HBase学习之结构设计
Posted vincent
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase学习之结构设计相关的知识,希望对你有一定的参考价值。
一、HBase在应用层面存取的数据结构
应用层面上,不考虑实现细节。我们对Hbase的操作像其他数据库一样。是以表为单位来存放数据的。但HBase中的表跟传统的关系数据库表,在结构上和存储上有一定差别。
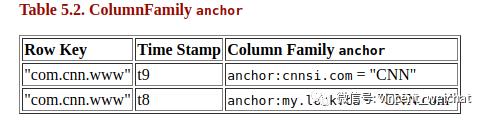
上图中存储了一行cnn的网站数据,这行数据又具体存储了网站的网页内容(contents),和网站的链接(anchor)数据
HBase的表有以下几个重要术语
Row Key :标示一行的主键,按字典顺序排列。查找数据都是通过Row Key来进行。比如上图中展示了Row key为“com.cnn.www”的一行数据(不要看上图表格有多行。那是由于Hbase每列数据有一个版本概念,在逻辑上,只要他们的Row key相同,则属同一行)
Column Famliy 列族。Hbase中的最小存储单元。不同于关系型数据库以行为单位存储,Hbase 是以列族的为单位存储。上图当中有两个列族。contents 和anchor
Column 一个列族下有多个列。以上图为例。列族 contents下有一列 html 。 列族anchor 下有 cnnsi.com 和 my.look.ca 两列数据。所以名字上描述一个列,应该加上列族前缀,因为不同的列族可能拥有相同的列名。列名描述形式 “列族:列”(英文术语,Family Prefix: qualifier)。所以上图中三列分别写作:contents:html 、anchor:cnnsi.com 和 anchor:my.look.ca 尽量将相同作用,或相同类型业务范围的列,放在同一个列族中
Version 也就是上图中的Time Stamp ,随着时间推移,一列数据可能被记录了多个值,每一个值,都一个对应的时间戳做为版本
Cell 某一个行某一列,某个时间点的具体取值,叫做cell。定位元组 {row, column, version}
从逻辑试图上看上图的表,感觉结构上很稀疏,因为有些列没值。但HBase不是以行而是以列族为单位存储,所以不会浪费存储空间。上图的实际存储形式如下:

二、HBase的三种类型的服务器
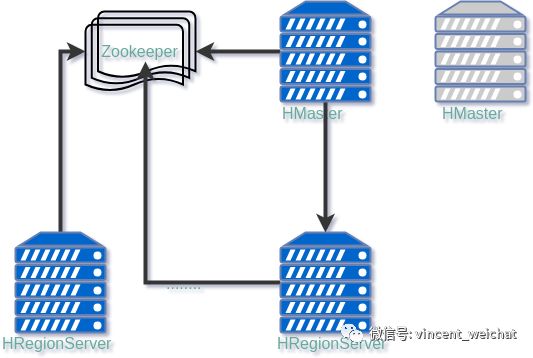
HBase在服务结构上,主要有三种类型的服务集群组成。他们分别是Zookeeper, HMaster,以及HRegionServer。这三者之间的工作关系如下:
HMaster 分为多台,活跃的HMaster向Zookeeper维持心跳。不活跃的HMaster监听。如果发现活跃的HMaster心跳停止,则自己承担起新的HMaster角色。活跃的HMaster只有一个。活跃的HMaster还要通过Zookeeper监听HRegionServer的状态,从而获知哪些HRegionServer是可用的。对于表的DDL(create,delete table)是通过HMaster来操作的。Region Split后的重新分配,也是通过HMaster来负责。总的来说,除了Table数据的读写,其余的事情HMaster都要负责。
HRegionServer 向Zookeeper注册自己的心跳
Zookeeper 当然是所有这些角色的协调者。
三、HRegionServer结构
任何大数据存储系统,在设计时都要实现以下几个重要的点
数据分片Shard 一台机器的存储有限,通过将海量数据切分存储到不同的机器。数据的持续增长,只需要加机器就好
数据分片的备份Replica 数据被存放到了不同的机器,某台机器挂掉,会导致部分数据不可用。Replica副本机制,通过将分片备份到不同的机器,实现数据的高可用
数据的读写路由 逻辑上的一张表,被分散存在不同的机器,那找一份数据的时候,如何定位?
