只了解MapReduce的Shuffle?Spark Shuffle了解一下
Posted 小猴学Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了只了解MapReduce的Shuffle?Spark Shuffle了解一下相关的知识,希望对你有一定的参考价值。
点击蓝字
作者 | 小猴
编辑 | 小猴
分享Java、大数据内容
# 本篇要解决的问题
Spark之前的HashShuffle会有什么问题?
说一下Spark中的HashShuffle的工作方式?
是不是HashShuffle一定比SortShuffle效率低?
说一下Spark中的SortShuffle的工作方式?
Spark中的SortShuffle和MapReduce Shuffle的区别?
1
Shuffle简介
1
请把MapReduce和Spark联系起来
最近发现,很多人在用Spark的时候,根本没法和MapReduce建立联系。还有人告诉我,Spark跟MapReduce没有关系。 “之前写的MapReduce必须要实现一个Mapper、Reducer,还要自己创建一个Job,让它执行起来。而现在写的Spark程序我只需要写算子就可以了。根本没有Mapper、Reducer”。
听完这句话,大家是不是有一种莫名的认同感 。因为大多数人学Spark的时候,也没有想着要与MapReduce建立联系。更有人说,现在谁还用MapReduce啊,学Spark就可以了。我可以很负责的告诉大家,如果大家没能把Spark和MapReduce建立关联,那基本上等于Spark没有学会。
。因为大多数人学Spark的时候,也没有想着要与MapReduce建立联系。更有人说,现在谁还用MapReduce啊,学Spark就可以了。我可以很负责的告诉大家,如果大家没能把Spark和MapReduce建立关联,那基本上等于Spark没有学会。
2
Spark shuffle简介
在Apache Spark中,Spark Shuffle描述了map任务和reduce任务之间的过程,Spark也只是MapReduce的一种实现而已,我们看到的各种算子操作,其实从根本上来讲还是Map和Reduce,只不过Spark提供了High Level API,让我们开发起来更简单而已。
