深度学习网络之RNN(递归神经网络)
Posted pytorch玩转深度学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习网络之RNN(递归神经网络)相关的知识,希望对你有一定的参考价值。
递归神经网络(recursive neural network)是具有树状阶层结构且网络节点按其连接顺序对输入信息进行递归的人工神经网络,是深度学习算法之一。
递归神经网络提出于1990年,被视为循环神经网络(recurrent neural network)的推广。当递归神经网络的每个父节点都仅与一个子节点连接时,其结构等价于全连接的循环神经网络。递归神经网络可以引入门控机制(gated mechanism)以学习长距离依赖。递归神经网络具有灵活的拓扑结构且权重共享,适用于包含结构关系的机器学习任务,在自然语言处理(Natural Language Processing, NLP)领域有重要应用。
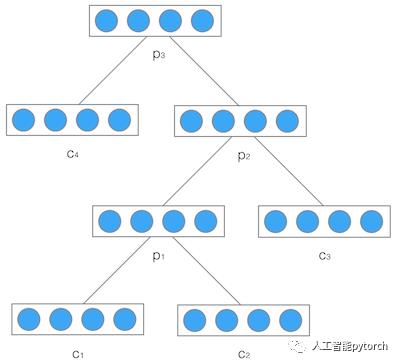
因为神经网络的输入层单元个数是固定的,因此必须用循环或者递归的方式来处理长度可变的输入。循环神经网络实现了前者,通过将长度不定的输入分割为等长度的小块,然后再依次的输入到网络中,从而实现了神经网络对变长输入的处理。一个典型的例子是,当我们处理一句话的时候,我们可以把一句话看作是词组成的序列,然后,每次向循环神经网络输入一个词,如此循环直至整句话输入完毕,循环神经网络将产生对应的输出。如此,我们就能处理任意长度的句子了。然而,有时候把句子看做是词的序列是不够的,比如下面这句话『两个外语学院的学生』:
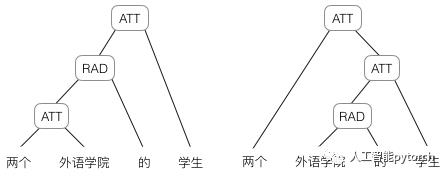
上图显示了这句话的两个不同的语法解析树。可以看出来这句话有歧义,不同的语法解析树则对应了不同的意思。一个是『两个外语学院的/学生』,也就是学生可能有许多,但他们来自于两所外语学校;另一个是『两个/外语学院的学生』,也就是只有两个学生,他们是外语学院的。为了能够让模型区分出两个不同的意思,我们的模型必须能够按照树结构去处理信息,而不是序列,这就是递归神经网络的作用。当面对按照树/图结构处理信息更有效的任务时,递归神经网络通常都会获得不错的结果。
递归神经网络可以把一个树/图结构信息编码为一个向量,也就是把信息映射到一个语义向量空间中。这个语义向量空间满足某类性质,比如语义相似的向量距离更近。也就是说,如果两句话(尽管内容不同)它的意思是相似的,那么把它们分别编码后的两个向量的距离也相近;反之,如果两句话的意思截然不同,那么编码后向量的距离则很远。如下图所示:
