云HBaseSQL及分析——Phoenix&Spark
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云HBaseSQL及分析——Phoenix&Spark相关的知识,希望对你有一定的参考价值。
在2018年1月的数据库直播大讲堂峰会HBase专场,来自阿里云的研发工程师瑾谦和沐远分享了云HBaseSQL以及分析Phoenix&Spark。本文介绍了详细了Phoinix和Spark的架构,适用性以及优缺点,并在最后规划出未来将要设计的一款更符合用户需求的产品。
直播视频:https://yq.aliyun.com/video/play/1333
PDF下载:https://yq.aliyun.com/download/2457
以下是精彩视频内容整理:
HBase上的SQL&分析
Hbase上的分析从使用的方式上来分类可以分为NATIVE和SQL两类,而二者均存在小数量简单分析和大数据量复杂分析两种场景。但无论在NATIVE和SQL上做小数据量分析或者大数据量分析均需解决HBASE的一些根本问题,比如HBASE表数据热点问题,易用性以及适用更多场景。
SQL ON HBASE方案:ALI-PHOENIX
HBase上的SQL层
HBASE上的SQL层Phoenix 被大家更多使用的一个特性是二级索引。要使用Phoenix首先需要了解它分为Client端和server端,server端是以一个jar包的形式部署在HBASE的内部。server端对meta表的操作和二级索引的读写等一系列操作都是通过HBASE的ZOOKEEPER完成的。Phoneix是一个重客户端的引擎重要的实现逻辑都在客户端完成,包括从sql翻译成hbase API逻辑和整理收集查询结果逻辑。
二级索引
更为大家关注的是Phoenix的二级索引。目前Phoenix的二级索引主要被大家使用的是GLOBAL INDEX和LOCAL INDEX。GLOBAL INDEX目前为止使用场景比LOCAL INDEX更为广泛,它实质上是一张HBASE表,即把倒开索引单独存到另一张HBASE表中。由于这种设计的特性使得它更多的使用与写少多读的场景。当然由于GLOBAL INDEX是一张单独的表所以它可以使用一些主表的特性,比如可以使用加盐,指定压缩等特性。而LOCAL INDEX是在元数据表中多加了一个列数去存储的。由于LOCAL INDEX和元数据表是存在一张表中,故它更多的适用于写多读少的场景中,并且该特性使得主表的数据量不能过大。GLOBAL INDEX和LOCAL INDEX相比LOCAL INDEX的网络开销比较小,故当索引表数据量适量的情况下LOCAL INDEX的性能更高。
