腾讯专家讲解:微信支付HBase实践与创新
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯专家讲解:微信支付HBase实践与创新相关的知识,希望对你有一定的参考价值。
徐春明——腾讯金融与支付数据库平台组负责人,在数据库行业有超过10年的工作经验,擅长mysql数据库运维、内核开发。近期深入研究HBase相关技术,负责HBase技术在腾讯支付场景的落地。
摘要:
本次分享讲述的是关系型数据库在腾讯金融支付场景下遇到的挑战,选择HBase背后的主要原因以及我们是如何打造高性能、高可靠、高可用的HBase数据中心。最后是关于HBase在互联网金融业务方面遇到的挑战和解决之道。
分享大纲:
1.关系数据库挑战—扩展性、可维护性、易用性
2.如何打造HBase中心—高性能、可靠、高可用
3.HBase挑战和应对—业务局限、二级索引、集群复制
正文:
一.关系数据库挑战—扩展性、可维护性、易用性
财付通是腾讯在2005年成立的, 2013年逐渐淡出用户视野,之前负责解决在PC端的支付业务。现阶段财付通主要是为微信红包提供中后端业务以及服务金融业务。2005年,腾讯的数据库还比较单一,基本上都是MySQL,每秒的峰值交易量只有几百,当时我们着重解决数据安全、可容性以及跨城容灾等问题。但2015年因微信红包的出现,交易量峰值一年之内涨了100倍,我们遇到了性能、容灾以及可用性等方面的诸多问题,团队为解决这些问题做了非常多的工作,最终建立了一个交易系统+历史数据的基本系统架构。
以上这个架构主要运用了MySQL的一些组件,包括三种引擎,左边是实时库集群,这个集群使用的是InnoDB引擎,集群中的设备性能很好,IO能力强,内存大,CPU也很好,里面有几百套的分组,因为微信支付的交易很复杂,涉及到分布式事务、同城容灾、跨城容灾等等很多方面。当时我们使用的是MySQL和InnoDB数据库,使用过程中发现只要出现一个节日,我们线上的容量就会不够,因为高性能的服务器容量是有限的。
