HBase查询优化
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase查询优化相关的知识,希望对你有一定的参考价值。
1.概述
HBase是一个实时的非关系型数据库,用来存储海量数据。但是,在实际使用场景中,在使用HBase API查询HBase中的数据时,有时会发现数据查询会很慢。本篇博客将从客户端优化和服务端优化两个方面来介绍,如何提高查询HBase的效率。
2.内容
这里,我们先给大家介绍如何从客户端优化查询速度。
2.1 客户端优化
客户端查询HBase,均通过HBase API的来获取数据,如果在实现代码逻辑时使用API不当,也会造成读取耗时严重的情况。
2.1.1 Scan优化
在使用HBase的Scan接口时,一次Scan会返回大量数据。客户端向HBase发送一次Scan请求,实际上并不会将所有数据加载到本地,而是通过多次RPC请求进行加载。这样设计的好处在于避免大量数据请求会导致网络带宽负载过高影响其他业务使用HBase,另外从客户端的角度来说可以避免数据量太大,从而本地机器发送OOM(内存溢出)。
默认情况下,HBase每次Scan会缓存100条,可以通过属性hbase.client.scanner.caching来设置。另外,最大值默认为-1,表示没有限制,具体实现见源代码:
/** * @return the maximum result size in bytes. See {@link #setMaxResultSize(long)} */ public long getMaxResultSize() { return maxResultSize; } /** * Set the maximum result size. The default is -1; this means that no specific * maximum result size will be set for this scan, and the global configured * value will be used instead. (Defaults to unlimited). * * @param maxResultSize The maximum result size in bytes. */ public Scan setMaxResultSize(long maxResultSize) { this.maxResultSize = maxResultSize; return this; }

一般情况下,默认缓存100就可以满足,如果数据量过大,可以适当增大缓存值,来减少RPC次数,从而降低Scan的总体耗时。另外,在做报表曾显时,建议使用HBase分页来返回Scan的数据。
2.1.2 Get优化
HBase系统提供了单条get数据和批量get数据,单条get通常是通过请求表名+rowkey,批量get通常是通过请求表名+rowkey集合来实现。客户端在读取HBase的数据时,实际是与RegionServer进行数据交互。在使用批量get时可以有效的较少客户端到各个RegionServer之间RPC连接数,从而来间接的提高读取性能。批量get实现代码见org.apache.hadoop.hbase.client.HTable类:
public Result[] get(List<Get> gets) throws IOException { if (gets.size() == 1) { return new Result[]{get(gets.get(0))}; } try { Object[] r1 = new Object[gets.size()]; batch((List<? extends Row>)gets, r1, readRpcTimeoutMs); // Translate. Result [] results = new Result[r1.length]; int i = 0; for (Object obj: r1) { // Batch ensures if there is a failure we get an exception instead results[i++] = (Result)obj; } return results; } catch (InterruptedException e) { throw (InterruptedIOException)new InterruptedIOException().initCause(e); } }
