HBase原理-数据读取流程解析
Posted 大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase原理-数据读取流程解析相关的知识,希望对你有一定的参考价值。
 大 数 据
大 数 据
专注于前沿大数据案例资讯
和写流程相比,HBase读数据是一个更加复杂的操作流程,这主要基于两个方面的原因:其一是因为整个HBase存储引擎基于LSM-Like树实现,因此一次范围查询可能会涉及多个分片、多块缓存甚至多个数据存储文件;其二是因为HBase中更新操作以及删除操作实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本。删除操作也并没有真正删除原有数据,只是插入了一条打上”deleted”标签的数据,而真正的数据删除发生在系统异步执行Major_Compact的时候。很显然,这种实现套路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁,读取过程需要根据版本进行过滤,同时对已经标记删除的数据也要进行过滤。
总之,把这么复杂的事情讲明白并不是一件简单的事情,为了更加条理化地分析整个查询过程,接下来笔者会用两篇文章来讲解整个过程,首篇文章主要会从框架的角度粗粒度地分析scan的整体流程,并不会涉及太多的细节实现。大多数看客通过首篇文章基本就可以初步了解scan的工作思路;为了能够从细节理清楚整个scan流程,接着第二篇文章将会在第一篇的基础上引入更多的实现细节以及HBase对于scan所做的基础优化。因为理解问题可能会有纰漏,希望可以一起探讨交流,欢迎拍砖~
Client-Server交互逻辑
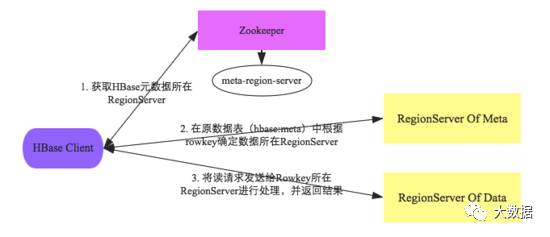
根据hbase:meta所在RegionServer的访问信息,客户端会将该元数据表加载到本地并进行缓存。然后在表中确定待检索rowkey所在的RegionServer信息。
根据数据所在RegionServer的访问信息,客户端会向该RegionServer发送真正的数据读取请求。服务器端接收到该请求之后需要进行复杂的处理,具体的处理流程将会是这个专题的重点。
通过上述对客户端以及HBase系统的交互分析,可以基本明确两点:
客户端会将hbase:meta元数据表缓存在本地,因此上述步骤中前两步只会在客户端第一次请求的时候发生,之后所有请求都直接从缓存中加载元数据。如果集群发生某些变化导致hbase:meta元数据更改,客户端再根据本地元数据表请求的时候就会发生异常,此时客户端需要重新加载一份最新的元数据表到本地。
-----------------此处应有华丽丽的分隔线----------------
RegionServer接收到客户端的get/scan请求之后,先后做了两件事情:构建scanner体系(实际上就是做一些scan前的准备工作),在此体系基础上一行一行检索。举个不太合适但易于理解的例子,scan数据就和开发商盖房一样,也是分成两步:组建施工队体系,明确每个工人的职责;一层一层盖楼。
构建scanner体系-组建施工队
scanner体系的核心在于三层scanner:RegionScanner、StoreScanner以及StoreFileScanner。三者是层级的关系,一个RegionScanner由多个StoreScanner构成,一张表由多个列族组成,就有多少个StoreScanner负责该列族的数据扫描。一个StoreScanner又是由多个StoreFileScanner组成。 每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成,相对应的,StoreScanner对象会雇佣一个MemStoreScanner和N个 StoreFileScanner 来进行实际的数据读取,每个StoreFile文件对应一个 StoreFileScanner, 注意:StoreFileScanner和MemstoreScanner是整个scan的最终执行者 。
对应于建楼项目,一栋楼通常由好几个单元楼构成(每个单元楼对应于一个Store),每个单元楼会请一个监工(StoreScanner)负责该单元楼的建造。而监工一般不做具体的事情,他负责招募很多工人(StoreFileScanner),这些工人才是建楼的主体。下图是整个构建流程图:
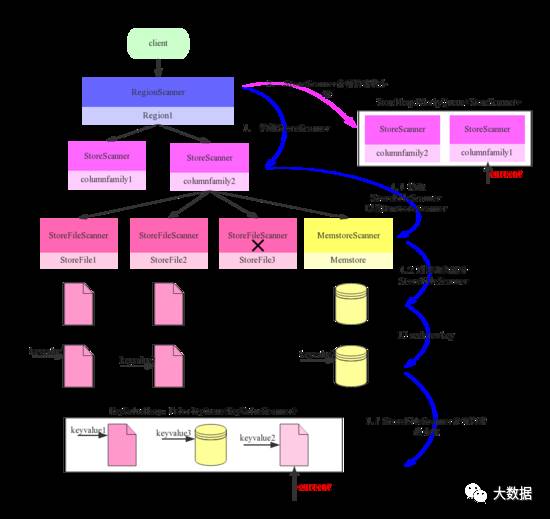
RegionScanner会根据列族构建StoreScanner,有多少列族就构建多少StoreScanner,用于负责该列族的数据检索
1.1 构建StoreFileScanner:每个StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于实际执行对应文件的检索。同时会为对应Memstore构造一个MemstoreScanner,用于执行该Store中Memstore的数据检索。 该步骤对应于监工在人才市场招募建楼所需的各种类型工匠。
