Hadoop实习操作练习1(Hive与HBase初探)
Posted 尚学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop实习操作练习1(Hive与HBase初探)相关的知识,希望对你有一定的参考价值。
Chapter 1: 引言
近期电信集团公司举办了大数据技术培训课,按照要求,Hadoop小白的我对两者作完对比,进行实际操作做一个练习记录吧,嘿嘿。。。
两者的共同点:
1.hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储
两者的区别:
2.Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
3.想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
4.Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
5.Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
6.hive借用hadoop的MapReduce来完成一些hive中的命令的执行
7.hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
8.hbase是列存储。所以Hbase可以对数据进行增改删等操作,但Hive是行的,只能追加数据。
9.hdfs作为底层存储,hdfs是存放文件的系统,而Hbase负责组织文件。
10.hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
Chapter 2: Hive操作
基础操作:
登录Hadoop的Master节点--》切换到Hadoop帐号-->使用Hive查看表,并exit退出:
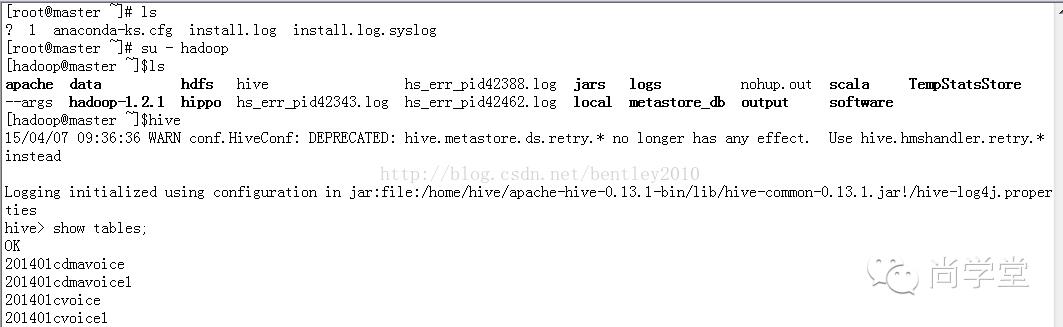
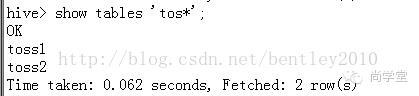
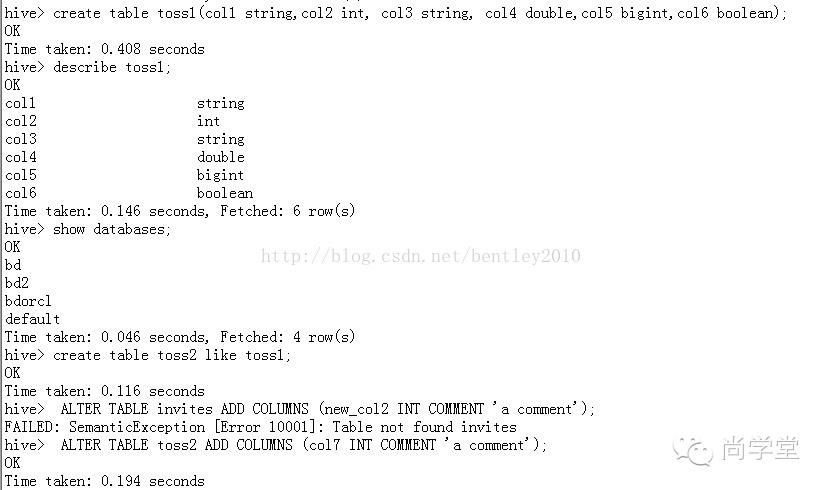
联合查询:
内连接:
hive> SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
查看hive为某个查询使用多少个MapReduce作业
hive> Explain SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
外连接:
hive> SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
hive> SELECT sales.*, things.* FROM sales RIGHT OUTER JOIN things ON (sales.id = things.id);
hive> SELECT sales.*, things.* FROM sales FULL OUTER JOIN things ON (sales.id = things.id);
in查询:Hive不支持,但可以使用LEFT SEMI JOIN
hive> SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);
CREATE TABLE ... AS SELECT:新表预先不存在
hive>CREATE TABLE target AS SELECT col1,col2 FROM source;
视图查询:
创建视图:
hive> CREATE VIEW valid_records AS SELECT * FROM records2 WHERE temperature !=9999;
查看视图详细信息:
hive> DESCRIBE EXTENDED valid_records;
外部表、内部表、分区表的区别及操作:
此时,会在hdfs上新建一个tt表的数据存放地,例如,笔者是在 hdfs://master/input/table_data
上传hdfs数据到表中:
load data inpath '/input/data' into table tt;
[sql] view plaincopy![]()
![]()
load data inpath '/input/data' into table tt;
此时会将hdfs上的/input/data目录下的数据转移到/input/table_data目录下。
删除tt表后,会将tt表的数据和元数据信息全部删除,即最后/input/table_data下无数据,当然/input/data下再上一步已经没有了数据!
如果创建内部表时没有指定location,就会在/user/hive/warehouse/下新建一个表目录,其余情况同上。
注意的地方就是:load data会转移数据!