GLOBAL INDEX和LOCAL INDEX的元数据均由Phoenix管理,Phoenix的单独管理着一套元数据信息,这些元数据信息均存在SYSTEM.CATALOG的HBASE表中。目前索引创建支持同步和异步两种方式同步索引数据,同步创建索引的意思是若当前的表有数据那么创建索引的过程就是一个同步索引数据的一个过程,它会把所有的主表的数据转化成索引数据,全部同步完成以后的再将索引表的状态置成active状态,这样一个过程称之为同步创建索引。异步创建索引主要是针对数据量大的场景,先执行create index创建索引表相关的元数据,再通过MR同步索引数据,该过程称之为异步创建索引。目前为止Phoenix4.12支持了检查主表和索引表数据一致工具。由于前面所说一些列限制,就导致Phoenix创建所以的时候不能超过一定数量,目前索引个数默认不建议超过10个。目前为止LOCAL INDEX的实现方案不太成熟,故不推荐使用。
索引中的Row Key格式

索引中的ROW KEY格式分为两种,一种为Local index Row Key格式和Global index Row Key格式,二者的数据均存于HBASE表中。对于Local index Row Key格式,由于Local index是存在于原表中的,也就相当于把元数据的value数据变成索引的Key,而Key的编码格式均是第一个为REGION START KEY,这样的设计可以使索引数据和元数据更贴近。与Local index Row Key格式不同Global index Row Key格式是另一种形式,因为Global index是存在另一张表中的,并且它可以继承主表的一些属性,比如说主表加的盐,放在格式的最前面可以解决数据的热点问题,另一方面放在最前面可以解决加盐数据的加码和解码问题。
二级索引单条写性能测试结果
下面是一条二级索引单条写性能测试的数据,配置信息为:云HBASE 1.4.4.3&ALi-Phoenix4.12,4核8G SSD(2个RS),主表SALT_BUCKETS=4,GLOBLA INDEX SALT_BUCKETS=4,下图为测试结果。
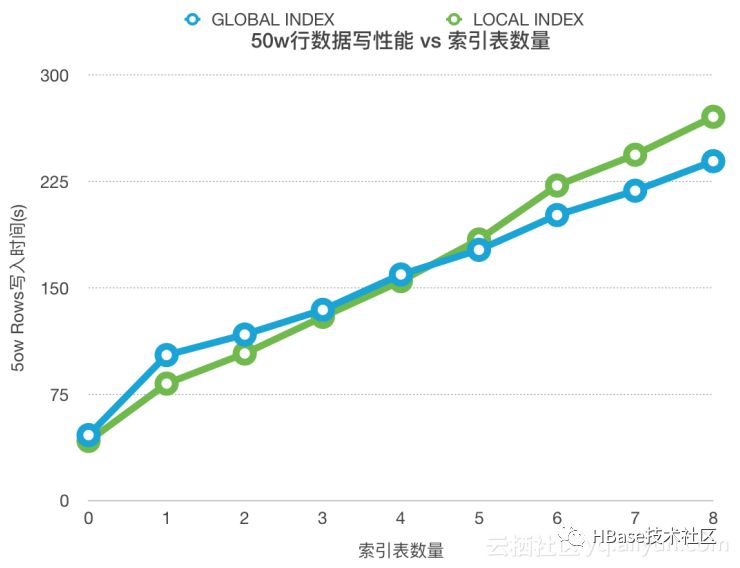
从上表中可以看出,主表写入性能随着二级索引表增多线性降低,无索引表和8个索引表的主表写性能相差6-7倍,而随着索引表的增多,GLOBAL INDEX的写性能优于LOCAL INDEX的。
二级索引案例
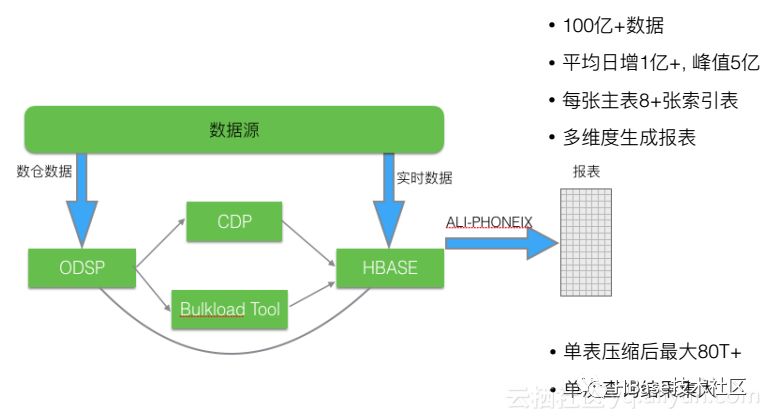
下面通过两个二级索引的案例来加深对二级索引使用的了解。上图为集团内部的一个场景,该案例是要对商品做一个报表。从图中可以了解,平均每天的增长量为1亿+,峰值为5亿,每张主表有8+张索引表,所以是多维度生成报表。其中主要应用到了Phoenix的二级索引的功能,通过二级索引做一些多维度的查询和分析。图中显示单表的压缩后最大为80T+,单次查询结果集大。由此可以看出Phoenix在这种简单查询的多维度大数据的场景中已经很成熟,是一个不错的选择。
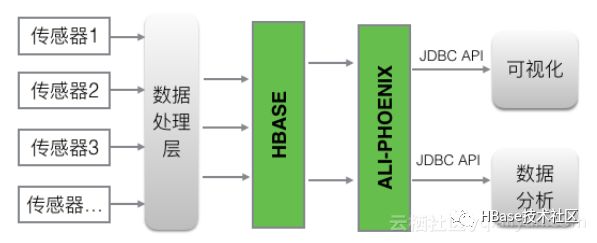
案例二就是物联网,它的特点就是数据量大,写多读少,它的数据来自多个传感器,它每天的写入数据都是5亿+的数据量。在一个HBase的场景中把数据写进来,再把冷数据放出存储低架的存储介质中,把热数据放在SSD中即冷热分离存储,再上面所做的分析功能也是通过二级索引来完成前缀+时间范围的扫描。
