HBASE研究及优化-上篇:HBASE基本模块及优化
Posted 中国移动大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBASE研究及优化-上篇:HBASE基本模块及优化相关的知识,希望对你有一定的参考价值。
背景
Hadoop云平台是中国移动企业级大数据集群建设的重要项目,本期项目包含采集集群、日志集群、清单集群。其中清单集群,主要是为客服提供用户上网日志查询,为满足数据量大,并发性高,查询低时延要求,使用Hadoop生态系统中的HBase实现业务需求。
由于数据量大,在HBase使用过程中,先后遇到了Rowkey设计不均衡,预分区数量不合理,使用默认参数配置不够优的各类问题。因此,特别对HBase进行了深入研究,以此来诠释实际应用中遇到的各种问题。
HBASE基本模块
HBase是一个构建在HDFS之上的分布式列簇数据库,是一个开源的、分布式的、多版本、面向列簇的存储模型,基于Google的Bigtable论文开发而成,底层使用Hadoop的HDFS作为文件存储系统,依赖ZooKeeper进行集群的状态同步。
HBase集群采用Master/Slave架构搭建,由以下类型节点组成:HMaster节点、HRegionServer节点,并依赖ZooKeeper集群,HDFS集群,总体结构如下图所示:
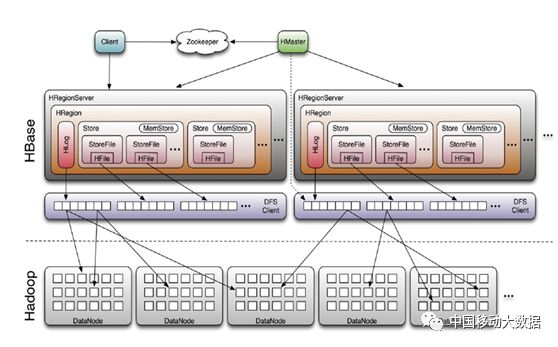
图1 HBASE结构
1

HMaster

管理HRegionServer,实现其负载均衡。
管理和分配HRegion。
响应DDL请求并执行操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
2
HRegion Server
HRegionServer是HBase中最主要的组件,负责table数据的实际读写,管理一到多个HRegion。在分布式集群中,HRegionServer一般跟DataNode在同一个节点上,目的是实现数据的本地性,提高读写效率。
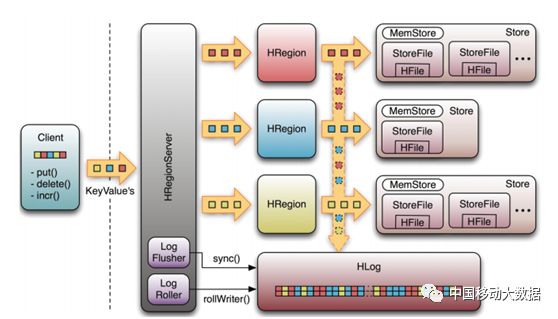
图2 HBase数据存储结构
3
HRegion
HBase表根据row key 划分成“Region”, 表的行数据按照Rowkey 全局有序。一个HRegion包含该表格中从起始key到结束key之间的所有行。HRegion会被分配到集群中的RegionServer的节点。HRegion 中MemStore Flush的时候,会优先在本地DataNode 生成一份副本,如下图所示:
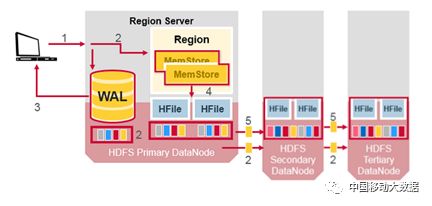
图3 HBase数据存储流程
注:HBase数据的逻辑和物理层次:Namespace->table->Region->Store->HFile->Block->KeyValue
HRegion是HBase实现分布式存储和负载均衡的最小单元。
4
Store
Region是Region Server上的基本数据服务单位,用户表由1个或者多个Region组成,根据Table的Schema定义,在Region内每个ColumnFamily的数据对应一个Store。一个Region可能包括多个不同Table的Store,这也是单个表ColumnFamily不建议设置过多的原因,因为Region可能split Store到不同的节点上,造成ColumnFamily扫描性能低下。每个Store内包括一个MemStore和若干个StoreFile(HFile)。如下图所示:
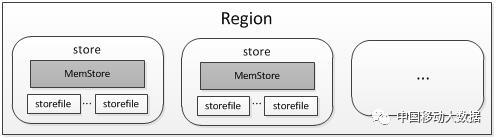
图4 Region组成
5
hbase:meta表
注:0.98版本以后Hbase取消了-root-表
HBase的特殊内置表,从存储结构和操作方法的角度来说,它们和其他HBase的表没有任何区别,可以认为就是张普通的表,对于普通表的操作对.META.表适用。.META.表与众不同的地方是HBase用它们来存贮重要的系统信息—Region的分布情况以及每个Region的详细信息。
.META. 表结构为:
- Key: table,region start key,region id
aaaaa_week_2018,201805:170100626,1526094008559.f7f37b98c01f68b7b5cc6c1c3734a666
|---表名-------------|-----起始行-----------|--创建时间戳---|----整体进行MD5 hash 值------------|
- Values: RegionServer
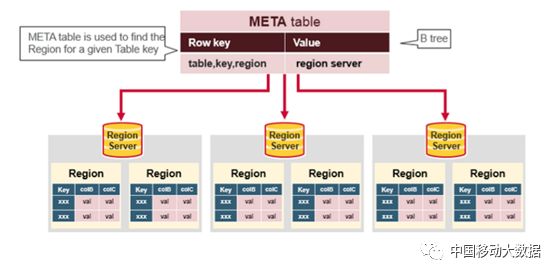
图5 HBASE:META表
6
Block
HBase数据读写的最小单元,读写必须以Block为单位。
有四种类型的block:DATA、INDEX、BLOOM和META