1.2 过滤淘汰StoreFileScanner:根据Time Range以及RowKey Range对StoreFileScanner以及MemstoreScanner进行过滤,淘汰肯定不存在待检索结果的Scanner。上图中StoreFile3因为检查RowKeyRange不存在待检索Rowkey所以被淘汰。该步骤针对具体的建楼方案,裁撤掉部分不需要的工匠,比如这栋楼不需要地暖安装,对应的工匠就可以撤掉。
1.3 Seek rowkey:所有StoreFileScanner开始做准备工作,在负责的HFile中定位到满足条件的起始Row。工匠也开始准备自己的建造工具,建造材料,找到自己的工作地点,等待一声命下。就像所有重要项目的准备工作都很核心一样,Seek过程(此处略过Lazy Seek优化)也是一个很核心的步骤,它主要包含下面三步:
定位Block Offset:在Blockcache中读取该HFile的索引树结构,根据索引树检索对应RowKey所在的Block Offset和Block Size
Load Block:根据BlockOffset首先在BlockCache中查找Data Block,如果不在缓存,再在HFile中加载
Seek Key:在Data Block内部通过二分查找的方式定位具体的RowKey
整体流程细节参见 《HBase原理-探索HFile索引机制》 ,文中详细说明了HFile索引结构以及如何通过索引结构定位具体的Block以及RowKey
1.4 StoreFileScanner合并构建最小堆:将该Store中所有StoreFileScanner和MemstoreScanner合并形成一个heap(最小堆),所谓heap是一个优先级队列,队列中元素是所有scanner,排序规则按照scanner seek到的keyvalue大小由小到大进行排序。这里需要重点关注三个问题,首先为什么这些Scanner需要由小到大排序,其次keyvalue是什么样的结构,最后,keyvalue谁大谁小是如何确定的:
为什么这些Scanner需要由小到大排序?
最直接的解释是scan的结果需要由小到大输出给用户,当然,这并不全面,最合理的解释是只有由小到大排序才能使得scan效率最高。举个简单的例子,HBase支持数据多版本,假设用户只想获取最新版本,那只需要将这些数据由最新到最旧进行排序,然后取队首元素返回就可以。那么,如果不排序,就只能遍历所有元素,查看符不符合用户查询条件。这就是排队的意义。
工匠们也需要排序,先做地板的排前面,做墙体的次之,最后是做门窗户的。做墙体的内部还需要再排序,做内墙的排前面,做外墙的排后面,这样,假如设计师临时决定不做外墙的话,就可以直接跳过外墙部分工作。很显然,如果不排序的话,是没办法临时做决定的,因为这部分工作已经可能做掉了。
HBase中KeyValue是什么样的结构?
HBase中KeyValue并不是简单的KV数据对,而是一个具有复杂元素的结构体,其中Key由RowKey,ColumnFamily,Qualifier ,TimeStamp,KeyType等多部分组成,Value是一个简单的二进制数据。Key中元素KeyType表示该KeyValue的类型,取值分别为Put/Delete/Delete Column/Delete Family四种。KeyValue可以表示为如下图所示:
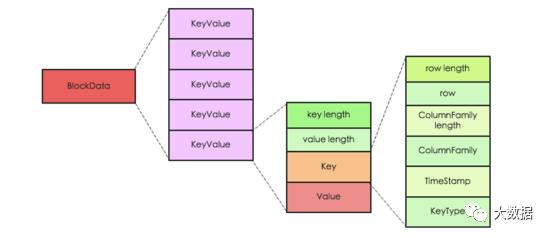
了解了KeyValue的逻辑结构后,我们不妨再进一步从原理的角度想想HBase的开发者们为什么如此对其设计。这个就得从HBase所支持的数据操作说起了,HBase支持四种主要的数据操作,分别是Get/Scan/Put/Delete,其中Get和Scan代表数据查询,Put操作代表数据插入或更新(如果Put的RowKey不存在则为插入操作、否则为更新操作),特别需要注意的是HBase中更新操作并不是直接覆盖修改原数据,而是生成新的数据,新数据和原数据具有不同的版本(时间戳);Delete操作执行数据删除,和数据更新操作相同,HBase执行数据删除并不会马上将数据从数据库中永久删除,而只是生成一条删除记录,最后在系统执行文件合并的时候再统一删除。
HBase中更新删除操作并不直接操作原数据,而是生成一个新纪录,那问题来了,如何知道一条记录到底是插入操作还是更新操作亦或是删除操作呢?这正是KeyType和Timestamp的用武之地。上文中提到KeyType取值为分别为Put/Delete/Delete Column/Delete Family四种,如果KeyType取值为Put,表示该条记录为插入或者更新操作,而无论是插入或者更新,都可以使用版本号(Timestamp)对记录进行选择;如果KeyType为Delete,表示该条记录为整行删除操作;相应的KeyType为Delete Column和Delete Family分别表示删除某行某列以及某行某列族操作;
不同KeyValue之间如何进行大小比较?
