成功运行第一个MapReduce任务
Posted 核点点
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了成功运行第一个MapReduce任务相关的知识,希望对你有一定的参考价值。
在开始说MapReduce之前,应该先了解一下hadoop,在安装完成hadoop的程序时,MapReduce组件作为hadoop的一部分也随之进行安装。
hadoop是一个开源的大数据操作系统。
为了执行MapReduce任务,需要以下必要步骤:
1,安装hadoop的集群
hadoop的集群,可以是单节点,如果条件比较好的话,可以多搞几个节点组成完全分布式的集群。如果只有一台电脑,那么可以选择单机模式或者伪分布模式。
我在安装hadoop的过程中,进行过多种尝试。分别在fedora22、Centos6.7、Centos7、Ubuntu16.04的操作系统中安装过,是在hadoop发布2.9.0版时开始,得到结论如下:
| 操作系统 | 支持情况(hadoop 2.9) |
| Fedora 22 | 支持 |
| Centos 6.7 | 支持,但需要额外解决一些问题 |
| Centos 7 | 支持 |
| Ubuntu 16.04 | 支持 |
下面介绍一下安装hadoop的关键步骤。
电脑的内存在4G以上,多核cpu。
配置无密钥登录。对于伪分布式和完全分布式都需要配置好无密钥登录,大致过程是在节点上新建用户had,密码统一为root,在节点上使用had登录,在had根目录执行ssh-keygen –t rsa,将生成的id_rsa.pub公钥内容合并为一个文件:authorized_keys,然后将这个文件复制到各个hadoop节点的/home/had/.ssh目录下。
