飞桨开源框架2.0,带你走进全新高层API,十行代码搞定深度学习模型开发
Posted 飞桨PaddlePaddle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞桨开源框架2.0,带你走进全新高层API,十行代码搞定深度学习模型开发相关的知识,希望对你有一定的参考价值。
深度学习作为人工智能时代的核心技术,近年来无论学术、还是工业领域,均发挥着愈加重要的作用。而对于深度学习项目开发来说,选择使用哪个框架非常重要,一个合适的框架往往能起到事半功倍的作用。百度飞桨作为行业的领军者,为了进一步降低深度学习的学习门槛,提升开发效率,推出高层API。此API具有高低融合、科学统一、完备易用、兼容历史版本四大特点,更贴近开发者的使用习惯,可谓是实现了真正意义上的快速上手,友好开发。
高层API,Why

什么是高层API

高层API的特点
高层API全景图

import paddle
from paddle.vision.transforms
import Compose, Normalize
from paddle.vision.datasets
import MNIST
import paddle.nn
as nn
# 数据预处理,这里用到了归一化
transform = Compose([Normalize(mean=[
127.5],
std=[
127.5],
data_format=
'CHW')])
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = paddle.vision.datasets.MNIST(mode=
'train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode=
'test', transform=transform)
# 模型组网
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(
784,
512),
nn.ReLU(),
nn.Dropout(
0.2),
nn.Linear(
512,
10)
)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 模型训练,
model.fit(train_dataset,
epochs=
10,
batch_size=
64,
verbose=
1)
# 模型评估,
model.evaluate(test_dataset, verbose=
1)
# 模型保存,
model.save(
'model_path')

高层API详解
数据预处理与数据加载
-
飞桨框架内置数据集:paddle.vision.datasets内置包含了许多CV领域相关的数据集,直接调用API即可使用; -
飞桨框架数据预处理:paddle.vision.transforms飞桨框架对于图像预处理的方式,可以快速完成常见的图像预处理的方式,如调整色调、对比度,图像大小等; -
飞桨框架数据加载:paddle.io.Dataset与paddle.io.DataLoader飞桨框架标准数据加载方式,可以”一键”完成数据的批加载与异步加载;

