开源的非关系型分布式数据库--HBase
Posted 亚洲技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源的非关系型分布式数据库--HBase相关的知识,希望对你有一定的参考价值。
一、起源和来由
自1970年以来,关系数据库用于数据存储和处理结构化的数据。大数据的出现后,好多公司实现处理大数据并从中受益,并开始选择像 Hadoop 的解决方案。
Hadoop使用分布式文件系统,用于存储大数据,并使用MapReduce来处理。Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理。
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
技术发展已经向开源、共享的方式前进,特别是软件发展的历史一次次证明了,软件开放的重要性。下面我们一起来了解一下,开源的分布式数据库--HBase。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
| HDFS | HBase |
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
二、简单定义HBase
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会Hadoop项目的一部分,运行于HDFS文件系统之上,为Hadoop提供类似于BigTable规模的服务。HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来存取数据,也可以通过REST、Avro或者Thrift的API来访问。HBase虽然性能有显著的提升,但还不能直接取代SQL数据库。现今它已经应用于多个数据驱动型网站。
三、基本介绍
HBase–HadoopDatabase,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。
与YonghongZ-DataMart等商用大数据产品不同,HBase是GoogleBigtable的开源实现,类似GoogleBigtable利用GFS作为其文件存储系统,HBase利用HadoopHDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用HadoopMapReduce来处理HBase中的海量数据;GoogleBigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
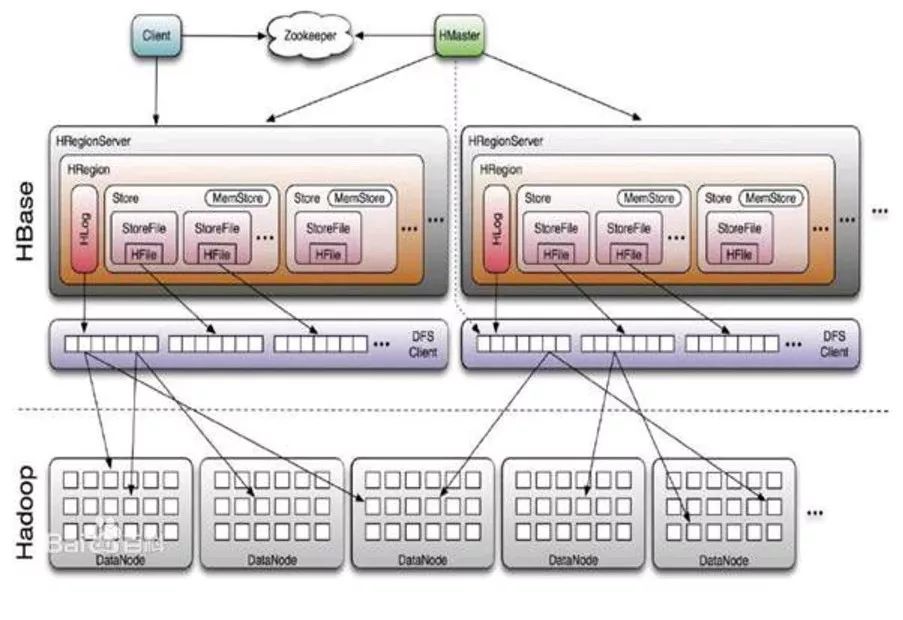
上图描述HadoopEcoSystem中的各层系统其中,HBase位于结构化存储层,HadoopHDFS为HBase提供了高可靠性的底层存储支持,HadoopMapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
2主要模型
主要讨论逻辑模型和物理模型
(1)逻辑模型
Hbase的名字的来源是Hadoopdatabase,即hadoop数据库。
主要是从用户角度来考虑,即如何使用Hbase。
(2)物理模型
主要从实现Hbase的角度来讨论
HBase的存储机制
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
表是行的集合。
行是列族的集合。
列族是列的集合。
列是键值对的集合。
3访问接口
1.NativeJavaAPI,最常规和高效的访问方式,适合HadoopMapReduceJob并行批处理HBase表数据
2.HBaseShell,HBase的命令行工具,最简单的接口,适合HBase管理使用
3.ThriftGateway,利用Thrift序列化技术,支持C++,php,Python等多种语言,适合其他异构系统在线访问HBase表数据
4.RESTGateway,支持REST风格的HttpAPI访问HBase,解除了语言限制
5.Pig,可以使用PigLatin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduceJob来处理HBase表数据,适合做数据统计
6.Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
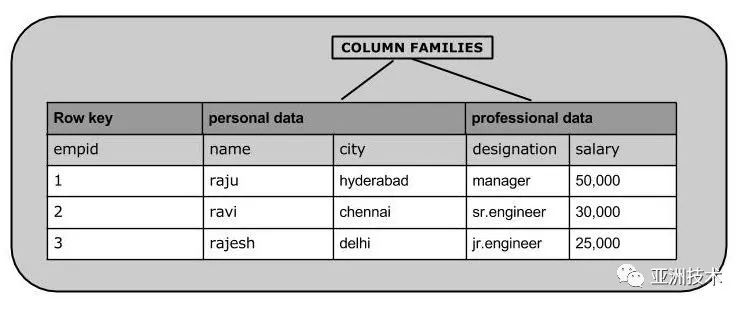
HBase数据模型Table&ColumnFamily
| RowKey | Timestamp | ColumnFamily | |
| URI | Parser | ||
| r1 | t3 | url=http:// | title= |
| t2 | host=com | ||
| t1 | |||
| r2 | t5 | url=http:// | content=每天… |
| t4 | host=com |
ØRowKey:行键,Table的主键,Table中的记录默认按照RowKey升序排序
ØTimestamp:时间戳,每次数据操作对应的时间戳,可以看作是数据的versionnumber
ØColumnFamily:列簇,Table在水平方向有一个或者多个ColumnFamily组成,一个ColumnFamily中可以由任意多个Column组成,即ColumnFamily支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Table&Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理:
-ROOT-&&.META.Table
HBase中有两张特殊的Table,-ROOT-和.META.
