从HBase Region无法写入的案例聊聊技术细节
Posted 安可数据库论坛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从HBase Region无法写入的案例聊聊技术细节相关的知识,希望对你有一定的参考价值。
许子文:去哪儿网数据库和大数据高级工程师
个人简介:曾任达梦高级数据库工程师,现任去哪儿网高级DBA,负责mysql、大数据及自动化运维工具开发。在RDBMS拥有多年数据库架构设计、性能优化和运维经验,尤其在海量数据有丰富的运维经验和个人见解。
最近HBase相关业务集群出现问题,我将问题记录下来并分享给大家,但由于本人技术有限,希望和大家能一起探讨进步,有不对的地方烦请指出。
问题出现
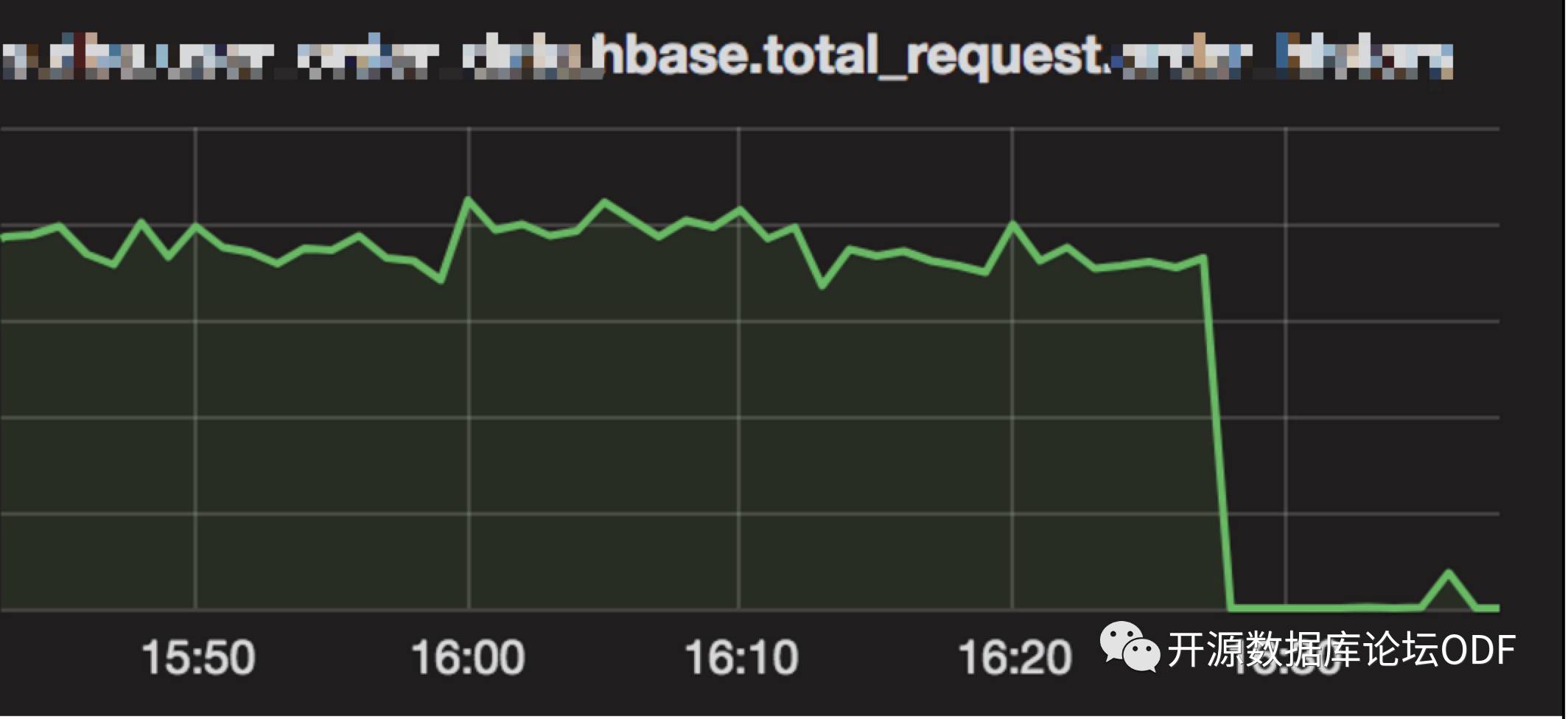
业务反应HBase写入出现问题,集中在表proble_table(别名)上。业务保存数据报错信息:
[2017-08-11 16:36:59 ERROR *******:92] hbase save