而且节日的出现导致交易峰值很高,所以我们出现了锯齿形的峰值图。除此之外,数据库容量也在飞快的增长,基于这些问题我们的解决办法是进行删除不重要字段、优化索引、减少数据内容等操作,将历史数据迁移到历史库集群中,2015年之前我们还不是实时迁移,一般是第二天低峰期批量导出导入然后再删除。
这样的方式虽然能解决我们线上交易的高并发海量数据问题,但是在遇到需要历史数据的情况时依旧会出现很多问题。

我们遇到的挑战主要是上图的几个方面,第一个水平扩展,因为国家要求金融机构保存交易数据,随着交易数据与日俱增,单机性能存储很容易达到瓶颈,架构难以适应目前数据存储规模,需要考虑数据拆分,但传统DB拆分困难,工作量很大周期又长。
第二个是数据迁移,我们设置数据迁移策略,定期从交易DB里将数据写入到历史DB中,但其中分库分表的迁移策略很复杂,造成了上一层Spider的配置非常复杂,容易出错,所以在业务使用的时候就出现了好几次查不出数据,导致业务数据不完整。
再一个问题历史DB一般是廉价的设备,容量很大也很容易出故障,虽然我们有多个历史库备机,直接通过复制同步数据来解决系统问题,但数据量实在太大,运行过程中发现备机总是追不上主机,一旦主机出现故障,备机由于延迟不能对外作为主机使用,只能去修复故障的主机,存在比较大的风险。
在批量查询上,传统历史DB采用TokuDB引擎,数据高度压缩,磁盘IO、内存性能比较差,大批量的数据扫面对单机性能影响很大,容易拖垮历史库。业务查询方面也出现了查询数据不准、数据错乱等等问题。
总的来说,业务开始运行之后,数据库总是出现问题,导致了很多数据库口碑的负面影响。
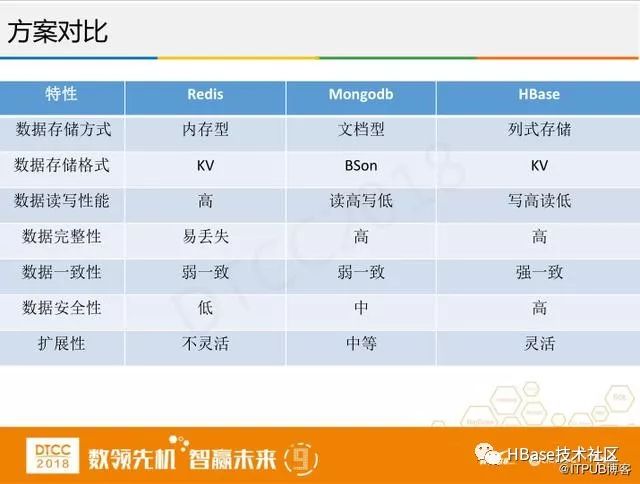
我们当时解决方案就是对比数据库来选择性能更好的数据库,我们对比了Redis、MongoDB还有 HBase,但最终选择了HBase,主要是看中了它写高读低的特点,这个对我们其实影响不大,我们对历史数据的查询比较少,也没有像对在线交易业务的要求那么高。第二是它的扩展性灵活,只要HBase的集群稳定,它的扩容就非常容易,HBase的安全性也高,这样团队需要做的事情就少了很多,我们可以有更多的精力放在其他方面的工作。
二.如何打造HBase中心—高性能、可靠、高可用