Ø.META.:记录了用户表的Region信息,.META.可以有多个regoin
Ø-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
ØZookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
MapReduceonHBase
在HBase系统上运行批处理运算,最方便和实用的模型依然是MapReduce,如下图:
HBaseTable和Region的关系,比较类似HDFSFile和Block的关系,HBase提供了配套的TableInputFormat和TableOutputFormatAPI,可以方便的将HBaseTable作为HadoopMapReduce的Source和Sink,对于MapReduceJob应用开发人员来说,基本不需要关注HBase系统自身的细节。
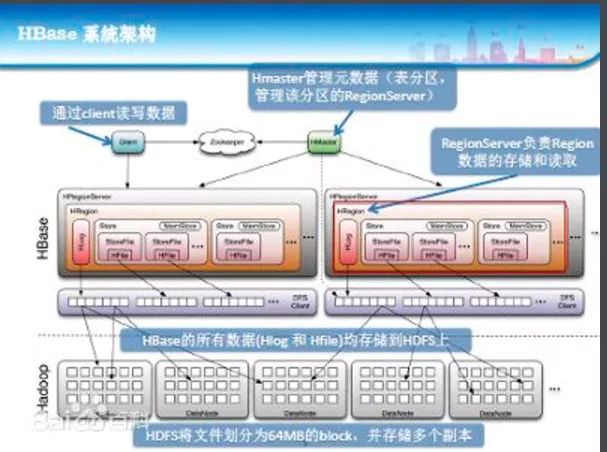
HBase系统架构
ClientHBaseClient使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
1Zookeeper
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的MasterElection机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1.管理用户对Table的增、删、改、查操作
2.管理HRegionServer的负载均衡,调整Region分布
3.在RegionSplit后,负责新Region的分配
4.在HRegionServer停机后,负责失效HRegionServer上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个ColumnFamily的存储,可以看出每个ColumnFamily其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个ColumnFamily中,这样最高效。
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是SortedMemoryBuffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBaseI/O的高性能。当StoreFilesCompact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前RegionSplit成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
在理解了上述HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每个HRegionServer中都有一个HLog对象,HLog是一个实现WriteAheadLog的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在LoadRegion的过程中,会发现有历史HLog需要处理,因此会ReplayHLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
4存储格式

规范化的信息容易使用结构化的表格存储,而非结构化的数据无法指定规则存储空间,需要另行开创存储思路。
HBase中的所有数据文件都存储在HadoopHDFS文件系统上,主要包括上述提出的两种文件类型:
1.HFile,HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2.HLogFile,HBase中WAL(WriteAheadLog)的存储格式,物理上是Hadoop的SequenceFile
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数据块的起始点。FileInfo中记录了文件的一些Meta信息,例如:AVG_KEY_LEN,AVG_VALUE_LEN,LAST_KEY,COMPARATOR,MAX_SEQ_ID_KEY等。DataIndex和MetaIndex块记录了每个Data块和Meta块的起始点。
DataBlock是HBaseI/O的基本单元,为了提高效率,HRegionServer中有基于LRU的BlockCache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:
开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示TimeStamp和KeyType(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HLog文件的结构可以看出,其实就是一个普通的HadoopSequenceFile,SequenceFile的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括sequencenumber和timestamp,timestamp是“写入时间”,sequencenumber的起始值为0,或者是最近一次存入文件系统中sequencenumber。
HLogSequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
下图显示了列族在面向列的数据库:
| HBase | RDBMS |
| HBase无模式,它不具有固定列模式的概念;仅定义列族。 | RDBMS有它的模式,描述表的整体结构的约束。 |
| 它专门创建为宽表。 HBase是横向扩展。 | 这些都是细而专为小表。很难形成规模。 |
| 没有任何事务存在于HBase。 | RDBMS是事务性的。 |
| 它反规范化的数据。 | 它具有规范化的数据。 |
| 它用于半结构以及结构化数据是非常好的。 | 用于结构化数据非常好。 |
HBase的特点
HBase线性可扩展。
它具有自动故障支持。
它提供了一致的读取和写入。
它集成了Hadoop,作为源和目的地。
客户端方便的Java API。
它提供了跨集群数据复制。
在哪里可以使用HBase?
Apache HBase曾经是随机,实时的读/写访问大数据。
它承载在集群普通硬件的顶端是非常大的表。
Apache HBase是此前谷歌Bigtable模拟非关系型数据库。 Bigtable对谷歌文件系统操作,同样类似Apache HBase工作在Hadoop HDFS的顶部。
HBase的应用
它是用来当有需要写重的应用程序。
HBase使用于当我们需要提供快速随机访问的数据。
很多公司,如Facebook,Twitter,雅虎,和Adobe内部都在使用HBase。
喜欢文章可以长按二维码识别并关注 亚洲技术。回看历史文章。
以上是关于开源的非关系型分布式数据库--HBase的主要内容,如果未能解决你的问题,请参考以下文章