配置jdk运行环境。下载jdk文件,解压缩到/usr/lib/jdk目录下。配置一些必要的环境变量,直到可以在终端执行java命令,而不同的操作系统在配置环境变量是有轻微的差异,需要检查清楚。
安装hadoop程序。到apache项目网站下载对应版本的hadoop已经编译好的压缩包。解压缩在系统工作目录下,再配置一些环境变量。此时可以在终端执行命令hadoop version查看hadoop的信息,如果正常显示相应的版本信息,则表示hadoop安装成功。
配置hadoop。仅仅是安装了主程序是不够的,还需要进行一些必要的配置,这些配置文件在hadoop目录下的etc/hadoop中,主要配置其中的4个文件,分别是:
core-site.xml,
hdfs-site.xml,
mapred-site.xml,
yarn-site.xml,
相应的配置项最好通过查看文档来确定,因为不是每个人的节点配置是完全一样的。
最后,需要执行hadoop文件系统格式化。我这里是按照伪分布模式来安装的,因此在终端执行
hdfs namenode –format,
等待格式化完成,那么就可以启动hadoop了。
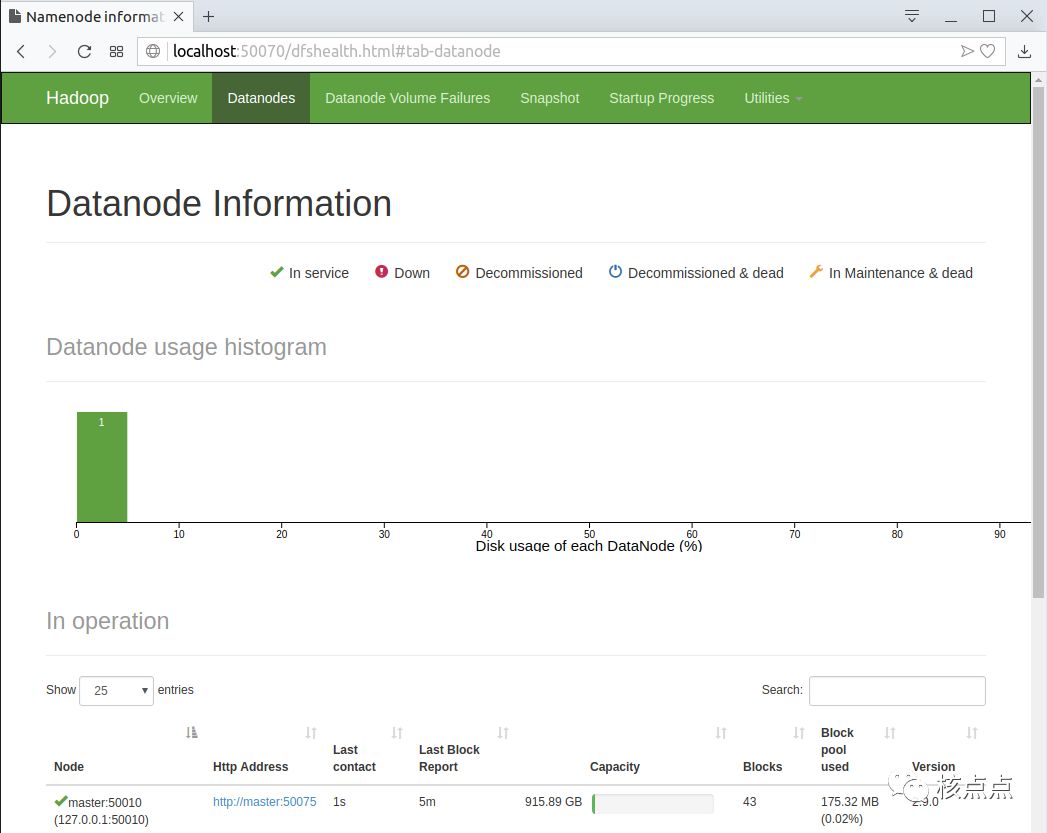
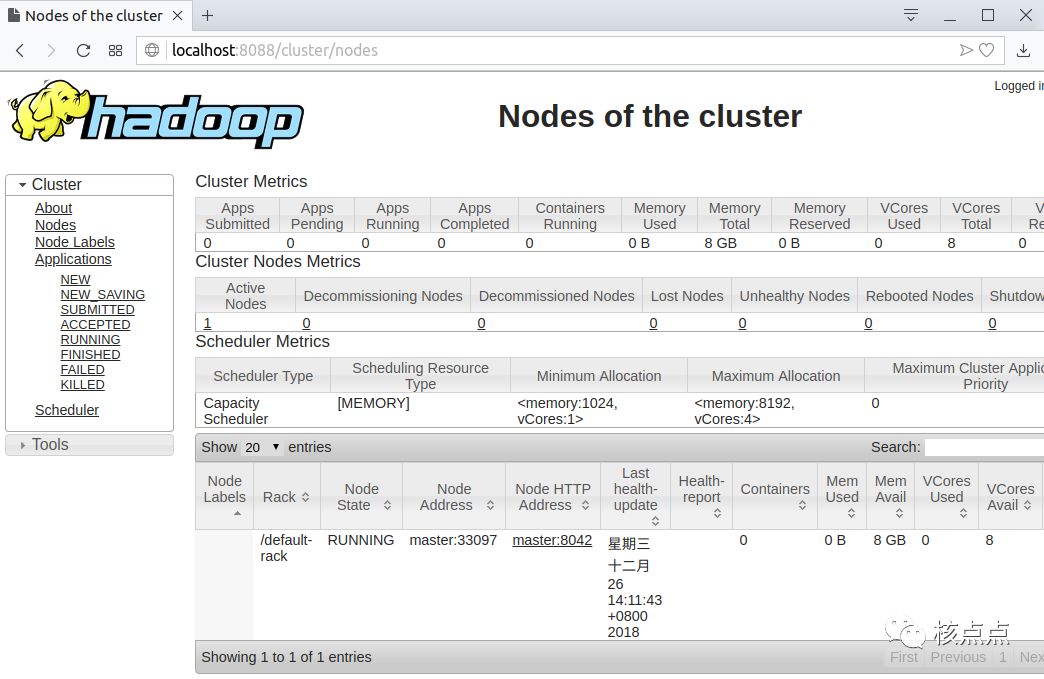
在hadoop启动完成之后,可以通过web页面查看hdfs节点存储情况以及mapreduce程序的执行情况。网址分别是:
http://localhost:50070
http://localhost:8088
不得不提醒,安装hadoop需要踩不少的坑,自己在实践的过程中要学会遇到问题解决问题。
2,开发MapReduce程序
我这里是使用idea作为IDE编辑器,idea中配置hadoop的开发环境另外再介绍,也可以自行百度,我的知识也来自各大搜索引擎。
这里预先下载了两个专利的数据集,一个文件大概在250M左右。