选择HBase数据中心之后,接下来就是如何打造的问题,当时团队确定了100万+每秒输入,可用率99.9%、0条记录丢失、错误的目标,具体实施步骤分两步走:
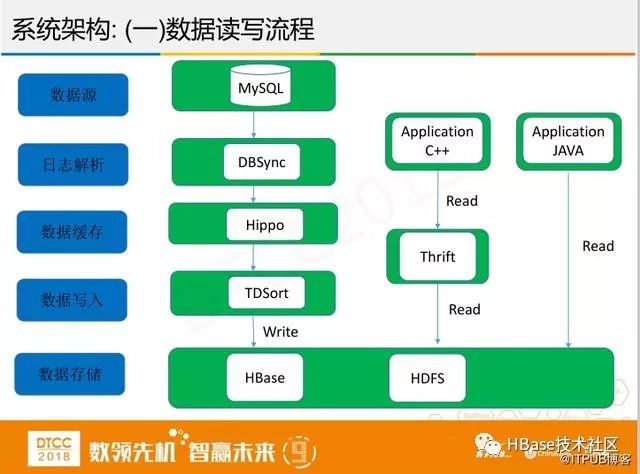
首先要将数据录入到HBase中,我们的数据源是MySQL,数据经过日志解析系统DBSync之后缓存再写入HBase。中间过程本来没有这么复杂,当时是负责数据挖掘的leader找到我,因为他们每次数据统计不准确,接到的投诉比较多。正好我们从成本角度考虑,不用申请这部分服务器,可以快速将数据写入到自己的HBase。数据录入后该如何查询呢?我们交易业务基本用c++实现,HBase用的是Java语言,HBase的thrift可用于跨语言的数据传输,所以我们就基于thrift做了一个API来解决跨语言问题。
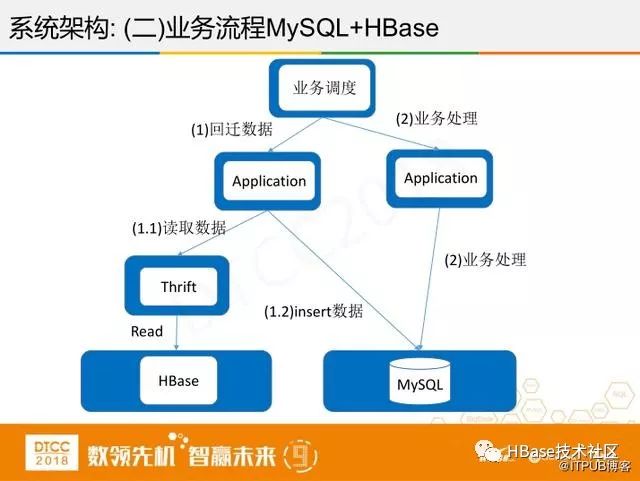
对于业务流程该如何使用呢?我们不仅仅把HBase当做存历史数据的平台,业务流程除开账务DB外,还有其他交易相关的DB,它们都有同一个问题,容量很容易爆满,为了将HBase发挥更大的用处,在特定的场景下,比如一个月前的历史退款,线上数据不可能保存这么久,如果时间有一个月以上的退款,我们从HBase查退款,将其写入MySQL,核心的退款流程和金融流程直接在MySQL做,这样一来对业务的改动最小,方便业务操作。
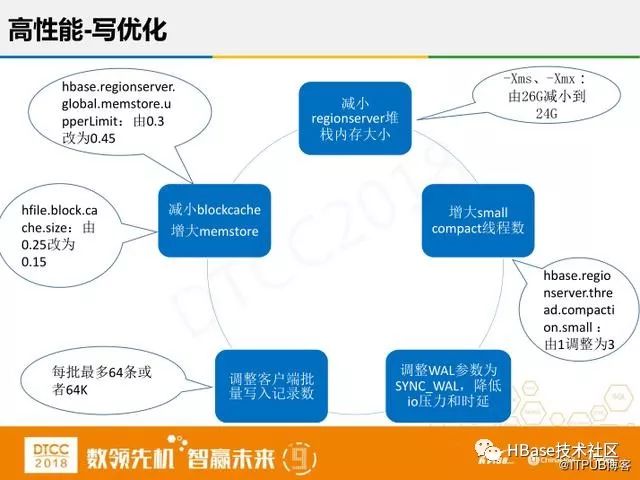
HBase的写入原理是基于LSM思想,先把数据写入内存之后返回,通过异步方式再落盘,但是这样在磁盘就有很多小文件,查询的性能就会非常差。所以,还需要将磁盘上的小文件compaction,减少文件个数。考虑之前积压的很多compaction任务,我们把small compact线程条加大。再一个是调整WAL日志的参数,做过关系型数据库的人可能清楚,HBase里有四种方式,第一种是直接写内存不写硬盘,第二种是异步的落盘,第三种就是写入操作系统不落盘,第四种是实时写盘。