透过生活看实质,源码解析分布式计算框架MapReduce(附源码)
Posted Java架构师联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了透过生活看实质,源码解析分布式计算框架MapReduce(附源码)相关的知识,希望对你有一定的参考价值。
先来出道题引入一个重要的思想----分布式计算思想
在上面的这个图中,主要是对一个1T的文件进行排序操作,是不是可以将这个大文件切割成一个个的小文件尽心处理,就可以解决啊,但是按照正常来说,一共需要三次io,读取文件进行切割一次,小文件内部排序一次,然后对小文件进行合并形成大文件一次,一共三次,并且大家是知道的,磁盘的io是非常慢的,所以,我能不能减少磁盘io的数量啊------这也就产生了第二步所整理的,大家想一下,反正我都要进行排序,那我可不可以在切割的时候就按照顺序切割呢?这样切出来的数据就是有序的小文件,直接进行小文件之间的排序,是不是什么都解决了啊,只需要两次io就可以解决所有的问题啊

同样的,如果我现在有1000台服务器进行10亿条url的排序工作,我是不是可以将这10亿条url的hashcode%1000.然后每一台服务器只去处理自己对应的数据就可以,每一台服务器上的小文件都是有序的,然后就可以进行最后的合并工作
好了,通过这两道题,不知道大家对于分布式思想有么有一个大致的概念呢?
接下来就是踏入正题了,mapreduce
> 首先我们要知道为什么要有mapreduce框架
mapreduce---计算处理框架
如果为了进行分布式计算,单纯的写一套计算处理程序,就像你们的数据结构算法一样,可以吗?
对于一些老牌程序员,我觉得完全没有问题---在代码层的处理逻辑
但是,一套处理高可用的处理程序除了正常的处理逻辑外,尤其是像这种大数据处理程序,还需要考虑网络、磁盘io、寻址。
都说懒人推动世界的发展,比方说自动驾驶,自动扫地机器人,不都是因为懒不想干活啊,然后产生了这些可以替代人的设备,说到懒,每个人都懒尤其是程序员,相当的懒,所以,她也不想每次写代码的时候都考虑那么多,所以啊,他就写一套框架,把所有的这个情况考虑进去,然后只要单纯的写处理逻辑就可以了,对吧!
哪知道了为什么会有mapreduce的处理框架,接下来就是她的原理了
大数据,大数据,数据至上,要想马儿跑,还想马尔不吃草,哪有那么好的事啊,对吧,那数据从何而来啊,对,
> 数据来源于生活
我就以生活中的实例对mapreduce进行讲解

> 问题1: 每一座山头在砍伐了树木,在将树木传输到工厂之后全都可以被使用吗?
> 答案:
> 肯定这些树木会产生边角料(脏数据),这些脏数据传输过来不用,但是依旧会占用传输的资源,产生浪费吧
> 问题2:如何避免边角料?
> 答案:我在山头的时候, 就已经把木材加工成简易的零件,这样的话就不会产生边角料的资源浪费吧
就比方说我在hdfs刚去处理数据的时候,就已经把数据进行处理,拿到我们需要的数据,如果说数据为表格,可能会有空行,空行就是脏数据把
> 问题3:简易的零件- -搬运浪不浪费时间?
> 答案:在山头的时候就已经把相应的零件进行组装,运输的时候,运输成品和半成品,同样的数据进行运输,我们在前期的时候就把数据准备好,最后的时候进行reduce,是不是压力会小很多
那这样的话我们就在刚才的生活实例中产生了多种不同的角色,那对于大数据,都对应哪些呢?
角色对应:
> 山树--hdfs中的数据
> 工人上山--map
> 山头: block
> 山头组装--- combiner
工人:处理进程--maptask
中间的运输-shuffle (洗牌)
工厂最终组装--reduce
那在这个过程中,最影响mapreduce处理效率的过程是哪里呢?