上文提到KeyValue中Key由RowKey,ColumnFamily,Qualifier ,TimeStamp,KeyType等5部分组成,HBase设定Key大小首先比较RowKey,RowKey越小Key就越小;RowKey如果相同就看CF,CF越小Key越小;CF如果相同看Qualifier,Qualifier越小Key越小;Qualifier如果相同再看Timestamp,Timestamp越大表示时间越新,对应的Key越小。如果Timestamp还相同,就看KeyType,KeyType按照DeleteFamily -> DeleteColumn -> Delete -> Put 顺序依次对应的Key越来越大。
2. StoreScanner合并构建最小堆:上文讨论的是一个监工如何构建自己的工匠师团队以及工匠师如何做准备工作、排序工作。实际上,监工也需要进行排序,比如一单元的监工排前面,二单元的监工排之后… StoreScanner一样,列族小的StoreScanner排前面,列族大的StoreScanner排后面。
scan查询-层层建楼
构建Scanner体系是为了更好地执行scan查询,就像组建工匠师团队就是为了盖房子一样。scan查询总是一行一行查询的,先查第一行的所有数据,再查第二行的所有数据,但每一行的查询流程却没有什么本质区别。盖房子也一样,无论是盖8层还是盖18层,都需要一层一层往上盖,而且每一层的盖法并没有什么区别。所以实际上我们只需要关注其中一行数据是如何查询的就可以。
对于一行数据的查询,又可以分解为多个列族的查询,比如RowKey=row1的一行数据查询,首先查询列族1上该行的数据集合,再查询列族2里该行的数据集合。同样是盖第一层房子,先盖一单元的一层,再改二单元的一层,盖完之后才算一层盖完,接着开始盖第二层。所以我们也只需要关注某一行某个列族的数据是如何查询的就可以。
还记得Scanner体系构建的最终结果是一个由StoreFileScanner和MemstoreScanner组成的heap(最小堆)么,这里就派上用场了。下图是一张表的逻辑视图,该表有两个列族cf1和cf2(我们只关注cf1),cf1只有一个列name,表中有5行数据,其中每个cell基本都有多个版本。cf1的数据假如实际存储在三个区域,memstore中有r2和r4的最新数据,hfile1中是最早的数据。现在需要查询RowKey=r2的数据,按照上文的理论对应的Scanner指向就如图所示:
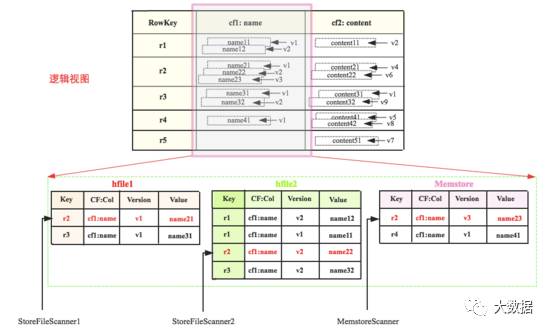
这三个Scanner组成的heap为<memstorescanner,storefilescanner2, storefilescanner1="">,Scanner由小到大排列。查询的时候首先pop出heap的堆顶元素,即MemstoreScanner,得到keyvalue = r2:cf1:name:v3:name23的数据,拿到这个keyvalue之后,需要进行如下判定:
检查该KeyValue的KeyType是否是Deleted/DeletedCol等,如果是就直接忽略该列所有其他版本,跳到下列(列族)
检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略
检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略
检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该cell的其他版本;反正如果用户查询所有版本,则还需要查询该cell的其他版本。
现在假设用户查询所有版本而且该keyvalue检查通过,此时当前的堆顶元素需要执行next方法去检索下一个值,并重新组织最小堆。即图中MemstoreScanner将会指向r4,重新组织最小堆之后最小堆将会变为<storefilescanner2, memstorescanner="" storefilescanner1,="">,堆顶元素变为StoreFileScanner2,得到keyvalue=r2:cf1:name:v2:name22,进行一系列判定,再next,再重新组织最小堆…
不断重复这个过程,直至一行数据全部被检索得到。继续下一行…
----------------此处应有华丽丽的分隔符----------------
本文从框架层面对HBase读取流程进行了详细的解析,文中并没有针对细节进行深入分析,一方面是担心个人能力有限,引入太多细节会让文章难于理解,另一方面是大多数看官可能对细节并不关心,下篇文章笔者会揪出来一些比较重要的细节和大家一起交流~
文章最后,贴出来一个一些朋友咨询的问题:Memstore在flush的时候会不会将Blockcache中的数据update?如果不update的话不就会产生脏读,读到以前的老数据?
数据工匠 专注 专业 聚焦
以上是关于HBase原理-数据读取流程解析的主要内容,如果未能解决你的问题,请参考以下文章