结合性能与数据可靠性,我们采用写入操作系统不落盘的方式,考虑有三个副本同时出现三连级故障的可能性比较低,降低IO压力和时延。再有就是减小regionserver堆栈内存大小,因为我们业务写入量实在太频繁,而cache查询命中率真非常低,大概只有10%到15%,所以我们将内存全部分给写入,来提高写入的量。因为是批量写入型业务,我们可以根据需求调整客户端批量写入记录数来提高写的性能。
优化之后,压测时达到了每秒150万+次写入,达到了很不错的效果。

之后是读的优化,我们用的服务器硬件很差,运作率很低,所有的查询基本全靠磁盘的IO硬能力去抗。LSM思想有个缺点,就是文件数太多影响查询性能,假如要查询rowkey=100的数据,文件数有100个,由于每个文件里可能都有rowkey=100的记录,那么我们就要扫描100个文件,耗费时间很长。我们的解决方法是减少在region下的文件数,定期合并文件,把小文件整合成大文件。第二个就是重点隔离,我们把一些表单独隔离,做一个组,去减小耦合,而且组内机器只允许制定表读写请求,避免不同表之间的相互影响。还有参数优化,我们一开始建了很多region表,这样对整个集群压力太大,所以就减少小表,控制其数量。再有一个就是业务按照优先级分等级,不同的级别的业务不同处理,有些索引表可以按年建,有些表可以按月建。最后是硬件升级,重点组配置更高性能的服务器。
优化之后,查询时耗从开始的260毫秒下降到60毫秒,查询时耗曲线也逐渐平缓。

在高可用方面,第一个HBase本身必须保证可用,这是最基础的点,避免Full GC,避免Region Server单个Region阻塞不可用。第二当机器出现故障,怎么做才不会影响整个集群的读写?我们使用快速剔除机制,避免单台服务器负载高影响集群,第三考虑网络不可用、机房故障情况,为此建立主、备集群,一个集群里有三个副本,那么就共有六个副本,成本很高,我们考虑隔三个月时间就减少到两个副本,以此来节约成本。第四避免雪崩,无论是Thrift Server还是RPC的调用,操作时间都是比较长的, 这就需要缩短Thrift Server超时时间,减少重试次数。最后按业务重要级别分组,减少和其他机器的耦合。
