HBase基础知识浅入
Posted 大数据技术博文
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase基础知识浅入相关的知识,希望对你有一定的参考价值。

HBase是建立在Hadoop文件系统之上的分布式面向列的数据库,HBase是一个数据模型,类似于谷歌的BigTable,可以提供快速随机访问海量结构化数据。它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分,可以直接通过HBase存储HDFS数据。HBase在Hadoop的文件系统之上,并提供了读写访问。
本片文章比较偏向于HBase的基础理论,适合初入HBase的新手或者作为一个基础回顾
目录
HBase 基础
一致性模型
表-行-列和单元格
分区(sharding)
HBase自动分区
HBase基础配置
HBase API操作
HBase 基础特性
一致性模型介绍
HBase是一个分布式的,具有持久的,强一致性的存储系统,所谓一致性是保证数据库客户端操作的正确性,每一步的操作都是从一个一致性的状态进入另一个一致性的状态中。
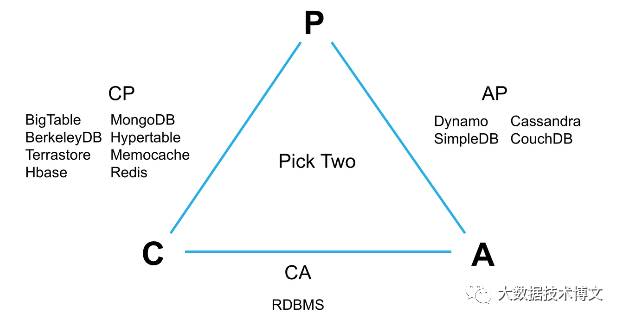
在CAP理论中 [Consistency (一致性)Availability (可用性)Partition tolerance (分区容错性) 首字母的缩写]提出,任何分布式系统在可用性、一致性、分区容错性方面,不能兼得,最多只能满足其中两个。
在这里HBase是一种基于CP的实现 [分布式系统一般是在C和A之间做一个选择,因为对于分布式系统而言,分区容错性是必须的,否则会存在单点问题]
HBase的Consistency主要是因为对于每一个region分区的操作同时只有一个region server对它进行服务,region的读写都是由region server去响应的,所以他是强一致性的。当region server挂掉之后,这时faildover 回到其他的region server去redo region(通过WAL log),然后redo之后的region是不可用的,所以失去了可用性。
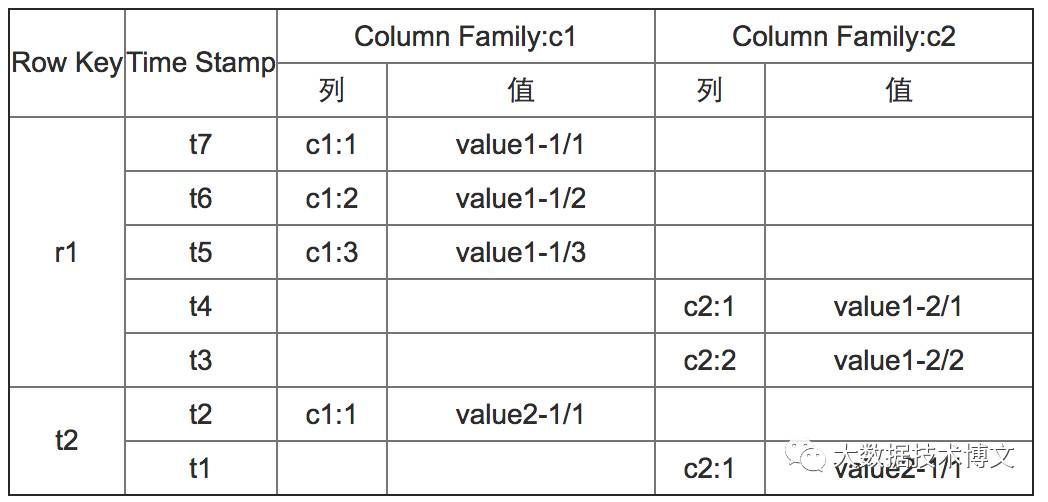
表/行/列/单元格
HBase中最简单的单位是列(Column),一列或者多列形成一行(Row),由一个唯一的主键(Row key)来形成存储。行键时唯一的并且是任意的字节数组,一行由若干列组成,若干列构成了一个列族(列族有助于构建数据的语义以及设置特性)每一个列族的列存储在同一个底层存储文件中,这个存储文件就是HFile,一个表会有若干行,其中每列有多个版本,在每一个单元格中存储了不同的值
分区
分区(sharding):主要描述了逻辑上水平划分数据的方案,分区的特点就是将数据分文件或者分服务器存储,而不是连续存储
HBase自动分区
HBase中扩展和负载均衡的基本单位时region,region本质上是以行键排序的连续存储的区间,如果region过大,那么HBase会将它动态的分为多个region,反之,则会将多个region合并,从而减少存储文件的数量(HDFS不适宜存储小文件)