Spark on HBase
简介
众所周知Spark 和 HBase是大数据目前比较流行的两款产品。HBase可以划分在OLTP领域,它基于Row key点查性能好,能够自动sharding,具有高可用的特性。而Spark可以划分在OLAP领域,它是一款通用的DAG分析引擎,能够做高性能的内存迭代计算,具有完善的SQL优化层一系列特点。这两款产品的结合映射成了目前比较流行的一类数据库HTAP,它既具备OLAP的功能又具备OLTP的功能。
目前社区做Spark on HBase主要会做以下三方面的功能和优化:支持Spark SQL、Dataset、DataFrame API,支持分区裁剪、列裁剪、谓词下推等优化,Cache HBase的Connections。
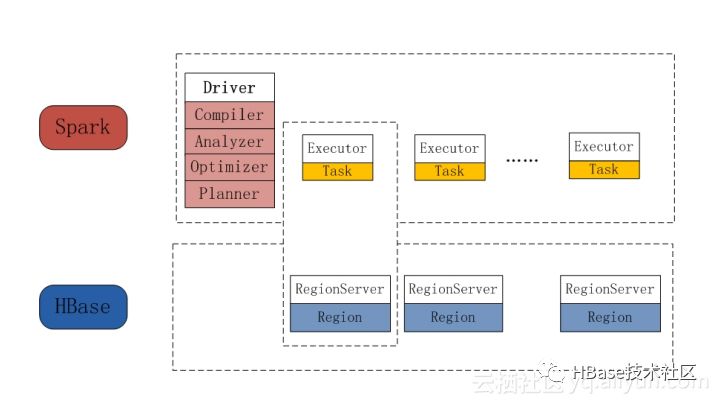
下面我们从Spark和HBase的部署层面以及执行层面来看如何用Spark来分析HBase上的数据。 一个Spark作业运行时首先会启动一个driver,driver中会做Compiler,Analyzer,Optimizer,Planner,并最终生成执行计划,执行计划的每个stage会有多个partition,每个partition对应一个task,每个task会下发到实际的资源上执行。HBase是通过RegionServer来部署的,而每个RegionServer负责若干个Region的读和写服务。
架构
我们在了解Spark on HBase的框架后,接下来深入了解如何在Spark SQL层面上来支持访问HBase。到目前为止比较好的做法就是为Spark SQL添加HBase Source。下面讲述一下Spark SQL的运行流程,首先收到一个SQL Query,通过Catalog识别它的Unresolved Logical Plan生成Logical Plan,再由Logical Optimization做一些优化最终生成物理执行计划从而转化成RDD到Spark Runtime上执行。集成HBase Source主要会做三方面的事情,一是需要HBase TableCatalog完成SQL schema到HBase Column映射,二是需要HbaseRelation继承PrunedFilteredScan 并传入requiredColumns列参数,三是需要HBaseScanRDD来分区裁剪以及task执行location相关的。
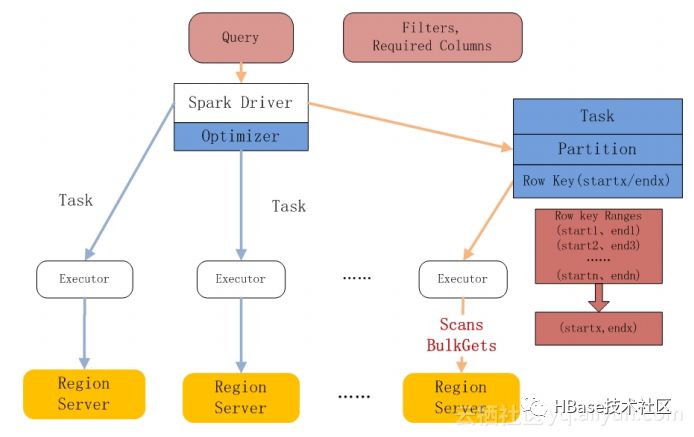
下面将介绍一下相关的优化:分区裁剪、谓词下推、列裁剪。分区裁剪:只去访问需要扫描数据的region,且扫描最少的数据。列裁剪:只去Scan需要的列出来。谓词下推:将filter下推到HBase层面去做。
性能对比及使用