Shuffle是Spark重新分配数据的一种机制,简单理解就是对数据进行重新分组。因为数据是分布式存储,每个分区的数据存储在不同的服务器中,所以在Shuffle期间,会写入到本地磁盘并在网络上传输。Shuffle操作是最昂贵的,这也说明Shuffle对Spark Job的性能影响是很大的。通过Shuffle,将数据从一个分区移动到另一个分区,这样方便用不同的方式组织数据,例如:分组、Join这些操作等(先别着急跟我说Broadcast Join)。
简单用一个图来描述:
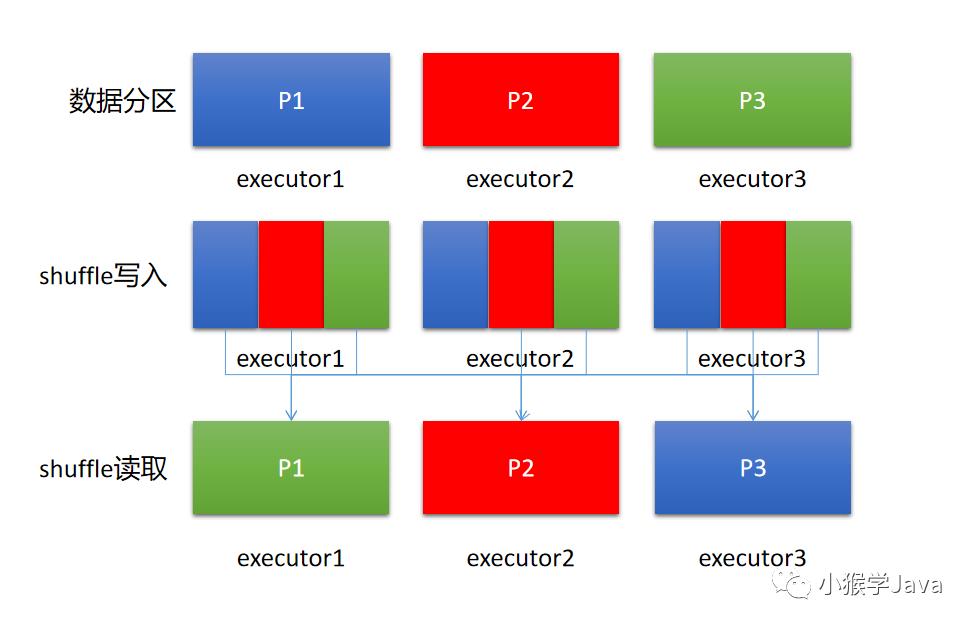
上图,我们假设使用每个executor处理一个分区的数据,在执行shuffle相关的算子操作,首先会进行shuffle写入(可理解为重新分区,例如:按照key重新分区)——这个阶段其实就类似于MapReduce的Map侧Shuffle。其他的Task(类似于Reduce侧Shuffle)会进行shuffle读取,拉取属于自己的那个分区。
3
Shuffle非常重要
在Spark程序运行过程中,有许多的任务需要对集群中的数据进行shuffle。例如:我们要通过某个字段来连接两个表,而在连接之前必须得保证所有该相同值的字段放在一起。如果该字段是一个整数,整数的范围是从1到5000W。这么大量的数据是无法直接进行表关联的。
我们需要进行分区处理。例如:字段值为1-100的存储在一个分区中,无需遍历第二张表的每个分区,直接将分区与分区进行关联。这样可以极大地缩小计算量,也使得大表关联成为可能。这里要求,两个表必须要有相同的分区,否则无法进行分区关联。大量数据的Shuffle并不总是一件坏事,我们通过Shuffle可以突破在内存上计算的限制。
通过这个示例,大家一定能感受到shuffle的重要性。
在RDD中,有这样的一些典型的shuffle操作:
subtractByKey
groupBy
foldByKey
reduceByKey
aggregateByKey
join
distinct
cogroup
2
Hash Shuffle与Sort Shuffle
1
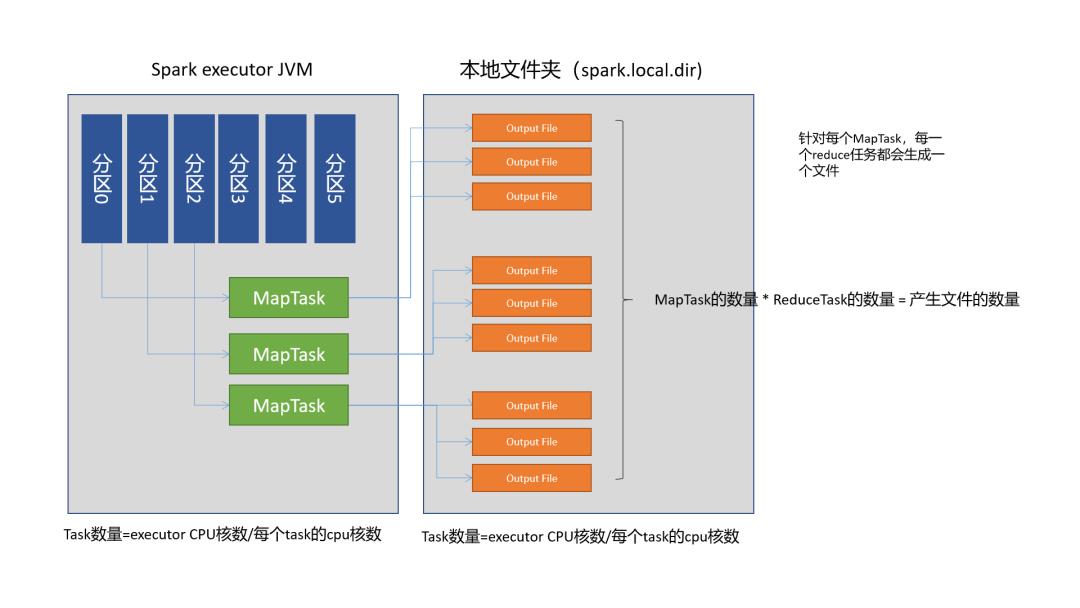
Hash Shuffle如何工作
在Spark 1.2之前,Hash Shuffle是Spark shuffle的默认Shuffle方式。这种shuffle方式有很多问题。Hash Shuffle针对每一个Reduce Task都会创建一个单独的文件,从而会导致有MapTask数量 * ReduceTask数量个文件总数。如果我们运行一个Job有大量的分区,这会导致很大的问题。它需要更多的输出缓冲区、FS需要打开文件的数量更多、创建和删除这些文件速度也会变慢。
这种shuffle的方式实现方式很直接:
计算Reducer的数量
