大数据的灵魂(下):MapReduce
Posted 大数据weekly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据的灵魂(下):MapReduce相关的知识,希望对你有一定的参考价值。
上一章我们讲了大数据的灵魂之一,HDFS。我们已经知道大数据是如何存储的了,那么这一章我们将要看看大数据存储之后是如何使用的。其实由于技术的不断更迭以及层出不穷新软件的发布,MapReduce已经几乎不被公司所使用,但是万变不离其宗,MapReduce就是大数据计算的基石,明白了内部是如何运作的,学起新的技术也就游刃有余了。
当我们存储了大量的数据,想全部导入到内存中进行运算是不可能实现的。
这时就需要用到MapReduce来进行分批处理了,MapReduce是一个编程模型,将一件单台机器不能处理的复杂任务分解成多个子任务,分发到集群中的其他机器上处理,当这些机器完成任务之后将会把结果返回,之后进行汇总,这样就可以进行十分有效率的并行计算。
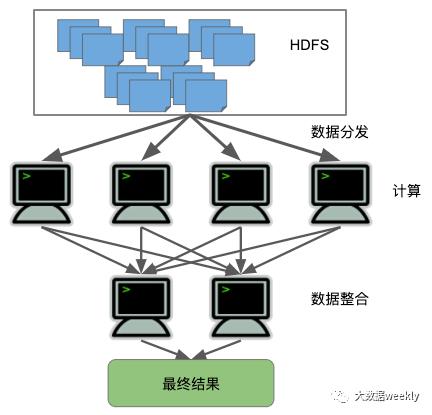
可能有的同学会问,到底数据是如何分发,又是如何并行计算的呢?接下来我将举个例子加以说明MapReduce的各个阶段。
现在假设我们有个数据需要计算每个汉字出现的频率,拿这句来看看MapReduce是如何处理数据的:“你好,早上好 ,今天早上天气真好”
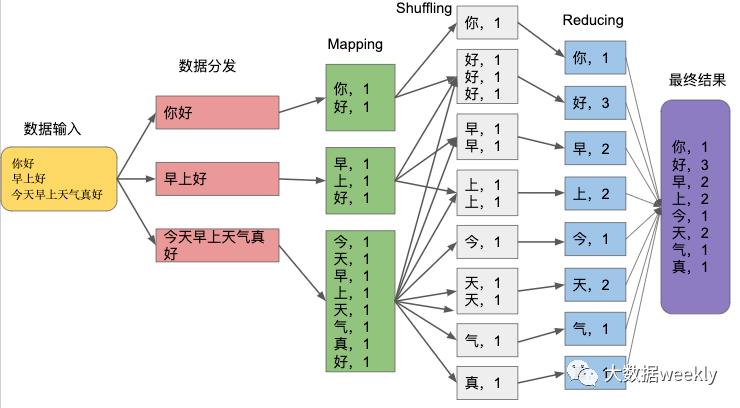
这个数据经过MapReduce处理后,最后我们得到最终结果显示在紫色框中。
数据输入后经过了四个阶段:
数据分发:文件首先会被分割成几个小文件,分别发送到不同的Mapper机器上
Mapping:MapReduce中的“Map”每一个文件在这个节点会被计算,每个汉字出现一次就记一次,生成一系列:<汉字,频率>,比如,<你,1>
Shuffling:得到Mapping生成的<汉字,频率>根据其中的汉字做归类,相同汉字的数据集合在一起
Reducing:对所有的数据进行汇总计算,得出每个汉字在整个文件中出现的频率
文章的最后,我们再来看一下MapReduce的程序是如何被Hadoop所执行的:
还记得上一章提到的Namenode和Datanode吗?当我们提交一个MapReduce程序的时候,代码将被发送到Namenode。在Namenode上有一个程序控制模块,实时监控Datanode的运行情况,把程序分发到各个正常运行的Datanode上去并行计算。当一个Datanode发生问题的时候,Namenode将会把任务分配到另外的Datanode去计算。
希望看完这篇,读者会有对如何对大数据进行计算有些基本的了解。
下周见!
以上是关于大数据的灵魂(下):MapReduce的主要内容,如果未能解决你的问题,请参考以下文章