HQueue:基于HBase的消息队列
Posted 数盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HQueue:基于HBase的消息队列相关的知识,希望对你有一定的参考价值。
【数盟倡导“数据创造价值”,致力于打造最卓越的数据科学交流平台,为企业、个人提供最卓越的服务】
(部分文章来自于第三方平台,未能找到原作者,敬请谅解~sorry~)
1. HQueue简介
HQueue是一淘搜索网页抓取离线系统团队基于HBase开发的一套分布式、持久化消息队列。它利用HTable存储消息数据,借助HBase Coprocessor将原始的KeyValue数据封装成消息数据格式进行存储,并基于HBase Client API封装了HQueue Client API用于消息存取。
HQueue可以有效使用在需要存储时间序列数据、作为MapReduce Job和iStream等输入、输出供上下游共享数据等场合。
2. HQueue特性
由于HQueue是基于HBase进行消息存取的,因此站在HDFS和HBase的肩膀上,使得其具备如下特点:
(1)支持多Partitions,可根据需求设置Queue的规模,支持高并发访问(HBase的多Region);
(2)支持自动Failover,任何机器Down掉,Partition可自动迁移至其他机器(HBase的Failover机制);
(3)支持动态负载均衡,Partition可以动态被调度到最合理的机器上(HBase的LoadBalance机制,可动态调整);
(4)利用HBase进行消息的持久化存储,不丢失数据(HBase HLog和HDFS Append);
(5)队列的读写模式与HBase的存储特性天然切合,具备良好的并发读写性能(最新消息存储在MemStore中,写消息直接写入MemStore,通常场景下都是内存级操作);
(6)支持消息按Topic进行分类存取(HBase中的Qualifier);
(7)支持消息TTL,自动清理过期消息(HBase支持KeyValue级别的TTL);
(8)HQueue = HTable Schema Design + HQueue Coprocessor + HBase Client Wrapper,完全扩展开发,无任何Hack工作,可随HBase自动升级;
(9)HQueue Client API基于HBase Client Wrapper进行简单封装,HBase的ThriftServer使得其支持多语言API,因此HQueue也很容易封装出多语言API;
(10)HQueue Client API可以天然支持Hadoop MapReduce Job和iStream的InputFormat机制,利用Locality特性将计算调度到存储最近的机器;
(11)HQueue支持消息订阅机制(HQueue 0.3及后续版本)。
3. HQueue系统设计及处理流程
3.1. HQueue系统结构
HQueue系统结构如图(1)所示:
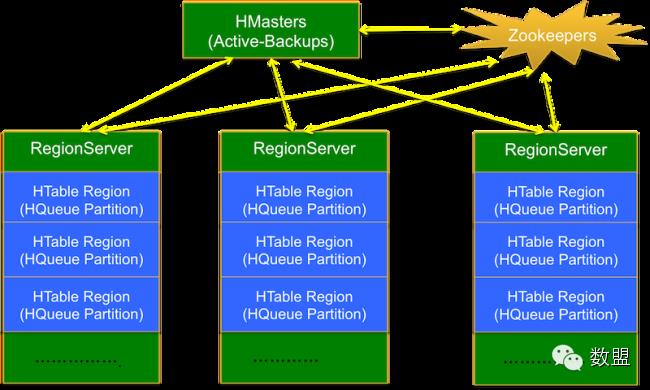 图(1):HQueue系统结构
图(1):HQueue系统结构
其中:
(1)每个Queue对应一个HTable,创建Queue可以通过Presharding Table方式创建,有利于负载均衡。
(2)每个Queue可以有多个Partitions(HBase Regions),这些Partitions均匀分布在HBase集群中的多个Region Servers中。
(3)每个Partition可以在HBase集群的多个Region Servers中动态迁移。任何一台Region Server挂掉,运行在其上的HQueue Partition可以自动迁移到其他Region Server上,并且数据不会丢失。当集群负载不均衡时,HQueue Partition会自动被HMaster迁移到负载低的Region Server。
(4)每个Message对应一个HBase KeyValue Pair,按MessageID即时间顺序存储在HBase Region中。MessageID由Timestamp和同一Timestamp下自增的SequenceID构成,详细信息参见《Message存储结构》部分。
3.2. Message存储结构
Message存储结构如图(2)所示:
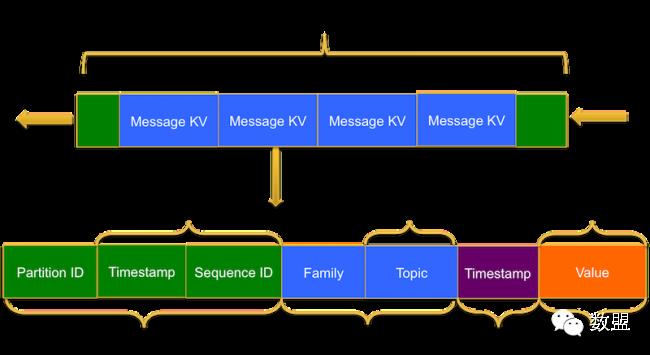
图(2):Message存储结构
其中:
(1)RowKey:由PartitionID和MessageID构成。
PartitionID:一个Queue可以有多个Partitions,目前最多支持Short.MAX_VALUE个Partitions。Partition ID可以不在创建Message对象时指定,而是在发送消息时设定,或者不指定而使用一个随机Partition ID。