为每一个分区创建一个单独的文件
遍历要输出的record,计算每一个record的分区
将record输出到文件。
2
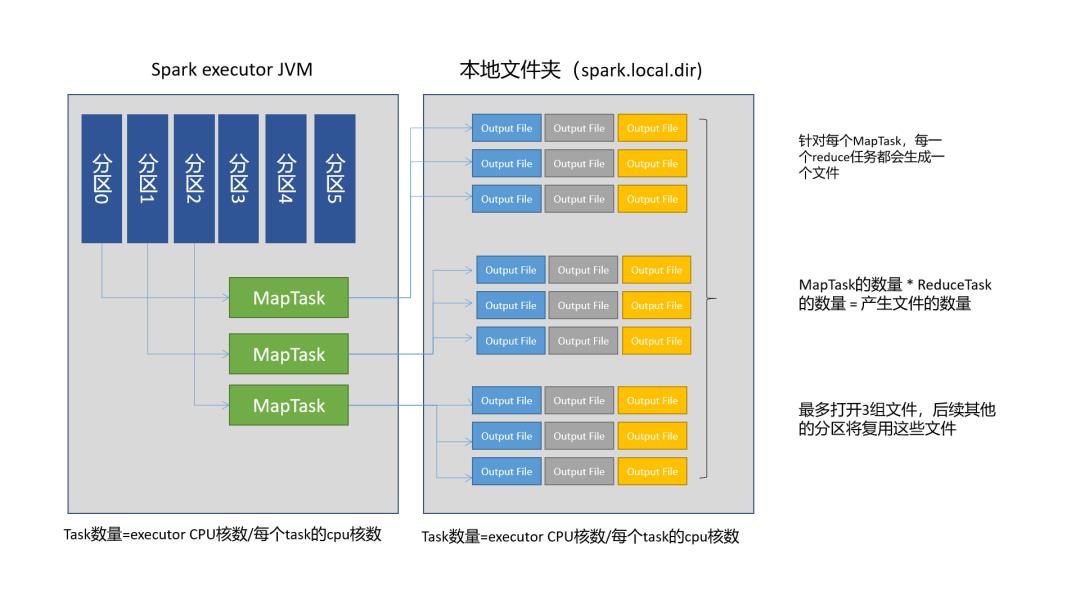
Spark对Hash Shuffle的优化
Hash Shuffle这样操作问题很大, Spark因此对它提供了优化。在1.2.x版本的Spark中,有这样的一个参数:spark.shuffle.consolidateFiles。默认为false,当设置它为true时,它可以将MapTask输出的文件进行合并。这种方式不是为每个Reducer创建一个文件,而是创建一个文件输出池。
假设:我们有JVM运行1个Executor,每个Executor上有4个Core可用于运行MapTask,每个Task一个core。所以该Executor最多并行执行4个MapTask。这种优化方式,每一次执行MapTask会打开一组文件,然后进行写入。并行最多打开3组文件。如果executor上要运行40个任务,那么下一次并行执行MapTask,将复用之前打开的文件继续输出。
3
Spark 2.0开始停用HashShuffle
通过GitHub,我们可以查看从Spark 2.0开始,ShuffleManager的实现只有一种:SortShuffle
https://github.com/apache/spark/tree/branch-2.0/core/src/main/scala/org/apache/spark/shuffle
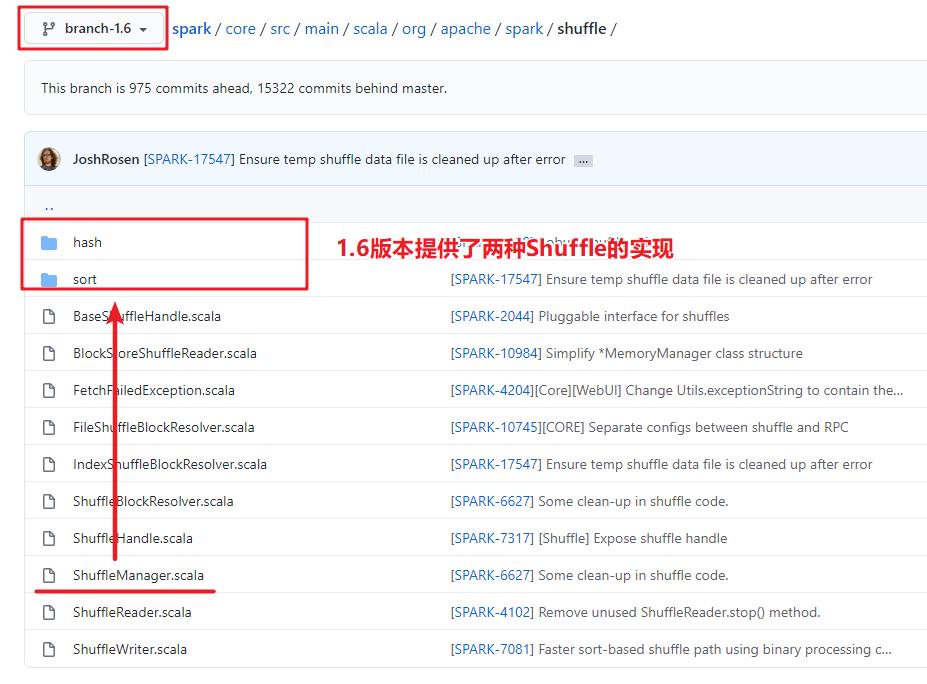
虽然Spark 2.0后没有了HashShuffle的实现,但它可以通过配置:spark.shuffle.sort.bypassMergeThreshold来达到HashShuffle类似的效果,默认为200。如果shuffle MapTask侧的任务数量是小于这个值,且没有Map侧的聚合,Spark在Map端是不会进行Merge-Sort的,这个过程其实就是HashShuffle。
4
Sort Shuffle如何工作
Sort shuffle有点类似于MapReduce的方式,对比于Hash Shuffle,MapTask针对每一个ReduceTask生成一个独立的文件,Sort Shuffle会按照分区Id进行排序,并为每个数据文件提供索引。通过索引可以快速地根据位置获取数据了,读取数据只需要执行一次fseek设置某个ReduceTask的开始读取的位置即可。