error, rowKey=1005100419711447$28, content=170811.162748.10.88.106.206.6607.22303832 .... org.apache.hadoop.hbase.client.RetriesExhaustedWithDetailsException: Failed 1 action: RegionTooBusyException: 1 time
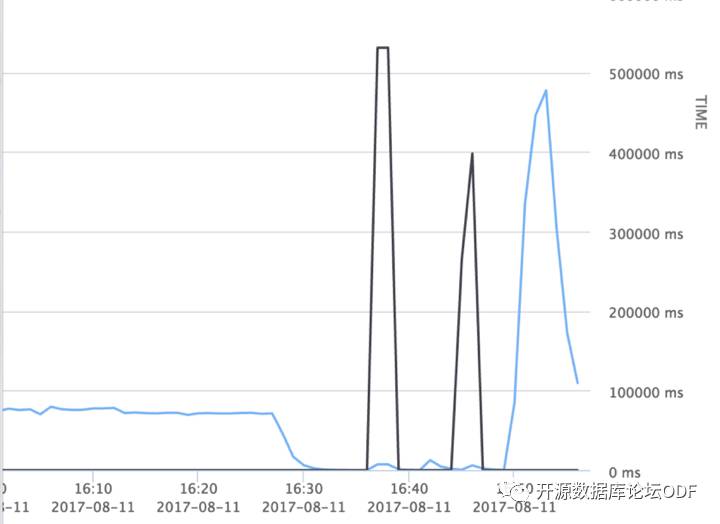
业务监控图显示表的写入量直线下降,(蓝线为写入量,黑线为响应时间)
问题分析
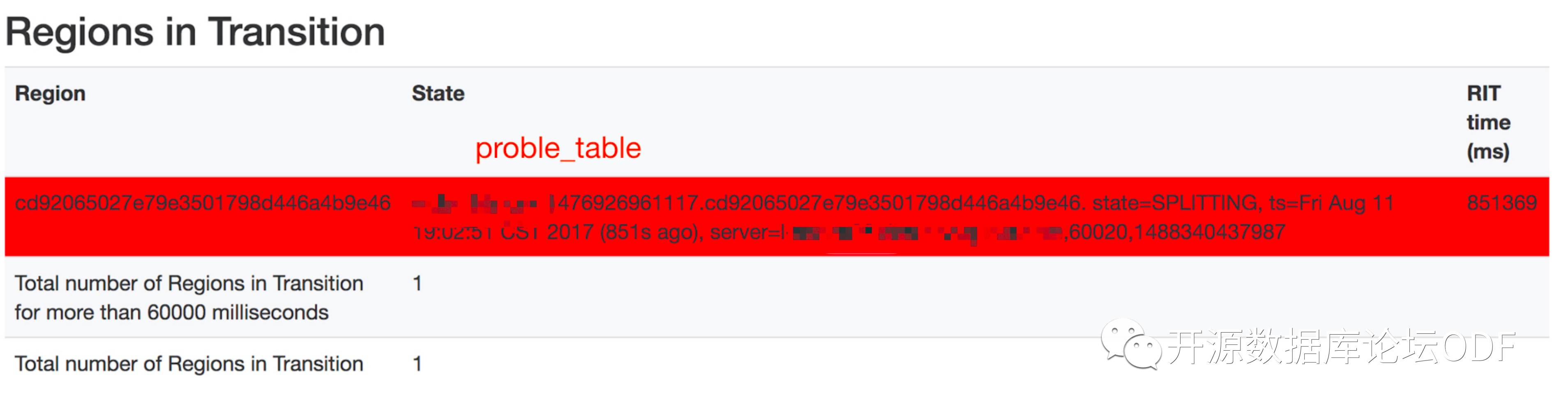
通过WEB UI (Regions in Transition)发现有一个Region Split很长时间都没有成功。
查看region信息:
100.2 G /hbase/*/proble_table/cd92065027e79e3501798d446a4b9e46
hbase配置hbase.hregion.max.filesize为107374182400触发split,目前看触发split正常,那为什么迟迟没有split完成?