最消耗资源最影响效率是在磁盘上进行的---也就是shuffle过程
至于其他的过程,那不用说了,为了不让io影响效率,那指定是在内存中进行的
MapReduce处理流程
官方配图:
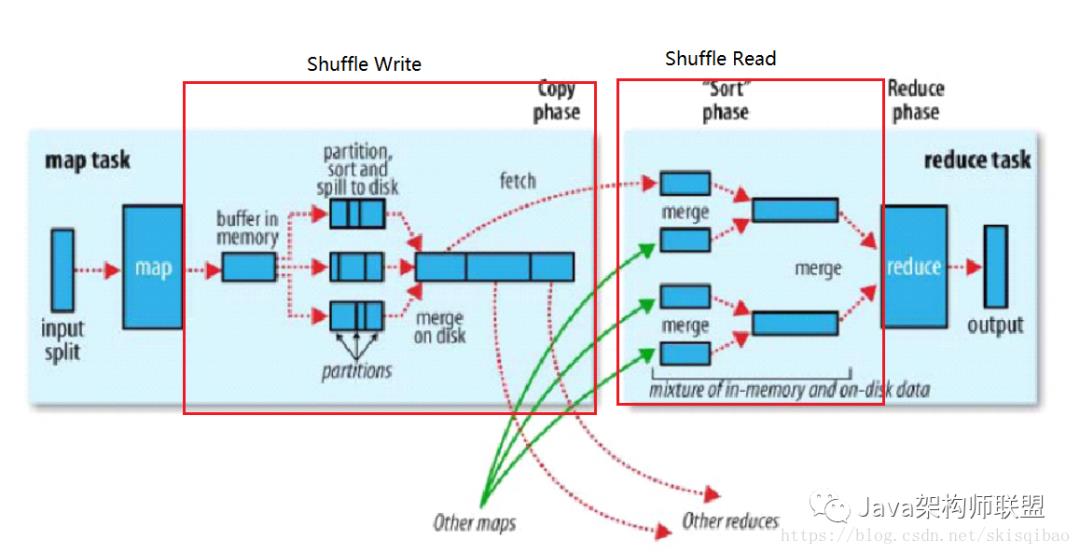
MapReduce 具体分为四步:
Map 阶段;
Shuffle Write阶段
Shuffle Read阶段
Reduce 阶段
MapReduce中的几个名词:
map task – Map端开启的处理线程, 一个map task 读取的数据称为一个split(切片),
split – 切片的概念, 假设数据存放在HDFS上, 每一个map task读取的数据就是一个切片,但这并不是在读取前就切好的. split的默认大小与一个block的大小一致, 即block数 = split数 = map task数.
也可设置split与block之间的大小关系, 例如, 2block = split = map task; 1/2block = split = map task.也可设置split与block之间的大小关系, 例如, 2block = split = map task; 1/2block = split = map task.
split是一个逻辑概念, map task会一行一行的读取某个block中的数据, 为防止数据被切分, 它还会多读取下一个block的第一行数据(HDFS中按照字节存储数据, 所以极有可能一条数据被拆分存放在两个block中).
key-value : MR处理过程中, 数据都是通过键值对的形式传递的. 起初key值为block中一条记录的偏移量(long类型), value为block中的数据(String类型), 两个偏移量之间是一条记录. 经过map, reduce处理过后, key-value内容根据需求而定.
map – 对数据切分的方法, 输入类型为<LongWritable, Text>, 输出类型<key, value>由需求决定.
HashPartitioner – 默认分区器. 相同的分区由相同的reduce task处理, 分区策略: 经map处理后, 将key的Hash值与reduce task的个数(NUM)取模, 模值相同的key将放在同一个分区中.
buffer in memory – 内存缓冲区, map对split内容处理后先写入内存缓冲区, 进入缓冲区的每一条记录都由三部分组成: 分区号, key, value. buffer大小默认100M, 分为两份, 一份80M, 一份20M.
