面试必问 | 一文轻松搞定MapReduceHQL执行原理
Posted 数据仓库与Python大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试必问 | 一文轻松搞定MapReduceHQL执行原理相关的知识,希望对你有一定的参考价值。
如果你是一名数据工程师,还是一名吃货,那这篇文章应该没那么枯燥了。
今天用日料Sushi来一起走进MapReduce与HQL执行过程!轻松愉快美味~
##Ps:本人是个吃货(但人又很瘦的那种),尤其爱吃刺身日料,而且一说到吃就很激动,小胃已经锻炼的杠杠的了。
先简单介绍一下什么是Sushi,就是寿司。寿司也分很多种,本次就用手握寿司来生动形象的描述MR的原理和过程。
进入MapReduce之前的阶段
因为是对比讲解,所以从准备阶段开始,在准备阶段我们要准备好食材,食材就好比我们准备阶段的数据,食材有好有坏,数据同样也有好坏之分,一般想要得出的数据准确无误,都要准备“上好食材”,脏数据差数据尽可能避免,做好的sushi重点也是要好原料,新鲜度和品质占一部分,厨师的手艺也很关键。
我们这里分3个厨师吧,分别叫:M、S、R。
开始说下我们的原料食材,要做手握寿司,三文鱼、金枪鱼、干海苔、鱼子酱、山葵酱、醋饭,其他小的细节就不提了,而且也只用两种鱼类做参考。
准备好这些“数据”后开始进入下一阶段。
M厨师的Map阶段
整块三文鱼和金枪鱼放到面前,开切!切鱼也有很多讲究(刀、角度、还有姿势),在这里就不过多描述了,每片切1厘米左右,备用。
