hbase知识总结
Posted 大数据的那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hbase知识总结相关的知识,希望对你有一定的参考价值。
为了解决数据量越来越大所带来的问题,谷歌在十几年前发表了几篇论文,这几篇文章可以认为是大数据领域的基石,从此大数据行业与技术得到了快速的发展。其中有一篇是关于BigTable,这是一个分布式的存储系统。但是谷歌并没有将BigTable开源出来,本文要讲的Hbase参考了BigTable的建模,并用java将其实现。
HBase是一个运行于HDFS文件系统之上的非关系型(NoSQL)分布式数据库,可以容错地存储海量稀疏的key/value数据。
一、Hbase的特点有:
1) 存储量大:一张表可以存储十亿行,上百万列;
2) 无模式:每行都有一个可排序的主键和任意多的列,列可以动态添加,同一个表中不同的行可以有不同的列。
3) 面向列:数据是以列(或列簇)为单位进行存储。
4) 稀疏:空列不占用存储空间,表可以做得很稀疏。
5) 数据版本多:每个单元中的数据可以由多个版本,默认是数据插入时的时间戳。
6) 数据类型单一:数据都是字符串。
7) 可扩展性高:与hadoop类似,Hbase主要通过横向扩展,不断增加廉价服务器来增加存储能力。
二、行存储vs列存储
行存储:
– 优点:写入一次性完成,保持数据完整性
– 缺点:数据读取过程中产生冗余数据,若有少量数据可以忽略
列存储
– 优点:读取过程,不会产生冗余数据,特别适合对数据完整性要求不高的大数据领域
– 缺点:写入效率差,保证数据完整性方面差。
三、Hbase
Hmaster:
1) 负责HregionServer的负载均衡,
2) 为HregionServer分配region
3) 对失效的HregionServer,对其上的region迁移
4) region分裂以及分裂后的region分配
5)负责表的增删改查
6)注意:client访问hbase上的数据并不需要master参与,寻址访问zookeeper和regionserver,数据读写访问region server。
Zookeeper:
2)避免Master 单点故障
3)管理HMaster和HRegionServer的状态(available/alive等)
HregionServer:
1)维护master分配过来的region,处理对这些region的io请求
2)切分待分裂的region
3)RegionServer要求和HDFS的Data Node一起部署
4)Zookeeper 负责 Region 和 RegionServer 的注册。
四、Hbase集群架构
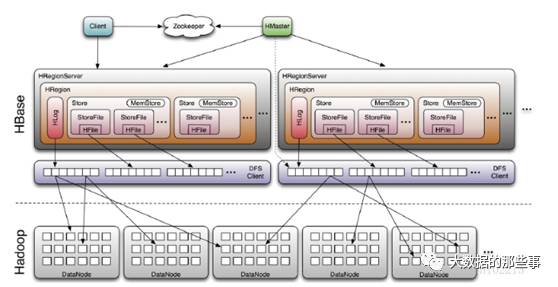
Client通过RPC与HMaster进行管理类通信,与HRegion Server进行数据操作类通信。HregionServer中管理了很多HRegion,每个HRegion由多个Store组成。每个Store对应一个Column Family,Store是HBase的存储核心。每个Store包含一个MemStore和0到多个StoreFile。
MemStore是一个有序的内存缓存区,用户写入的数据首先放入MemStore,当MemStore满了以后Flush成一个StoreFile,当StoreFile数量达到一定的阈值,触发合并,将多个StoreFiles合并成一个。当Region内所有StoreFiles(Hfile)的总大小超过一个阈值时会触发Split,把当前的Region 分裂成2个Region,这两个Region会被HMaster分配到合适HRegionServer上。
五、HBase于Hive 的区别
Hive:对一段时间内的数据进行分析查询,不支持实时查询,支持sql,要经过mapreduce过程。
Hbase:适用于实时查询,需要用到zookeeper,只提供了Java 的 API 接口,不支持sql。
HBase 与 Hive的存储都是基于hdfs。
六、两张特殊的表,-ROOT-和.META.
HBase中有两张特殊的Table,-ROOT-和.META.
1).META.:记录了用户表的Region信息,.META.可以有多个regoin。
2)-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region。
RowKey:表中每条记录的“主键”,可排序,方便快速查找,Rowkey的设计非常重要。Column Family:列族,拥有一个名称(string),包含一个或者多个相关列。
Column:属于某一个列族,列可动态添加。
Version Number:默认值为时间戳,可自定义。
Value(Cell):每个单元的多个版本的数据按时间倒叙存储
Hbase的每一行记录都有可排序的关键字(RowKey)和任意列项(Column &Column Family)。所有数据按照逐渐排序后存储,只可以通过主键和主键版本号来检索数据,仅支持单行事务。
八、table、region、store、StoreFile、Hfile的对应关系
一个table可能会切分成多个Region,每个Region对应于HregionServer上的一个Hregion对象,HregionServer内部管理着多个Hregion对象。Hregion由多个Store组成,每个Store对应Table中的一个Column Family,准确的说应该是一个region的CF。每个Store包含一个MemStore和0到多个StoreFile。
每个Hregion Server中有一个预写日志文件(WriteAhead Log),为该server中的所有Region所共有。在数据写入时,首先写入预写日志,然后才会写入数据,数据也不是一开始就直接写入HDFS,而是会等缓存到一定数量再批量写入,写入完成后在日志中做一个标记。MemStore是一个有序的内存缓存区,写入的数据首先存入MemStore,当MemStore满了以后Flush成一个StoreFile文件,当这个文件数达到一个阈值时会触发Compact操作,将多个StoreFiles合并成一个StoreFile,当一个Hregion中所有StoreFiles(Hfile)的总大小超过某个阈值时会触发Split操作将一个Region分成两个。
以上是关于hbase知识总结的主要内容,如果未能解决你的问题,请参考以下文章