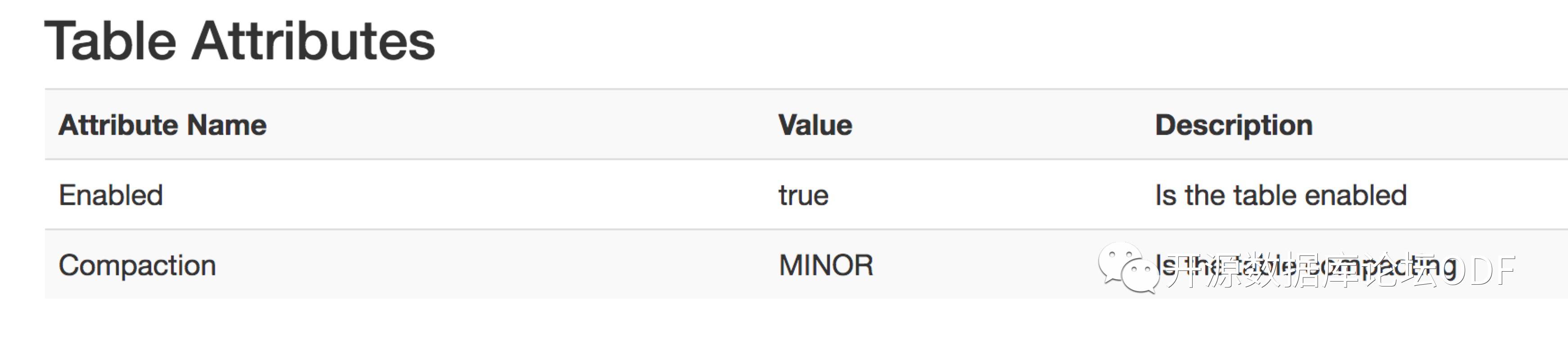
继续分析查看表的状态正在进行minor compact。
登录namenode执行hbase hbck(运维习惯性操作) 发现数据出现不一致,报错大量锁信息:
2017-08-11 16:49:51,344 INFO [main] lock.ZKInterProcessLockBase: Lock is held by: read-regionserver:600200000000013 ERROR: Table lock acquire attempt found:[tableName= proble_table, lockOwner=l-hbase100.dba(机器别名),60020,1482892096208, threadId=38000, purpose=SPLIT_REGION:proble_table, ,1476926961117.cd92065027e79e3501798d446a4b9e46., isShared=true, createTime=1502429990652] Summary:....希望持有该lock的regionserver列表....
应急处理
重启持有lock并且问题region cd92065027e79e3501798d446a4b9e46 所属的RegionServer l-hbase100.dba(机器别名) ,业务写入恢复正常。HBCK集群数据也一致。
问题原因
当问题出现并看到触发split和minor major时怀疑是数据量写入过大原因导致,并且是集中写入热点region(RegionTooBusyException)。咨询业务线的rowkey设计为:sysCode + orderNo + “$” + version (业务线编号+ 订单号+ version),而业务数据量是集中按业务线过来的,存在同一个regon的写入量增大的隐患。(吐槽下rowkey的设计,正常应该是orderNo放最前面,这样更分散。)
解析问题region的key-value如下:
1005100659272625$25/o 1005100659748320$25/o ... 1005100774729800$21/o 1005100777283044$28/o 1005100778905286$17/o
集群表相关的写入量,最大才3K,初步怀疑是单行过大的原因,但是每个key-value size业务反应并不大,单行过大被否决。(Tips:hbase.table.max.rowsize参数可以限制单行写入大小)
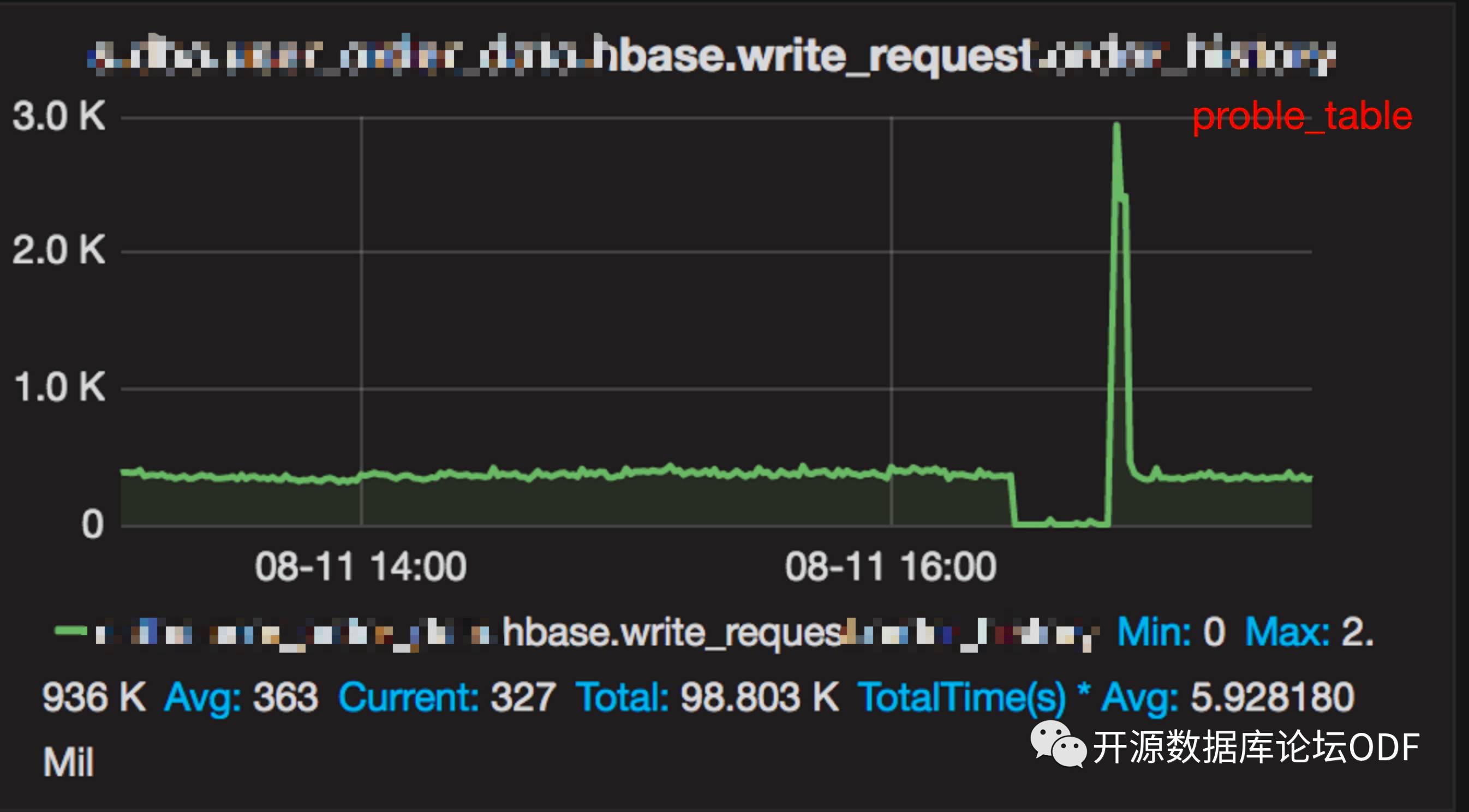
继续分析发现表proble_table(别名) region cd92065027e79e3501798d446a4b9e46 (来源于hbck持有锁报错的region)一直处于合并状态,并且时间特别长。

出现问题时该region的hfile个数是30个(hbase.hstore.blockingStoreFiles=30)触发写入阻塞 ,该region大小为100G(hbase.hregion.max.filesize=100G)需要进行split。初步怀疑是split需要持有相关hfile的锁,而hfile一直compact不完成无法释放相关锁导致死循环, region hfile文件数=30触发阻塞写,该表写入很慢进而阻塞业务消息。
事后分析发现hbck有相关锁冲突是因为split需要获取表锁,而hbck也需要获取表锁(来源hbck的信息ERROR: Table lock acquire attempt found)。
继续分析split时的log信息,发现如下日志:
2017-08-11 13:39:50,787 DEBUG [regionserver60020-splits-1483311994063] regionserver.HRegion: Closing proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46.: disabling compactions & flushes 2017-08-11 13:39:50,787 DEBUG [regionserver60020-splits-1483311994063] regionserver.HRegion: waiting for 1 compactions to complete for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46.
