你应该知道Tez比MapReduce好用
Posted 大数据修行直通车
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你应该知道Tez比MapReduce好用相关的知识,希望对你有一定的参考价值。

1、什么是Tez?
Tez是Hontonworks开源的支持DAG作业的计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升MapReduce作业的性能。Tez并不直接面向最终用户,事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。
2、TEZ引擎特性
根据Apache TEZ官网的介绍,主要有以下几个新特性:
任务抢占,即可通过资源抢占的方式,让优先级更高的任务优先运行。
任务执行断点检查。通过对任务执行过程记录断点,可在任务失败时从断点恢复运行,以避免任务重算。这个功能实现的难度不小,就从当前YARN的设计架构而言,只能做到已经完成的任务不重新计算,对于正在运行的任务需要重新开始计算。
Container重用
首先理解一下概念:Container也就是容器,容器中封装了大数据机器资源,如内存,CPU,磁盘,网络等,每个任务(Task)会被分配一个容器,该任务只能在该容器中执行,并使用该容器封装的资源。重用主要涉及两个方面:一方面,同一个应用程序的多个任务可重用一个Container,该功能是一个非常重要的Feature,这样就不会像MR频繁的申请导致执行时间变长。另一方面,不同应用程序的Container重用,即不同应用程序的多个任务可重用一个Container。
3、Tez和MapReduce哪个好用
先说结论:Tez比MR好太多,至少快5倍
【基于MR的Job】
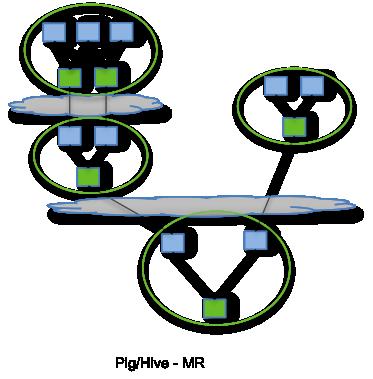
在YARN中,每个作业的AM会先向RM申请资源(Container),申请到资源之后开始运行作业,作业处理完成后释放资源,期间没有资源重新利用的环节。这样会使作业大大的延迟。
基于MR的Hive/Pig的DAG数据流处理过程”,可以看出图中的每一节点都是把结果写到一个中间存储(HDFS/S3)中,下个节点从中间存储读取数据,再来继续接下来的计算。可见中间存储的读写性能对整个DAG的性能影响是很大的。
【基于Tez的Job】
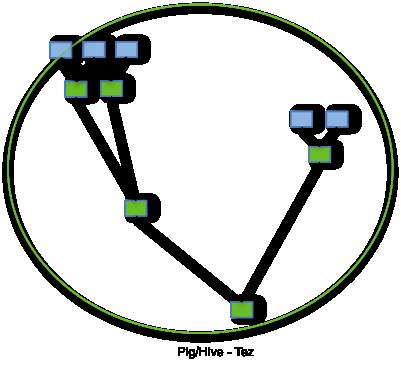
使用Tez后,yarn的作业不是先提交给RM了,而是提交给AMPS。
AMPS在启动后,会预先创建若干个AM,作为AM资源池,当作业被提交到AMPS的时候,AMPS会把该作业直接提交到AM上,这样就避免每个作业都创建独立的AM,大大的提高了效率。
AM缓冲池中的每个AM在启动时都会预先创建若干个container,以此来减少因创建container所话费的时间。每个任务运行完之后,AM不会立马释放Container,而是将它分配给其它未执行的任务。
【Tez实操】
网上安装Tez的资料简直能眼膜人,就不在这里赘述了,学会google。
安装好Tez之后启动hive,随意写一个sql即可
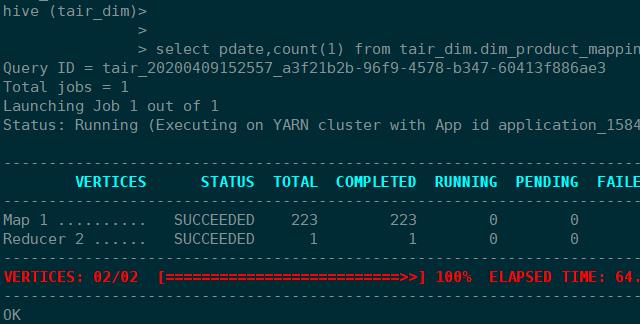
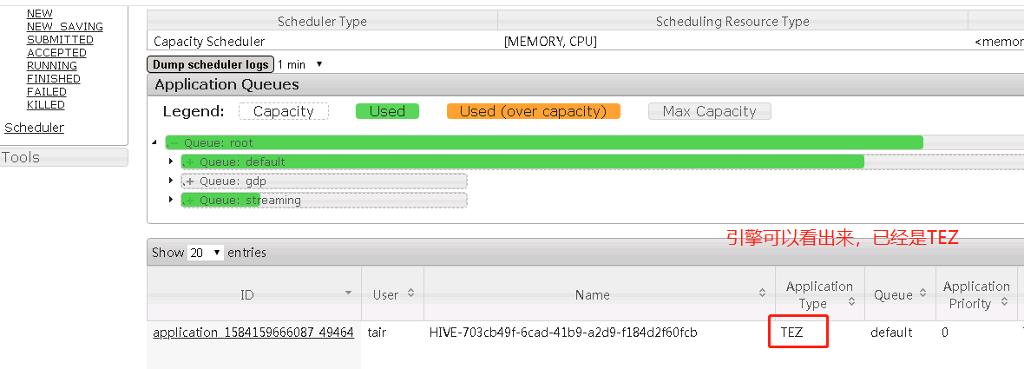
打开web端查看任务,如下图所示,可以看出引擎已经变成了Tez。
总结
MR计算,会对磁盘进行多次的读写操作,这样启动多轮job的代价略有些大,不仅占用资源,更耗费大量的时间。
采用TEZ计算框架,就会生成一个简洁的DAG作业,算子跑完不退出,下轮继续使用上一轮的算子,这样大大减少磁盘IO操作,从而计算速度更快。
TEZ比MR至少快5倍。
个人心得
-
TEZ执行引擎的问世,可以帮助我们解决现有MR框架的一些不足,另外,TEZ是基于YARN的,所以可以与原有的MR共存,不会相互冲突。 -
工作中,我们只需在hadoop-env.sh文件中配置TEZ的环境变量,并在mapred-site.xml设置执行作业的架构为yarn-tez,这样在YARN上运行的作业就会跑TEZ计算模式,所以原有的系统接入TEZ很便捷。
PS: 另外,笔者刚建了个学习交流群,禁广告、推广,大家有啥问题也可以在群里提问,有需要的小伙伴可以加一下~
加群方式 - 扫描下方 以上是关于你应该知道Tez比MapReduce好用的主要内容,如果未能解决你的问题,请参考以下文章