深度学习十年发展回顾:里程碑论文汇编
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习十年发展回顾:里程碑论文汇编相关的知识,希望对你有一定的参考价值。
理解深度前馈神经网络训练的难点(7446次引用)
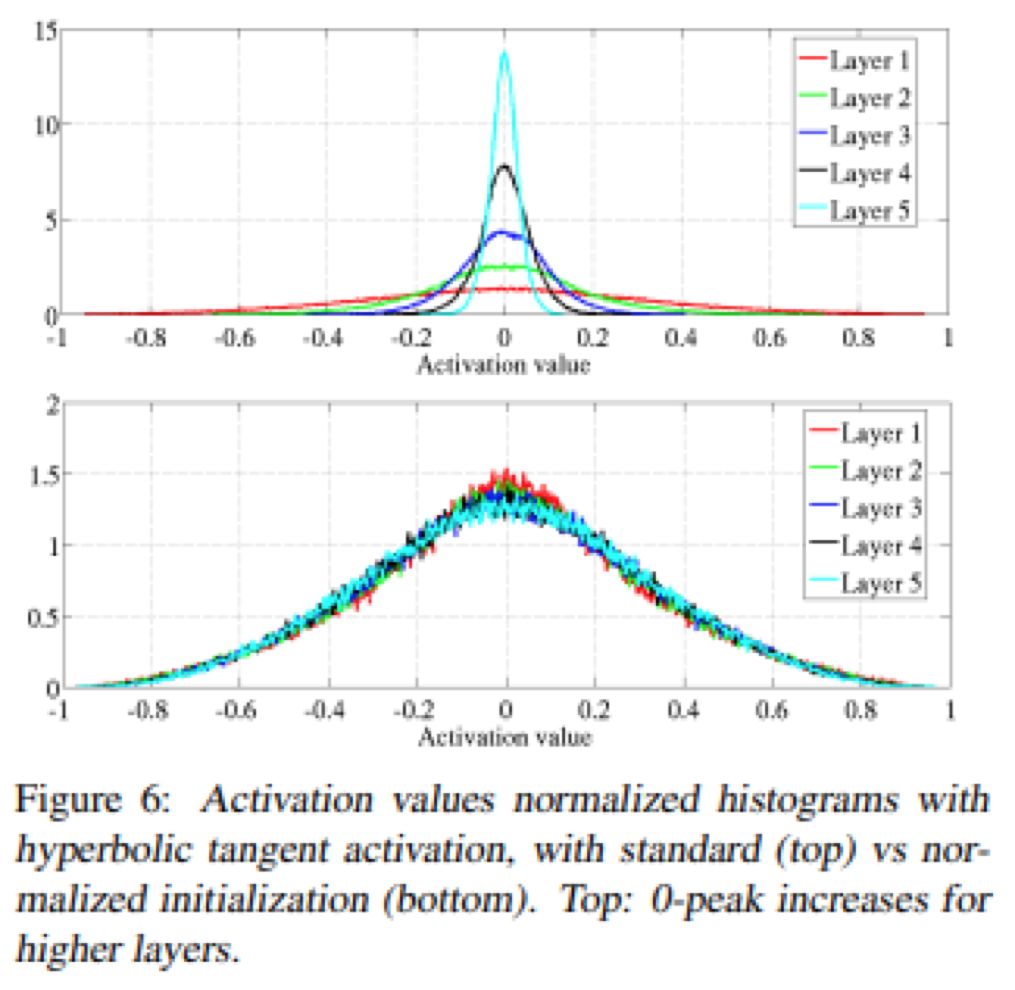
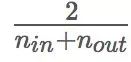 的正态分布初始化权重,
的正态分布初始化权重,
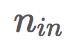 和
和
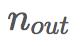 分别是前一层神经元和后一层神经元的数量。2015年的一篇论文《深入研究整流函数:在ImageNet分类上超越人类水平》介绍了Kaiming初始化,它是在Xavier初始化的基础上考虑了ReLU激活函数的一个改进版本。
分别是前一层神经元和后一层神经元的数量。2015年的一篇论文《深入研究整流函数:在ImageNet分类上超越人类水平》介绍了Kaiming初始化,它是在Xavier初始化的基础上考虑了ReLU激活函数的一个改进版本。
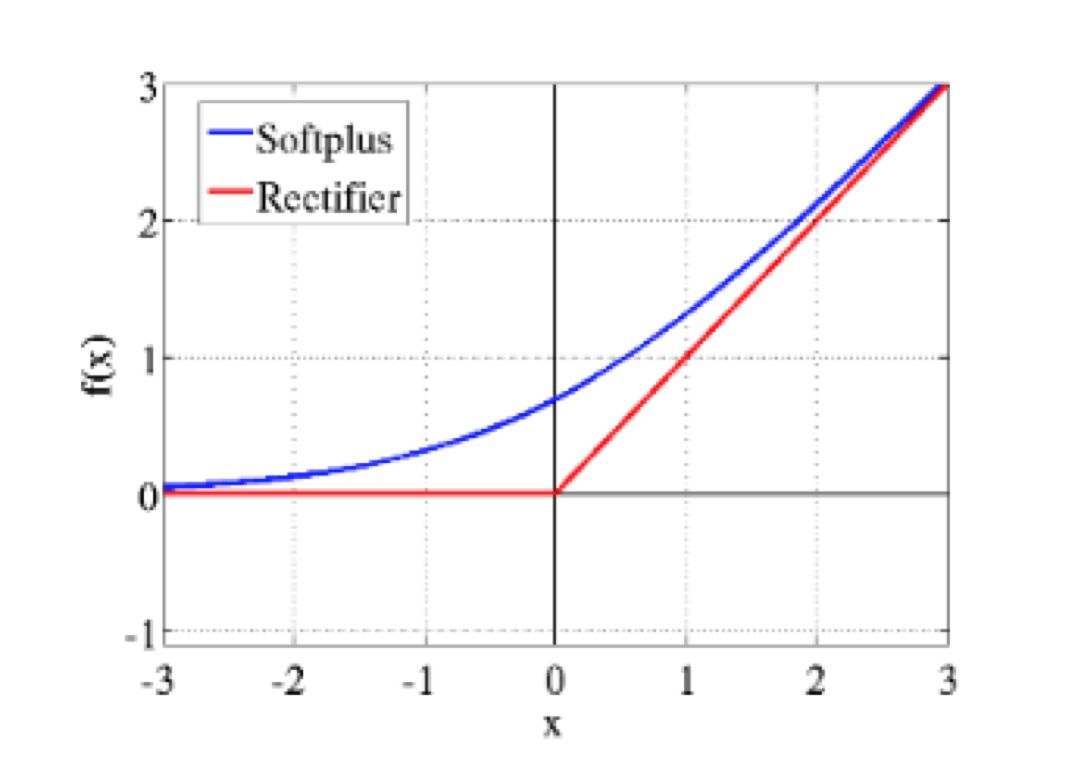
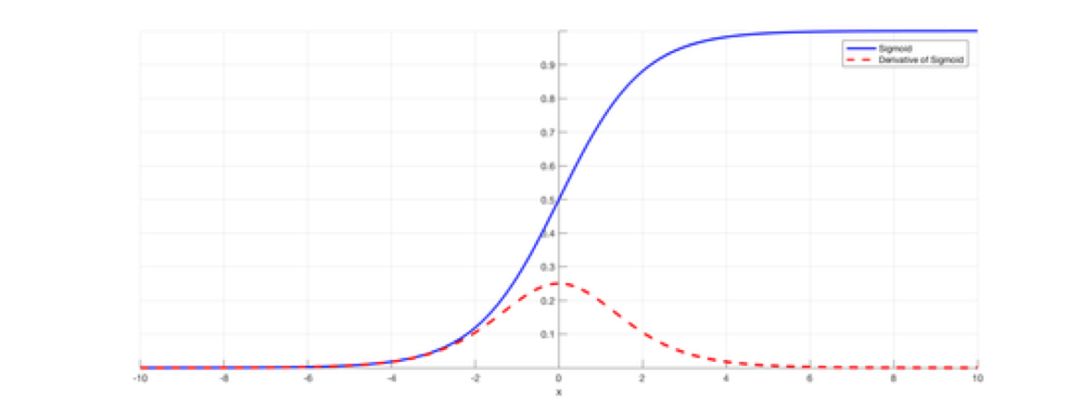
深度稀疏整流神经网络 (4071 次引用)
著名文章对其的引用:
整流非线性改进神经网络声学模型:该论文介绍了带泄露线性整流函数(Leaky ReLU),由于在负半部分上存在较小的梯度“泄露”,因此其输出不为零。这也防止了ReLU激活函数中部分神经元死亡现象的出现。然而,Leaky ReLU在0处的导数是不连续的。
指数线性单元快速准确的深度网络学习:指数线性单元(ELUs,Exponential Linear Units)和 Leaky ReLU相似,但在负侧更平滑且饱和值为-1。
Self-Normalizing神经网络:自归一化神经网络(SELUs,Self-Normalizing Neural Networks)旨在缩放ELU来创建固定点,并将其分布修改为标准正态分布,从而解决数据批量归一化的需求。
高斯误差线性单位:高斯误差线性单元(GELU,Gaussian Error Linear Units (GELUs):)作为一种常用的激活函数,其激活是基于高斯分布及对应的随机正则器dropout。具体来说,一个特定的值被保留的概率是标准正态分布的累积分布函数
 。因此,这个变量的期望值在随机正则化后就变成了。GELU在许多SOTA模型中有所应用,如BERT和GPT/GPT2。
。因此,这个变量的期望值在随机正则化后就变成了。GELU在许多SOTA模型中有所应用,如BERT和GPT/GPT2。
深度卷积神经网络的ImageNet分类(52025次引用)
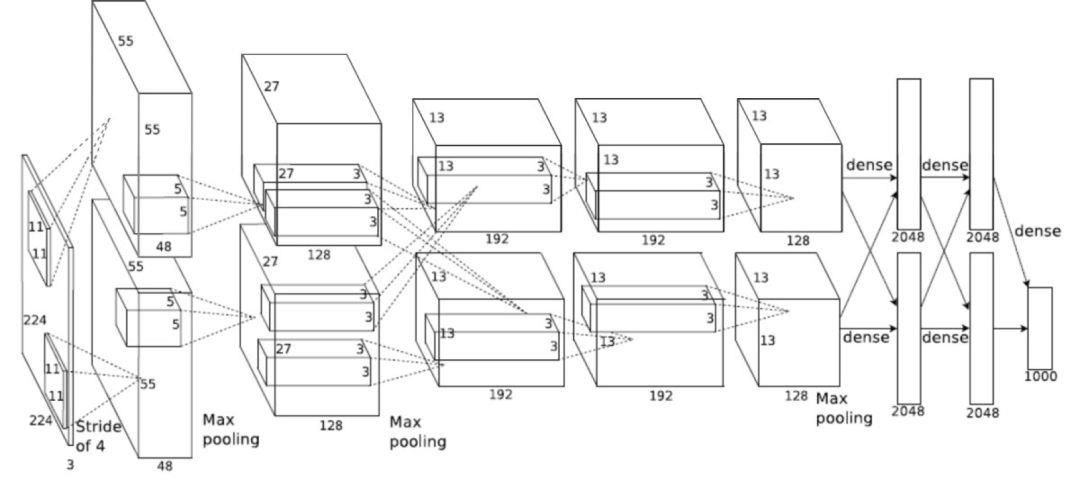
著名文章对其的引用:

ImageNet:一个大型的分级图像数据库 :ImageNet数据集也为深度学习的兴起做了相当大的贡献。它也是深度学习领域被引量最高的论文之一,有着大约15050次引用(因为它于2009年发表,所以我决定将它列为荣誉奖)。该数据集是使用Amazon Mechanical Turk将分类任务外包给工人来构建的,这也使得这个天文级别的数据集成为可能。ImageNet大型视觉识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge)是以ImageNet数据库为对象的图像分类算法竞赛,同时它也推动了计算机视觉领域其他许多创新的发展。
灵活、高性能的卷积神经网络用于图像分类 :这篇论文早于AlexNet发表并与AlexNet有着许多共同点:这两篇论文都利用GPU加速训练神经网络,都利用ReLU激活函数来解决梯度消失问题。一些人认为这篇文章被冷落是很不公正的,它的被引量远少于AlexNet。
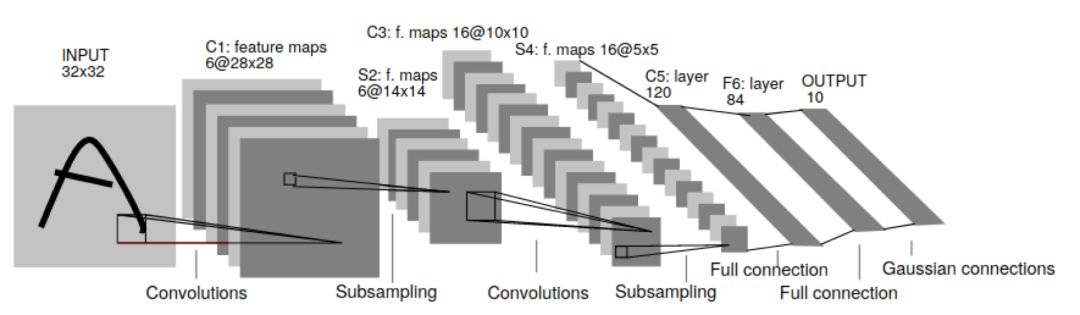
梯度学习在文档识别中的应用:发表于1998年,有着23110被引量,是将卷积神经网络用于图像识别的先驱。事实上,当下的卷积神经网络几乎完全是该早期工作的放大版。甚至于更早的论文,如LeCun在1989年发表的《Backpropagation Applied to Handwritten Zip Codes》可以说是第一例梯度下降的卷积神经网络。
著名文章对其的引用:
GloVe: 单词表示的全局向量 :GloVe的核心思想与word2vec相同,是其改进版本,但是实现方式略有不同。关于这两个模型哪一个更好,人们至今没有定论。