出现写入异常时间点的相关日志如下:
2017-08-11 16:39:53,617 DEBUG [MemStoreFlusher.0] regionserver.HRegion: NOT flushing memstore for region proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46., flushing=false, writesEnabled=false 2017-08-11 16:39:53,617 DEBUG [MemStoreFlusher.0] regionserver.CompactSplitThread: Split requested for proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46.. compaction_queue=(0:0), split_queue=412, merge_queue=0 2017-08-11 16:40:00,975 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 10411 2017-08-11 16:40:10,975 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 16379 2017-08-11 16:40:11,386 DEBUG [MemStoreFlusher.3] regionserver.HRegion: NOT flushing memstore for region proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46., flushing=false, writesEnabled=false 2017-08-11 16:40:11,386 DEBUG [MemStoreFlusher.3] regionserver.CompactSplitThread: Split requested for proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46.. compaction_queue=(0:0), split_queue=413, merge_queue=0 2017-08-11 16:40:20,976 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 8235 2017-08-11 16:40:29,212 DEBUG [MemStoreFlusher.3] regionserver.HRegion: NOT flushing memstore for region proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46., flushing=false, writesEnabled=false 2017-08-11 16:40:29,212 DEBUG [MemStoreFlusher.3] regionserver.CompactSplitThread: Split requested for proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46.. compaction_queue=(0:0), split_queue=414, merge_queue=0 2017-08-11 16:40:30,975 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 16180 2017-08-11 16:40:40,975 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 8687 2017-08-11 16:40:47,155 DEBUG [MemStoreFlusher.3] regionserver.HRegion: NOT flushing