从实现的源代码分析可知,批量get请求的结果,要么全部返回,要么抛出异常。
2.1.3 列簇和列优化
通常情况下,HBase表设计我们一个指定一个列簇就可以满足需求,但也不排除特殊情况,需要指定多个列簇(官方建议最多不超过3个),其实官方这样建议也是有原因的,HBase是基于列簇的非关系型数据库,意味着相同的列簇数据会存放在一起,而不同的列簇的数据会分开存储在不同的目录下。如果一个表设计多个列簇,在使用rowkey查询而不限制列簇,这样在检索不同列簇的数据时,需要独立进行检索,查询效率固然是比指定列簇查询要低的,列簇越多,这样影响越大。
而同一列簇下,可能涉及到多个列,在实际查询数据时,如果一个表的列簇有上1000+的列,这样一个大表,如果不指定列,这样查询效率也是会很低。通常情况下,在查询的时候,可以查询指定我们需要返回结果的列,对于不需要的列,可以不需要指定,这样能够有效地的提高查询效率,降低延时。
2.1.4 禁止缓存优化
批量读取数据时会全表扫描一次业务表,这种提现在Scan操作场景。在Scan时,客户端与RegionServer进行数据交互(RegionServer的实际数据时存储在HDFS上),将数据加载到缓存,如果加载很大的数据到缓存时,会对缓存中的实时业务热数据有影响,由于缓存大小有限,加载的数据量过大,会将这些热数据“挤压”出去,这样当其他业务从缓存请求这些数据时,会从HDFS上重新加载数据,导致耗时严重。
在批量读取(T+1)场景时,建议客户端在请求是,在业务代码中调用setCacheBlocks(false)函数来禁止缓存,默认情况下,HBase是开启这部分缓存的。源代码实现为:
/** * Set whether blocks should be cached for this Get. * <p> * This is true by default. When true, default settings of the table and * family are used (this will never override caching blocks if the block * cache is disabled for that family or entirely). * * @param cacheBlocks if false, default settings are overridden and blocks * will not be cached */ public Get setCacheBlocks(boolean cacheBlocks) { this.cacheBlocks = cacheBlocks; return this; } /** * Get whether blocks should be cached for this Get. * @return true if default caching should be used, false if blocks should not * be cached */ public boolean getCacheBlocks() { return cacheBlocks; }
2.2 服务端优化
HBase服务端配置或集群有问题,也会导致客户端读取耗时较大,集群出现问题,影响的是整个集群的业务应用。
2.2.1 负载均衡优化
客户端的请求实际上是与HBase集群的每个RegionServer进行数据交互,在细分一下,就是与每个RegionServer上的某些Region进行数据交互,每个RegionServer上的Region个数上的情况下,可能这种耗时情况影响不大,体现不够明显。但是,如果每个RegionServer上的Region个数较大的话,这种影响就会很严重。笔者这里做过统计的数据统计,当每个RegionServer上的Region个数超过800+,如果发生负载不均衡,这样的影响就会很严重。