 —它根据Q函数及概率
的估计结果而采取最贪婪(即得分最高)的行动。这样也是为了探索整个状态空间。训练Q值函数的目标是从贝尔曼方程(Bellman equation)推导出来的,它将Q值分解为当前奖励值与加权后的下一期的最大Q值之和
—它根据Q函数及概率
的估计结果而采取最贪婪(即得分最高)的行动。这样也是为了探索整个状态空间。训练Q值函数的目标是从贝尔曼方程(Bellman equation)推导出来的,它将Q值分解为当前奖励值与加权后的下一期的最大Q值之和
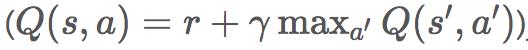 ,从而可以实现参数的自更新。这种基于当前值和未来价值函数之和来更新价值函数的方式通常被称为时差学习(Temporal Difference Learning)。
,从而可以实现参数的自更新。这种基于当前值和未来价值函数之和来更新价值函数的方式通常被称为时差学习(Temporal Difference Learning)。
著名文章对其的引用:
Learning from Delayed Rewards:Christopher Watkins发表于1989年的博士毕业论文介绍了Q学习。

-
Wassertein GAN及改进的Wassertein GAN:原版生成对抗网络(Vanilla GANs)存在种种问题,特别是训练的稳定性问题。即使经过轻微调整,原版GANs也常常训练失败,或者出现模式崩溃(也即,生成器生成只生成几张图片)的情况。