3.1 HRegionServer分片
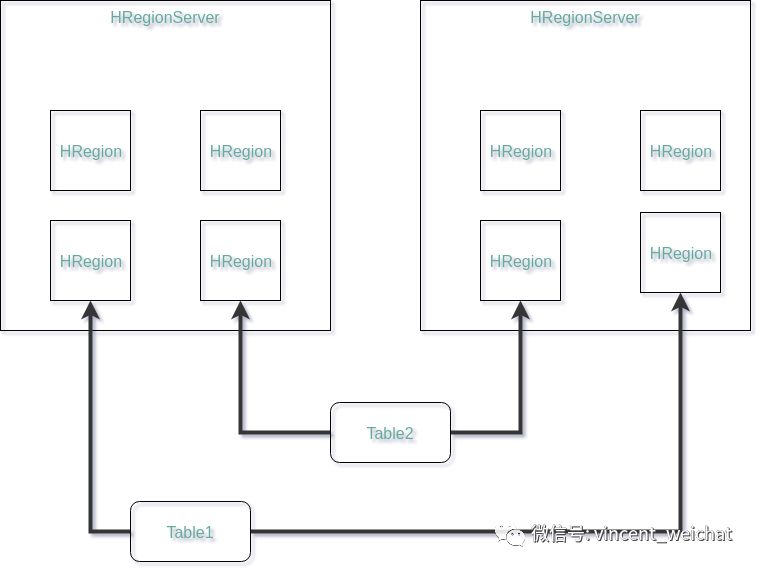
一个HRegionServer当中存放了多个Region。HBase中的表可能很大,其对应的存储单元就是Region,初始的时候,一张表可能只有一个Region,当数据量增多时,Region会分化,并且为了保证负载均衡,分化后的Region会被放在不同的RegionServer中(一台RegionServer的读写性能有限)。所以Region相当于分表后的Shard。
3.2 HRegionServer的Replica
HRegionServer通过Region的方式,实现了数据的分片功能。数据的Replica则是通过底层的HDFS来实现的。所以Region实际存储在HDFS中的。HDFS本身有实现稳定的Replica功能。
3.3 读写数据的时的路由
当读取一条数据时,为了快速在海量数据中定位数据所在的机器,需要一张索引表。这个表叫META Table. Meta Table也是一张HBase Table.只是他存储了如下信息:
某个表的某个Region存储在哪个HRegionServer
这个Region存储起始键值(Row Key)是多少
查找数据的时候,先从Zookeeper找到Meta Table在那个RegionServer上,然后加载Meta Table,从中查询定位要找的业务数据。
四、如何保证海量数据存取的性能
互联网业务往往即时就会产生大量的数据,这些数据需要快速的存储。保证数据的快速写入有一个经典的数据结构LSM。LSM Tree的具体实现不在赘述,请移步另外一篇专题。LSM在HBase中的实现结构如下:
五、后话
在整个Hadoop生态中,Zookeeper负责分布式一致性。HDFS负责分布式数据的高可用。而HBase则在这之上实现数据的分片,路由,高速读写。这种堆积木式的架构设计,让每一个组件都及其精简可维护、可更换(比如架设在数据层上的计算层Hadoop MapReduce,就可以替换成Spark)。从而降低了分布式系统开发的复杂性。这种思想值得在设计所有复杂系统时参考。
六、参考文献
https://mapr.com/blog/in-depth-look-hbase-architecture/
http://hbase.apache.org/0.94/book/book.html
以上是关于HBase学习之结构设计的主要内容,如果未能解决你的问题,请参考以下文章