memstore for region proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46., flushing=false, writesEnabled=false 2017-08-11 16:40:47,155 DEBUG [MemStoreFlusher.3] regionserver.CompactSplitThread: Split requested for proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46.. compaction_queue=(0:0), split_queue=415, merge_queue=0 2017-08-11 16:40:50,976 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 15599 2017-08-11 16:41:00,975 INFO [regionserver60020.periodicFlusher] regionserver.HRegionServer: regionserver60020. periodicFlusher requesting flush for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46. after a delay of 8402 2017-08-11 16:41:06,575 DEBUG [MemStoreFlusher.3] regionserver.HRegion: NOT flushing memstore for region proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46., flushing=false, writesEnabled=false 2017-08-11 16:41:06,575 DEBUG [MemStoreFlusher.3] regionserver.CompactSplitThread: Split requested for proble_table,, 1476926961117.cd92065027e79e3501798d446a4b9e46.. compaction_queue=(0:0), split_queue=416, merge_queue=0
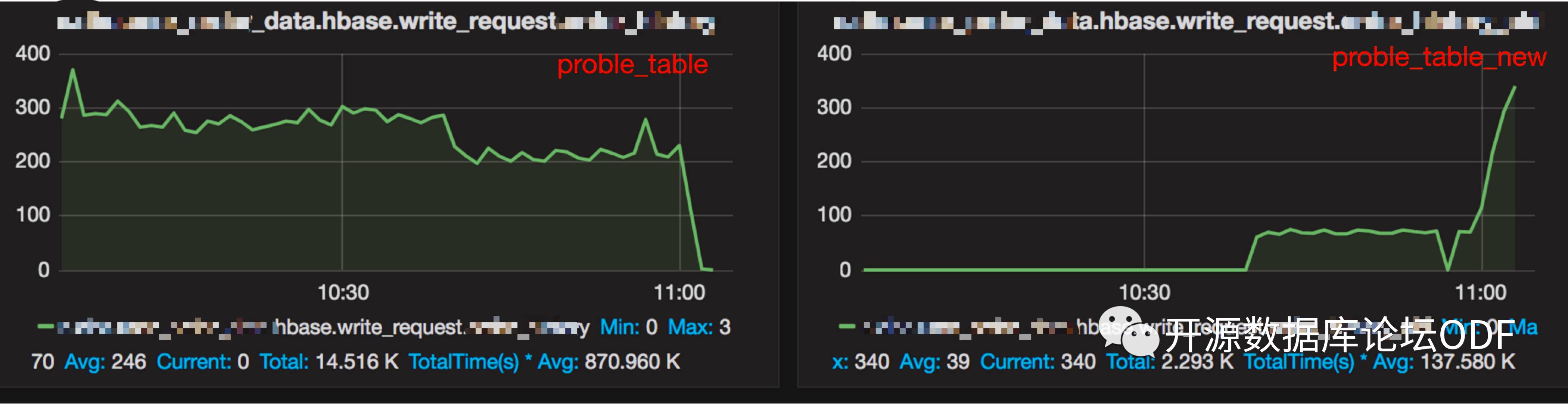
怀疑是该region compact和split冲突导致问题,尝试进行重现,当向该region进行写入时触发split后该表的写入量直线下降(被阻塞)。
那么为什么region split无法完成呢?首先说下region split的约束条件:
a)RegionServer 线上Region数量 < hbase.regionserver.regionSplitLimit,默认值1000。 b)StoreFile文件数量< hbase.hstore.blockingStoreFiles,否则优先Compact。 c)region不属于meta table d)region非RIT状态。
第二点约束条件很重要,split的优先级并没有compact高,再次分析split的日志可以看出问题:
Closing proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46.: disabling compactions & flushes
父region关闭,开启两个子region,关闭父region需要先disable compactions & flushed。而由于region compact一直卡住没完成,因此需要等待完成。
regionserver.HRegion: waiting for 1 compactions to complete for region proble_table,,1476926961117.cd92065027e79e3501798d446a4b9e46.
split一直处于运行状态会定期去尝试是否可以split,否则入队split_queue(),Region无法写入的时的split_queue已经达到400。
那么为什么出现region无法合并完成?