当达到溢写比例(buffer中约有80M数据)时, 会将这80M数据封锁, 然后对数据进行聚合, 排序, 排序时先按照分区排序, 分区相同的再按照key排序. 排序完成后就将数据溢写到磁盘上. 每次溢写产生一个磁盘小文件.
聚合排序过程中, 如果还有内容继续往buffer中写的话, 这些内容将被写入buffer剩余的20M中.
merge – map阶段的merge基于磁盘小文件进行合并, 合并时按照分区号进行合并, 将相同分区号的数据放在同一个大分区中. 合并完成后会对相同分区的数据进行排序.
– reduce阶段的merge合并时会对每一个有序的磁盘小文件进行排序, 这些小文件已经属于同一个分区. 最后合并成一个磁盘大文件时, 会根据key值进行分组, key值相同的为一组.
fetch – reduce task进程从map task产生的磁盘大文件中拉取数据, 拉取的数据先放入Reduce端的内存中, 内存大小默认为1G的70%. 内存中数据达到一定的溢写比例后, 就会将内存中的数据溢写到磁盘小文件中, 溢写之前也会进行排序.
reduce – 对有序的大文件中key值相同的一组数据处理的方法, 输入参数由map端的输出参数决定, 输出参数由需求决定, 都是key-value的形式.
reduce task – Reduce端开启的处理线程, 一个reduce task产生一个output文件 .
MapReduce执行流程:
假设MR处理的数据存储在HDFS上, HDFS上的数据是以block的形式存放.
假设有三个map task和三个reduce task线程.
map task 线程
执行流程
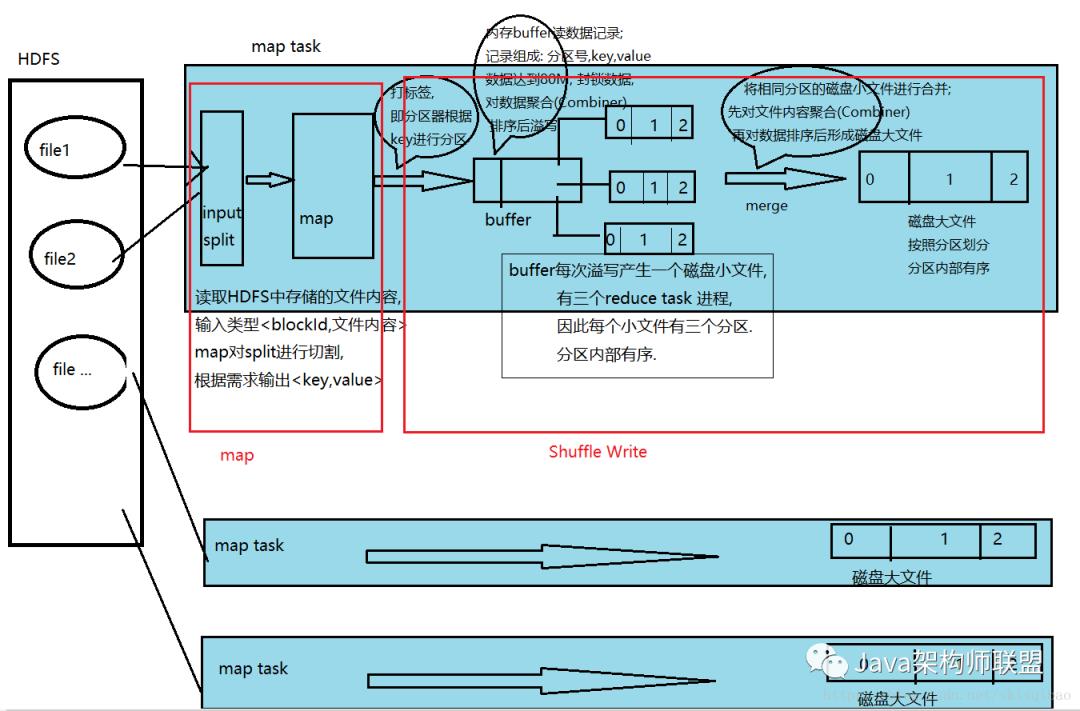
map阶段
map端进行了什么事:砍树这一步叫做split 过程
砍树---把我们hdfs的文件进行切割(砍树) ----- 默认与block块的大小一
致(128M) split=block=maptask
2.1当然为了更好的处理,在计算资源充足的情况下,把split变大设置为256M
> split= 2block= maptask
2、计算资源不充足,假设一个maptask只能处理64M的数据,那该怎么办呢?