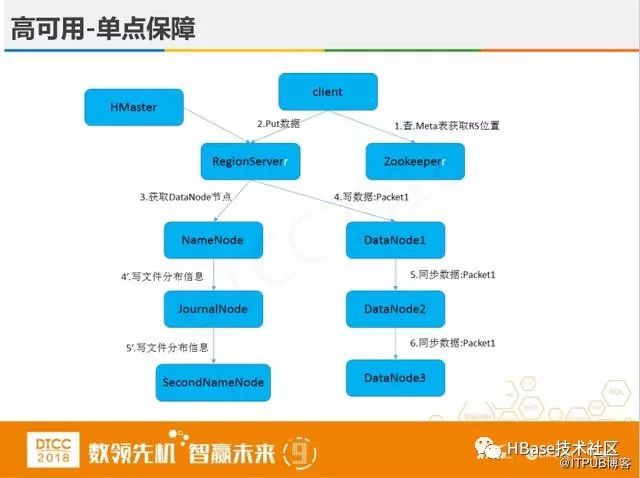
上图是高可用单点保障的流程图:从客户端写入一个数据,查阅Meta表获取RS位置,把数据写到RegionServer中,然后异步写到Hadoop层去同步数据。可以看到在集群内只有Region Server是单点,其它组件都有高可用方案。当Region Server故障时,集群内迁移恢复一般需要几分钟,对于OLTP业务来说是不可接受的。可选择的方案是业务快速迁移到备集群,或者使用region replica。
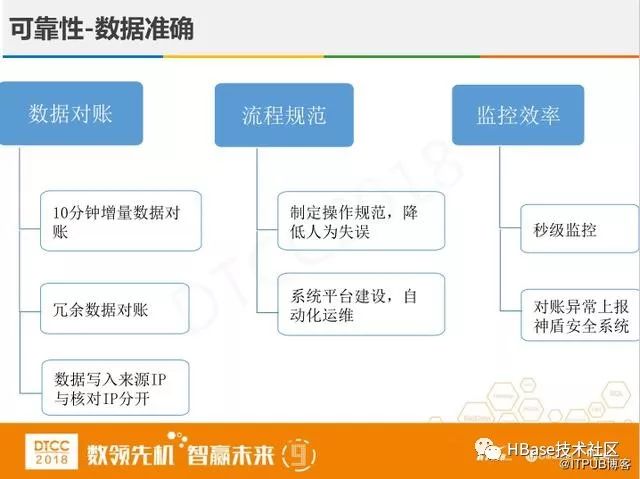
我们通过三种方法来保证数据的准确性,第一种是数据对账,在金融系统中都会有数据对账,我相信无论什么系统都会有bug,对账十分关键不能出错,我们有10分钟增量对账,有冗余数据对账,要求数据写入来源IP与核对IP分开,来源DB于对账DB分开。第二个从流程规范来降低人为失误,通过一些系统化的方法来运维。第三个是提高监控效率,加了秒级监控,如果出现问题能快速发现马上解决,出现对账异常立刻上报神盾安全系统。这样通过上面的三种方法,我们把数据的准确性提高了一个量级。

这里单独讲下update的特殊处理,金融业务对数据的处理分两种,第一种是直接映射的,像用户资金流失这种比较简单。比较困难的是第二种时间批量对账,比如像一些余额和某些订单的状态,我们一天的数据量有几百亿,该如何应对平均一秒几十万的对账呢,为此系统加了修改时间,使得对账更加准确,但同时会造成数据的冗余,比如一个单号对应我们交易系统里的一条记录,但在HBase中没有update,全部是映射,这样就会有两条记录,这样状态下退款是不能成功的,为解决这个问题,我们将MySQL binlog中update拆分成delete + insert两条消息,使得HBase中保留一条记录。
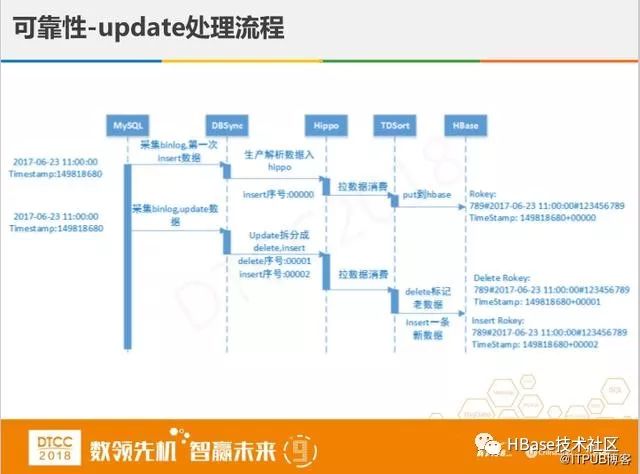
但这样还有一个问题,有可能在同一秒钟有两次记录,就是说同一个单号在一秒钟内完成交易,拆分数据时,有可能导致两条数据记录都删掉,如果没有一定的并发量,这个问题是不会出现的。我们在处理这个问题时采取在拆分时加个序号,并且保证insert在delete的后面,这样就能确保留下一条记录。