另外写了两个MapReduce的程序。
一个是统计某个专利被哪些引用过,

另一个程序是统计某个专利被引用的次数。
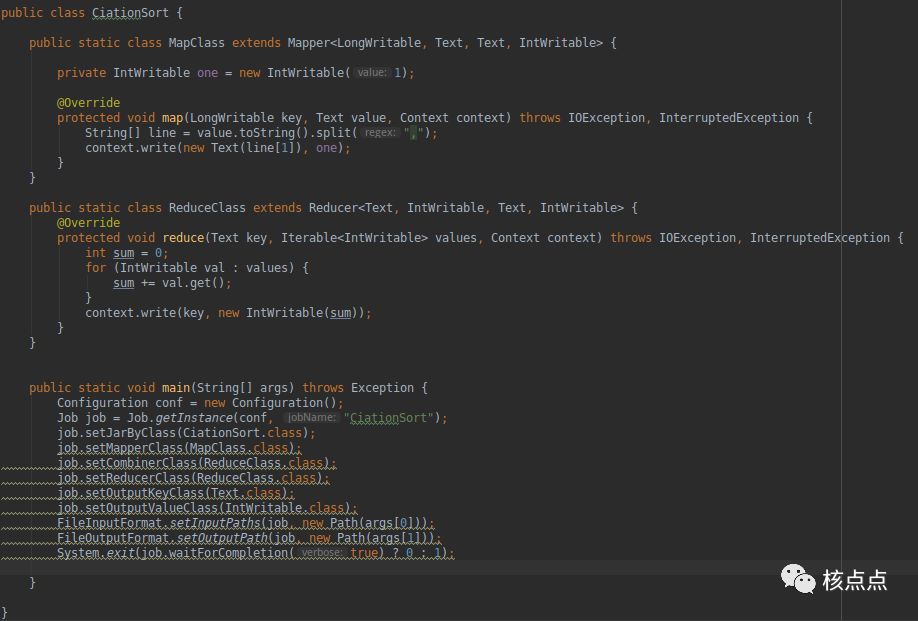
MapReduce程序开发还需要专门学习,这部分的课程需要补上。
3,运行MapReduce程序
可以直接在IDE工具界面执行编写的mapreduce程序,这样输入的数据集和计算完成输出的结果都会存在项目文档里,操作起来要方便许多。
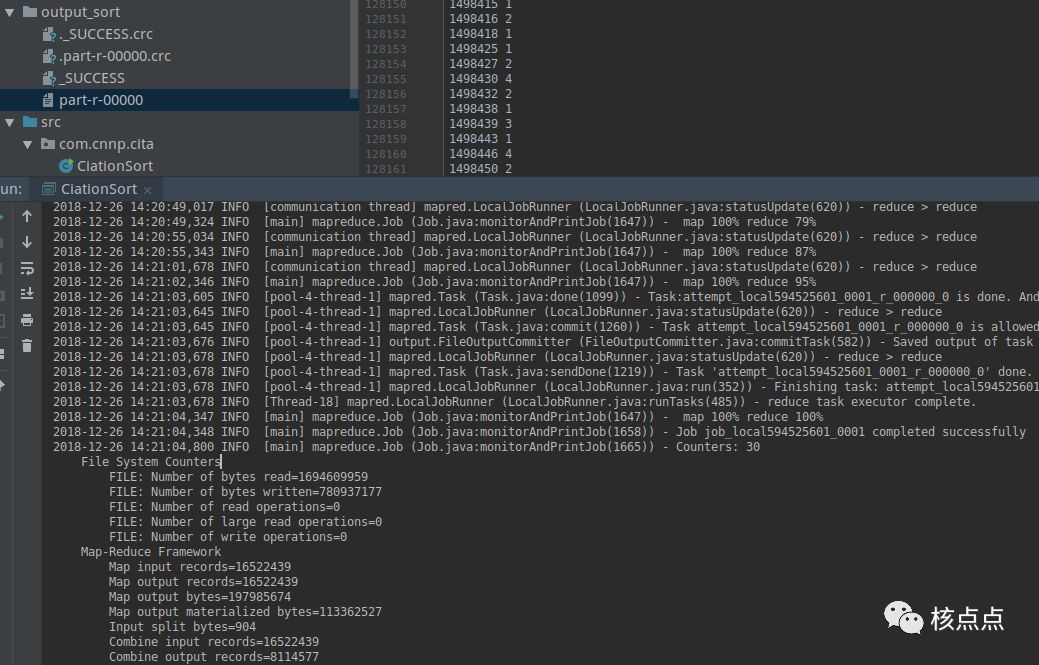
也可以将程序导出为jar包,使用hadoop jar命令来执行,这种方式需要先将数据集文件上传到hdfs里。

上图中的/cite75_99.txt是通过
hadoop fs -put
命令从本地上传到hdfs的根目录的,对应的查看计算结果也需要使用
hdaoop fs -cat
命令查看,我这里直接使用-tail -f 显示少量行数据。

从结果中可以看到999579号专利被引用了3次。
使用hadoop jar命令执行MR时,可以方便的通过web页面查看每个任务使用系统资源情况,以及各个MR任务的进度情况。
4,总结
执行一个MapReduce 的任务,需要大致经过上述过程,
准备hadoop环境、
编写MapReduce代码、
执行代码,查看结果。
既然没有一个专门的老师来教,那么就需要自己多看书,多查找资料,多动手练习。完整的学习过程下来的话,相信会对linux、java以及hadoop的相应知识有非常好的掌握。
还要注意到,每次都编写mapreduce的代码,经过不同的MR任务可以连接,但是仍然感觉不是很方便。因此,还需要继续学习hadoop的其他组件。
以上是关于成功运行第一个MapReduce任务的主要内容,如果未能解决你的问题,请参考以下文章