转回来在MapReduce中,首先M厨师上场,根据文件个数分配Mapper Task个数,M厨师依照下图SQL,再根据自己的手法做切分,当然手法是固定的,不能有偏见。主料和配料都会在这步做切分。
这一步主要是根据不同的鱼类进行切分,每个种类应切多少片呢,一般是按照DFS块大小来切,当然也可以用这个参数mapred.min.split.size自定义。
(join,SQL:select u.name, o.orderid from order o join user u on o.uid = u.uid;普通两表join,只要在value上打上标记就可以了)
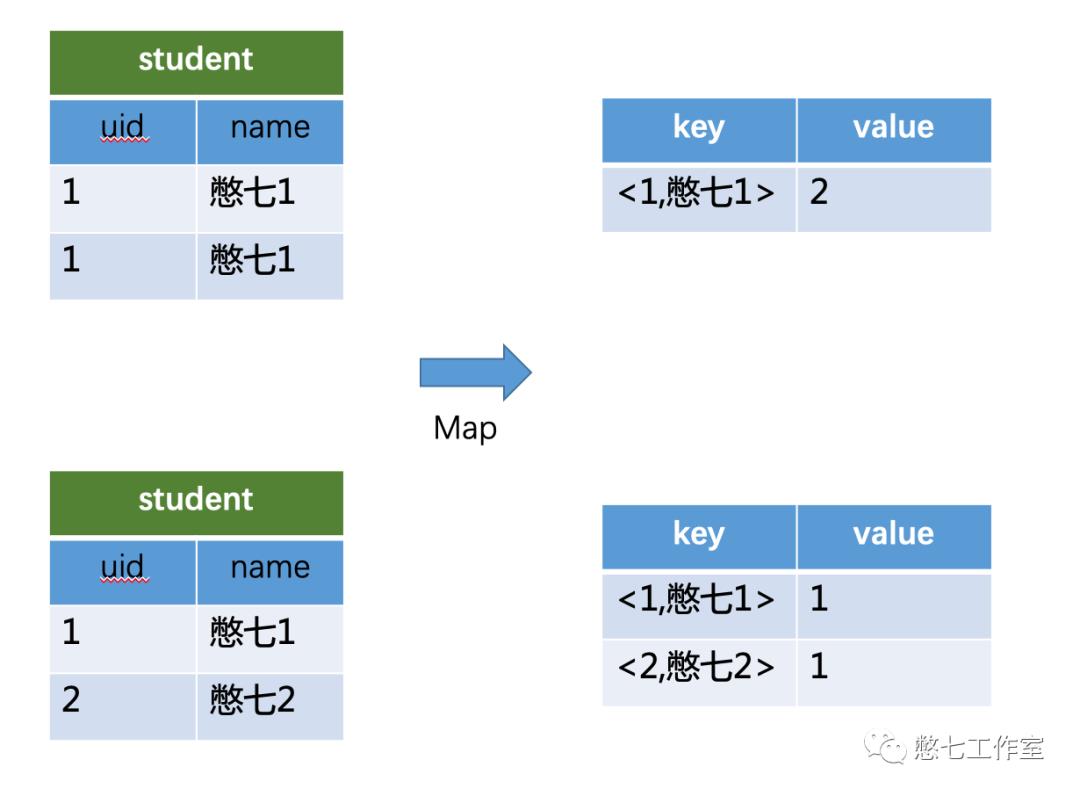
(group by,SQL:select uid, name, count(*) from student group by uid, name;将GroupBy的字段组合为map的输出key值)
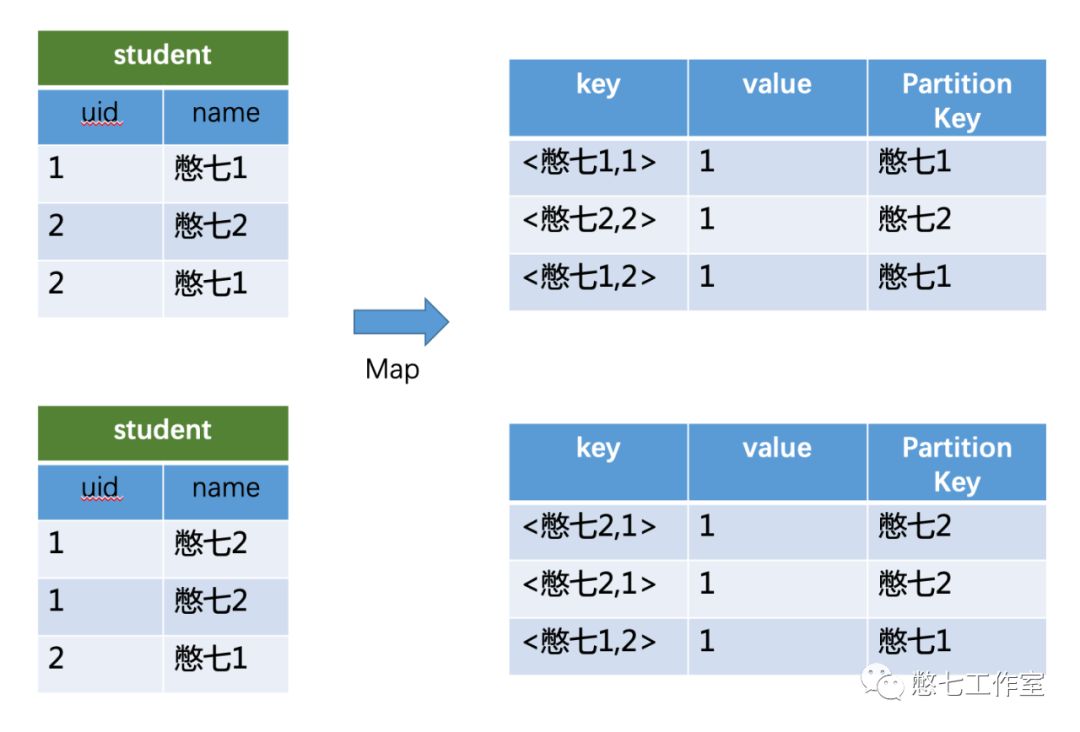
(count(distinct),SQL:select name, count(distinct uid) cnt from student group by name;将GroupBy字段和Distinct字段组合为map输出key)
下一步到S厨师,Shuffle阶段。
(本次没让负责Combine阶段的C厨师介入)
这步非常关键!也是最核心的,为什么核心呢?是因为衔接Map阶段和Reduce阶段之间的,核心的中间桥梁。