调整梯度的Wassertein GAN提高了训练稳定性,因此也成为如今事实上默认使用GAN。原版GANs使用Jensen-Shannon距离法,导致分布之间因不正常的梯度饱和几乎不相交;WGAN与之不同,采用的是Earth Mover距离法。WGAN原稿论文通过限制权重的方式,强加了一个要求梯度小于任何一个常量的Lipschitz连续性限制,从而通过调整梯度的方式改善了一些存在的问题。

-
StyleGAN:StyleGAN能够生成令人惊叹的、几乎无法区分于真实图片的高清图片。生成如此高清图片的GANs之中所运用的最重要的技术就是渐进地增大图片大小,而StyleGAN内置了这项技术。StyleGAN还能修改不同大小规模的图片的隐空间,从而只对生成图片的特定细节进行操作。

-
无耦合权重衰减正则化: 这篇文章声称发现了在通常实施中使用带权重衰减的Adam运用的一个错误,并提出替代方案AdamW优化来解决上述问题。
-
RMSProp :另一个流行的自适应优化方法(特别是RNNs领域,虽然这个方法与Adam相比究竟孰优孰劣还在争论中)。RMSProp因其可能是机器学习领域的课程ppt中被引用最多而“臭名昭著”。
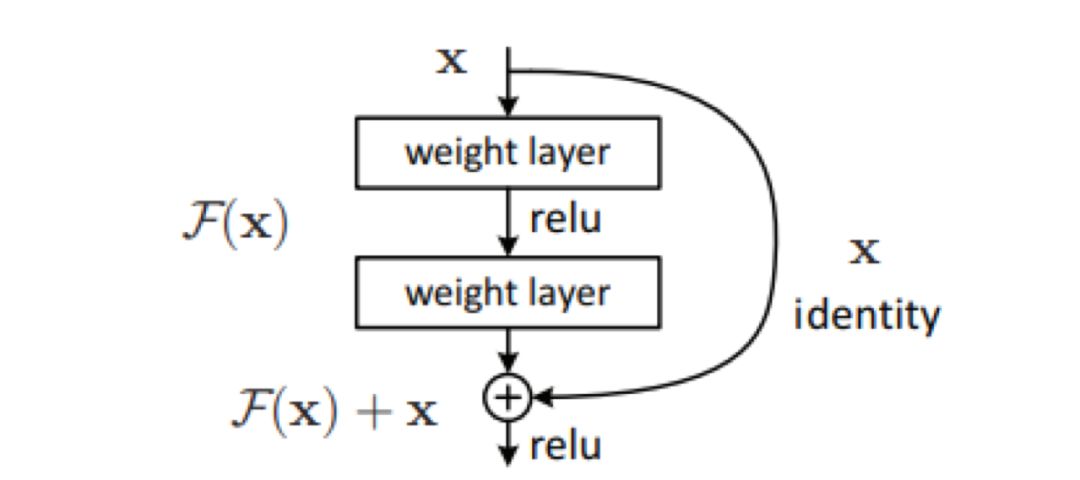
• 高速网络:残差网络是早期高速网络的一个特例。早期的高速网络通过一个类似但更复杂的封闭式设计,来在更深度网络中处理梯度。
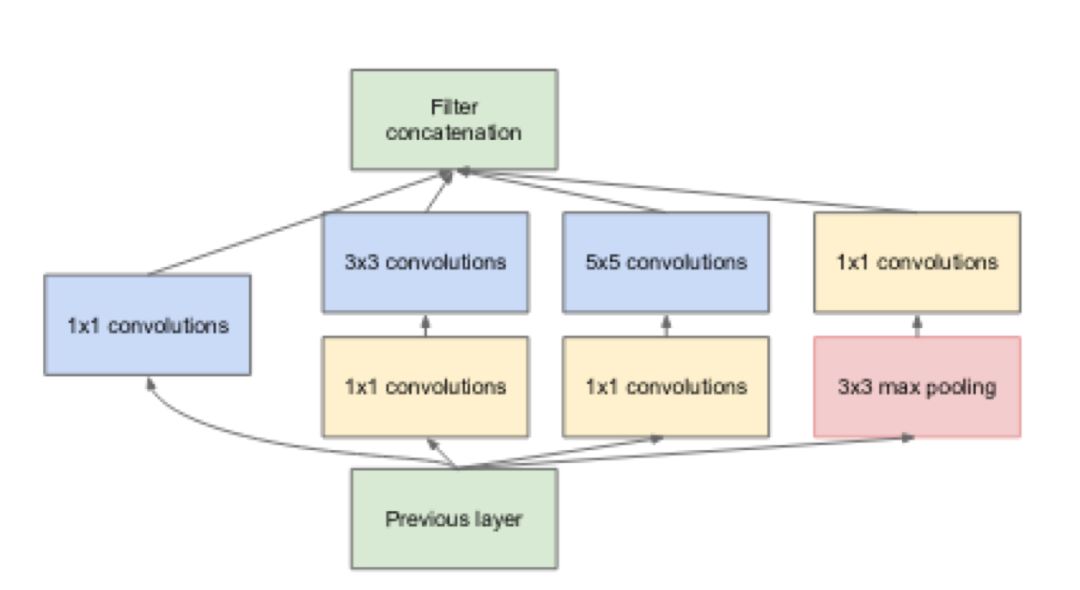
