第一个MapReduce程序——WordCount
Posted 数据分析与商业智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一个MapReduce程序——WordCount相关的知识,希望对你有一定的参考价值。
通常我们在学习一门语言的时候,写的第一个程序就是Hello World。而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序。
一、MapReduce简介
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:
JobTracker用于调度工作的,一个Hadoop集群中只有一个JobTracker,位于master。
TaskTracker用于执行工作,位于各slave上。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。
map:
(K1, V1)——>list(K2, V2)reduce:
(K2, list(V2))——>list(K3, V3)
如下图所示:
二、运行WordCount程序
在运行程序之前,需要先搭建好Hadoop集群环境,参考《Hadoop+HBase+ZooKeeper分布式集群环境搭建》。
2.1 源代码
WordCount可以说是最简单的MapReduce程序了,只包含三个文件:一个 Map 的 Java 文件,一个 Reduce 的 Java 文件,一个负责调用的主程序 Java 文件。
我们在当前用户的主文件夹下创建wordcount_01/目录,在该目录下再创建src/和classes/。 src 目录存放 Java 的源代码,classes 目录存放编译结果。
TokenizerMapper.java
1 |
package com.lisong.hadoop; |
IntSumReducer.java
1 |
package com.lisong.hadoop; |
WordCount.java
1 |
package com.lisong.hadoop; |
以上三个.java源文件均置于 src 目录下。
2.2 编译
Hadoop 2.x 版本中jar不再集中在一个 hadoop-core-*.jar 中,而是分成多个 jar。编译WordCount程序需要如下三个 jar:
1 |
$HADOOP_HOME/share/hadoop/common/hadoop-common-2.4.1.jar |
使用javac命令进行编译:
1 |
$ cd wordcount_01 |
-classpath,设置源代码里使用的各种类库所在的路径,多个路径用
":"隔开。-d,设置编译后的 class 文件保存的路径。
src/*.java,待编译的源文件。
2.3 打包
将编译好的 class 文件打包成 Jar 包,jar 命令是 JDK 的打包命令行工具。
1 |
$ jar -cvf wordcount.jar classes |
打包结果是 wordcount.jar 文件,放在当前目录下。
2.4 执行
执行hadoop程序的时候,输入文件必须先放入hdfs文件系统中,不能是本地文件。
1 . 先查看hdfs文件系统的根目录:
1 |
$ hadoop/bin/hadoop fs -ls / |
可以看出,hdfs的根目录是一个叫/hbase的目录。
2 . 然后利用put将输入文件(多个输入文件位于input文件夹下)复制到hdfs文件系统中:
1 |
$ hadoop/bin/hadoop fs -put input /hbase |
3 . 运行wordcount程序
1 |
$ hadoop/bin/hadoop jar wordcount_01/wordcount.jar WordCount /hbase/input /hbase/output |
提示找不到 WordCount 类:Exception in thread "main" java.lang.NoClassDefFoundError: WordCount…
因为程序中声明了 package ,所以在命令中也要 com.lisong.hadoop.WordCount 写完整:
1 |
$ hadoop/bin/hadoop jar wordcount_01/wordcount.jar com.lisong.hadoop.WordCount /hbase/input /hbase/output |
其中 “jar” 参数是指定 jar 包的位置,com.lisong.hadoop.WordCount 是主类。运行程序处理 input 目录下的多个文件,将结果写入 /hbase/output 目录。
4 . 查看运行结果
1 |
$ hadoop/bin/hadoop fs -ls /hbase/output |
可以看到/hbase/output/目录下有两个文件,结果就存在part-r-00000中:
1 |
$ hadoop/bin/hadoop fs -cat /hbase/output/part-r-00000 |
三、WordCount程序分析
3.1 Hadoop数据类型