from paddle.io
import Dataset
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
if mode ==
'train':
self.data = [
[
'traindata1',
'label1'],
[
'traindata2',
'label2'],
[
'traindata3',
'label3'],
[
'traindata4',
'label4'],
]
else:
self.data = [
[
'testdata1',
'label1'],
[
'testdata2',
'label2'],
[
'testdata3',
'label3'],
[
'testdata4',
'label4'],
]
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = self.data[index][
0]
label = self.data[index][
1]
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
# 测试定义的数据集
train_dataset = MyDataset(mode=
'train')
val_dataset = MyDataset(mode=
'test')
print(
'=============train dataset=============')
for data, label
in train_dataset:
print(data, label)
print(
'=============evaluation dataset=============')
for data, label
in val_dataset:
print(data, label)
网络构建
对于组网方式,飞桨框架统一支持 Sequential 或 SubClass 的方式进行模型的组建。我们根据实际的使用场景,来选择最合适的组网方式。如针对顺序的线性网络结构我们可以直接使用 Sequential ,相比于 SubClass ,Sequential 可以快速的完成组网。
# Sequential形式组网
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
# SubClass方式组网
class Mnist(nn.Layer):
def __init__(self):
super(Mnist,
self).__init_
_()
self.flatten = nn.Flatten()
self.linear_1 = nn.Linear(
784,
512)
self.linear_2 = nn.Linear(
512,
10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(
0.
2)
def forward(self, inputs):
y =
self.flatten(inputs)
y =
self.linear_1(y)
y =
self.relu(y)
y =
self.dropout(y)
y =
self.linear_2(y)
return y
模型训练
# 将网络结构用 Model类封装成为模型
model = paddle.Model(mnist)
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=10,
batch_size=64,
verbose=1)
# 启动模型评估,指定数据集,设置日志格式
model.evaluate(test_dataset, verbose=1)
# 启动模型测试,指定测试集
Model.predict(test_dataset)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=
64, shuffle=
True)
# 使用train_batch 完成训练
for batch_id, data
in enumerate(train_loader()):
model.train_batch([data[
0]],[data[
1]])
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), batch_size=
64, shuffle=
True)
# 使用 eval_batch 完成验证
for batch_id, data
in enumerate(test_loader()):
model.eval_batch([data[
0]],[data[
1]])
# 使用 predict_batch 完成预测
for batch_id, data
in enumerate(test_loader()):
model.predict_batch([data[
0]])
高阶用法
class SelfDefineLoss(paddle.nn.Layer):
"""
1. 继承paddle.nn.Layer
"""
def __init__(self):
"""
2. 构造函数根据自己的实际算法需求和使用需求进行参数定义即可
"""
super(SelfDefineLoss, self).__init__()
def forward(self, input, label):
"""
3. 实现forward函数,forward在调用时会传递两个参数:input和label
- input:单个或批次训练数据经过模型前向计算输出结果
- label:单个或批次训练数据对应的标签数据
接口返回值是一个Tensor,根据自定义的逻辑加和或计算均值后的损失
"""
# 使用Paddle中相关API自定义的计算逻辑
# output = xxxxx
# return output
class SoftmaxWithCrossEntropy(paddle.nn.Layer):
def __init__(self):
super(SoftmaxWithCrossEntropy,
self).__init_
_()
def forward(self, input, label):
loss = F.softmax_with_cross_entropy(input,
label,
return_softmax=False,
axis=
1)
return paddle.mean(loss)
# 自定义Callback 记录训练过程中的loss信息
class LossCallback(paddle.callbacks.Callback):
def on_train_begin(self, logs={}):
# 在fit前 初始化losses,用于保存每个batch的loss结果
self.losses = []
def on_train_batch_end(self, step, logs={}):
# 每个batch训练完成后调用,把当前loss添加到losses中
self.losses.append(logs.get(
'loss'))
# 初始化一个loss_log 的实例,然后将其作为参数传递给fit
loss_log = LossCallback()
model.fit(train_dataset,
epochs=
10,
batch_size=
64,
callbacks=loss_log,
verbose=
1)
# loss信息都保存在 loss_log.losses 中,可视化后得到下图
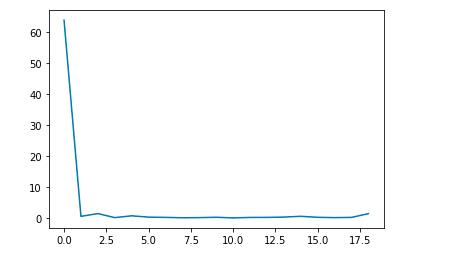
模型可视化
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
# 模型封装,用Model类封装
model = paddle.Model(mnist)
model.summary()
---------------------------------------------------------------------------
Layer (
type) Input Shape Output Shape Param #
===========================================================================
Flatten
-795
[[32, 1, 28, 28]] [
32,
784]
0
Linear
-5
[[32, 784]] [
32,
512]
401,
920
ReLU
-3
[[32, 512]] [
32,
512]
0
Dropout
-3
[[32, 512]] [
32,
512]
0
Linear
-6
[[32, 512]] [
32,
10]
5,
130
===========================================================================
Total params:
407,
050
Trainable params:
407,
050
Non-trainable params:
0
---------------------------------------------------------------------------
Input size (MB):
0.10
Forward/backward pass size (MB):
0.57
Params size (MB):
1.55
Estimated Total Size (MB):
2.22
---------------------------------------------------------------------------
{
'total_params':
407050,
'trainable_params':
407050}
总结一下
体验一把
# CPU版
$ pip3 install paddlepaddle==
2.0.0rc0
-i https:
//mirror.baidu.com/pypi/simple
# GPU版
$ pip3 install paddlepaddle_gpu==
2.0.0rc0 -i https:
//mirror.baidu.com/pypi/simple
写在最后
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
以上是关于飞桨开源框架2.0,带你走进全新高层API,十行代码搞定深度学习模型开发的主要内容,如果未能解决你的问题,请参考以下文章