MessageID:即消息ID,它由Timestamp和SequenceID两部分组成。Timestamp是消息写入HQueue时的时间戳,单位为毫秒。SequenceID是同一Timestamp下消息的顺序编号,目前最多支持同一Timestamp下Short.MAX_VALUE个Messages。
(2)Column:由Column Family和Message Topic构成。
Column Family:HBase Column Family,此处为固定值“message”。
Message Topic :HBase Column Qualifier,消息Topic名称。用户可以根据需要将Message存储在不同的Topics之下,也可以从Queue中获取感兴趣的Topics消息数据。
(3)Value:即消息内容。
3.3. HQueue消息写入及Coprocessor处理流程
HQueue利用HQueue Client API写入消息数据,为保证消息唯一和有序,HQueue利用Coprocessor处理用户写入消息的MessageID,然后立即放入HBase MemStore中,使其可以被访问到,最后持久化的HLog中。具体的处理逻辑如图(3)所示:
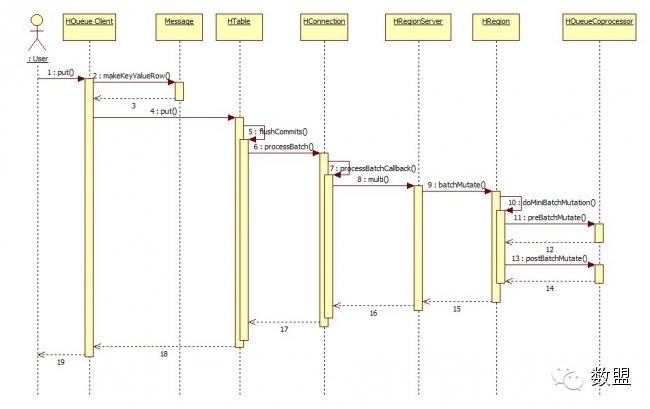
图(3):数据写入及Coprocessor处理流程
其中:
(1)HQueue封装了HQueue Client API,用户可以使用其提供Put等方法向HQueue中写入消息。
(2)HQueue Client会使用Message.makeKeyValueRow()用于完成将Message数据结构转换成HBase Rowkey。HQueue所要求的RowKey格式可以参加上述内容。
(3)HQueue Client在完成RowKey的转换后,会调用HTable的put方法按照HBase标准的写入流程来完成消息的写入。
(4)HQueue上注册有HQueueCoprocessor,它扩展自BaseRegionObserver。HRegion在真正写入消息数据前,会调用HQueueCoprocessor的preBatchMutate方法,该方法主要用于调整MessageID,保证MessageID唯一并且有序。
(5)在HQueueCoprocessor的preBatchMutate方法中同时会调整Durability为SKIP_WAL,这样HBase将不会主动将消息数据持久化进HLog。
(6)HRegion在写入消息数据后,会调用HQueueCoprocessor的postBatchMutate方法,该方法主要完成将消息数据持久化进HLog的功能。
3.4. HQueue Scan处理流程
为了方便从Queue中Scan数据,HQueue封装了ClientScanner,提供了QueueScanner、PartitionScanner和CombinedPartitionScanner等Scanner,用于不同的场景。HQueue Scan的具体处理流程如图(4)所示:
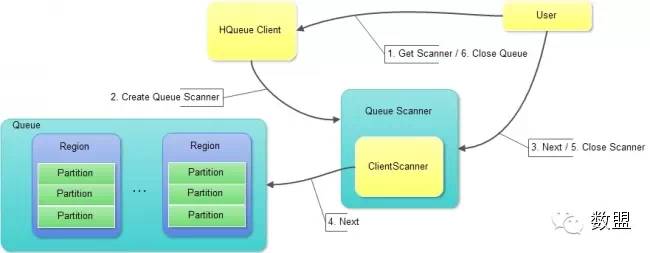
图(4):HQueue Scan处理流程
其中:
(1)用户可以根据需要从HQueue Client中获取所需的Queue Scanner,目前主要提供三种Scanner:
QueueScanner:用于Scan Queue中全部Partitions的数据;
PartitionScanner:用于Scan Queue中指定Partition的数据;
CombinedPartitionScanner:用于Scan Queue中若干指定Partitions的数据。
(2)用户获取到Scanner之后,可以循环调用Scanner的next方法依次取出消息数据,直至无数据返回,本次Scan结束。Scan结束后,用户应主动关闭Scanner以便及时释放资源。
(3)用户在不再使用先前创建的Queue对象时,应主动关闭Queue以便及时释放资源。
3.5. HQueue订阅流程
3.5.1. 整体流程
HQueue自0.3版本开始提供订阅功能,一个订阅者可以订阅一个Queue的多个Partitions、多个Topics。与用户使用Scanner主动Scan消息数据的方式相比,订阅方式具有(1)消息数据一旦写入Queue便会被主动推送至订阅者,消息送达更为及时;(2)订阅者被动接收新消息,可以省去HQueue无新消息数据时多余的Scan操作,减少系统开销等优点。
HQueue订阅流程处理逻辑如图(5)所示:
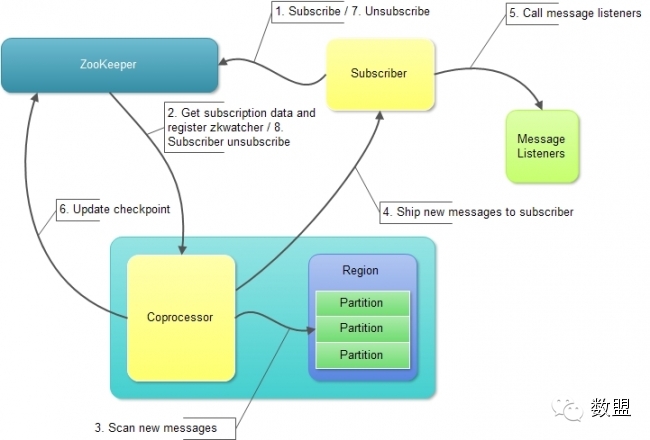
图(5):HQueue订阅流程处理逻辑
其中:
(1)HQueue订阅主要由Subscriber、ZooKeeper和Coprocessor这三部分组成。其中:
Subscrier:即订阅者。主要完成向ZoeoKeeper写入订阅信息、启动监听、接收新消息并回调注册在其上的消息处理函数(MessageListener)等功能。
Coprocessor:主要完成从ZooKeeper获取订阅信息、使用InternalScanner从Queue中Scan最新的消息、将新消息发送至订阅者并将当前Checkpoint更新至ZooKeeper等功能。
(2)Coprocessor的主要处理流程如下:
Step 1:创建Subscriber,添加订阅信息和消息处理函数,将订阅信息写入ZooKeeper,启动监听等待接收新消息。写入ZooKeeper中的订阅信息主要包括:
订阅者订阅的Queue名称;
订阅者订阅的Queuee Partitions以及各Partition上消息的起始ID。一个订阅者可以订阅多个Partitions,如果没有指定,那么认为订阅该Queue的所有Partitions。
订阅者订阅的消息Topics。一个订阅者可以订阅多个主题,如果没有指定,那么认为订阅该Queue上的所有Topics。
订阅者的Addresss/Hostname和监听端口。用户创建订阅者时可以指定监听端口,如果没有指定,那么会随机选择一个当前可用端口作为监听端口。
Step 2:Coprocessor从ZooKeeper获取订阅信息并向ZooKeeper注册相关Watcher,以便ZooKeeper中订阅信息发生变化时ZooKeeper能够及时通知Coprocessor。Coprocessor在获取到订阅信息后,会根据需要创建SubscriptionWorker等工作线程,以便从HQueue Partition中Scan消息并将消息发送至Subscriber。
Step 3:Coprocessor从HQueue Partition中Scan新消息。
Step 4:Coprocessor将新消息发送至Subscriber。
Step 5:Subscriber在接收到新消息时,会回调注册在其上的回调函数。
Step 6:待新消息发送成功后,Coprocessor会将消息的Checkpoint更新至ZooKeeper以便后续使用。
Step 7:Subscriber取消订阅,并从ZooKeeper中删除必要的订阅信息。
Step 8:ZooKeeper会通过注册在其上的Watcher将Subscriber订阅信息的变化通知至Coprocessor,Coprocessor根据订阅信息的变化,暂停SubscriptionWorker等工作线程等。
3.5.2. HQueue Subscriber
HQueue Subscriber结构和主要处理逻辑如图(6)所示:
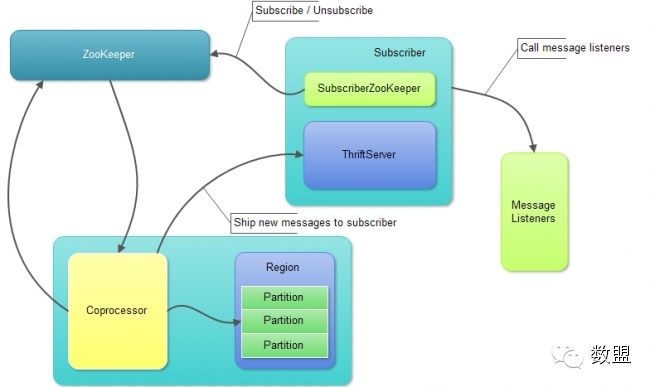
图(6):HQueue Subscriber结构和主要处理逻辑
其中:
(
1)Subscriber主要由两部分组成:SubscriberZooKeeper和Thrift Server。其中,SubscriberZooKeeper主要完成与ZooKeeper相关的若干操作,包括写入订阅信息、删除订阅信息等。Coprocessor与Subscriber之间的通讯通过Thrift来完成,Subscriber中启动Thrift Server,监听指定的端口,等待接收Coprocessor发送过来的新消息。
(2)Subscriber通过Thrift Server接收到新消息后,会回调注册在其上的回调函数(MessageListeners),并将状态码返回给Coprocessor。
(3)可以在一个Subscriber上注册多个MessageListeners,多个MessageListeners会被依次调用。
3.5.3. HQueue Coprocessor
HQueue Coprocessor结构和主要处理逻辑如图(7)所示:
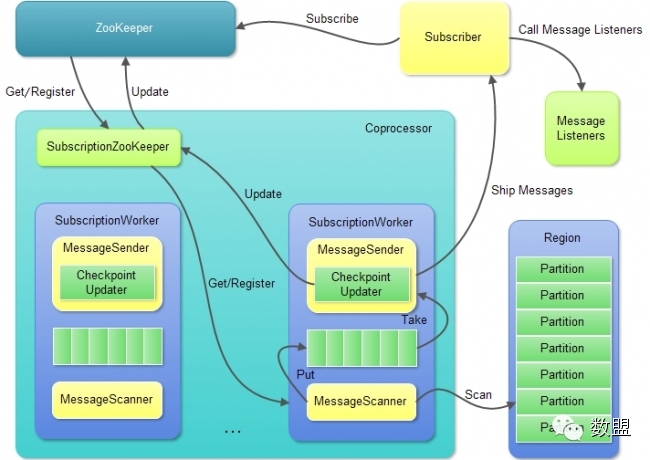
图(7):HQueue Coprocessor结构和主要处理逻辑
其中:
(1)Coprocessor:主要由两部分构成SubscriptionZooKeeper和SubscriptionWorker。
SubscriptionZooKeeper:主要完成与ZooKeeper相关的工作,包括从ZooKeeper获取订阅信息并注册相关Watcher、SubscriptionWorker将Checkpoint更新至ZooKeeper等操作。
SubscriptionWorker又主要包括MessageScanner和MessageSender两部分,主要完成Scan新消息、发送消息至Subscriber和更新Checkpoint等操作。
(2)MessageScanner主要完成创建InternalScanner,从Queue Partition中Scan新消息,并将其放入缓冲队列中等操作。