经过一阵时间的资料查询是由于表结构设置编码格式为PREFIX_TREE,触发了DATA_BLOCK_ENCODING 的BUG(HBASE-12959 Compact never end when table’s dataBlockEncoding using PREFIX_TREE ),导致compaction卡住不释放,修改DATA_BLOCK_ENCODING => NONE 也会卡住执行不成功(可以作为确定触发bug的方法),如果没有触发bug则会alter成功。
因为compact无法完成那么region split无法完成就很好理解了(split need disabling compactions & flushes)。
确定问题后有如下解决方案:
1)将问题region的数据导出来后,直接删除hdfs file后hbck repair修复后导入数据。(成本高) 2)新建一张业务表写入和查询,现有表只供查询不提供写入。 3)问题region的范围不再新写入key,如有key写入则业务重定向(hash或key处理)到其它region上,确保问题的region不再有写入。 4)修改单个region的最大文件大小为150G,加大hbase.hstore.blockingStoreFiles(临时解决方案),业务可以继续写入该region。
因为临近周末,采用临时方案处理。工作日后选择新建表后切换读写。
问题小结
很早就发现此region一直处于合并状态,并尝试将线上表alter DATA_BLOCK_ENCODING => NONE;但是该表的部分数据有问题导致BUG已经触发,修改ENCODING也卡住。由于当时region数据量很小、业务反馈写入量也不会很大,因此不会触发split且HFile数不会到hbase.hstore.blockingStoreFiles,所以该问题一直放着没有处理。
但该region的业务量日积月累的写入并达到100G时触发split,因为compact无法完成导致hfile个数越来越多,达到hbase.hstore.blockingStoreFiles后阻塞写入。
问题小结:建议HBase 表定义默认DATA_BLOCK_ENCODING => NONE即可,不要设置为PREFIX_TREE ,压缩使用SNAPPY。 如果修改ENCODING卡住则确定触发BUG,顺利alter成功则正常。整个运维过程中涉及到了region split 、hbase compact及hbck操作,这些都是hbase的技术细节,只有掌握到位才能运维得心应手,接下来聊聊这些技术细节。
技术细节
Region Split
Region大小超过阀值(可以是hbase.hregion.max.filesize也可以是建表时列族配置的大小)后会触发Split,由RegionServer负责来拆分region并且offline下线该region。随后将两个子region添加到hbase:meta并在RegionServer上打开后汇报给HMaster。默认情况下Region会自动触发split,同时也可以手动运行split命令。
Region Split可以手动split也可以自动split(建议),其中手动split region往往是在region出现热点时或者自动负载不均衡时通过手动split后move region来更好进行负载均衡。怎么进行Region呢?初步印象可以理解为折半拆分,每个子region是父region(原region)的一半。如图:
Region Split相关的参数如下:
配置参数
默认值
hbase.hregion.max.filesize |
hbase.hregion.max.filesize10737418240 (10GB) |
hbase.regionserver.region.plit.policy |
IncreasingToUpperBoundRegionSplitPolicy(0.94版本后) |
hbase.regionserver.regionSplitLimit |
1000 |
hbase.client.keyvalue.maxsize |
10485760 (10MB) |
Qunar HBase配置
hbase.regionserver.region.split.policy为org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy hbase.hregion.max.filesize为100G,为了避免拆分IO风暴。 hbase.hstore.blockingStoreFiles为30。 hbase.regionserver.regionSplitLimit配置用来限制region的数量,默认值是1000个region。
Region Split策略
HBase region split的策略由参数hbase.regionserver.region.split.policy配置。
0.94之前默认拆分策略是org.apache.hadoop.hbase.regionserver. ConstantSizeRegionSplitPolicy,该策略是基于Region配置的最大大小,由参数hbase.hregion.max.filesize指定。当Region的StoreFiles大小之和超过了hbase.hregion.max.filesize设置时,Region将被拆分。默认值是10GB。
自0.94版本后,默认策略是org.apache.hadoop.hbase.regionserver. IncreasingToUpperBoundRegionSplitPolicy,该策略是基于RegionServer上表中region个数的平方乘以memstore size 得出split region的大小,每次split的region大小并不相同,具体算法:
regionsize = Min (R^2 * “MEMSTORE_FLUSHSIZE”||”hbase.hregion.memstore.flush.size”,”hbase.hregion.max.filesize”),最大为hbase.hregion.max.filesize。
其中R为region所在regionserver上该table的region数。MEMSTORE_FLUSHSIZE为建表是DDL定义的大小,如果没有指定则使用hbase.hregion.memstore.flush.size 。
默认hbase-site文件配置hbase.hregion.memstore.flush.size 设定大小为128M,hbase.hregion.max.filesize设定大小为10G。
举例:表定义没有指定MEMSTORE_FLUSHSIZE,hbase.hregion.memstore.flush.size默认128M,hbase.hregion.max.filesize默认10G。 那么第一个region 是memstore刷盘到HFile的大小,即 1*1*128M=128M,生成一个region。 (1*1是region个数的平方) 当region数达到2个时,2*2*128M=512M。 (2*2是region个数的平方) 当region数达到3个时,3*3*128M=1152M。 (3*3是region个数的平方) ...依此类推... 当region数达到9个时,9*9*128M= 10368M > 10G。从第10个region开始每个region最大大小为10G(hbase.hregion.max.filesize)
同时还有一种策略是KeyPrefixRegionSplitPolicy,通过rowkey前缀位数来划分region,策略适合固定前缀的rowkey。
Qunar方便运维和管理统一使用的ConstantSizeRegionSplitPolicy(什么时候触发region split一目了然)。
Region Split流程
Region Split的流程如下:
1.客户端向RegionServer发送写入请求。 2.数据写入到内存memstore。 3.当memstore被填满并达到阀值,存储在内存中的数据被写入到磁盘生成HFiles,过程叫做memstore flush。 4.随着HFiles的增加,regionserver通过compact来将文件压缩成较大的文件。 5.region的数据量增加。 6.RegionServer根据region split的策略确定所属的region是否应该进行region split。 7.如果需要进行region split,则将region split请求加入到队列中(split_queue)
但是一个region实际是如何进行split呢? 是否会在某一个row key上进行split? split region会做什么?会发生什么?