有一个词叫做并行计算,并且中国传统文化也支持有福同享,有难同当,对吧
那我们就把split设置为64M
> 2split= 1 block= 2maptask
那在这里也证明了一个点
-一个计算处理进程(maptask)处理一个split
> 1split= 1maptask
注意
split是一个逻辑概念, map task会一行一行的读取某个block中的数据, 为防止数据被切分, 它还会多读取下一个block的第一行数据(HDFS中按照字节存储数据, 所以极有可能一条数据被拆分存放在两个block中).
1.2 shuffle write阶段
将map切割下来的数据放进内存缓冲区

磁盘和内存:谁的处理速度快,内存对吧,所以这个处理进程都是在内存中进行
在内存.上进行处理效率最高
那在内存缓冲区干了什么事--打标签
> 砍树的时候要进行分堆,是不是按照树木类型分的
> 给split打.上标签,同样标签的数据分到一起
如何打标签
> hashcode 相同的数据有自己固定的hashcode % reduce的个数=reduce个数的分区
> 分区的作用:相同hashcode种类的数据分到了一个reduce.上处理
那有了这些标签,之后,我们该如何去进行分区排序呢?
> 在最一开始的时候产生的数据是kv键值对,在进行分区的时候也是根据key值的hashcode
> HashPartitioner – 默认分区器. 相同的分区由相同的reduce task处理, 分区策略: 经map处理后, 将key的Hash值与reduce task的个数(NUM)取模, 模值相同的key将放在同一个分区中.
> buffer in memory – 内存缓冲区, map对split内容处理后先写入内存缓冲区, 进入缓冲区的每一条记录都由三部分组成: 分区号, key, value

问题:如果说我这100M空间满了,,又来数据了,怎么办?
> 对默认的100M进行划分=80+20
> 来的数据存放在80M中进行处理,当80M满了之后,对内存中的数据进行聚合(Combiner), combiner完成后再根据分区号排序, 分区号排序完之后再按照key的大小排序(Sort). 此时这80M的数据中相同分区号的数据存放在一起, 并且分区内的数据是有序的.然后会溢写(Spill)到磁盘上进行存储
> 在溢写的过程中,再来的数据,存放在20M中 因为溢写时会将80M内存给封印