当缓冲队列中没有空闲空间时,MessageScanner会等待直至缓冲队列中的消息被MessageSender消费掉,腾出剩余空间。
当Queue Partition中没有新消息时,MessageScanner会主动Sleep,当有新消息写入时,Coprocessor会通过SubscriptionWorker唤醒MessageScanner,开始新一轮Scan。
(3)MessageSender主要完成从缓冲队列中取出新消息,将其发送至Subscriber,并等待Subscriber发回响应等操作。当缓冲队列中没有新消息时,MessageSender会等待直至有新消息到来。
(4)MessageSender中的CheckpointUpdater会定时将当前的Checkpoint写入ZooKeeper中的相关订阅节点中,以便后续使用。
3.5.4. 订阅信息层次结构
HQueue相关订阅信息保存在ZooKeeper,ZooKeeper中订阅信息的层次结构如图(8)所示:
图(8):订阅信息层次结构
其中:
(1)订阅者节点(subscriber_x)上会记录该订阅者在Queue Partition上的Checkpoint。该Checkpoint由Subscriber在发起订阅时写入,并由SubscriptionWorker MessageSender中的CheckpointUpdater来更新。
(2)订阅者节点下会有两个临时性节点:address和topics,分别保存订阅者的IP Address/Hostname:Port和订阅的主题。当订阅者主动取消订阅时会删除这两个临时节点,当订阅者意外退出时,等Session失效后,ZooKeeper会删除该临时节点。
3.5.5. 订阅者Thrift Service
HQueue订阅功能使用Thrift来简化对多语言客户端的支持。Subscriber启动Thrift Server,监听指定端口,接收消息,并回调MessageListeners以便处理消息。用于描述HQueue Subscriber所提供服务的接口定义如下所示:
namespace java com.etao.hadoop.hbase.queue.thrift.generated
/**
* HQueue MessageID
*/
struct TMessageID {
1: i64 timestamp,
2: i16 sequenceID
}
/**
* HQueue Message
*/
struct TMessage {
1: optional TMessageID id,
2: optional i16 partitionID,
3: binary topic,
4: binary value
}
/**
* HQueue Subscriber Service
*/
service HQueueSubscriberService {
i32 consumeMessages(1:list<TMessage> messages)
}
4. HQueue使用
4.1. HQueue Toolkit
为方便用户使用,HQueue封装了HQueue Client API用于存取消息数据。自HQueue 0.3版本,HQueue日志运维工具集成进HQueue Shell中,构成HQueue Toolkit,为用户提供一站式服务,方便用户管理Queue以及Queue订阅者。
同HBase Shell使用方式相似,用户使用$ ${HBASE_HOME}/bin/hqueue shell便可以进入HQueue Shell命令行工具。需要注意的是,用户在使用HQueue Toolkit之前需要确保已经部署HQueue Toolkit。
HQueue Toolkit中包括创建Queue、Disable Queue、Enable Queue、删除Queue和清空Queue等命令。使用示例如下:
(1)创建队列
USAGE:create ‘queue_name’, partition_count, ttl, [Configuration Dictionary]
DESCRIPTIONS:
queue_name:待创建的HQueue的名称,必选参数。
partition_count:待创建的HQueue的Partition个数,必选参数。
ttl:失效时间,必选参数。
Configuration Dictonary:可选配置参数。目前支持的配置参数为:(1)hbase.hqueue.partitionsPerRegion;(2)hbase.hregion.memstore.flush.size;(3)hbase.hregion.majorcompaction;(4)hbase.hstore.compaction.min;(5)hbase.hstore.compaction.max;(6)hbase.hqueue.compression;(7)hbase.hstore.blockingStoreFiles等。
