深入MapReduce计算引擎02
Posted 董世森BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入MapReduce计算引擎02相关的知识,希望对你有一定的参考价值。
MapReduce的Reducer
Reducer类是MapReduce处理Reduce阶段业务逻辑的地方。将重点学习Reducer如何处理Redcue阶段的业务逻辑,使读者对其处理过程有一个清楚的认识。
Reducer类
Reducer的核心Reduce方法是MapReduce提供给用户编写业务的另一个主要接口,它的输入是一个键-数组的形式,和Mapper的输入不太一样。Reducer任务启动时会去拉取Map写入HDFS的数据,并按相同的键划分到各个Reducer任务中,相同键的值则会存入到一个集合容器中,因此Reducer 的输入键所对应的值是一个数组,Reducer 输出则是同Mapper一样的键-值对形式。如图5.8所示为WordCount的Reducer例子。
从上面的代码可以知道,Reducer提供的Reduce方法与Mapper中的Map方法一样,都只是约定了输入和输出的数据格式。和Map方法一样,Reducer在提供方便的同时,也有相似的弊端。Reducer还提供了Reduce之外的其他方法,如图5.9所示。

图5.9 Reducer 涉及的方法可以看到,Reducer 类如 Mapper 类一样,也提供了 cleanup()、reduce()、run() 和 setup() 方法,它们之间的关系同Mapper 中的方法一致,这里就不再赘言。
一个完整的MapReduce任务提交到Hadoop集群,Reducer中的逻辑会被分发到集群中的各个节点。但是不同于 Mapper 读取本地文件,Reducer 会去拉取远程 Map 节点产生的数据,这里必然也会涉及网络 I/O 和磁盘 I/O。从这里我们可以看到,如非需要对数据进行全局处理,例如全局排序,就关掉Reduce阶段的操作,可以提升程序性能。
Hive中与Reducer相关的配置
Hive可以通过一些配置来影响Reducer的运行,将会介绍与Reducer相关的一些配置。
● mapred.reduce.tasks:设置Reducer的数量,默认值是-1,代表有系统根据需要自行决定Reducer的数量。
● hive.exec.reducers.bytes.per.reducer:设置每个Reducer所能处理的数据量,在Hive 0.14版本以前默认是1000000000(1GB), Hive 0.14及之后的版本默认是256MB。输入到Reduce的数据量有1GB,那么将会拆分成4个Reducer任务。
● hive.exec.reducers.max:设置一个作业运行的最大Reduce个数,默认值是999。
● hive.multigroupby.singlereducer:表示如果一个SQL 语句中有多个分组聚合操作,且分组是使用相同的字段,那么这些分组聚合操作可以用一个作业的Reduce完成,而不是分解成多个作业、多个Reduce完成。这可以减少作业重复读取和Shuffle的操作
● hive.mapred.reduce.tasks.speculative.execution:表示是否开启Reduce任务的推测执行。即系统在一个Reduce 任务中执行进度远低于其他任务的执行进度,会尝试在另外的机器上启动一个相同的Reduce任务。
● hive.optimize.reducededuplication:表示当数据需要按相同的键再次聚合时,则开启这个配置,可以减少重复的聚合操作。
● hive.vectorized.execution.reduce.enabled:表示是否启用Reduce任务的向量化执行模式,默认是true。MapReduce计算引擎并不支持对Reduce阶段的向量化处理。
● hive.vectorized.execution.reduce.groupby.enabled:表示是否移动Reduce任务分组聚合查询的向量化模式,默认值为true。
MapReduce计算引擎并不支持对Reduce阶段的向量化处理。更多关于Mapper的配置。