下图是HFile的存储结构,显示了对不同Block的组织:
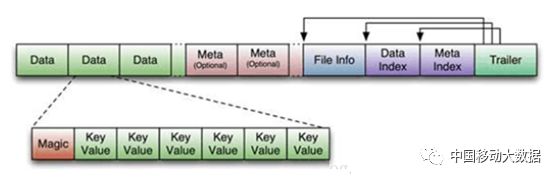
图6 HFile存储格式
DATA:存储用户数据
INDEX:用于提高读取速度,为DATA BLOCK中的cell建立索引
BLOOM:用于提高读取速度,用bloom filter过滤掉不包含需求数据的block
META:存储HFile本身数据和元数据。
7
WAL(Write Ahead Log)
0.94版本之前叫做HLog,存储在/hbase/.logs/目录中。
0.94版本之后存储在HDF上的/hbase/WALs/{HRegionServer_name}中。
记录RegionServer上的所有编辑信息(Puts/Deletes操作,属于哪个Region),在写到memstore之前,先写WAL,用于RegionServer宕机后,通过Replay恢复RegionServer上memstore中尚未持久化的数据。
8
MemStore
写缓存。写入数据时先写到MemStore,flush触发后刷新到磁盘,以KeyValue的形式存储在内存中。读数据时,也会将MemStore作为缓存的一部分。
9
BlockCache
读缓存,数据被读取之后缓存在内存中。
有LruBlockCache(效率较高,但缓存在JVM Heap中,GC压力大)和BucketCache(有3种配置方式,分别是Java heap,off heap以及SSD)两种BlockCache,默认为LruBlockCache。每个RegionServer中只有一个BlockCache实例。
HBASE优化
在日常优化工作中,我们总结了一些HBase可优化的内容及建议:
01
在创建HBase表时,根据数据量合理的设置预分区数量,设置合理的split key,设计均衡的rowkey,减少region分裂的发生次数。但预分区数量也不宜过多,如数据使用Bulkload 导入的时候,每个Region 对应一个reduce任务,Region数量越多,reduce 任务越多。
02
majorcompaction时会产生大量IO,同时处于分裂或移动期间的Region,数据暂时不能读写,因此对major compaction需要设置合理的周期,建议关闭,并通过脚本设置在业务低谷(如凌晨)执行,避免在业务高峰期自动执行。在Region分裂或移动时,由于数据暂时不能读写,如果此时客户端读写数据会报异常并重试,所以我们应该尽量避免Region split,同时适当增加客户端重试次数,优化参数hbase.client.retries.number(默认值为31)。
03
建议每台RegionServer管理10-100个Regions,每个Region最大控制在40G以下。RegionServer 管理的Region 数量越大,通常读写性能越差。另外过多的Region 会导致RegionServer 宕机恢复、集群重启的时间更长。
04
大数据量数据导入推荐使用Bulkload,Bulkload的原理是通过MR 根据Region 的范围,生成HFile,然后将HFile 导入到HBase 中。可减少大数据量插入带来的RegionServer RPC以及GC压力,需要注意的是BulkLoad会跳过WAL,Replication需要使用WAL所以无法看到bulk load数据,需要通过发送裸数据或者HFILE到备集群处理。
05
对于随机查询量大,时延要求低的应用,需要大量的HDFS 磁盘 seek,HDD磁盘的随机访问性能很差,延迟比较长,此类业务如手机详单,可以使用SSD,SSD 随机读的性能非常高,当然成本也高。
06
对于数据量比较大的业务,又带有时间访问特性的,建议使用按天、按月来分表(目前Hadoop清单集群是按月分表)。数据量越大需要的Region 以及HFile越多,每个Region发生 compaction的成本越高,对网络IO和磁盘IO消耗也大,同时会降低读性能。如果在集群规模一定的情况下,可通过分表来解决。每个表参与的compaction 数据量很显著减少。因为历史表的数据不会参与当前表的compaction。
07
BucketCache配置off heap来减少Java 堆内存的占用,减少GC对RegionServer 的影响。
08
HDFS 可以开启短路读及Hedged Read来提高读取效率。
HBase 开启Hedged Read 来降低HBase 读取超时的概率。Hedged Read的原理是在RegionServer(相当于是HDFS的客户端)启动多个读线程,当RegionServer 读取HDFS 数据时候,配置一个超时时间,如果超过这个超时时间,则启动另外的线程去读取HDFS中的其它副本,2个读取线程谁先返回,则使用谁的结果,从而降低读取超时的概率。
在下篇文章中,将重点研究HBase主要业务流程。
以上是关于HBASE研究及优化-上篇:HBASE基本模块及优化的主要内容,如果未能解决你的问题,请参考以下文章