这一步是对食材进行分类,分类为什么核心,这次分类不是按照同种类区分,而是按照最终呈现的菜品进行分类。比如一贯寿司中,要几片干海苔,几片三文鱼,多少量的饭,多少量的鱼子酱等等。要注意的是,S厨师只是进行分类,并不负责将这些食材组合成最终的菜品,最终组合是R厨师的工作。试想一下,如果S厨师没学习过日料厨艺,也没吃过寿司,可能就会在某一贯寿司上分10片三文鱼,在另一贯寿司上分2片三文鱼,(可能是有自家亲戚或哥们来关顾才会这么分吧),这样分类会给R厨师造成很大难度,这种情况一会详细介绍。
转回到在MapReduce中,S厨师依据最终菜品进行食材分类,分类手法也是不一样的,根据SQL分不同方式分类,Shuffle阶段细分的话会分Map Task阶段的Shuffle和Reduce Task阶段的Shuffle:
Mapper Task输出时会开启一个环形内存缓冲区,并且在配置文件里有个设定的阈值(默认80%,可以改),当发现使用量到达这个内存阈值的时候,就会把这80%的内容写到磁盘上,这个过程叫分隔,Map Shuffle过程过后会生成1个或者多个分隔文件
Reduce Task输入时会分为两个任务:
1.Copy Map输出:直接Copy Map Shuffle的最后一步
2.Merge:基于JVM的heap size设置的内存缓冲区
最后Reduce Task不断合并后,会写到内存中或者磁盘中
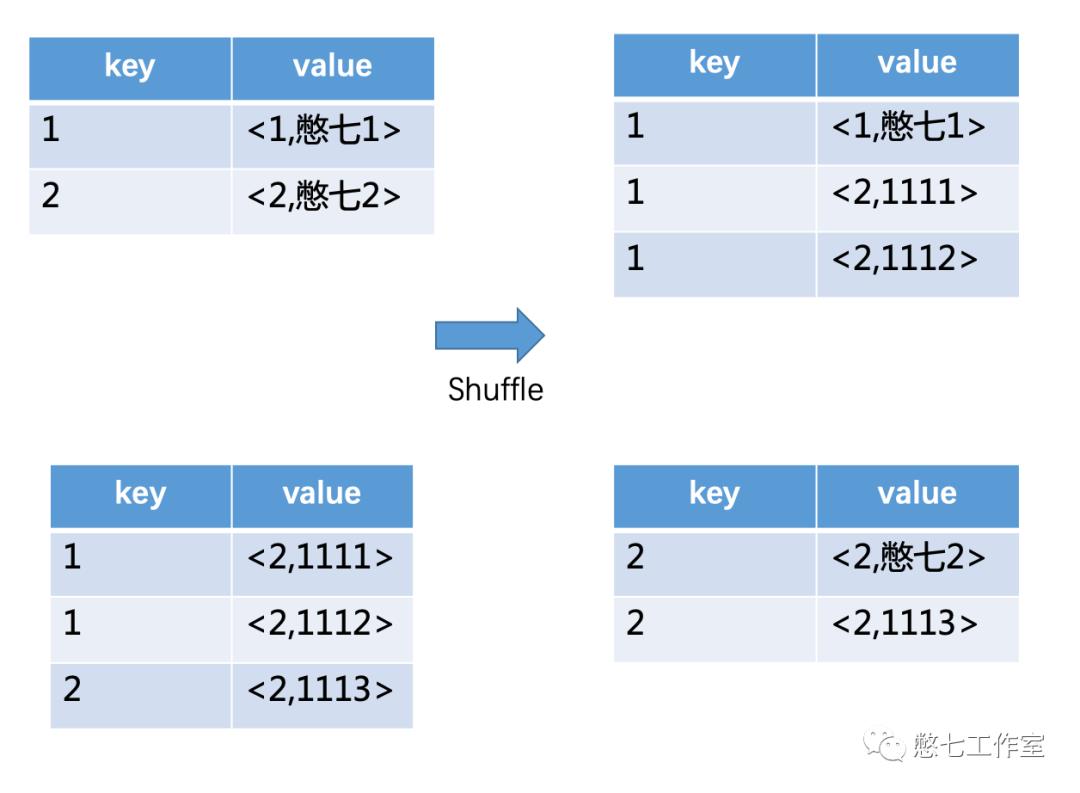