Sort Shuffle默认不会在MapTask对数据进行排序,分区数量少情况下也不会进行合并,除非在Reduce侧有Sort操作。在Shuffle阶段,如果没有足够的内存,就需要将数据spill到磁盘上。默认能使用的内存是 JVM堆内存大小 * 0.6 * 0.5,如果一个executor中运行了多个线程(R = executor.cores / task.cpus),还要除以R。假设JVM堆内存是800M,每个executor是运行2个任务,每个任务1个core,那就是 800 * 0.3 / 2 = 120M。超过120M就要进行spill了。
Spark使用:
spark.memory.fraction(默认:0.6)
spark.memory.storageFraction(默认:0.5)
两个参数控制Shuffle内存容量。
每个溢写文件都分别写入到磁盘中,Spark的spill并不会像MapReduce那样进行磁盘上的合并,ReduceTask请求从executor中拉取数据时,会对数据进行合并,然后ReduceTask开始拉取。
# 总结
Spark之前的HashShuffle会有什么问题?
产生大量小文件,Number(MapTask) * Number(ReduceTask),分区多了性能下降严重
说一下Spark中的HashShuffle的工作方式?
对key值进行哈希分区,每个MapTask针对每个ReduceTask生成一个文件,然后ReduceTask拉取文件进行计算。
是不是HashShuffle一定比SortShuffle效率低?
不一定,如果说分区数量小的话,HashShuffle速度很快,因为都是顺序读写。而Sort Shuffle会有一些随机IO,分区少的时候,没有HashShuffle快。但分区数量非常多,Sort Shuffle可以极大到介绍文件数量,提升IO效率。
说一下Spark中的SortShuffle的工作方式?
MapTask侧根据分区ID进行排序,输出到单独的一个文件中,ReduceTask拉取自己分区的数据。
Spark中的SortShuffle和MapReduce Shuffle的区别?
Spark排序会根据下游算子判断是否需要在MapTask侧排序,否则是不会按key排序的,而且Spark SortShuffle不会像MR那样内存→磁盘、磁盘→磁盘做Merge。直接在Reduce侧Merge。
THE
END
推荐你看 以上是关于只了解MapReduce的Shuffle?Spark Shuffle了解一下的主要内容,如果未能解决你的问题,请参考以下文章