HBase 预分区设计
HBase开始一个表默认只有一个region,当数据量达到一定阀值时,会自动的分为多个region,但是当数据量增速的很快的时候进行region分区,会造成一定程度的资源消耗,所以可以在创建表的时候就对HBase进行预分区。
create 't1','ed', SPLITS => ['10','15','21’]
当put一条数据到rowkey为15的时候,就会放在region2中
HBase基础配置操作
分布式系统的配置参数是性能调优中很重要的一部分,通过参数调优可能很好的利用集群规模。如果我们不添加或者修改一些配置的话,那么系统自身就会使用自己默认的参数(比较基础和公用,需要根据自身业务进行调整)
HBase的配置文件放置在conf/下,其中hive-env.sh 主要是一些环境变量以及JVM的启动参数比如堆栈大小和垃圾回收策略,我们需要修改的主要配置文件就是hbase-site.xml 这样文件是由我们进行配置定义的,另外hbase-default.xml包含了默认hbase使用的配置参数,可以参考着hbase-default.xml中的配置节点在配置hbase-sitex.xml, HBase在启动的时候,会先加在hbase-default.xml中的配置,然后在加载hbase-site.xml,hbase-site.xml中的配置会覆盖掉hive-default.xml中的配置。
hbase-env.sh 配置环境变量
export JAVA_HOME=/opt/java/java8
export HBASE_HOME=/opt/hbase/hbase1.1
export HBASE_LOG_DIR=/var/logs/hbase
具体的配置列表移步这里看吧,太多了(后续会结合经验写一些参数调优的文章) :
https://hbase.apache.org/book.html#_configuration_files
HBase 特性介绍
过滤器
通常我们在查询HBase数据时采用的是get()和scan()函数,也可以指定一些条件来限制查询到的数量,比如指定某些列,列族,时间等,但是这些都是比较粗的查询方式,过滤器Filter就可以帮助我们查询细粒度的,通过实现Filter过滤器接口,然后编写客户端代码(HBase内部也实现了一部分过滤器),过滤器在客户端创建,然后通过RPC传送到服务器(regionServer),然后服务器端执行过滤操作。
通过HBase过滤器可以帮助我们提高处理表的效率,HBase提供了内置的过滤器同时也可以自己定义过滤器
计数器
通过计数器特性,我们可以很方便的,快速的进行计数操作,从而避免了行锁带来的资源竞争问题,通过计数器特性可以用来做一些实时数据展示的功能,只需要将标识存入计数器列中
单计数器
每一次增加都只操作一个计数器,需要自己来设定使用哪一列。
给x表x行x列族添加一个计算器
incr 'table', ‘row-1', 'cf1:count', 10
后续继续总结复习~~。 以上是关于HBase基础知识浅入的主要内容,如果未能解决你的问题,请参考以下文章 重点知识学习(9.3)--[浅入MySQL数据库事务,浅入MVCC]