穷!深度学习中如何更好地利用显存资源?
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了穷!深度学习中如何更好地利用显存资源?相关的知识,希望对你有一定的参考价值。
-
默认使用显存自增长AutoGrowth策略,根据模型实际占用的显存大小, 按需自动分配显存 ,并且不影响训练速度。在模型实际占用显存不多的情况下,同一张GPU卡可以同时运行多个深度学习训练/预测任务。
-
支持限制任务的最大显存策略,每个任务只能在限定的显存量下运行, 实现同一张GPU卡多个任务间的显存隔离 。
-
默认使用Lazy显存分配方式。只有GPU卡工作时才自动分配显存, 实现不同GPU卡上的任务的相互隔离 ,可以在一台机器上实现更灵活的任务排布。
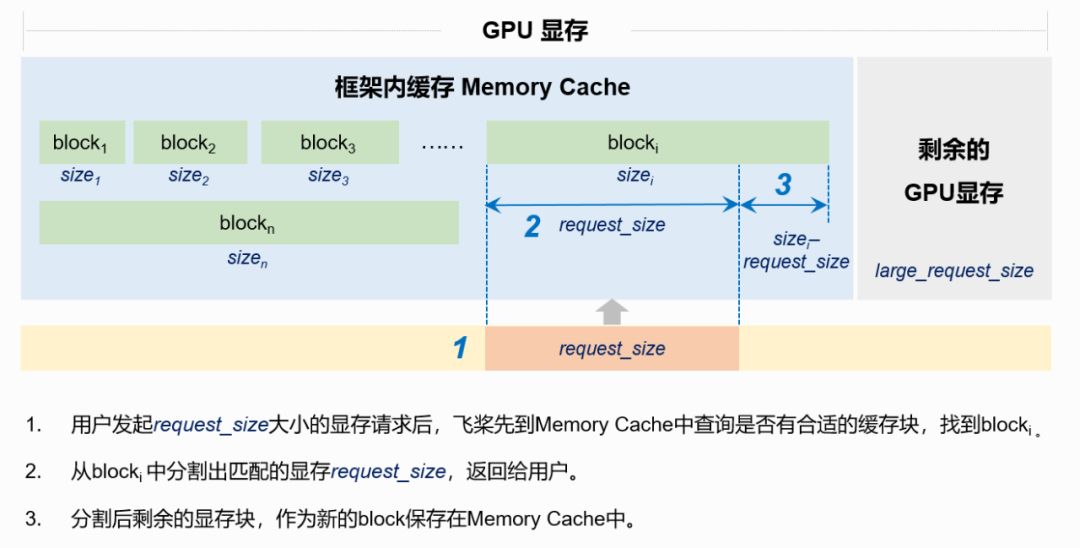
-
若Memory Cache为空,或者所有block均小于request_size,通过调用cudaMalloc从GPU中申请显存(对应图1中的large_request_size)。 -
若Memory Cache不为空,且存在大于等或者request_size大小的block,查找到满 足条件的最小block,从中分割出request_size大小的显存返回给用户。 -
显存释放时,释放的显存将存储到Memory Cache中,不再返回给GPU。
git clone -b release/1.7 https://github.com/PaddlePaddle/models.gitcd models/PaddleCV/image_classification
export CUDA_VISIBLE_DEVICES=0python train.py --model=ResNet50 --data_dir=./data/ILSVRC2012/ --batch_size=32
-
data_dir:设置ImageNet数据集的路径。 -
batch_size:设置batch_size为32。
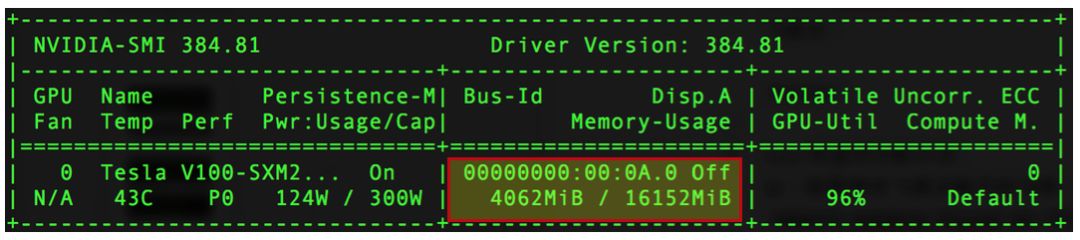
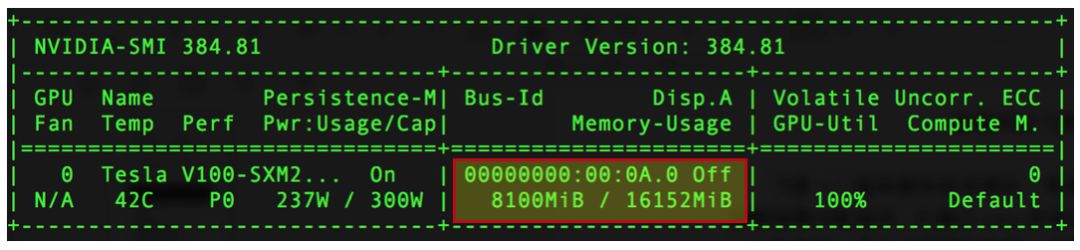
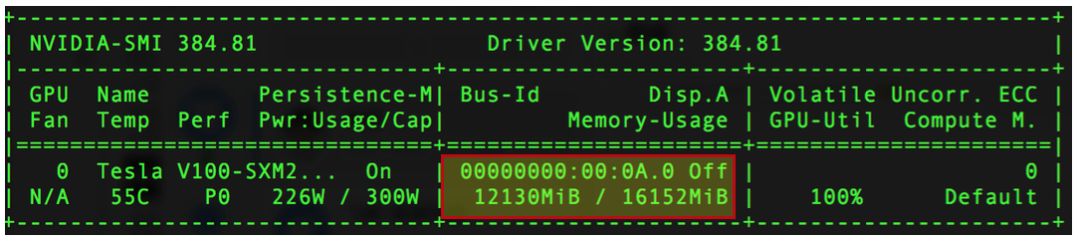
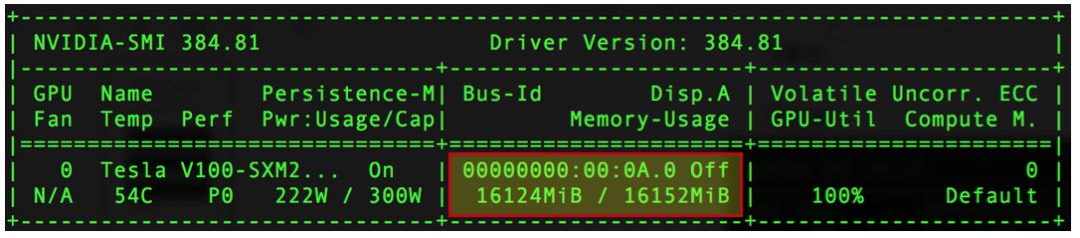
export FLAGS_gpu_memory_limit_mb=2048-
默认值为0,表示飞桨任务可以使用所有可用的显存资源,不设上限。 -