EXAMPLES:
hqueue> create ‘q1′, 32, 86400
hqueue> create ‘q1′, 32, 86400, {‘hbase.hqueue.partitionsPerRegion’ => ’4′, ‘hbase.hstore.compaction.min’ => ’16′, ‘hbase.hstore.compaction.max’ => ’32′}
(2)清空队列
USAGE:truncate_queue 'queue_name' DESCRIPTIONS:
queue_name:待清空的Queue名称,必选参数。
EXAMPLES:
hqueue(main):013:0> truncate_queue 'replication_dev_2_test_queue'
需要注意的是:该命令与HBase Shell中的truncate有所不同,该命令仅会删除Queue中的数据,而保留Queue的Presharding信息。
更多操作请参阅:http://searchwiki.taobao.ali.com/index.php/HQueue_Toolkit#Queue.E7.AE.A1.E7.90.86
(3)新增订阅者
USAGE:add_subscriber 'queue_name', 'subscriber_name'
DESCRIPTIONS:
queue_name:队列名称,必选参数。
subscriber_name:订阅者名称,必选参数。
EXAMPLES:
add_subscriber 'replication_dev_2_test_queue', 'subscriber_1'
(4)删除订阅者
USAGE:delete_subscriber 'subscriber_name', 'queue_name' DESCRIPTIONS:
queue_name:订阅者所订阅的Queue名称,必选参数。
subscriber_name:订阅者名称,必选参数。
EXAMPLES:
hqueue(main):040:0> delete_subscriber 'replication_dev_2_test_queue', 'subscriber_1'
更多信息可以参阅:http://searchwiki.taobao.ali.com/index.php/HQueue_Toolkit#.E8.AE.A2.E9.98.85.E8.80.85.E7.AE.A1.E7.90.86
4.2. Put
HQueue Client API中的Put相关操作可以完成将用户消息数据写入HQueue中,Put支持批量操作,具体使用方式示例如下:
HQueue queue = new HQueue(queueName); String topic1 = "crawler"; String value1 = "http://www.360test.com"; // 写入单条消息数据,不指定Partition ID。在不指定Partition ID的情况下,将会在Queue的所有Partitions中随机选取一个。 Message message1 = new Message(Bytes.toBytes(topic1), Bytes.toBytes(value1)); queue.put(message); // 写入Message时,显式指定PartitionID。 short partitionID = 10; queue.put(partitionID, message1); List<Message> messages = new ArrayList<Message>(); messages.add(message1); String topic2 = "dump"; String value2 = "http://www.jd.com"; Message message2 = new Message(Bytes.toBytes(topic2), Bytes.toBytes(value2)); messages.add(message2); // 写入多条消息数据,不指定Partition ID。 queue.put(messages); // 写入多条消息数据,指定Partition ID。 queue.put(partitionID, messages); queue.close();
4.3. Scan
为方便用户从Queue中Scan消息数据,HQueue Client API提供了三种自定义Scanner,分别为:QueueScanner、PartitionScanner和CombinedPartitionScanner,使用示例如下:
String queueName = "subscription_queue";