Hadoop MapReduce操作的是键值对,但这些键值对并不是Integer、String等标准的Java类型。为了让键值对可以在集群上移动,Hadoop提供了一些实现了WritableComparable接口的基本数据类型,以便用这些类型定义的数据可以被序列化进行网络传输、文件存储与大小比较。
值:仅会被简单的传递,必须实现
Writable或WritableComparable接口。键:在Reduce阶段排序时需要进行比较,故只能实现
WritableComparable接口。
下面是8个预定义的Hadoop基本数据类型,它们均实现了WritableComparable接口:
| 类 | 描述 |
|---|---|
| BooleanWritable | 标准布尔型数值 |
| ByteWritable | 单字节数值 |
| DoubleWritable | 双字节数 |
| FloatWritable | 浮点数 |
| IntWritable | 整型数 |
| LongWritable | 长整型数 |
| Text | 使用UTF8格式存储的文本 |
| NullWritable | 当<key,value>中的key或value为空时使用 |
3.2 源代码分析
3.2.1 Map过程
1 |
package com.lisong.hadoop; |
Map过程需要继承org.apache.hadoop.mapreduce包中 Mapper 类,并重写其map方法。
1 |
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> |
其中的模板参数:第一个Object表示输入key的类型;第二个Text表示输入value的类型;第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型。
注:StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分——默认情况下使用空格作为分隔符进行分割。
3.2.2 Reduce过程
1 |
package com.lisong.hadoop; |
Reduce过程需要继承org.apache.hadoop.mapreduce包中 Reducer 类,并 重写 reduce方法。
1 |
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> |
其中模板参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型。
1 |
public void reduce(Text key, Iterable<IntWritable> values, Context context) |
reduce 方法的输入参数 key 为单个单词,而 values 是由各Mapper上对应单词的计数值所组成的列表(一个实现了 Iterable 接口的变量,可以理解成 values 里包含若干个 IntWritable 整数,可以通过迭代的方式遍历所有的值),所以只要遍历 values 并求和,即可得到某个单词出现的总次数。
3.2.3 执行作业
1 |
package com.lisong.hadoop; |
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置,此处:
设置了使用
TokenizerMapper.class完成Map过程中的处理,使用IntSumReducer.class完成Combine和Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。
任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。
FileInputFormat类的很重要的作用就是将文件进行切分 split,并将 split 进一步拆分成key/value对
FileOutputFormat类的作用是将处理结果写入输出文件。
完成相应任务的参数设定后,即可调用
job.waitForCompletion()方法执行任务。
3.2.4 WordCount流程
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,key为偏移量(包括了回车符),value为文本行。这一步由MapReduce框架自动完成,如下图:
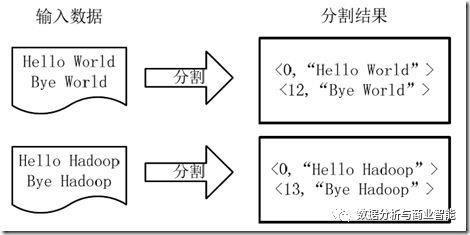
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示:
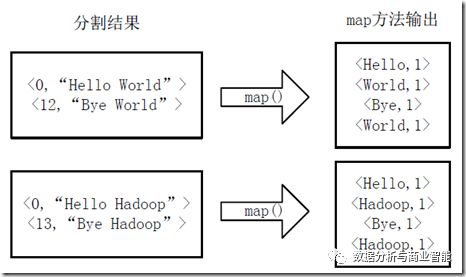
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果。如下图:
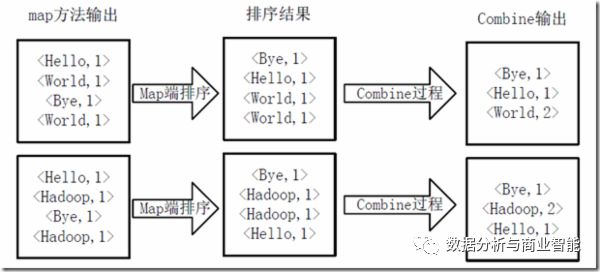
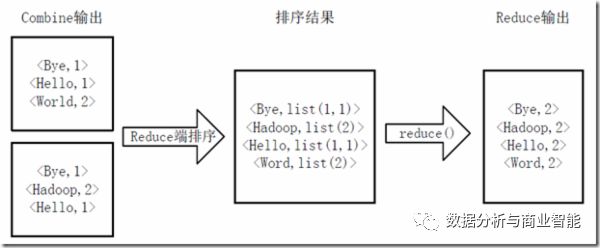
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图:
MuMu
关注
以上是关于第一个MapReduce程序——WordCount的主要内容,如果未能解决你的问题,请参考以下文章
2.3 基于IDEA开发第一个MapReduce大数据程序WordCount