所有溢写完毕后, 会将磁盘小文件合并成一个大文件, 合并时先对数据进行聚合(Combiner), 然后再使用归并算法将各个小文件合并(merge)成一个根据分区号划分且内部有序的大文件. 每一个map task都会产生这么一个大文件
reduce task 线程
执行流程:
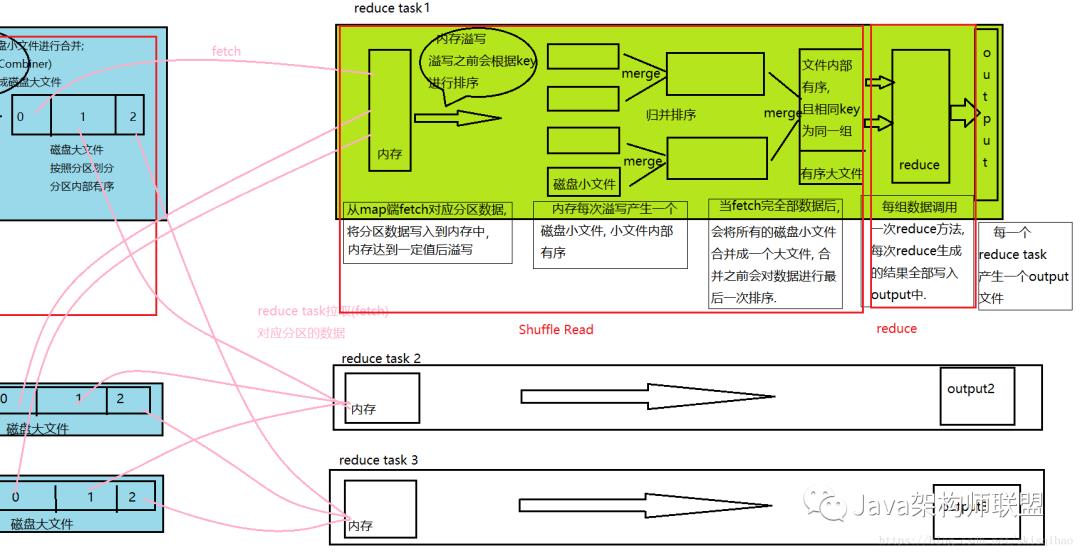
shuffle read阶段
reduce会 去map端拉取数据(shuffle),他会把磁盈上的数据拉取到reduce自己的内存中(默认1G)

和map一样,为了避免产生内存溢出的情况,reduce的内存也分为两块,7+3,并且,处于reduce聚合占用的资源更多,所以只要内存占用超过66%,就开始将reduce内存中的数据溢写到磁盘上,
溢写到磁盘之前:还是会进行一次小的排序
溢写之后:在进行合并,形成reduce端的有序小文件
reduce阶段
当map中对应分区的数据全部读取之后. reduce task会对所有的磁盘小文件进行归并算法合并, 合并成一个内部有序的磁盘大文件. 大文件中相同key值的数据为同一组数据.
至此,mapreduce除了进行结束
MapReduce整个过程流程图:
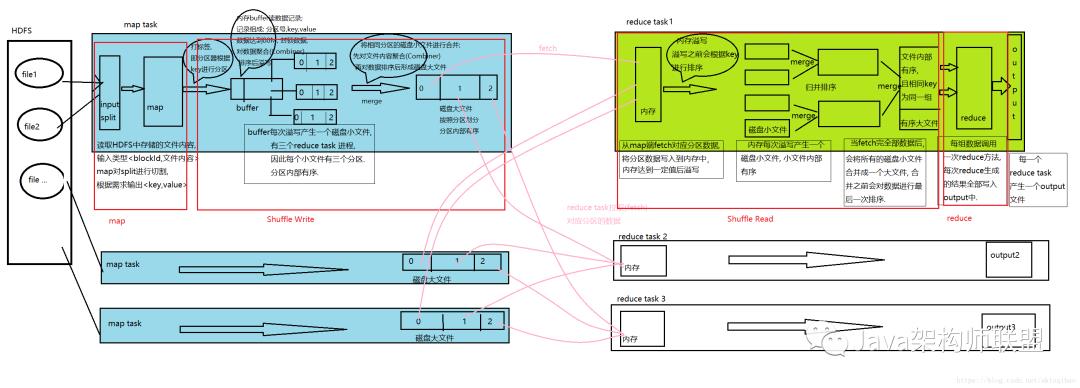
流程中可以看出, 一共进行了四次排序, 而这四此排序的最终目的都是在于提高最终分组的效率.
MR核心思想:“相同”的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
MapReduce概述
MapReduce的定义
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
上文是官方对MapReduce的描述, 大意为MapReduce是一个软件框架, 用来写应用程序, 该程序以可靠, 容错的方式能够在大型集群(上千节点)上处理海量数据(多为TB级别).
换句话说, MapReduce是一个分布式计算框架, 它能将用户编写的程序和其默认组件整合为一个分布式处理程序, 并发运行在Hadoop集群上.
MapReduce的优缺点
优点
易于编程. 实现一个分布式程序只需简单地实现几个接口即可, 而且这个程序可以放到大量廉价的服务器(或PC机)上执行, 门槛低.
