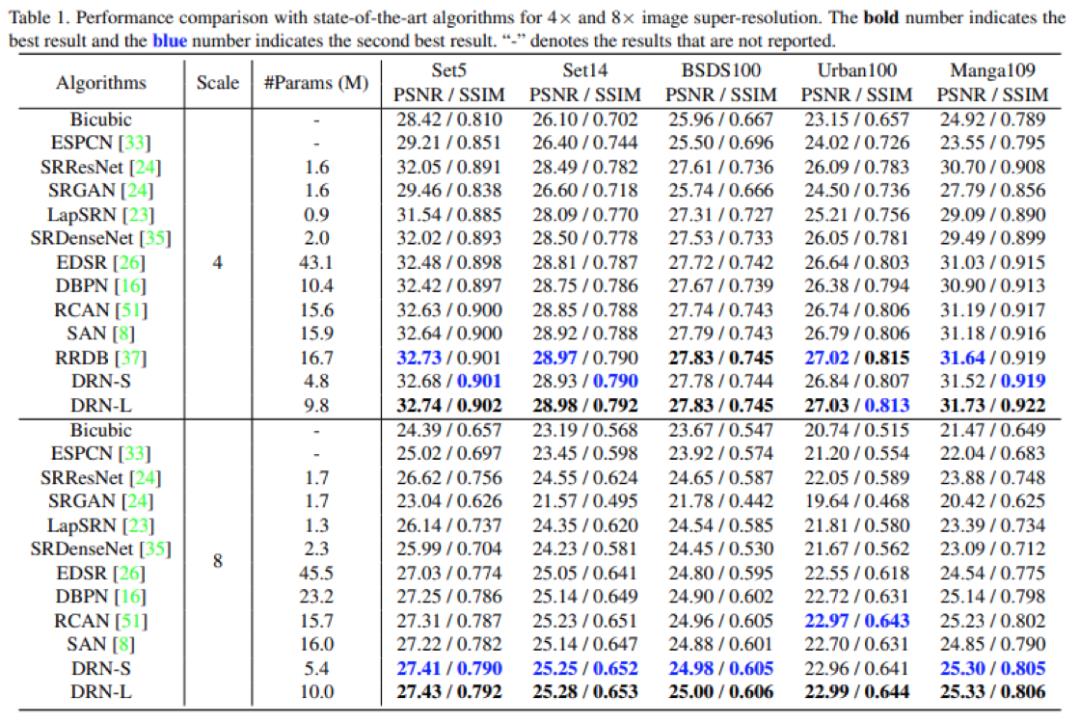
作者首先展示了4x和8x SR的性能和模型大小的比较。在实验中,作者提出了两种模型,即小模型DRN-S和大模型DRN-L。而对比的方法是从它们的预训练模型,开源的代码或是原始论文中获得的结果。结果如下:
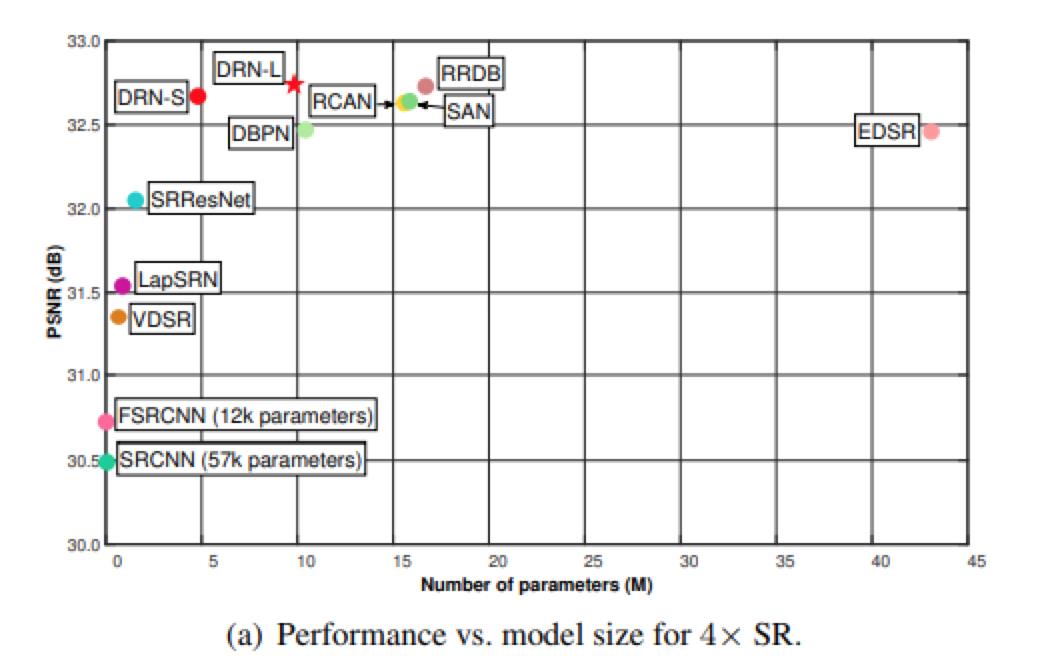
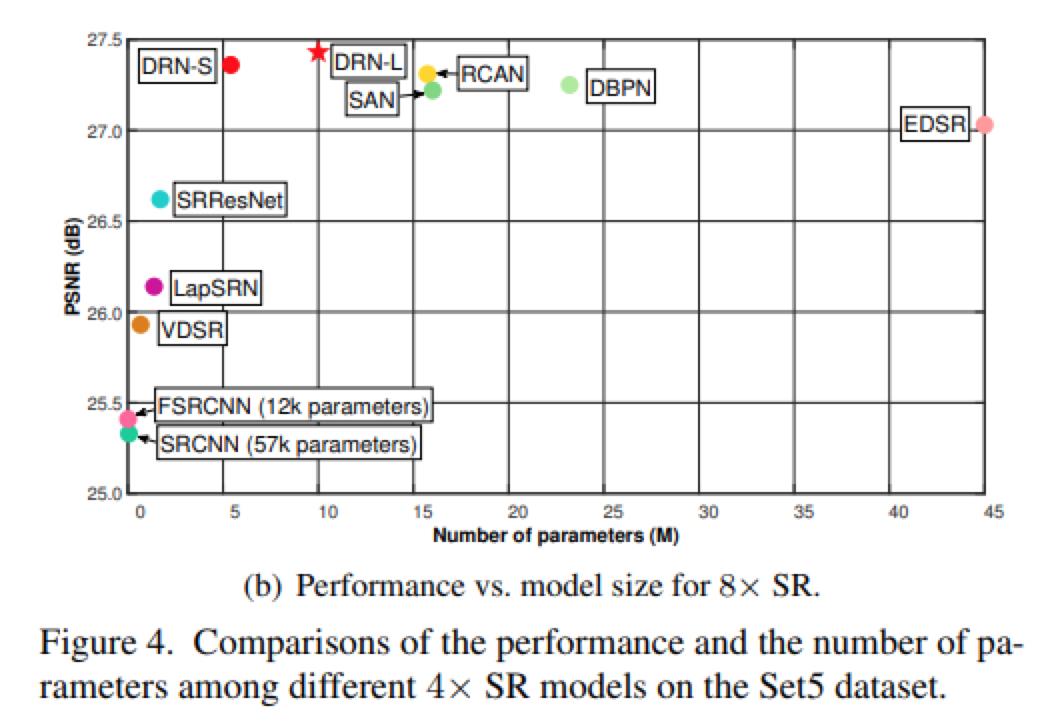
还提供了4倍超分辨和8倍超分辨下,各方法性能对比的曲线图。
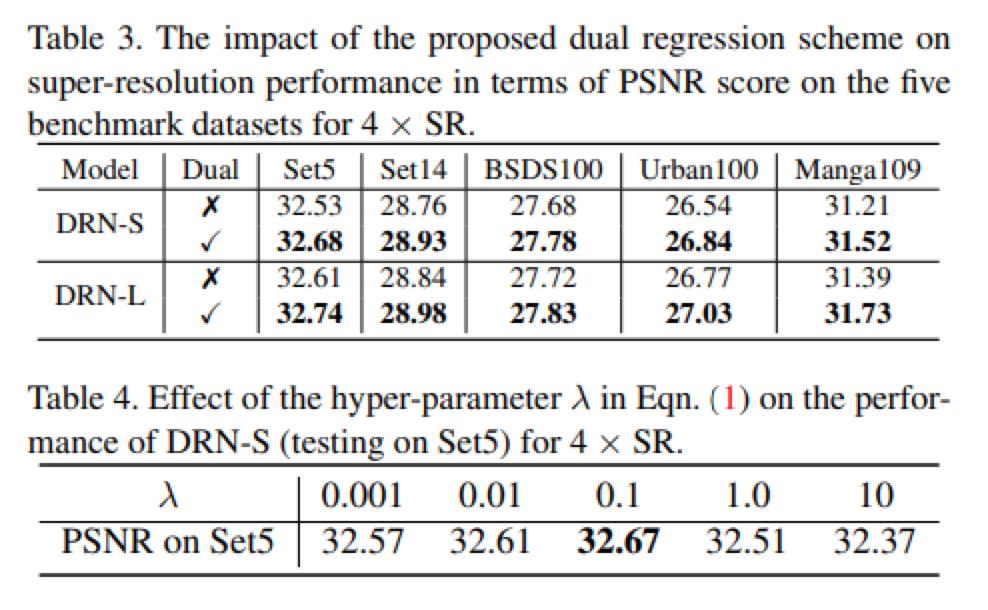
作者还研究了P网络和D网络两个损失函数之间的权重影响。以及是否加对偶学习的影响。如下表格所示。
最后,作者对比了在真实场景下的重构效果,这里仅展示了视觉上的结果。也对比了使用不同插值方法下的效果,可发现本文的效果均是最优的。
在本文中,作者提出了一种针对配对和非配对数据的对偶回归方法。在配对数据上,作者通过重构LR图像来引入解空间的约束,可以显著提高SR模型的性能。此外,本文还将重点放在未配对的数据上,并将对偶回归方法应用于实际数据,例如来自YouTube的原始视频。对成对和非成对数据的大量实验证明了本文的方法是优于基准方法。
https://arxiv.org/pdf/2003.07018.pdf
今
晚8点
,我们一起来看Sophon KG如何追寻新冠病毒轨迹,运用AI技术、工具建立相关知识图谱,通过确诊案例的亲属、同事和朋友的关系网找出密切接触者进行及时隔离,同时刻画出确诊案例的活动轨迹,找到其关系网之外的密切接触者及病毒可能的“行凶环境”。

点击阅读原文,参与报名!
以上是关于深度学习工程师必看:更简单的超分辨重构方法拿走不谢的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow入门必读教程,拿走不谢!
曾售价 2599 元的 TensorFlow 培训你没舍得?今 580 元拿走不谢!
200页!阿里巴巴内部火爆的Python学习知识手册!拿走不谢!
常用算法25讲,拿走不谢!
Android面试中最常见的174个问题 (附详细答案),拿走不谢
初学 C 语言没有项目练手?这 20 个小项目拿走不谢~