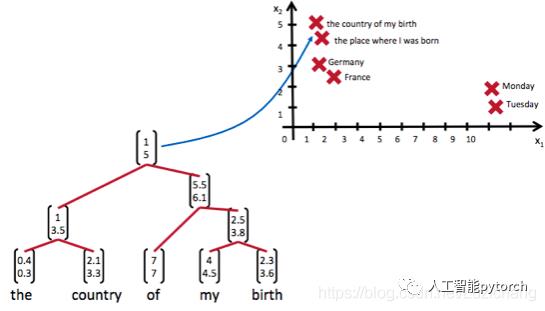
从上图我们可以看到,递归神经网络将所有的词、句都映射到一个2维向量空间中。句子『the country of my birth』和句子『the place where I was born』的意思是非常接近的,所以表示它们的两个向量在向量空间中的距离很近。另外两个词『Germany』和『France』因为表示的都是地点,它们的向量与上面两句话的向量的距离,就比另外两个表示时间的词『Monday』和『Tuesday』的向量的距离近得多。这样,通过向量的距离,就得到了一种语义的表示。
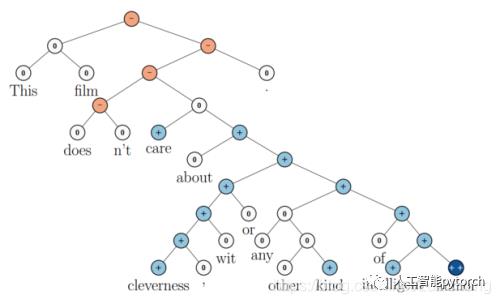
上图还显示了自然语言可组合的性质:词可以组成句、句可以组成段落、段落可以组成篇章,而更高层的语义取决于底层的语义以及它们的组合方式。递归神经网络是一种表示学习,它可以将词、句、段、篇按照他们的语义映射到同一个向量空间中,也就是把可组合(树/图结构)的信息表示为一个个有意义的向量。比如上面这个例子,递归神经网络把句子"the country of my birth"表示为二维向量[1,5]。有了这个『编码器』之后,我们就可以以这些有意义的向量为基础去完成更高级的任务(比如情感分析等)。如下图所示,递归神经网络在做情感分析时,可以比较好的处理否定句,这是胜过其他一些模型的。
在下图中,蓝色表示正面评价,红色表示负面评价。每个节点是一个向量,这个向量表达了以它为根的子树的情感评价。比如"intelligent humor"是正面评价,而"care about cleverness wit or any other kind of intelligent humor"是中性评价。我们可以看到,模型能够正确的处理doesn't的含义,将正面评价转变为负面评价。
计算
1前向计算
递归神经网络的输入是两个子节点(也可以是多个),输出就是将这两个子节点编码后产生的父节点,父节点的维度和每个子节点是相同的。如下图所示:
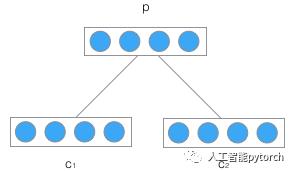
![]() 分别是表示两个子节点的向量,P是表示父节点的向量。子节点和父节点组成一个全连接神经网络,也就是子节点的每个神经元都和父节点的每个神经元两两相连。我们用矩阵W表示这些连接上的权重,它的维度将是d×2d ,其中,d 表示每个节点的维度。父节点的计算公式可以写成:
分别是表示两个子节点的向量,P是表示父节点的向量。子节点和父节点组成一个全连接神经网络,也就是子节点的每个神经元都和父节点的每个神经元两两相连。我们用矩阵W表示这些连接上的权重,它的维度将是d×2d ,其中,d 表示每个节点的维度。父节点的计算公式可以写成:
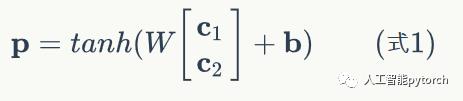
在上式中,tanh是激活函数(当然也可以用其它的激活函数),b 是偏置项,它也是一个维度为d 的向量。
然后,我们把产生的父节点的向量和其他子节点的向量再次作为网络的输入,再次产生它们的父节点。如此递归下去,直至整棵树处理完毕。最终,我们将得到根节点的向量,我们可以认为它是对整棵树的表示,这样我们就实现了把树映射为一个向量。在下图中,我们使用递归神经网络处理一棵树,最终得到的向量![]() ,就是对整棵树的表示:
,就是对整棵树的表示:
举个例子,我们使用递归神将网络将『两个外语学校的学生』映射为一个向量,如下图所示:
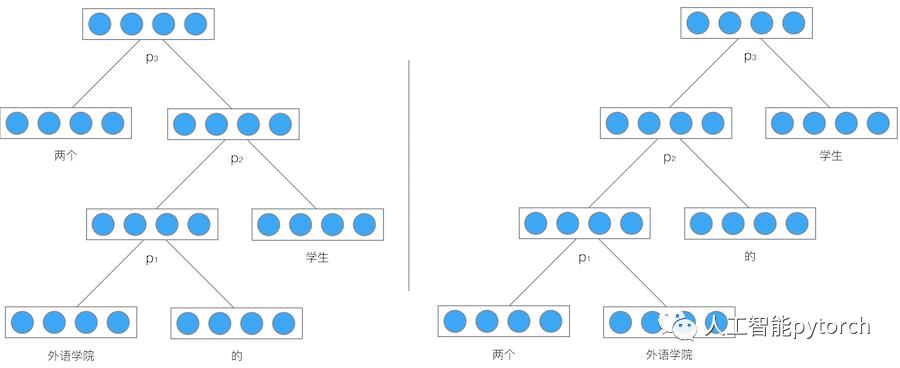
最后得到的向量![]() 就是对整个句子『两个外语学校的学生』的表示。由于整个结构是递归的,不仅仅是根节点,事实上每个节点都是以其为根的子树的表示。比如,在左边的这棵树中,向量
就是对整个句子『两个外语学校的学生』的表示。由于整个结构是递归的,不仅仅是根节点,事实上每个节点都是以其为根的子树的表示。比如,在左边的这棵树中,向量![]() 是短语『外语学院的学生』的表示,而向量
是短语『外语学院的学生』的表示,而向量![]() 是短语『外语学院的』的表示。
是短语『外语学院的』的表示。
式1就是递归神经网络的前向计算算法。它和全连接神经网络的计算没有什么区别,只是在输入的过程中需要根据输入的树结构依次输入每个子节点。需要特别注意的是,递归神经网络的权重和偏置项在所有的节点都是共享的。
2 训练
递归神经网络的训练算法和循环神经网络类似,两者不同之处在于,前者需要将残差δ 从根节点反向传播到各个子节点,而后者是将残差δ 从当前时刻![]() 反向传播到初始时刻
反向传播到初始时刻![]() 。
。
误差项的传递
首先,先推导将误差从父节点传递到子节点的公式,如下图:
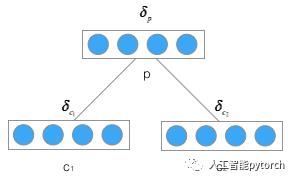




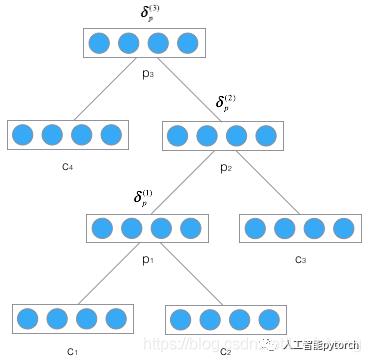
上图是在树型结构中反向传递误差项的全景图,反复应用式2,在已知![]() 的情况下,我们不难算出
的情况下,我们不难算出![]() 为:
为:
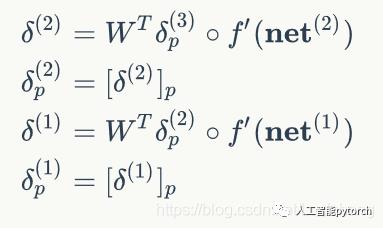
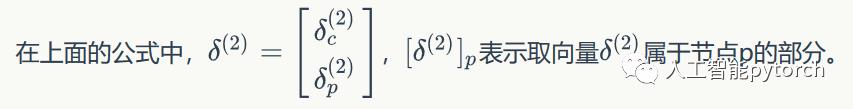
权重梯度的计算