MapReduce的Shuffle
Shuffle过程按官方文档的解释是指代从Mapper的输出到Reduer输入的整个过程。
但个人认为Shuffle的过程应该是从Mapper的Map方法输出到Reducer的Reduce方法输入的过程。它是制约MapReducer 引擎性能的一个关键环节,但同时也保证了Hadoop 即使能在一些廉价配置较低的服务器上可靠运行的一个环节。
在Mapper的Map方法中,context.write()方法会将数据计算所在分区后写入到内存缓冲区,缓冲区的大小为mapreduce.task.io.sort.mb=100MB。当缓冲区缓存的数据达到一定的阀值mapreduce.map.sort.spill.percent=0.8,即总缓冲区的80%时,将会启动新的线程将数据写入到HDFS临时目录中。
这样设计的目的在于避免单行数据频繁写,以减轻磁盘的负载。这与关系型数据库提倡批量提交(commit)有相同的作用。
在写入到HDFS的过程中,为了下游Reducer任务顺序快速拉取数据,会将数据进行排序后再写入临时文件中,当整个Map 执行结束后会将临时文件归并成一个文件。如果不进行文件的排序归并,意味着下游Reducer任务拉取数据会频繁地搜索磁盘,即将顺序读变为随机读,这会对磁盘I/O产生极大的负载。
扩展:在早期的Spark计算引擎中,Shuffle过程的排序会影响程序的性能,默认采用的是Hash Based Shuffle,会产生大量的临时文件,下游在拉取数据时不仅需要频繁读取大量的临时文件,还需保持大量的文件句柄。
这种方式在面对海量数据时不仅性能低下,而且也容易内存溢出。
在Spark 1.1版本开始引入Sort BasedShuffle后,Spark 在处理大数据量时性能得以改善,并且在Spark 2.0版本时正式废弃Hash Based Shuffle。事实上,Sort Based Shuffle也是借鉴了HadoopShuffle的实现思想。Reducer任务启动后,会启动拉取数据的线程,从HDFS拉取所需要的数据。
为什么不选用Mapper任务结束后直接推送到Reducer节点,这样可以节省写入到磁盘的操作,效率更高?
因为采用缓存到HDFS,让Reducer主动来拉,当一个Reducer任务因为一些其他原因导致异常结束时,再启动一个新的Reducer依然能够读取到正确的数据。
从HDFS拉取的数据,会先缓存到内存缓冲区,当数据达到一定的阈值后会将内存中的数据写入内存或者磁盘中的文件里。当从HDFS 拉取的数据能被预先分配的内存所容纳,数据会将内存缓存溢出的数据写入该内存中,当拉取的数据足够大时则会将数据写入文件,文件数量达到一定量级进行归并。
扩展:Hive里面经常使用到表连接,如果非特别处理,例如不特别声明使用MapJoin,则一般就是发生在这个阶段,因此普通的表连接又被称之为Repartition Join。
MapReduce的Map端聚合
MapReduce的Map端聚合通常指代实现Combiner类。Combiner也是处理数据聚合,但不同于Reduce是聚合集群的全局数据。Combiner聚合是Map阶段处理后的数据,因此也被称之为Map的聚合。
5.6.1 Combiner类
Combiner是MapReduce计算引擎提供的另外一个可以供用户编程的接口。Combiner所做的事情如果不额外进行编写,则可以直接使用Reducer 的逻辑,但是Combiner发生的地方是在Mapper任务所在的服务器,因此它只对本地的Mapper任务做Reducer程序逻辑里面的事情,无法对全局的Mapper任务做,所以一般也被称为Map端的Reducer任务。
如图5.10所示为Combiner的使用方法示例图。

图5.10 Combiner使用的代码片段
使用Combiner的初衷是减少Shuffle过程的数据量,减轻系统的磁盘和网络的压力。如图5.11所示为使用Combiner缩小数据的表示图。
扩展:在Hive 中,Hive 提供了另外一种聚合方式——使用散列表,即在每个Mapper中直接使用散列表进行聚合,而不是另起Combiner聚合任务,这样避免另外起一个任务和额外的数据读写所带来的开销。散列表,可以类比Java中的HashMap。