更深度的卷积:Inception模块理论源于把卷积化为因子来减少参数数量,以及减少激活次数。它能容下更深度的层嵌套,对这篇文章中提到的GoogleNet十分有益;文中的GoogleNet后来改名为SOTA网络(ILSVRC2014)。之后的许多再次介绍Inception模块的文章也相继发表了,Inception模块最终以Inception版本4嵌入于ResNets中,详情参考:Inception-ResNet及残差关系在机器学习上的影响。
针对大比例图像识别的超深度卷积网络:这是又一个在CNNs历史上非常重要的作品,这篇文章引入了VGG网络的概念。这篇文章的重大意义在于,它探索了只使用3*3卷积的可能性,而不是像其它大部分网络中更大的卷积,因而大幅降低了参数数量。
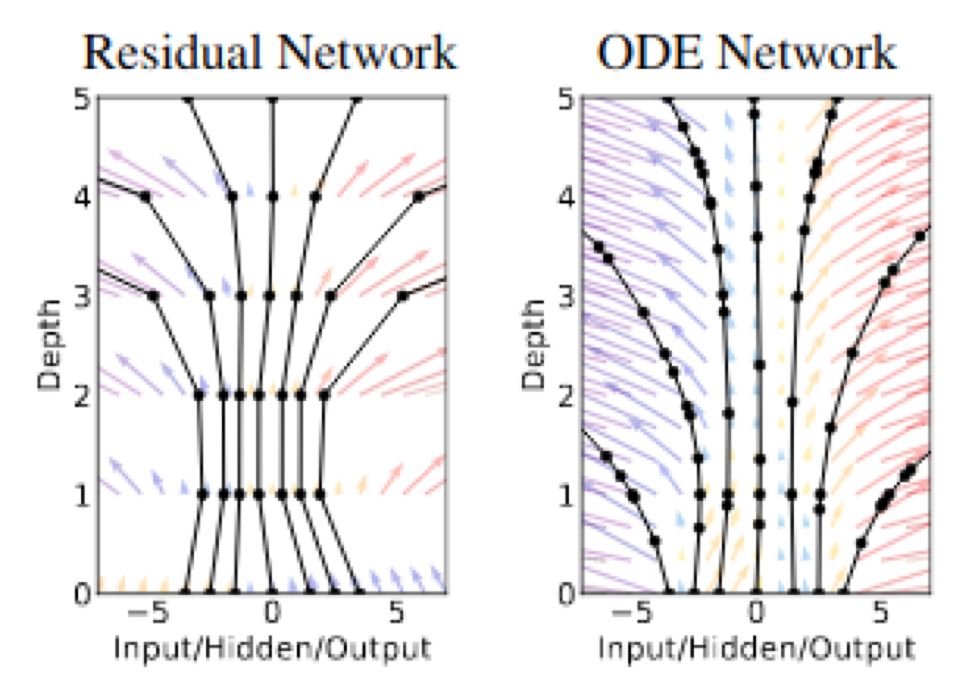
神经常微分方程:神经常微分方程这篇文章曾获2018年NIPS最佳论文奖,划分开了残差和微分方程。其核心观点就是讲残差网络视作连续转换的一个离散化,从而可定义残差网络为一个常微分方程的参数设定,也就可以用现成的求解器来求解。
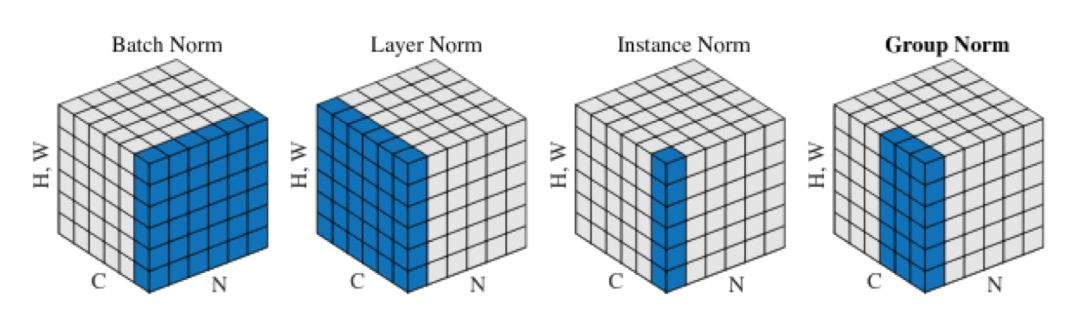
层正则化,实例正则化,以及群正则化:许多其它基于不同方法加总数据的可选方法如雨后春笋般出现,分别是同批处理,批处理和通道,或者批处理和多通道。这些技术在不希望同批处理和/或通道中的不同样本互相干扰的时候十分有效,关于这点最好的例子就是GANs中的应用。
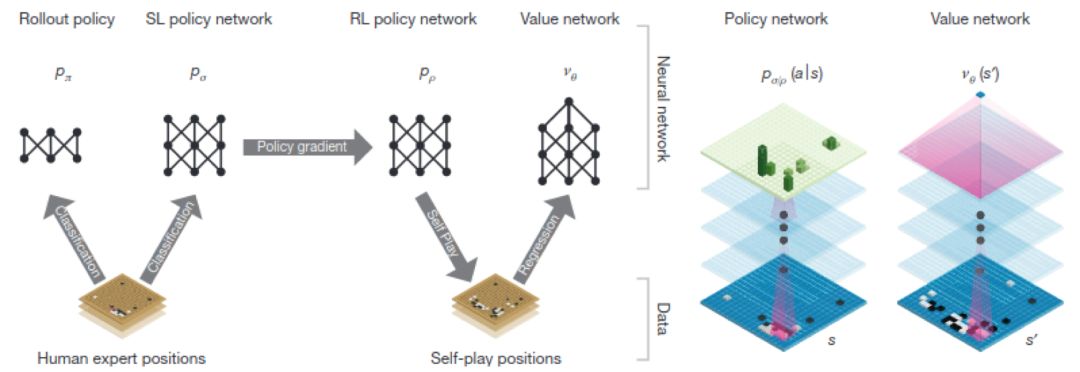