(join,SQL:select u.name, o.orderid from order o join user u on o.uid = u.uid;每个Mapper Task按照key进行分类)
(group by,SQL:select uid, name, count(*) cnt from student group by uid, name;同样按照Key值分类)
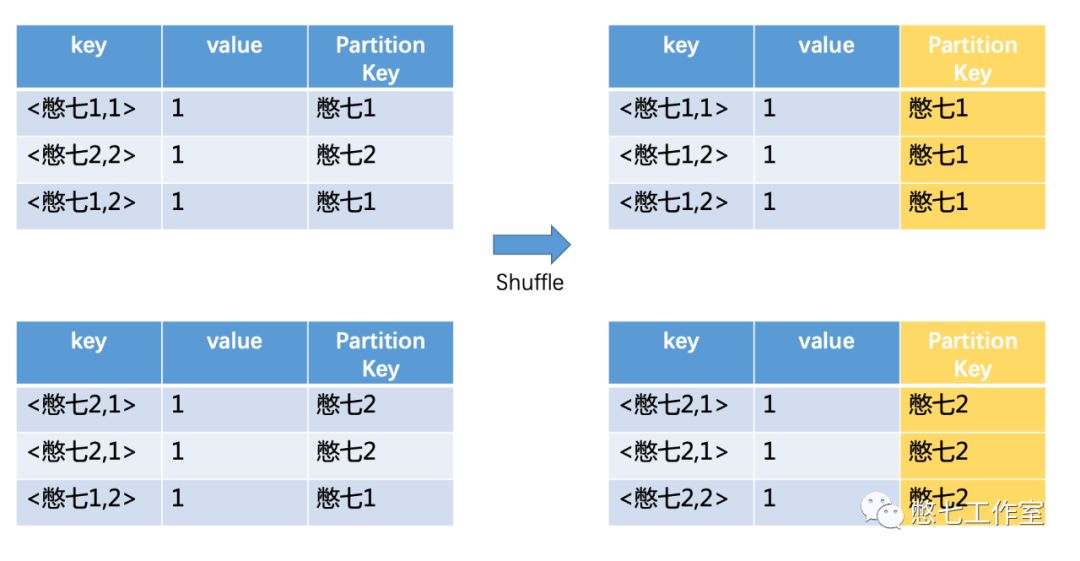
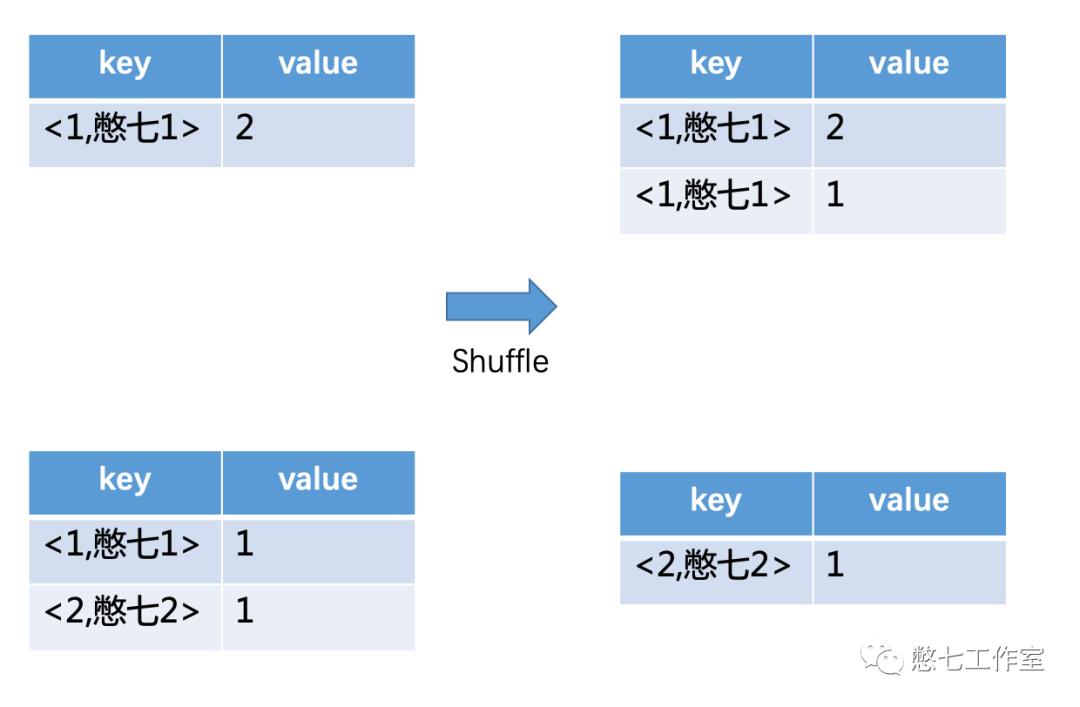
(count(distinct),SQL:select name, count(distinct uid) cnt from student group by name;这里图中保留出partition key,大家能看的清楚些,和Group by 不同的是会将distinct字段和group by字段全部已key的形式放到内存中,数据量大的时候会造成“内急”OOM情况,所以很多时候要避免count和distinct的cp组合)
最后到R厨师,Reduce阶段
组合排序,这一步将S厨师分类出的食材进行最终组合,组合成最终菜品展现给顾客,M、S、R三个厨师都只做自己的工作,不会有相互的交流(甚至连眼神的那种都没有),上游给到什么就做什么,这就是机器干活的弊端。最终三文鱼寿司,实在是不好描述,给大家个搜狗emoji
以上是关于面试必问 | 一文轻松搞定MapReduceHQL执行原理的主要内容,如果未能解决你的问题,请参考以下文章