HBase框架学习(上)
Posted 西安优盛数据库与大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase框架学习(上)相关的知识,希望对你有一定的参考价值。

HBase是Apache hadoop的数据库,能够对大型数据提供随机、实时的读写访问。HBase的目标是存储并处理大型的数据。HBase是一个开源的,分布式的,多版本的,面向列的存储模型,它存储的是松散型数据。

(1)随着数据规模越来越大,大量业务场景开始考虑数据存储水平扩展,使得存储服务可以增加/删除,而目前的关系型数据库更专注于一台机器。
(2)海量数据量存储成为瓶颈,单台机器无法负载大量数据。
(3)单台机器IO读写请求成为海量数据存储时候高并发,大规模请求的瓶颈。
(4)当数据进行水平扩展时候,如何解决数据IO高一致性问题。结合Map/Reduce计算框架进行海量数据的离线分析。


Google这个神奇的公司以其不保守的态度以学术论文的方式公开了其云计算的三大法宝:GFS、MapReduce和BigTable,其中对于BigTable的开源实现HBase则是由Doug Cutting完成的。
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“ Bigtable:一个结构化数据的分布式存储系统 ”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样, HBase在Hadoop之上 提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase中的表一般有这样的特点:
(1) 大:一个表可以有上亿行,上百万列
(2) 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
(3) 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。

PS
什么是列存储?
列存储不同于传统的关系型数据库,其数据在表中是按行存储的,列方式所带来的重要好处之一就是,由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,一个字段的数据聚集存储,那就更容易为这种聚集存储设计更好的压缩/解压算法。下图讲述了传统的行存储和列存储的区别:

与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统, HBase利用Hadoop HDFS作为其文件存储系统 ;Google运行MapReduce来处理Bigtable中的海量数据, HBase同样利用Hadoop MapReduce来处理HBase中的海量数据 ;Google Bigtable利用 Chubby作为协同服务, HBase利用Zookeeper作为对应 。
下图展示了HBase在Hadoop生态系统体系结构中所处的位置:
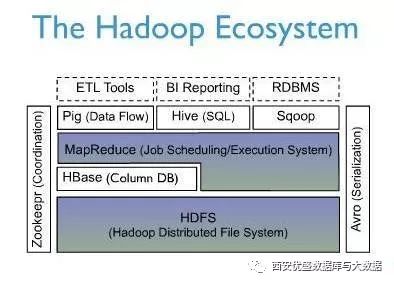
上图描述了Hadoop生态系统中的各层系统。其中,HBase位于结构化存储层 , Hadoop HDFS为HBase提供了高可靠性的底层存储支持 , Hadoop MapReduce为HBase提供了高性能的计算能力 , Zookeeper为HBase提供了稳定服务和失效转移(FailOver)机制 。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
以上是关于HBase框架学习(上)的主要内容,如果未能解决你的问题,请参考以下文章