2. 外部表:
create external table et (name string , age string);
[sql] view plaincopy![]()
![]()
create external table et (name string , age string);
此时,会在/user/hive/warehouse/新建一个表目录et![]()
load data inpath '/input/edata' into table et;
此时会把hdfs上/input/edata/下的数据转到/user/hive/warehouse/et下,删除这个外部表后,/user/hive/warehouse/et下的数据不会删除,但是/input/edata/下的数据在上一步load后已经没有了!数据的位置发生了变化!本质是load一个hdfs上的数据时会转移数据!
3. 分区表

为内部表某个分区导入数据,Hive将建立目录并拷贝数据到分区当中
LOAD DATA LOCAL INPATH '${env:HOME}/california-employees'
INTO TABLE employees
PARTITION (country = 'US', state = 'CA');
为外部表某个分区添加数据
ALTER TABLE log_messages ADD IF NOT EXISTS PARTITION(year = 2012, month = 1, day = 2)
LOCATION 'hdfs://master_server/data/log_messages/2012/01/02';
备注:Hive并不关心分区,目录是否存在,是否有数据,这会导致没有查询结果
从本地文件系统中加载数据。
LOAD DATA LOCAL INPATH "/opt/data/1.txt" INTO TABLE table1;
意思是,从本地文件系统/opt/data/1.txt加载到hive的table1中。这时hive会读取该文件,并将内容写到hdfs中table1所在的位置。
从HDFS中加载数据
LOAD DATA INPATH "/data/datawash/1.txt" INTO TABLE table1;
意思是从HDFS的/data/datawash/1.txt写入到table1所在目录。
关于加载中的OVERWRITE是这样。
LOAD DATA LOCAL INPATH "/opt/data/1.txt" OVERWRITE INTO TABLE table1;
如果加了OVERWRITE,则覆盖原先已经存在的数据,如果你确定原先没有数据,则可以写上。
Chapter 3: HBase操作
安装:在安装Hbase之前需先安装Zookeeper,见http://jeffxie.blog.51cto.com/1365360/329212
登录:

语法:
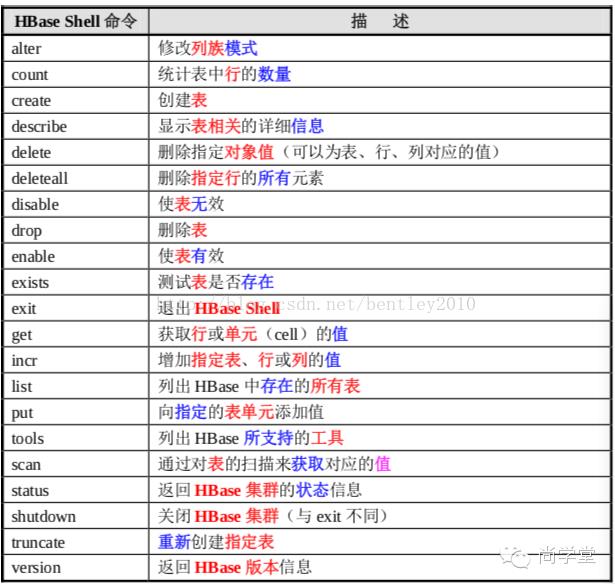
| 操作 | 命令表达式 |
| 创建表 | create 'table_name, 'family1','family2','familyN' |
| 添加记录 | put 'table_name', 'rowkey', 'family:column', 'value' |
| 查看记录 | get 'table_name, 'rowkey' |
| 查看表中的记录总数 | count 'table_name' |
| 删除记录 | delete 'table_name' ,'rowkey' , 'family:column' deleteall 'table_name','rowkey' |
| 删除一张表 | 先 disable 'table_name' 再 drop 'table_name' |
| 查看所有记录 | scan "table_name" ,很危险 最好加LIMIT : scan 'table_name',LIMIT=>10 |
| 查看某个表某个列中所有数据 | scan "table" , {COLUMNS =>['family1:','family2' VERSIONS=2]} VERSIONS 选填 |
练习:
status //查看服务器状态
version //查询Hbase版本
create 'test','course','device' //创建表
list //列出所有的表
exists 'test' //查询表是否存在
put 'test','Li Lei','course:Math','90'
put 'test','Han Meimei','course:English','92' //插入记录
get 'test','Li Lei' //获取一个Id的所有数据
get 'test','Li Lei','device' //获取一个ID,一个列族的所有数据
get 'test','Li Lei','device:laptop' // 获取一个ID,一个列族中的一个列的所有数据
更新一条记录:
get 'test','Li Yang','device:laptop','Asus'
count 'test' //查看表中有多少行
delete 'test','Li Yang','device:laptop‘ //删除id为’Li Yang’的值的’device:laptop’字段
deleteall 'test','Li Yang‘ //删除整行
删除表:
disable 'test'
drop 'test‘
退出:
exit
以上是关于Hadoop实习操作练习1(Hive与HBase初探)的主要内容,如果未能解决你的问题,请参考以下文章
hadoop生态系统学习之路hbase与hive的数据同步以及hive与impala的数据同步