不用人类经验而精通围棋:这篇介绍AlphaGo Zero的文章,移除了受监督学习过程,通过对战自己来训练策略和价值网络。虽然未受人类围棋策略的影响,AlphaGo Zero却能自己走出许多人类围棋手的策略,此外还能独创自己更优的围棋策略;这些策略甚至与传统围棋思路中的假定是相悖的。
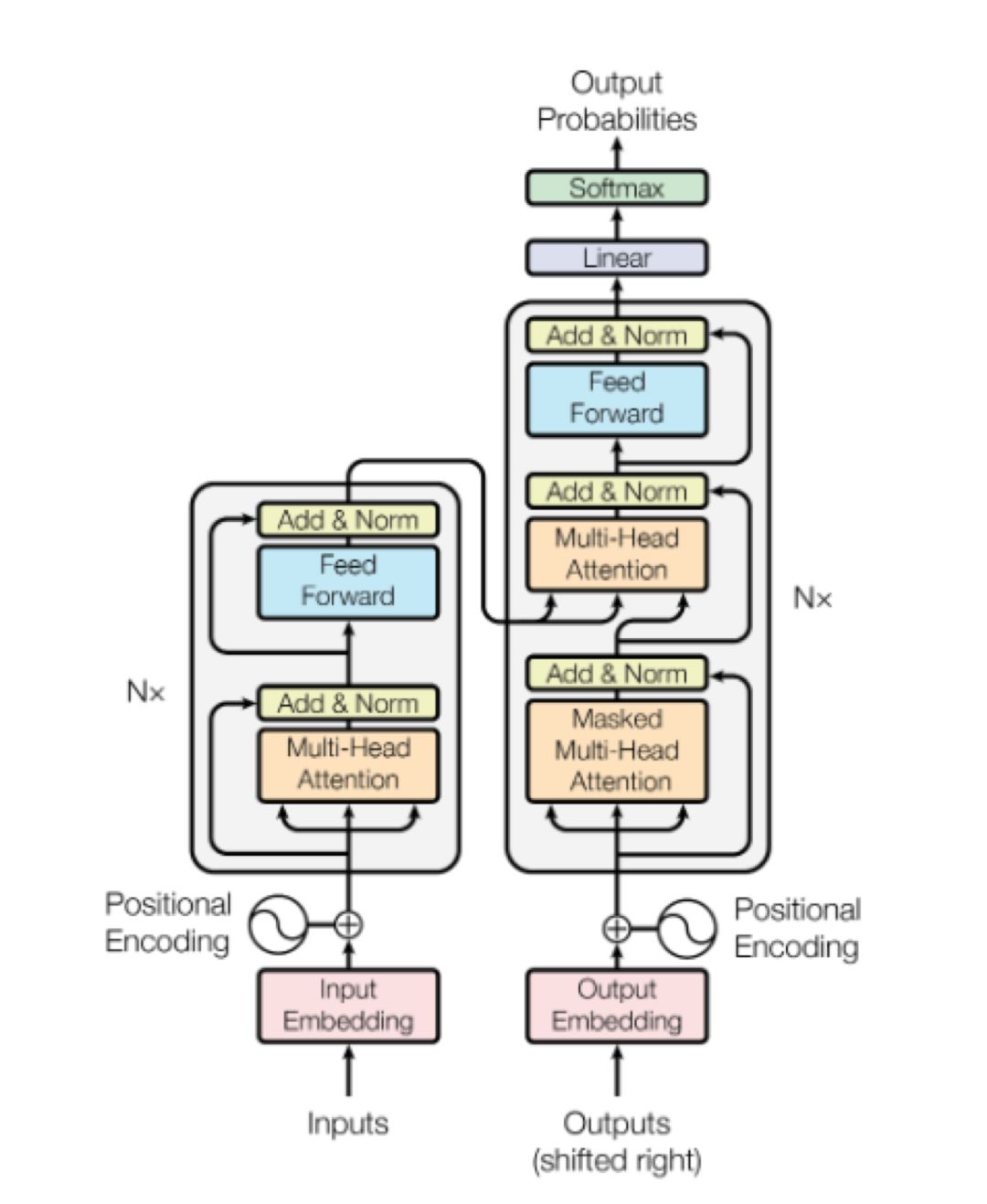
注意力机制即你所需(5059次引用)
使用增强学习的神经架构搜索(引用1186次)
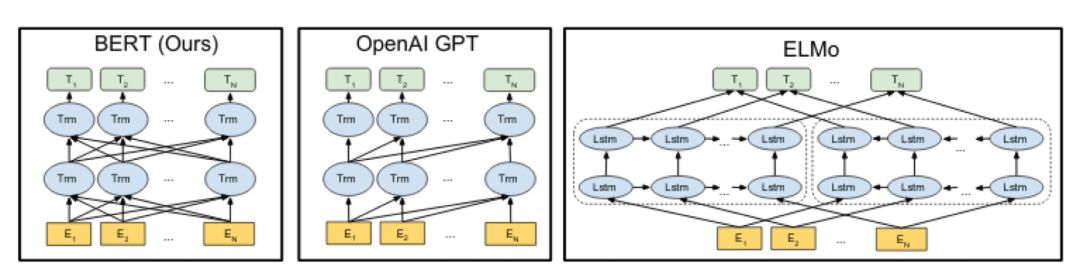
BERT:语言理解的深度双向转换器的预训练
-
深度语境化词语表征: 即前文提到的ELMo论文。ELMo是不是首个语境文本嵌入模型(contextual text embedding model)存在争议,但在实践中BERT更为流行。
-
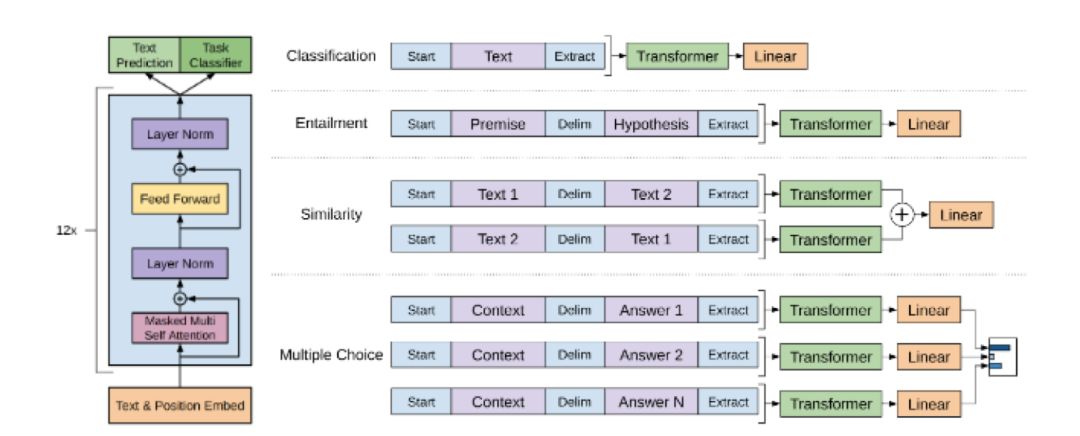
使用生成式预训练提高语言理解力 :即前文OpenAI发表的GPT论文。这篇文章深入研究了在多个不同类型问题中,使用相同预训练参数(仅简单微调)在下游任务中进行训练的想法。考虑到从头训练现代语言模型的高昂代价,这个方法非常具有说服力。
-
语言模型是无监督多任务学习者: GPT2,OpenAI的GPT模型后继者,很大程度上是GPT的扩展版本。它具有更多参数(高达15亿个),更多训练数据,更好的跨国测试困惑度。它的跨数据集泛化水平令人印象深刻,为超大网络泛化能力提供了进一步证据。但是,它的声望来自于强大的文本生成能力。我对文本生成有更深入的讨论,希望它有趣。GPT2的发布策略招致了一些批评,据称该策略的设计目的是为了最大化炒作。