我们在实际运用HBase过程中,也遇到了很多其他问题。第一个是遇到HBase读写线程队列分开,因为我们写入量远远多于读的量,比如退款业务只有写没有读,我们调整了hbase.ipc.server.callqueue.read.share=0.3的参数,来保证一定的读写线程。还遇到某一台DataNode负载高导致整个集群写入量下降非常明显,我们增加了秒级监控可以快速发现,快速迁移region解决。
之后还有可维护性方面的问题,HBase有些配置不能动态修改配置、不支持命令查看HBase集群运营情况、缺少汇总统计功能。还有就是容量均衡,我们的数据量在不断增加,我们有几十台服务器磁盘容量已经用了99%,有的服务器容量使用还不到1%。所以需要在服务器间迁移数据。可以不在HBase层操作,而是从hdfs层停datanode节点,让namenode迁移。
总的来说,虽然HBase有一些缺点,但HBase的优势更加明显,它性能稳定有利于更好地解放人力,节约成本。
三.HBase挑战和应对—业务局限、二级索引、集群复制
下面是我对于HBase的想法, 现阶段HBase的应用场景只有两种,有比较大的局限性,因为它不支持SQL,不支持跨行跨表事务,不支持二级索引,而且读时延大。它不能用在OLTP(On-Line Transaction Processing联机事务处理过程)业务,比如支付业务的核心流程,但适合存放历史数据,处理历史数据的对账、历史数据的回溯等需求。

那如何来解决事务问题呢?第一个,HBase虽然不支持跨行跨表事务,但可以多表变单表,实施单表设计与HBase单行事务。所以在处理数据表的事务时,尽量多表换单表,避免分布式事务。
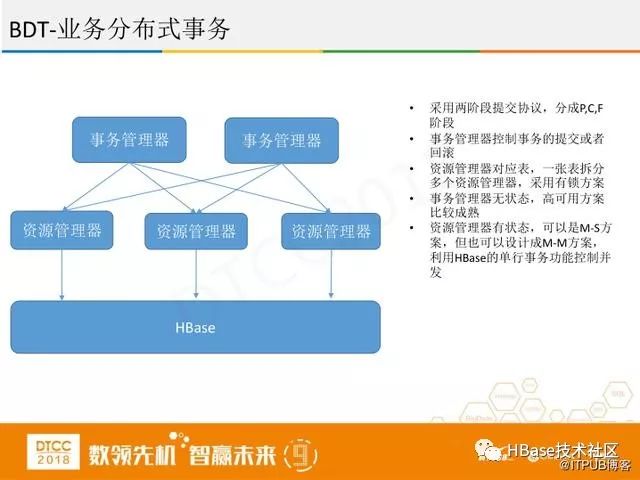