可能有同学会有疑问,为什么会发送负载不均衡?负载不均衡为什么会造成这样耗时严重的影响?
1.为什么会发送负载不均衡?
负载不均衡的影响通常由以下几个因素造成:
没有开启自动负载均衡
集群维护,扩容或者缩减RegionServer节点
集群有RegionServer节点发生宕机或者进程停止,随后守护进程又自动拉起宕机的RegionServer进程
针对这些因素,可以通过以下解决方案来解决:
开启自动负载均衡,执行命令:echo "balance_switch true" | hbase shell
在维护集群,或者守护进程拉起停止的RegionServer进程时,定时调度执行负载均衡命令:echo "balancer" | hbase shell
2.负载不均衡为什么会造成这样耗时严重的影响?
这里笔者用一个例子来说,集群每个RegionServer包含由800+的Region数,但是,由于集群维护,有几台RegionServer节点的Region全部集中到一台RegionServer,分布如下图所示:
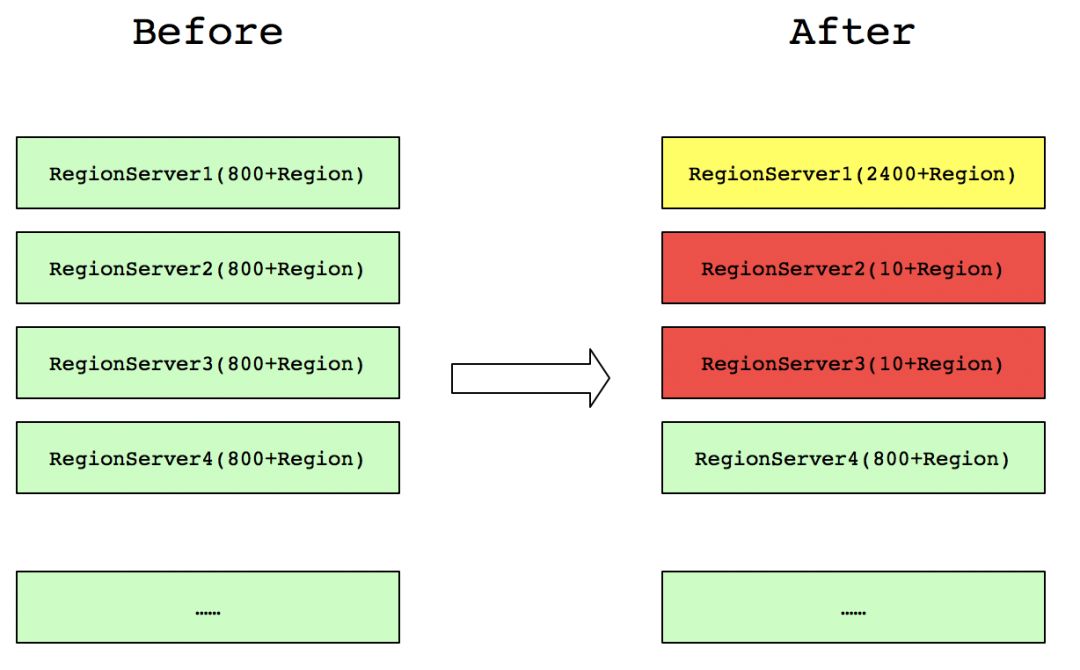
这样之前请求在RegionServer2和RegionServer3上的,都会集中到RegionServer1上去请求。这样就不能发挥整个集群的并发处理能力,另外,RegionServer1上的资源使用将会翻倍(比如网络、磁盘IO、HBase RPC的Handle数等)。而原先其他正常业务到RegionServer1的请求也会因此受到很大的影响。因此,读取请求不均衡不仅会造成本身业务性能很长,还会严重影响其他正常业务的查询。同理,写请求不均衡,也会造成类似的影响。故HBase负载均衡是HBase集群性能的重要体现。
2.2.2 BlockCache优化
BlockCache作为读缓存,合理设置对于提高读性能非常重要。默认情况下,BlockCache和Memstore的配置各站40%,可以通过在hbase-site.xml配置以下属性来实现:
hfile.block.cache.size,默认0.4,用来提高读性能
hbase.regionserver.global.memstore.size,默认0.4,用来提高写性能
本篇博客主要介绍提高读性能,这里我们可以将BlockCache的占比设置大一些,Memstore的占比设置小一些(总占比保持在0.8即可)。另外,BlockCache的策略选择也是很重要的,不同的策略对于读性能来说影响不大,但是对于GC的影响却比较明显,在设置hbase.bucketcache.ioengine属性为offheap时,GC表现的很优秀。缓存结构如下图所示:
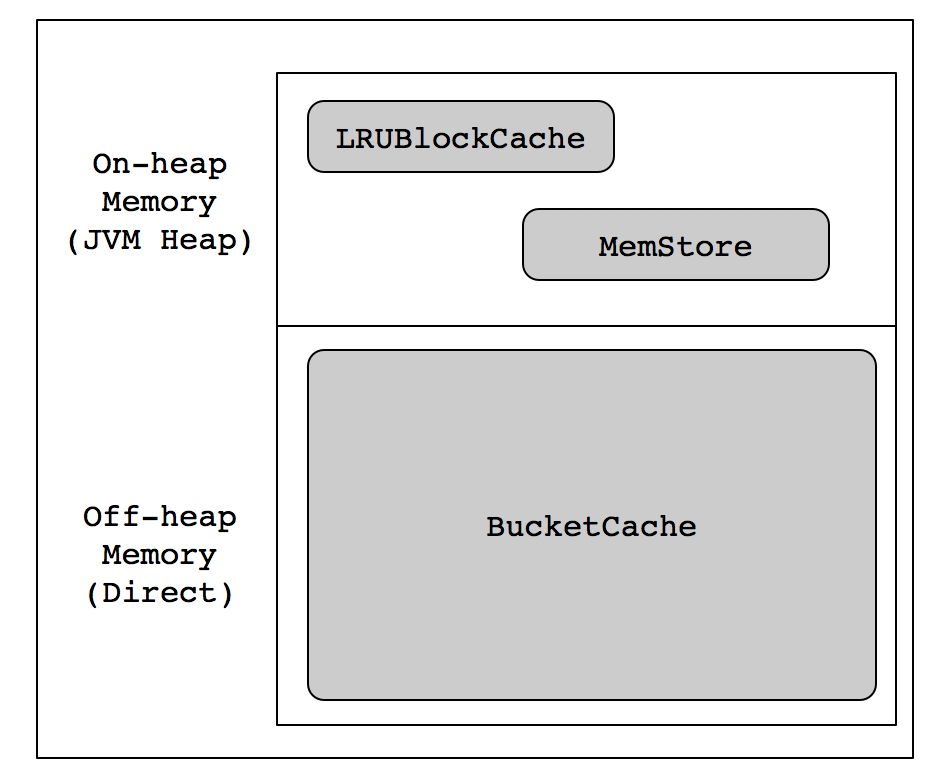
设置BlockCache可以在hbase-site.xml文件中,配置如下属性:
<!-- 分配的内存大小尽可能的多些,前提是不能超过 (机器实际物理内存-JVM内存) -->
<property>
<name>hbase.bucketcache.size</name>
<value>16384</value>
</property>
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property>
设置块内存大小,可以参考入下表格:
| 标号 | 描述 | 计算公式或值 | 结果 |
| A | 物理内存选择:on-heap(JVM)+off-heap(Direct) | 单台物理节点内存值,单位MB | 262144 |
| B | HBASE_HEAPSIZE('-Xmx) | 单位MB | 20480 |
| C | -XX:MaxDirectMemorySize,off-heap允许的最大内存值 | A-B | 241664 |
| Dp | hfile.block.cache.size和hbase.regionserver.global.memstore.size总和不要超过0.8 | 读取比例占比*0.8 | 0.5*0.8=0.4 |