RegionServer是通过如下流程进行region拆分:
1.当RegionServer确定需要对某个region进行拆分操作时,它将启动一个拆分事务。RegionServer首先会在表上获取一个共享锁 来防止拆分期间的schema修改。之后会在ZooKeeper中 /hbase/region-in-transition/region-name节点下创建一个znode,并将 znode状态设置为SPLITTING。 HMaster监视znode /hbase/region-in-transition时发现region(父region)需要开始拆分。 2.RegionServer在HDFS的region目录中创建一个名为.splits子目录,关闭父region并下线要拆分的父Region(本地数据结构标记 为下线)。客户端发送到给拆分region的请求都会获取到NotServingRegionException异常触发重试,该Region(父region)不再接受任何请求。 3.RegionServer在 .splits目录下(多线程并行)创建两个子region目录并创建必要的数据结构。 4.RegionServer创建两个引用文件并且引用文件指向父region的文件。 5.RegionServer在HDFS中真正创建子region目录(后续online),并将引用文件传送到相应的子region目录。 6.RegionServer向hbase:meta表发送put请求,将新建的两个子region和rowkey范围写入meta表并将父region标记为offline。在信息 没有加入到meta表之前,Client能查找到的只是父region,并不会查到新建的两个子region,同时子region在zk中的状态为SPLITTING_NEW。 如果数据写入hbase:meta成功,则region已经有效的完成拆分。如果RegionServer在单次RPC成功完成之前返回失败,则Master和 下一个RegionServer会重新打开该父region将清除有关该region拆分的脏状态和数据。如果hbase:meta更新成功完成,HBase则继续 region split的流程。如果拆分失败,则父region状态从SPLITTING变为OPEN,并且两个子region的状态从SPLITTING_NEW变为OFFLINE。 7.RegionServer并行的打开两个子region。 8.RegionServer将新region添加到hbase:meta并online。 9.之后客户端的相关请求会定向到新region并发送请求,客户端hbase:meta历史缓存被清除(因为父region已经下线,缓存非最新数据) 并从hbase:meta获取新region的信息并缓存。 10.RegionServer更新zk中znode /hbase/region-in-transition/region-name为split状态,新region的状态从SPLITTING_NEW为OPEN。 HMaster从znode发现更新,如果此时需要进行负载均衡,Hmaster会将两个子region重新分配给其它regionserver。整个region split过程完成。 对hbase中父reigon的引用会在hbase:meta和HDFS中通过compact来删除。删除过程中HMaster会定期检查子region是否还有引用指向 父region,如果没有指向,则将父region删除。
Tips:region split需要获取表锁,拆分过程中所有步骤依赖于zk,通过znode的状态进行跟踪,保证当split过程中出现问题时其它的进程能直到region的状态。
Compact
HBase合并一直是运维过程中的重点,这里打算简单说下。后续有时间整理单独的文章进行细节性总结,不是懒,是因为太多了(手动捂脸)。
HBase的写入流程是优先写WAL来实现数据不丢失,然后数据写入内存中的memstore,当memstore中数据达到给定的阀值后触发刷盘生成HFile。通过滚动memstore将数据移出内存同时丢弃对应的提交日志,内存中只保存数据为持久化道磁盘的日志。(滚动memstore是空的新memstore获取数据写入,满的memstore转存为HFile文件后移除内存)。
HBase的写入流程随着memstore中的数据不断刷写到磁盘,产生的HFile文件越来越多,HBase采用合并的方式来解决该问题。合并是指将多个文件合并成一个较大的文件。合并类型有:小合并 minor compaction 和大合并 major compaction。
小合并(minor compaction)是将多个小文件重写为数量较少的大文件,减少存储文件的数量。算法是多路合并,因为HFile文件本身是有序(memstore刷hfile前会在内存排序)的并经过归类的,所以合并速度很快,取决于磁盘IO的能力。设置minor合并处理最小文件数量由参数hbase.hstore.compaction.min设置,默认值是3。该属性最小值需要大于或等于2,过大的数字将会延迟minor合并的执行,同时也会增加执行时消耗的资源和执行时间。设置minor合并处理最大文件数量由参数hbase.hstore.compaction.max设置,默认值是10。设置合并文件大小限制是由参数hbase.hstore.compaction.max.size设置,默认值是Long.Max_VALUE,任何大于该参数值的HFile都不会参与合并。
