数据产品--MapReduce原理
Posted 白毛道长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据产品--MapReduce原理相关的知识,希望对你有一定的参考价值。
什么是map:
分析需求1,右边第一个表要求过滤性别为女的,那么,计算机处理这个问题的时候是这样的,首先扫描左边表第一行,找到性别那一栏,判断是不是符合要求,符合的留下,不符合的过滤掉,然后成为另一个表的结果,然后去处理第二条数据,依次类推。
分析需求二:转换码值为字典值,同样的,计算机扫描第一行,将性别的0和1转换成M和W,也是处理完一行后,接着处理第二行,依次类推
总结上面,计算机处理都是一行一行挨着处理,处理第一行的时候并不会考虑其他行的情况。
因此map:以一条记录为单位进行映射。
reduce:
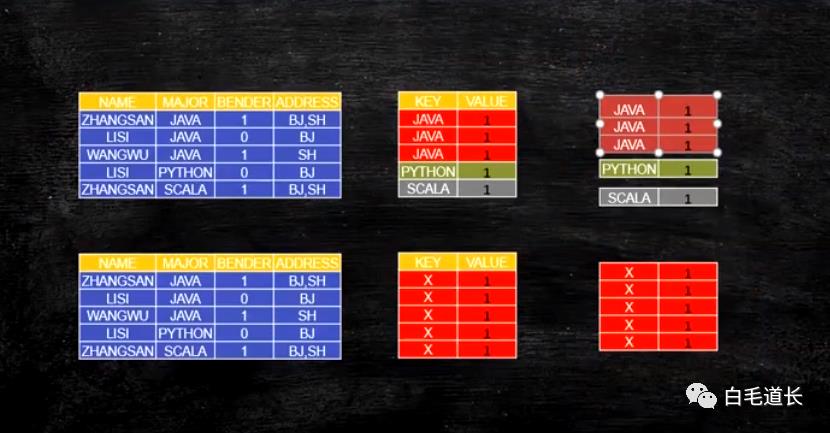
上面这个表,如果要计算学习java、python、scala的人有多少,那么计算机先是一条一条数据处理,把处理了java的技术1,挨个处理下一条数据,如果是python,计数1,得到最右边的分组的表,那么计算机在计算java多少人、python多少人、scala多少人时,是可以同时进行计算,那么这就是ruduce。
reduce是以一组为单位做计算。是以一种key-value的方式来处理数据
mapreduce,由计算机计算的,按照组来统计的map映射
所以计算机计算无非就是
第一种 逐个计算 map映射
第二种 map+reduce 分组计算
第三种 更复杂的就是map+reduce不停组合的计算
所以
map可以1进1出(选择性别为女的)、1进多出(选择地点的)、1进0出(性别为男的),所以map是1进N出。
reduce是一组进N出,比如一个班的语文成绩这一组,可以count()计算多少参加语文考试的,average()计算某参加语文考试的平均成绩。
而这种映射是通过key-value
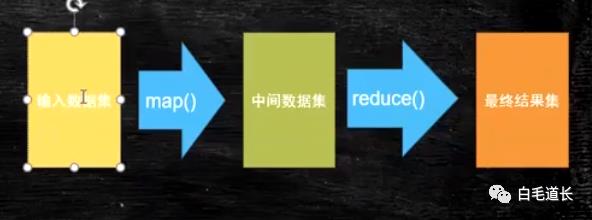
在脑中可以想象出,处理数据就是经过这三个阶段,第一个阶段map数据,map后有个中间数据集,再经过reduce得到最终数据集,复杂的数据处理可能就不停的循环这个操作。
但是mapreduce更重要的是分布式计算
所有的reduce计算依赖于map的完成
CPU密集型计算:计算,耗时长
IO密集型计算:映射,耗时短
HDFS物理块切分数据
split()对应HDFS的物理块切分,切片决定文件未来被处理的范围,但是计算机有个机制,比如hello被分在了两个切片中,那么,会计算机会通过某种框架和方法还原he为hello。
map是以一条数据作为依次处理的,那么怎么定义为一条数据?split()里的数据可以通过format()方法来定义什么是一条数据,比如/n作为分隔的数据(小明就是一条数据),或者<>这种格式作为一条数据(<大宝>就是一条数据)。
小明
小黄
小蓝
<大宝><二宝><三大宝><四宝><五宝>
所以切片split是确定了范围,拿出一条数据就调一次map
map根据切片的多少并行,几个切片几个map
map映射的是键值对 比如 k包括男、女。如果key是专业,那就会有更多
reduce并行计算:这么想,map映射了两个中间数据表,性别是男的和性别是女的,ruduce计算性别男的表的时候,是不管性别女的这个表的,既然这样,就可以动用两个reduce分别去处理性别男和性别女的两个表。
如果处理男的表要1个小时,处理女的要1个小时,那么同时计算就只要1小时,加入key值很多的话,并行不同的reduce,就可以节约很多时间
reduce的最小单位是组,不能再分,再分导致数据不准。
map的并行度由切片决定,reduce的并行度由人决定。由开发人员根据自己有多少台电脑决定,所以,一台电脑,一个reduce可以处理不止一组的数据,可能线性处理其中的几组。
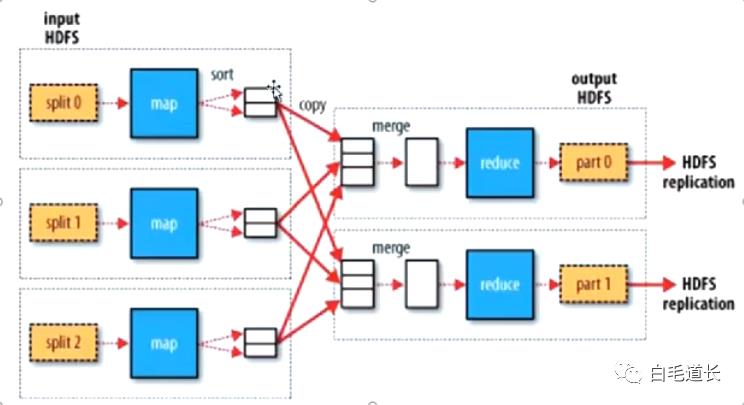
map---分组---(分区)多个组

课程来自:https://www.bilibili.com/video/BV1GJ411Q7Wm?p=1
以上是关于数据产品--MapReduce原理的主要内容,如果未能解决你的问题,请参考以下文章