Queue queue = new HQueue(queueName);
// 起始时间戳
long currentTimestamp = System.currentTimeMillis();
MessageID startMessageID = new MessageID(currentTimestamp - 6000);
MessageID stopMessageID = new MessageID(currentTimestamp);
Scan scan = new Scan(startMessageID, stopMessageID);
// 添加主题
scan.addTopic(Bytes.toBytes("topic1"));
scan.addTopic(Bytes.toBytes("topic2"));
Message message = null;
// 使用QueueScanner,扫描Queue下全部Partitions中的数据
QueueScanner queueScanner = queue.getQueueScanner(scan);
while ((message = queueScanner.next()) != null) {
// no-op
}
queueScanner.close();
short partitionID1 = 1;
// 使用PartitionScanner,扫描Queue中指定的Partition的数据
PartitionScanner partitionScanner = queue.getPartitionScanner(partitionID1, scan);
while ((message = partitionScanner.next()) != null) {
// no-op
}
partitionScanner.close();
short partitionID2 = 2;
Map<Short, Scan> partitions = new HashMap<Short, Scan>();
// 添加多个Partitions
partitions.put(partitionID1, scan);
partitions.put(partitionID2, scan);
CombinedPartitionScanner combinedScanner = queue.getCombinedPartitionScanner(partitions);
while ((message = combinedScanner.next()) != null) {
// no-op
}
combinedScanner.close();
queue.close();
4.4. 订阅消息
HQueue自0.3版本开始提供订阅功能,使用方式示例如下:
HQueue queue = null;
HQueueSubscriber subscriber = null;
try {
String queueName = "subscription_queue";
queue = new HQueue(queueName);
Set<Pair<Short, MessageID>> partitions = new HashSet<Pair<Short, MessageID>>();
// 添加所订阅的Partitions
Pair<Short, MessageID> partition1 = new Pair<Short, MessageID>((short)0, null);
partitions.add(partition1);
Pair<Short, MessageID> partition2 = new Pair<Short, MessageID>((short)1, null);
partitions.add(partition2);
Pair<Short, MessageID> partition3 = new Pair<Short, MessageID>((short)2, null);
partitions.add(partition3);
// 添加所订阅的Topics
Set<String> topics = new HashSet<String>();
topics.add("topic_1");
topics.add("topic_2");
topics.add("topic_3");
// 订阅者名称
String subscriberName = "subscriber_1";
Subscription subscription = new Subscription(subscriberName, topics);
subscription.addPartitions(partitions);
// 添加回调函数