根据加权输入的计算公式:


式3就是第l层权重项的梯度计算公式。我们知道,由于权重W是在所有层共享的,所以和循环神经网络一样,递归神经网络的最终的权重梯度是各个层权重梯度之和。即:
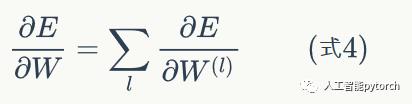

把上式扩展为矩阵的形式:
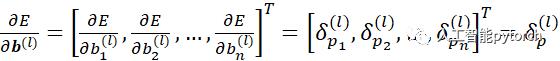 (式5)
(式5)
式5是第l层偏置项的梯度,那么最终的偏置项梯度是各个层偏置项梯度之和,即:
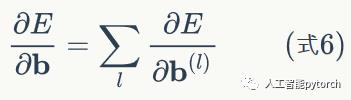

应用
自然语言和自然场景解析
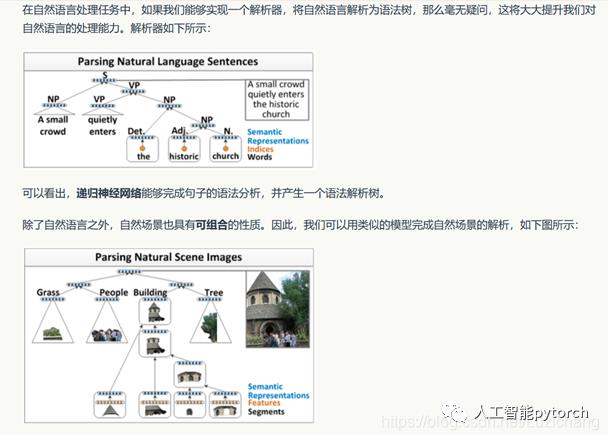
两种不同的场景,可以用相同的递归神经网络模型来实现。我们以第一个场景,自然语言解析为例。
我们希望将一句话逐字输入到神经网络中,然后,神经网络返回一个解析好的树。为了做到这一点,我们需要给神经网络再加上一层,负责打分。分数越高,说明两个子节点结合更加紧密,分数越低,说明两个子节点结合更松散。如下图所示:
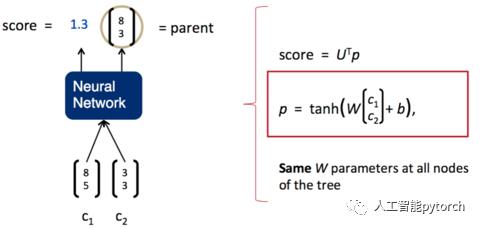
一旦这个打分函数训练好了(也就是矩阵U的各项值变为合适的值),我们就可以利用贪心算法来实现句子的解析(贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件。若下一个数据和部分最优解连在一起不再是可行解时,就不把该数据添加到部分解中,直到把所有数据枚举完,或者不能再添加算法停止)。第一步,我们先将词按照顺序两两输入神经网络,得到第一组打分:
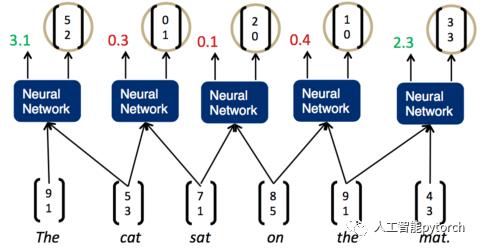
我们发现,现在分数最高的是第一组,The cat,说明它们的结合是最紧密的。这样,我们可以先将它们组合为一个节点。然后,再次两两计算相邻子节点的打分:
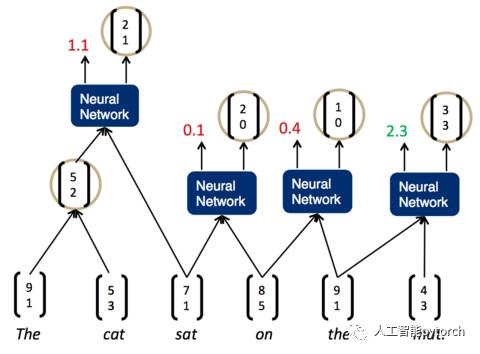
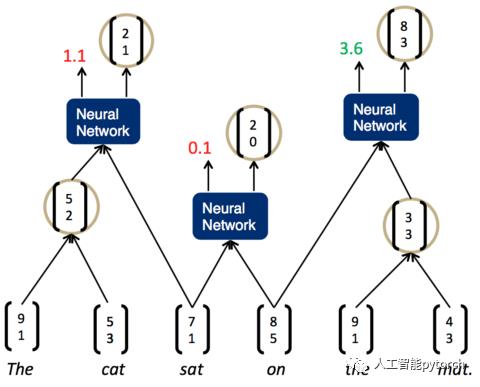
现在,分数最高的是最后一组,the mat。于是,我们将它们组合为一个节点,再两两计算相邻节点的打分。这时,我们发现最高的分数是on the mat,把它们组合为一个节点,继续两两计算相邻节点的打分......最终,我们就能够得到整个解析树:
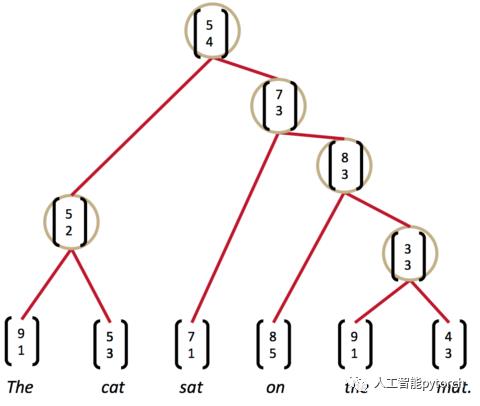
以上是关于深度学习网络之RNN(递归神经网络)的主要内容,如果未能解决你的问题,请参考以下文章