大合并(major compaction)是将一个region中一个列族的若干个HFile重写为一个新HFile,major合并负责把所有文件压缩成一个单独的文件,在执行压缩检查时,系统自动决定运行哪种合并。
大合并和小合并不同的是:大合并能扫描所有的键值对,顺序重写全部的数据,重写数据的过程会跳过删除标记的数据,对于那些超过版本号限制和生存时间到期的数据,在重写数据时同样不会重写入新HFile。
合并和拆分在运维过程中需要考虑IO风暴的问题,避免磁盘IO压力。原因是如果HBase region按照预定的速度进行增长,触发region split的时间可能在同一时间进行,region split本身会有IO开销,当同时进行major compact时则会引起IO风暴,因此运维过程中建议手动进行split和手动进行compact。手动split的方法是将hbase.hregion.max.filesize值设置得很大(例如100G,不会经常或触发不了split),手动compact则是设置参数hbase.hregion.majorcompaction为0,凌晨通过cron定时运行大合并。
通过手动管理split和major compact能避免操作在不同的region上错开执行,避免IO集中,降低IO负载来避免拆分/合并风暴。
注意目前hbase flush和compaction操作是针对一个Region。其中Compaction操作是根据一个列族下的全部文件的数量触发的,而不是根据文件大小触发的。当一个列族操作大量数据的时候会引发一个flush,如果有多个列族则会将那些不相关的列族也进行flush操作。当很多的列族在flush和compaction时,会造成很多没用的I/O负载,要想解决这个问题需要将flush和compaction操作只针对一个列族,即创建表时指定一个列族 。
针对IO瓶颈可以适当考虑使用SSD作为存储,例如我们某个业务的统计分析集群就是使用Shannon SSD进行加速满足性能需求。综合考虑业务场景(例如历史订单和实时推荐系统)和成本,HBase可以考虑使用SSD进行性能加速,HBase自身由于数据读取多种路径(优先在memstore读取最新写入数据其次在blockcache读取缓存数据最后从磁盘HFile文件加载到内存读取数据),同时原生HBase不支持二级索引导致要么通过rowkey查询要么全表扫描,查询性能通常比RDBMS差一些(当然HBase读延时也有很多优化手段,有时间可以总结),如果将热点数据能够全部加载到block cache(RAM/SSD)或者通过SSD加速HFile读取,HBase读写性能将大大提升,另外BucketCache file模式同样是建议使用SSD存储加速性能。官方同样对SSD做了相关的优化,详情见
HBase hbck
hbck是HBase的管理用具,用于检查或修复HBase,当HBase集群中出现不一致的地方时hbck会格式化输出。hbck经常用于检查region一致性和表完整性。hbck工具运行会扫描整个.META表来收集表相关信息,会访问所有RegionServer以及读取所有table region里的regioninfo,所以hbck操作很重并且需要获取表锁。 同时运维过程中需要知道hbck 报告有可能是暂时的,例如region split或某个时间不可用时hbck也会打印这些不一致信息。可以加上-details参数获取详细信息并多次运行hbck确定问题是否是暂时的。
常用例子
修复region一致性:hbase hbck -fixAssignments 修复region在HDFS和META信息不一致: hbase hbck -fixAssignments -fixMeta 修复 region空洞或起止rowkey重叠问题: hbase hbck -repairHoles 或 hbase hbck -repair META没有被分配,则将其正确分配: hbase hbck -fixMetaOnly -fixAssignments META表损坏: hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair 离线父region发生split: hbase hbck -fixSplitParents HBase版本文件丢失: hbase hbck -fixVersionFile
参考资料:
https://hbase.apache.org/book.html
https://issues.apache.org/jira/browse/HBASE-12959
http://hbasefly.com/2016/07/02/hbase-pracise-cfsetting/ (强烈推荐此blog,博主万事通)
《Apach HBase Primer》
《Learning HBase》
《HBase 权威指南》
开源数据库论坛(台北)将于10.27-28在国立台北商业大学举办,请参考最下阅读原文关注。
以上是关于从HBase Region无法写入的案例聊聊技术细节的主要内容,如果未能解决你的问题,请参考以下文章