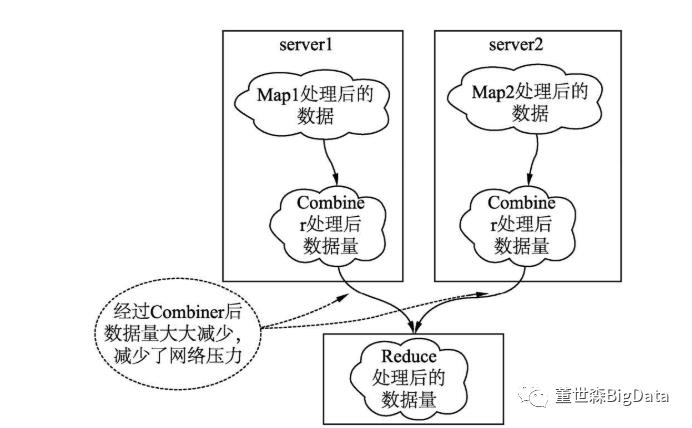
图5.11 Combiner减少数据量
Map端的聚合与Hive配置
在Hive中也可以启用Map端的聚合,但有别于使用Combiner, Hive端的聚合更多的是使用哈希表。即在Map执行时启用hash表用来缓存数据,并聚合数据,而不是单独启用Combiner任务来完成聚合。下面是关于Map端聚合的一些配置。
(1)hive.map.aggr:默认值为true,表示开启Map端的聚合。开启和不开启Map端聚合的差别可以在执行计划中看到,详见下面两个案例执行计划的精简结构。
备注:为了方便对比两个执行计划,将所有执行计划中大部分相同的信息进行省略,形成一个精简结构。
未启用Map端聚合的执行计划的精简结构如下:
 启用Map端聚合的执行计划的精简结构如下:
启用Map端聚合的执行计划的精简结构如下:

从上面的案例可以看到,启用Combiner,会在Map阶段多出一个GroupBy操作。
通常使用Map聚合往往是为了减少Map任务的输出,减少传输到下游任务的Shuffle数据量,但如果数据经过聚合后不能明显减少,那无疑就是浪费机器的I/O资源。因此Hive在默认开启hive.map.aggr的同时,引入了两个参数,
hive.map.aggr.hash.min.reduction
和
hive.groupby.mapaggr.checkinterval,用于控制何时启用聚合。
(2)hive.map.aggr.hash.min.reduction:是一个阈值,默认值是0.5。
(3)hive.groupby.mapaggr.checkinterval:默认值是100000。Hive在启用Combiner时会尝试取这个配置对应的数据量进行聚合,将聚合后的数据除以聚合前的数据,如果小于hive.map.aggr.hash.min.reduction会自动关闭。
(4)hive.map.aggr.hash.percentmemory:默认值是0.5。该值表示在进行Mapper端的聚合运行占用的最大内存。例如,分配给该节点的最大堆(xmx)为1024MB,那么聚合所能使用的最大Hash表内存是512MB,如果资源较为宽裕,可以适当调节这个参数。
(5)hive.map.aggr.hash.force.flush.memory.threshold:默认值是0.9。该值表示当在聚合时,所占用的Hash表内存超过0.9,将触发Hash表刷写磁盘的操作。例如Hash表内存是512MB,当Hash表的数据内存超过461MB时将触发Hash表写入到磁盘的操作。
MapReduce作业输出
MapReduce作业输出包含两部分,一部分是Map阶段的输出,另一部分是Reduce阶段的输出,主要用于检查作业的输出规范,并将数据写入存储文件中。
OutputFormat作业输出
作业输出(OutputFormat)是用于MapReduce 作业的输出规范。
通过继承并实现OutputFormat接口,可以将数据输出到任何想要存储的数据存储文件中。
OutputFormat主要设计两个接口/类:
OutputFormat和OutputCommitter。
1:OutputFormat类
OutputFormat类提供了3个方法,如图5.12所示。
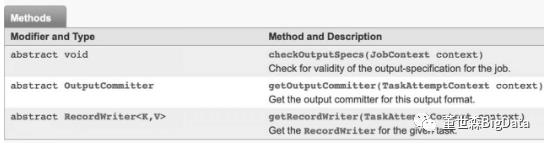
图5.12 OutputFormat类
● checkOutputSpecs()方法:校验作业的输出规范。
●getOutputCommitter()方法:获取OutputCommitter对象,OutputCommitter 用于管理配置,并提交作业的输出任务。
● getRecordWriter()方法:获取RecordWriter 对象,通过RecordWriter 将数据写入HDFS中。
2.OutputCommitter类
OuputCommitter类在这个输出任务组中要承担的任务如下:
● 在初始化期间,做些作业运行时的准备工作。例如,在作业初始化期间为作业创建临时输出目录。