扩展性较好. 当计算资源得不到满足时, 可通过简单地增加服务器数量来提升计算性能.
高容错性. 既然MapReduce部署在廉价机上, 那么就要求它具备较高的容错性. 当一个节点挂掉后, 集群内部可以自动地将计算任务转移到其他服务器节点上执行. 不仅保证任务不会失败, 而且还不需要开发人员的参与.
适合海量数据的离线处理. MapReduce可实现有上千台服务器集群的并发工作, 从而提高计算能力.
缺点
不适合实时计算. 无法像mysql一样, 在毫秒或秒级内返回结果.
不适合流式计算. MR自身设计决定它处理的数据集必须是静态的, 不能动态变化.
不适合有向图(DAG)计算. 当多个程序之间有相互依赖关系, 比如说前一个程序的输出要作为后一个程序的输入时, MR在处理时, 需要先将前一个程序的处理结果写入磁盘, 然后后一个程序再去磁盘读取结果之后才能处理, 从而造成大量磁盘IO, 导致性能低下.
最后指定是奉上代码啊--通过mapreduce编写wordcount
写上这份代码也是因为工作的关系,频繁的重复被wordcount配置的恐惧,尤其是在scala横飞的今天,长久的不再使用有的时候真的记不住啊,从网上找各种相应的代码,五味杂陈,所以在这里将简单的wordcount的代码整理出来供大家使用,也供自己参考
首先就是我们的Mapper层
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/** map阶段的业务逻辑就写在自定义的map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
// 1 将maptask传给我们的文本内容先转换成String
String line = value.toString();
// 2 根据空格将这一行切分成单词
String[] words = line.split(" ");
// 3 将单词输出为<单词,1>
for(String word:words){
// 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中
context.write(new Text(word), new IntWritable(1));
}
}
}
接下来是reduce层
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WcReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
// 1 汇总各个key的个数
for (IntWritable value : values) {
count += value.get();
}
// 2输出该key的总次数
context.write(key, new IntWritable(count));
}
}
最后是实现,但是在实现这里,主要分为三类
1、本地测试
package com.msb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcMain {
public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
//设置本地运行模式
configuration.set("fs.defaultFS","file:///");
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
// job.setJar("/home/admin/wc.jar");
job.setJarByClass(WcMain.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReduce.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
设置args[0]和args[1]的位置,也可以直接在代码中写死
注意,output路径不能有对应的文件夹
2、提交集群运行
package com.msb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcMainCluser {
public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
/*本地提交集群运行
* */
// configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("fs.defaultFS","hdfs://node01:9000");
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
// job.setJar("/home/admin/wc.jar");
job.setJarByClass(WcMainCluser.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReduce.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path( "hdfs://node01:9000/input/text"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://node01:9000/output"));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
3、提交yarn运行
package com.msb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcMainYarn {
public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
/*本地提交集群运行
* */
configuration.set("yarn.resourcemanager.address", "192.168.152.123:8050");
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("fs.defaultFS", "hdfs://node01:9000");
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
job.setJar("/test/hadoop/WordCount-1.0-SNAPSHOT.jar");
//job.setJar("E:\Java\WordCount\target\WordCount-1.0-SNAPSHOT.jar");
job.setJarByClass(WcMainYarn.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReduce.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path( "hdfs://node01:9000/input/text"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://node01:9000/output"));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
4、将代码打包提交到集群中运行
将idea中创建的项目进行打包,并上传到hadoop集群中
打包:
上传到集群之后,通过命令进行运行
hadoop jar jar包名 com.msb.WordCount(需要执行文件的路径名)
注意:
在这个地方有很多人本地进行测试或者连接集群的时候没有办法进行,是因为没有进行相应的修改,需要在本地windows下进行hadoop的配置,配置过程参考hadoop配置的博客
以上是关于透过生活看实质,源码解析分布式计算框架MapReduce(附源码)的主要内容,如果未能解决你的问题,请参考以下文章