在没有Spark SQL这一层面的HBase集成是,大部分人使用的是Native HBaseRDD来scan HBase的数据,当有Spark SQL的时候可以用DataFrame API来分析数据。通过执行一个catalog的表做简单的select及filter操作后count,对比二者的数据可以看出Spark SQL所需时间要远少于Native HBaseRDD,使用Spark SQL的方式消耗的时间为1.076s,使用Native HBaseRDD消耗的时间为15.425s。

上图为原始HBaseRDD的API使用使用方式。第一步是使用SparkContext的newAPIHadoopRDD来生成HBaseRDD,然后做map操作,map中的item._2是取出HBase的一行的record。由于HBase中存储的是Bytes,所以record对rowkey做filter时需要将rowkey转换成string,这里过滤条件是小于row005,然后filter是把cf1和clo1以true的形式过滤出来。下面所带的map的意义在于拿出所需要的列。
上图为Spark SQL的API使用使用方式,可以看出是主要介绍DataFrame层面的API的。首先需要sqlContext.read并配置参数其中cat是配置Spark SQL schema到HBase column的映射关系,然后生成一个DataFrame,同样类似于上一个例子,先对rowkey做filter,再对col1做filter,最终筛选出col0和col1,并对结果做一个count。
此外,由于HBase的API和Phoenix的API是不一样的,于是Phoinix社区也做了Spark SQL分析Phoenix表数据的一套插件,其做法和Spark分析HBase的插件是一样的,均是通过实现一套Spark SQL的Datasource,然后做列裁剪、分区裁剪、谓词下推这些优化来提高性能。上面的example可以从(https://github.com/lw309637554/alicloud-hbase-spark-examples.git) 这里下载,然后大家可以直接使用Spark来分析云HBase的数据。
未来的工作
关于SQL以及分析,未来计划将为用户做出一款体验更好的产品。该产品的架构最上层是SQL层,该SQL同其他的分析引擎一样会有MetaStore、compiler、optimizer,但这套SQL会提供两种能力分别为OLTP和OLAP,Runtime将使用Spark Runtime。同样在HBase底层会提供二级索引以及全文索引能力来丰富这套SQL的表达能力以及他的性能。在HBase存储层面,HBase原始的存储有Memstore以及HFile,也会引入parquet/ORC来提高性能,同时Spark Runtime也会去直接分析Hfile以及Memstore。
以上是关于云HBaseSQL及分析——Phoenix&Spark的主要内容,如果未能解决你的问题,请参考以下文章
Spark 实战系列Phoenix 整合 spark 进行查询分析
Spark 实战系列Phoenix 整合 spark 进行查询分析
工作中Hadoop,Spark,Phoenix,Impala 集群中遇到坑及解决方案