● 在作业完成后,清理作业遗留的文件目录。例如,在作业完成后删除临时输出目录。设置任务临时输出。这个输出有特殊的用处,下面将会结合Taskside-effect文件处理做说明。
● 检查任务是否需要提交。这是为了在任务不需要提交时避免提交过程。
● 提交输出任务。一旦任务完成,整个作业要提交一个输出任务。
● 丢弃任务提交。如果任务失败/终止,输出将被清理。
如果任务无法清除(在异常块中),将启动一个单独的任务,使用相同的attempt-id执行清除。OutputCommitter提供的方法如图5.13所示。
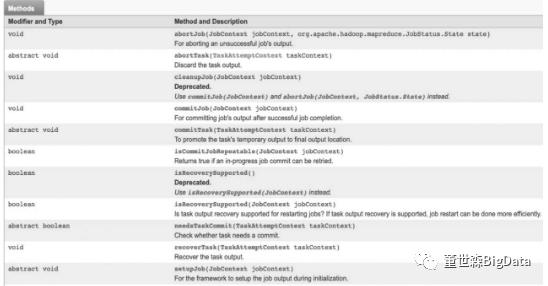
图5.13 OutputCommitter类的方法
扩展:Task side-effect文件并不是任务的最终输出文件,而是具有特殊用途的任务专属文件,它的典型应用是执行推测式任务。
在Hadoop中,同一个作业的某些任务执行速度可能明显慢于其他任务,进而拖慢整个作业的执行速度。为此,Hadoop 会在另外一个节点上启动一个相同的任务,该任务便被称为推测式任务。为防止这两个任务同时往一个输出文件中写入数据时发生写冲突,FileOutputFormat会为每个Task的数据创建一个side-effect file,并将产生的数据临时写入该文件,待Task完成后,再移动到最终输出目录中。
Hive配置与作业输出
Hive提供了作业输出文件的压缩,可以减少在Shuffle过程的数据量,减轻磁盘和网络的负载。但是有压缩就会有解压缩,免不了性能损耗,一般在大型作业中才会开启文件作业的压缩。
开启文件作业的压缩只要将hive.exec.compress.intermediate参数设置为true。
当然Hive提供写入到最终Hive表或者HDFS文件的压缩参数-- hive.exec.compress.output。
上述的压缩如果要是MapReduce中起作用的前提是需要配置mapred.output.compression. codec和mapred.output.compression两个属性。Hive提供多种方式去合并执行过程中产生的小文件,例如:
● 启用hive.merge.mapfile参数,默认启用,合并只有Map任务作业的输出文件;
● 启用hive.merge.mapredfiles参数,默认启用,合并MapReduce作业最终的输出文件;
● 设置hive.merge.smallfiles.avgsize参数,默认16MB,当输出的文件小于该值时,启用一个MapReduce任务合并小文件;
● 设置hive.merge.size.per.task参数,默认256MB,是每个任务合并后文件的大小。一般设置为和HDFS集群的文件块大小一致。
MapReduce作业与Hive配置
Hive的配置除了能控制作业在MapReduce中每个阶段的运行外,也能用于控制整个作业的运行模式。
下面是一些较为常见的通过Hive配置操作MapReduce作业运行的配置。
● hive.optimize.countdistinct:默认值为true, Hive 3.0新增的配置项。当开启该配置项时,去重并计数的作业会分成两个作业来处理这类SQL,以达到减缓SQL的数据倾斜作用。
● hive.exec.parallel:默认值是False,是否开启作业的并行。
默认情况下,如果一个SQL被拆分成两个阶段,如stage1、stage2,假设这两个stage没有直接的依赖关系,还是会采用窜行的方式依次执行两个阶段。如果开启该配置,则会同时执行两个阶段。在资源较为充足的情况下开启该配置可以有效节省作业的运行时间。
● hive.exec.parallel.thread.num:默认值是8,表示一个作业最多允许8个作业同时并行执行。
● hive.exec.mode.local.auto:默认值是false,表示是否开启本地的执行模式。开启该配置表示Hive 会在单台机器上处理完所有的任务,对于处理数据量较少的任务可以有效地节省时间。开启本地模式还需要以下几个配置帮助。
● hive.exec.mode.local.auto.inputbytes.max:默认值