-
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context:基于转换器的模型有固定的注意力长度,阻碍了对长文本语境的关注。通过关注来自于上一个注意力范围内的某些语境文本(为了计算可行没有传播梯度),来实现更长的有效注意力范围,Transformer-XL试图采用这种方式来解决这些问题。
-
XLNet: 语言理解的广义自回归预训练方法:XLNet以多种方式解决了BERT面临的“欺骗”难题。XLNet是单向的,但是利用转换器对输入顺序的内在不变性,令牌能按任意顺序变换。这使得网络能有效地双向工作,同时保持单向性的计算优势。XLNet也集成了Transformer-XL思想。
-
具有子词单元的罕见词的神经机器翻译 :更好的标记技术被认为是最近兴起的语言模型的核心内容。通过分段标记所有单词,这些技术消除了未登录词标记的可能性。
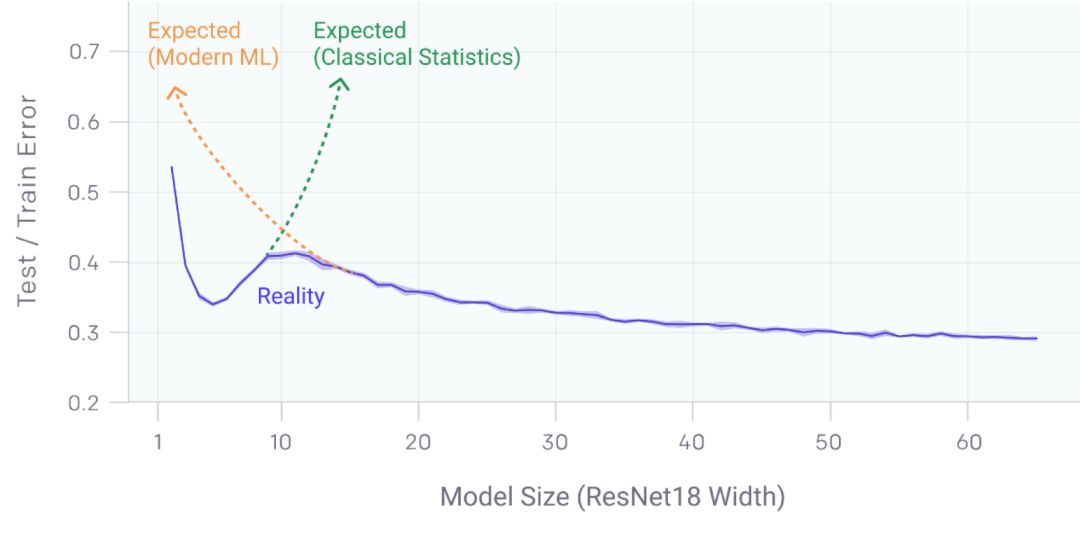
深度双波谷:更大的模型和更多的数据伤害了谁
彩票假说:发现稀疏可训练的神经网络
结论与未来展望
https://leogao.dev/2019/12/31/The-Decade-of-Deep-Learning/


实习/全职编辑记者招聘ing



以上是关于深度学习十年发展回顾:里程碑论文汇编的主要内容,如果未能解决你的问题,请参考以下文章