Hbase的python操作
Posted 大数据的那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase的python操作相关的知识,希望对你有一定的参考价值。
与上次通过sql语句的方式来操作hbase不同,本节采用python的方式来研究hbase。首先编写一个python脚本,在如下目录中:
打开这个脚本,查看python代码可知这个脚本的功能是创建一个hbase表,其中调用了hbase模块,这个模块与我们的脚本要在同一个目录中。
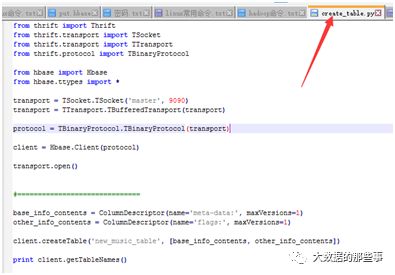
本地执行这个python脚本,如下:

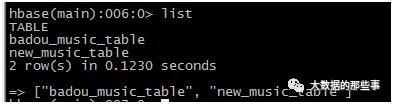
然后在hbase shell中通过list可以查看到已经有这个表了new_music_table。
通过describe'new_music_table'查看表结构,跟我们在python代码中定义的表结构是一样的。如下:

写一个python脚本insert_data.py,这个脚本的作用是往new_music_table中插入一条数据
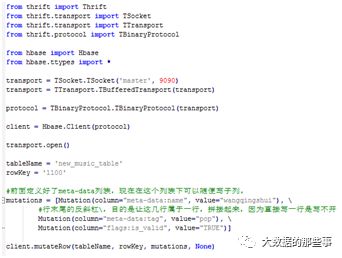
在本地执行这个脚本,如下:

执行完脚本后,在hbase shell中查看,可以看到这条数据已经插入进来了:

再写一个python脚本get_one_line.py,这个脚本的作用是读取new_music_table中的一条记录:
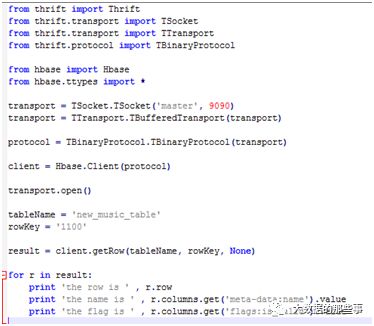
执行命令,结果是把数据确实读出来了

上面的脚本是读取一条记录,接下来尝试下批量读取数据,先往new_music_table再插入一条数据,

写一个python脚本
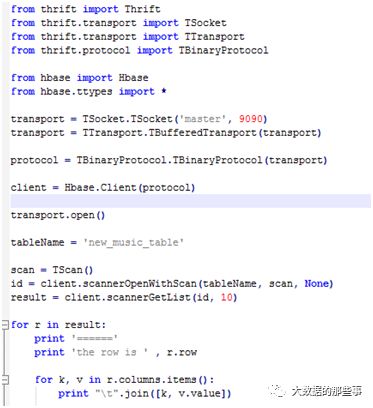
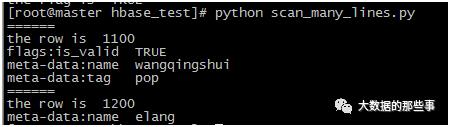
执行命令运行这个脚本,结果是把这个表中的数据都读出来了
上面的脚本都调用了一个hbase模块,什么是python的模块呢?当一个目录中有一个文件叫__init__.py,则这个目录就可以当做python的模块。我们要执行的脚本和需要的模块应该在一个路径中。
在执行MR任务时,这个模块应该分发到各个节点上去。那要怎么将hbase这个模块分发过去呢,用du –sh查看hbase的大小为792k,很小,可以用-file去分发。

但是-file去分发需要做一个压缩成hbase.tgz,如下:
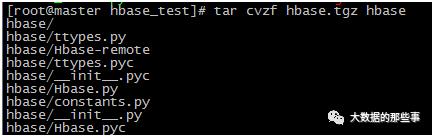
把hbase.tgz分发到各节点还不行,因为其他节点还没有thrift,所以还需要将thrift打个压缩包分发过去。
MR的run.sh核心代码

MR的map.py:


将来源数据上传到hdfs中,hadoop fs -put input.data /。在上传数据时发现很慢,原因是文件比较大。

用du -sh input.data查看发现有119M,用wc -linput.data查看发现有188万行。运行run脚本:
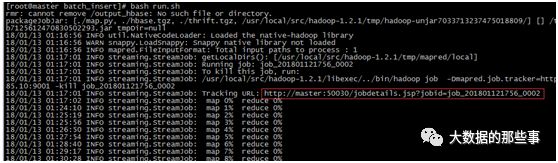
在浏览器中输入网址http://master:50030/jobdetails.jsp?jobid=job_201801121756_0002,可以打开如下网页(要注意配置域名)
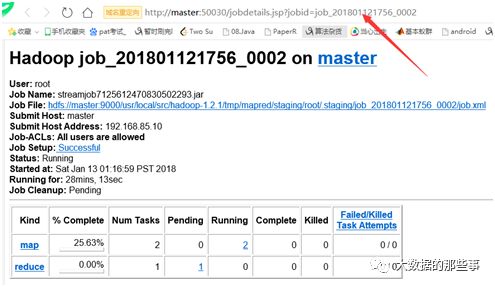
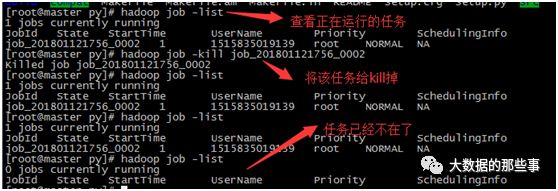
在hbase shell中,查看数据,注意不要使用scan查看大数据量的表,不然你就要被boss给file了。当前任务量太大了,MR任务一直执行,怎么办呢,直接kill掉吧
以上是关于Hbase的python操作的主要内容,如果未能解决你的问题,请参考以下文章