134217728(128MB),表示作业处理的数据量要小于该值,本地模式。
● hive.exec.mode.local.auto.tasks.max:默认值是4,表示作业启动的任务数必须小于或者等于该值,本地模式才能生效。在Hive 0.9的版本以后该配置被hive.exec.mode. local.auto. input.files.max配置所取代,其含义和hive.exec.mode.local.auto.tasks.max相同。
● hive.optimize.correlation:默认值为false,这个配置我们称之为相关性优化,打开该配置可以减少重复的Shuffle操作。
例如,存在如下的SQL:

上面的SQL在执行时,JOIN操作和GROUP BY操作通常情况下都会产生Shuffle的操作,但是由于Join阶段操作后输出的结果是作为GROUP BY阶段操作的输入,并且在JOIN操作时,数据已经按t1.Key分区,因此通常情况下GROUP BY操作没有必要为t1.key进行重新Shuffle。然而在一般情况下,Hive并不知道JOIN操作和GROUP BY操作之间的这种相关性,因此会产两个Shuffle操作。这种情况往往会导致低效SQL的产生,通过开启hive.optimize.correlation配置,可以避免这种低效SQL的产生。
MapReduce与Tez对比
Tez 是一个基于Hadoop YARN 构建的新计算框架,将任务组成一个有向无环图(DAG)去执行作业,所有的作业都可以描述成顶点和边构成的DAG。Tez为数据处理提供了统一的接口,不再像MapReduce计算引擎一样将任务分为作业Map和Reduce阶段。
在Tez 中任务由输入(input)、输出(output)和处理器(processor)三部分接口组成,处理器可以做Map 的事情,也可以做Reduce 需要的事情。Tez 中的数据处理构成DAG的顶点(Vertex),任务之间的数据连接则构成了边(Edge)。
通过案例代码对比MapReduce和Tez
一个包含Mapper和Reducer任务的作业,在Tez中可以看成是一个简单的DAG,如图5.14所示。

图5.14 用Tez表示MapReduce过程
Mapper 的输入和Reducer 的输出,分别作为Tez 中的输入和输出接口,Mapper和Reducer任务则可以看成两顶点vertex1和vertex2, Mapper和Reducer中间的Shuffle过程则可以看成是两顶点的边。
我们通过使用Tez编写案例来了解下Tez基本编程模型和运行原理。大数据最好的入门案例便是单词计数(wordcount)案例,如果要掌握一个案例,最好的方式便是实操。接下来写Tez版本的WordCount案例。在MapReduce版本的WordCount案例中,Map阶段所做的逻辑如下:
(1)读取一行数据。
(2)将一行的数据按固定的分隔符进行分割,如空格。
(3)将分割后的单词,按键-值对形式输出,键是单词,值是1。
Reduce阶段所做的逻辑如下:
(1)分别读取每个键对应集合中的值,并进行加总。
(2)将结果以键值对形式输出,键是单词,值是加总后的值。
在Tez中需要两顶点分别来处理MapReduce中Map和Reduce两个阶段的内容,以及构建一个DAG图来将两顶点连接起来。
1.顶点1—实现类似Map的逻辑下面是第一顶点的逻辑:

读完上面顶点1的实现逻辑,我们通过图5.15来比对Tez和Map阶段主体业务逻辑。
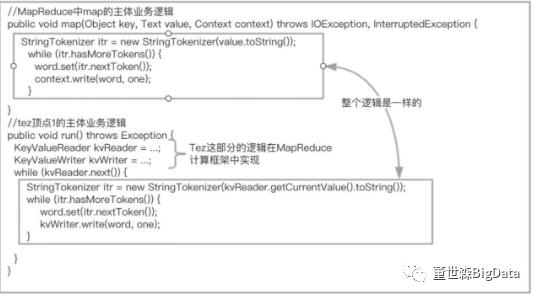
图5.15 Tez和MapReduce Map阶段比较
通过图5.15可知,Tez顶点1的实现逻辑和基本执行原理同Mapper基本一致,不同点在于Tez把输入和输出放在了run()方法中,而Mapper把输入和输出及遍历文件中的每一行数据交给整个计算框架去实现。
2.顶点2—实现类似Reduce的逻辑下面是第二顶点的逻辑:

读完SumProcessor 的逻辑,我们通过图5.16来对比SumProcessr 和MapReduce中Reduce的方法。
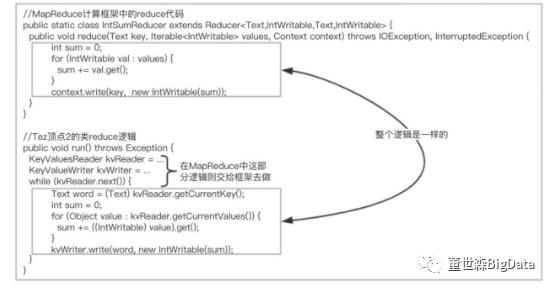