List<MessageListener> listeners = new LinkedList<MessageListener>();
MessageListener blackHoleListener = new BlackHoleMessageListener(subscriberName);
listeners.add(blackHoleListener);
// 创建订阅者
subscriber = queue.createSubscriber(subscription, listeners);
subscriber.start();
Thread.sleep(600000L);
subscriber.stop("Time out, request to stop subscriber:" + subscriberName);
} catch (Exception ex) {
LOG.error("Received unexpected exception when testing subscription.", ex);
} finally {
if (queue != null) {
try {
queue.close();
queue=null;
} catch (IOException ex) {
// ignore the exception
}
}
}
4.5. ThriftServer API
HBase自带的ThriftServer实现了对HTable的多语言API支持,HQueue在HBase ThriftServer中扩展了对HQueue的支持,使得C++、Python和PHP等语言也可以方便地访问HQueue。
HQueue目前提供的Thrift API如下所示:
| 1 | ScannerID messageScannerOpen(1:Text queueName,2:i16 partitionID,3:TMessageScan messageScan) | 根据Scan,打开Queue中某个Partition上的Scanner |
| 2 | TMessage messageScannerGet(1:ScannerID id) | 逐条获取Message |
| 3 | list<TMessage> messageScannerGetList(1:ScannerID id,2:i32 nbMessages) | 批量获取Messages |
| 4 | void messageScannerClose(1:ScannerID id) | 关闭ScannerID |
| 5 | void putMessage(1:Text queueName,2:TMessage tMessage) | 向Queue中写入Message,使用随机的Partition ID |
| 6 | void putMessages(1:Text queueName,2:list<TMessage> tMessages) | 向Queue中批量写入Messages,使用随机的Partition ID |
| 7 | void putMessageWithPid(1:Text queueName,2:i16 partitionID,3:TMessage tMessage) | 向Queue中写入Message,使用指定的Partition ID |
| 8 | void putMessagesWithPid(1:Text queueName,2:i16 partitionID,3:list<TMessage> tMessages) | 向Queue中批量写入Messages,使用指定的Partition ID |
| 9 | list<Text> getQueueLocations(1:Text queueName) | 获取Queue中所有Partition所在主机的地址 |
5. 总结
以上是对HQueue概念、特性、系统设计、处理流程以及应用等方面的简单阐述,希望对大家有所帮助。
From: http://blogread.cn/it/article/7150?f=wb
—————————————————
数盟网站:www.dataunion.org
数盟微博:@数盟社区
数盟微信:DataScientistUnion
数盟【大数据群】272089418
数盟【数据可视化群】 179287077
数盟【数据分析群】 174306879 ,110875722
—————————————————
点击阅读原文,更多技术、资讯~
以上是关于HQueue:基于HBase的消息队列的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud系列十一:SpringCloudStream(SpringCloudStream 简介创建消息生产者创建消息消费者自定义消息通道分组与持久化设置 RoutingKey)(代码片段