第二个事务是业务分布式事务,如果做金融业务,在HBase中改动难度太大,可以在业务层进行改动,采用两阶段提交协议,分成P,C,F阶段。事务管理器控制事务的提交或者回滚。资源管理器对应表,一张表拆分多个资源管理器,采用有锁方案。事务管理器无状态,高可用方案比较成熟。资源管理器有状态,可以是M-S方案,但也可以设计成M-M方案,无论是分布式还是单机,把HBase进行重组,利用HBase的单行事务功能来控制并发。
下面是具体的例子
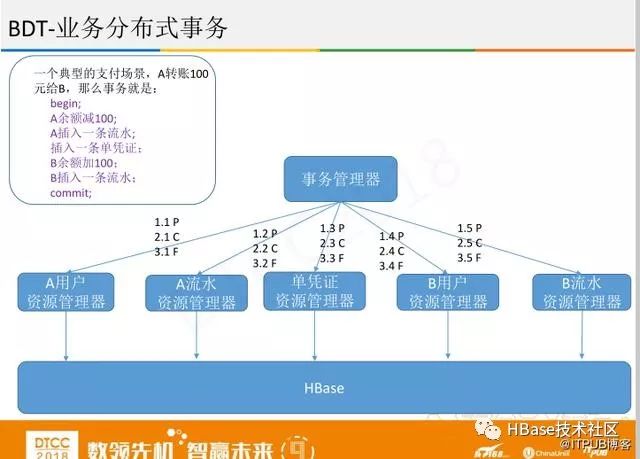
第三个是开源分布式事务框架。主要是两种OMID和Percolator,共同点是两阶段分布式。不同点是OMID有个全局事务,通过它来控制并发,控制哪个事务该回滚。Percolator主要是运用Hbase协处理器的技术,实践起来比较困难。
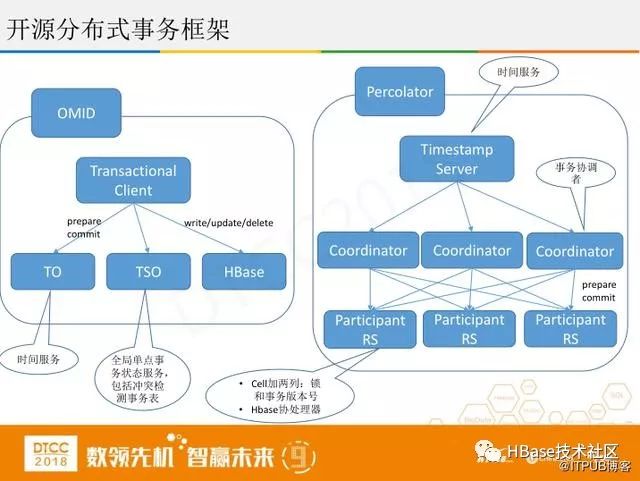

上图是协处理器的应用,第一个是Phoenix,它支持sql、二级索引,通过Coprocessor实现,但它不稳定,数据量大的情况容易造成HBase崩溃。第二个Coprocessor实现,使用Observer实现在写主表前先写索引表,最后是时间库表,表设计成按月或者按日分表,新建索引时不用copy历史数据。
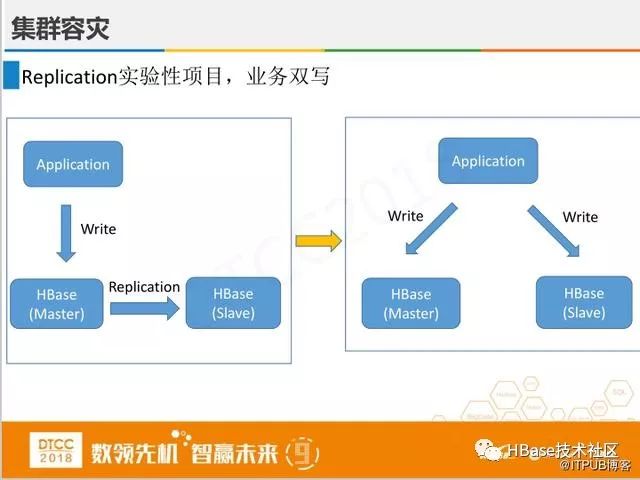
HBase有复制的功能,但在使用过程中发现它不稳定,我们后来通过应用来实现双写功能。
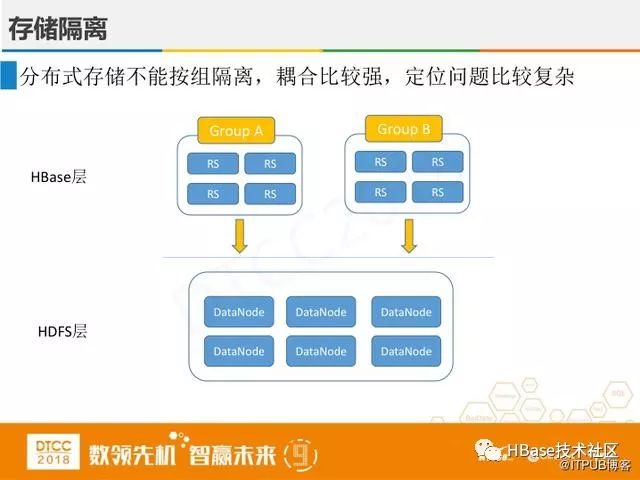
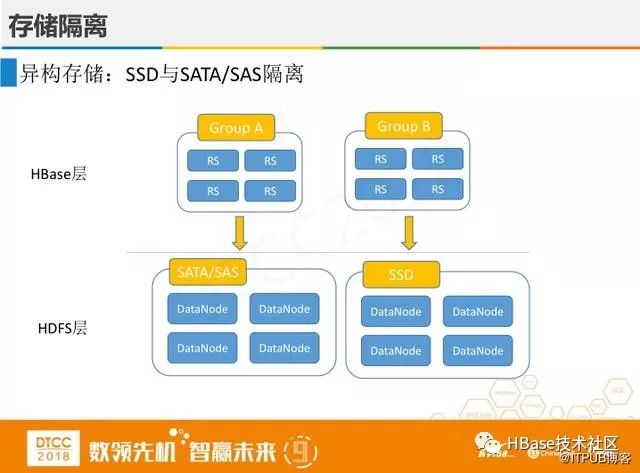
上图是HBase和Hadoop支持的隔离方案,虽然能在一定程度上做到了隔离,但这种隔离不彻底,耦合比较强,定位问题比较复杂,依旧不能实现业务上隔离。
最后,谈一下数据库的目标和方向。无论是传统的关系型数据库还是分布式数据库,努力的方向就是提供高可用、高性能、高并发、好用、易扩展的数据服务。目前市面上的数据库非常多,但所有的数据库或多或少总有几个特性实现得差强人意,所以也没有出现“一统江湖”的数据库,导致数据库应用出现百花齐放的局面,这也是各个数据库团队努力的方向和动力。
以上是关于腾讯专家讲解:微信支付HBase实践与创新的主要内容,如果未能解决你的问题,请参考以下文章