图5.16 Tez和MapReduce Reduce阶段比较
从图5.16中我们看到,Reduc代码和顶点2的逻辑一致。
3.构建DAG图并提交任务
Tez需要将所有的任务构建成一个DAG图,然后才进行任务的提交。
这是和MapReduce计算引擎最大的差别。
下面我们来看看Tez是如何构造整个DAG的:
通过createDAG方法构造完一个DAG图后就可以启动整个作业。下面是Tez版本完整的代码
Hive中Tez和LLAP相关的配置
Tez和MapReduce这两种计算引擎从架构到编写具体的项目代码其实有很多共通的地方,因此在配置Tez的环境参数方面也基本差不多。下面是Tez常见的配置。
● tez.am.resource.memory.mb:配置集群中每个Tez作业的ApplicationMaster所能占用的内存大小。
● tez.grouping.max-size、tez.grouping.min-size:配置集群中每个Map任务分组分片最大数据量和最小数据量。
● hive.tez.java.opts:配置Map任务的Java参数,如果任务处理的数据量过大,可以适当调节该参数,避免OOM(内存溢出)。选择合理的垃圾回收器,提升每个任务运行的吞吐量。
● hive.convert.join.bucket.mapjoin.tez:配置是否开启转换成桶MapJoin的表连接。默认是false,表示不开启。
● hive.merge.tezifles:是否合并Tez任务最终产生的小文件。
● hive.tez.cpu.vcores:配置每个容器运行所需的虚拟CPU个数。
● hive.tez.auto.reducer.parallelism:配置是否开启作业自动调节在Reduce阶段的任务并行度。
● hive.tez.bigtable.minsize.semijoin.reduction:设置当大表的行数达到该配置指定的行数时可以启用半连接。
● hive.tez.dynamic.semijoin.reduction:设置动态启用半连接操作进行过滤数据。
● hive.llap.execution.mode:配置Hive使用LLAP的模式,共有以下5种模式。
none:所有的操作都不使用LLAP。
map:只允许Map阶段的操作使用LLAP。
all:所有的操作都尽可能尝试使用LLAP,如果执行失败则使用容器的方式运行。
only:所有的操作都尽可能尝试使用LLAP,如果执行失败,则查询失败。auto:由Hive控制LLAP模式。
● hive.llap.object.cache.enabled:是否开启LLAP的缓存,缓存可以缓存执行计划、散列表。
● hive.llap.io.use.lrfu:指定缓存的策略为LRFU模式,替换掉默认FIFO模式。
● hive.llap.io.enabled:是否启用LLAP的数据I/O。
● hive.llap.io.cache.orc.size:LLAP缓存数据的大小,默认是1GB。
● hive.llap.io.threadpool.size:LLAP在进行I/O操作的线程池大小,默认为10。
● hive.llap.io.memory.mode:LLAP内存缓存的模式,共有以下3种模式。cache:将数据和数据的元数据放到自定义的堆外缓存中。
allocator:不使用缓存,使用自定义的allocator。
none:不使用缓存。因为上面两种方式有可能导致性能急剧下降。
● hive.llap.io.memory.size:LLAP缓存数据的最大值。
● hive.llap.auto.enforce.vectorized:是否强制使用向量化的运行方式,默认为true。
● hive.llap.auto.max.input.size、hive.llap.auto.min.input.size:是否检查输入数据的文件大小,如果为-1则表示不检查。
hive.llap.auto.max.input.size默认值为10GB, hive.llap. auto.min.input.size默认值为1GB。
以上是关于深入MapReduce计算引擎02的主要内容,如果未能解决你的问题,请参考以下文章