| Dm | JVM Heap允许的最大BlockCache(MB) | B*Dp | 20480*0.4=8192 |
| Ep | hbase.regionserver.global.memstore.size设置的最大JVM值 | 0.8-Dp | 0.8-0.4=0.4 |
| F | 用于其他用途的off-heap内存,例如DFSClient | 推荐1024到2048 | 2048 |
| G | BucketCache允许的off-heap内存 | C-F | 241664-2048=239616 |
另外,BlockCache策略,能够有效的提高缓存命中率,这样能够间接的提高热数据覆盖率,从而提升读取性能。
2.2.3 HFile优化
HBase读取数据时会先从BlockCache中进行检索(热数据),如果查询不到,才会到HDFS上去检索。而HBase存储在HDFS上的数据以HFile的形式存在的,文件如果越多,检索所花费的IO次数也就必然增加,对应的读取耗时也就增加了。文件数量取决于Compaction的执行策略,有以下2个属性有关系:
hbase.hstore.compactionThreshold,默认为3,表示store中文件数超过3个就开始进行合并操作
hbase.hstore.compaction.max.size,默认为9223372036854775807,合并的文件最大阀值,超过这个阀值的文件不能进行合并
另外,hbase.hstore.compaction.max.size值可以通过实际的Region总数来计算,公式如下:
hbase.hstore.compaction.max.size = RegionTotal / hbase.hstore.compactionThreshold
2.2.4 Compaction优化
Compaction操作是将小文件合并为大文件,提高后续业务随机读取的性能,但是在执行Compaction操作期间,节点IO、网络带宽等资源会占用较多,那么什么时候执行Compaction才最好?什么时候需要执行Compaction操作?
1.什么时候执行Compaction才最好?
实际应用场景中,会关闭Compaction自动执行策略,通过属性hbase.hregion.majorcompaction来控制,将hbase.hregion.majorcompaction=0,就可以禁止HBase自动执行Compaction操作。一般情况下,选择集群负载较低,资源空闲的时间段来定时调度执行Compaction。
如果合并的文件较多,可以通过设置如下属性来提生Compaction的执行速度,配置如下:
<property>
<name>hbase.regionserver.thread.compaction.large</name>
<value>8</value>
<description></description>
</property>
<property>
<name>hbase.regionserver.thread.compaction.small</name>
<value>5</value>
<description></description>
</property>
2.什么时候需要执行Compaction操作?
一般维护HBase集群后,由于集群发生过重启,HBase数据本地性较低,通过HBase页面可以观察,此时如果不执行Compaction操作,那么客户端查询的时候,需要跨副本节点去查询,这样来回需要经过网络带宽,对比正常情况下,从本地节点读取数据,耗时是比较大的。在执行Compaction操作后,HBase数据本地性为1,这样能够有效的提高查询效率。
3.总结
本篇博客HBase查询优化从客户端和服务端角度,列举一些常见有效地额优化手段。当然,优化还需要从自己实际应用场景出发,例如代码实现逻辑、物理机的实际配置等方面来设置相关参数。大家可以根据实际情况来参考本篇博客进行优化。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以去京东自营商店进行购买
以上是关于HBase查询优化的主要内容,如果未能解决你的问题,请参考以下文章