FLAGS_gpu_memory_limit_mb > 0,表示飞桨任务仅可使用不超过FLAGS_gpu_memory_limit_mb MB的显存。
import paddle.fluid as fluidimport numpy as np# 申请2G大小的Numpy数组two_gb_numpy_array = np.ndarray([2, 1024, 1024, 1024], dtype='uint8')place = fluid.CUDAPlace(0)t = fluid.Tensor()t.set(two_gb_numpy_array, place) # 将2G大小的Numpy数组拷贝到GPU上
-
若未设置FLAGS_gpu_memory_limit_mb,上述飞桨任务可正常运行,任务占用2048MB显存。 -
若设置了FLAGS_gpu_memory_limit_mb=1024,则会报出显存不足错误,如图2所示。表明任务使用的最大显存量被限定为1024MB。

import paddle.fluid as fluidimport numpy as npx = fluid.data(name='x', shape=[None, 784], dtype='float32')fc = fluid.layers.fc(x, size=10)loss = fluid.layers.reduce_mean(fc)sgd = fluid.optimizer.SGD(learning_rate=1e-3)sgd.minimize(loss)place = fluid.CUDAPlace(0) # 使用GPU 0卡进行训练exe = fluid.Executor(place)exe.run(fluid.default_startup_program())BATCH_SIZE = 32BATCH_NUM = 1000000for batch_id in range(BATCH_NUM):x_np = np.random.random([BATCH_SIZE, 784]).astype('float32')loss_np, = exe.run(fluid.default_main_program(),feed={x.name: x_np}, fetch_list=[loss])print('Batch id {}, loss {}'.format(batch_id, loss_np))
以上是关于穷!深度学习中如何更好地利用显存资源?的主要内容,如果未能解决你的问题,请参考以下文章